- The paper demonstrates that multimodal foundation models outperform audio-only models in detecting emotionally manipulated speech deepfakes.
- The study introduces SCAR, a fusion framework employing nested cross-attention and self-attention for refined feature integration.
- Results reveal improved EER and robust performance across language subsets, underscoring the advantages of multimodal approaches in EmoFake detection.
Investigating Multimodal Foundation Models for EmoFake Detection
Introduction
The paper "Are Multimodal Foundation Models All That Is Needed for Emofake Detection?" (2509.16193) addresses the emerging challenge of detecting emotionally manipulated speech deepfakes, known as EmoFakes. These manipulations alter a speaker's emotional attributes while preserving linguistic content and speaker identity. Current threats from such manipulations include identity fraud, misinformation, and forensic evidence alteration, emphasizing the necessity for robust detection mechanisms. While significant advancements have been made in detecting traditional audio deepfakes using foundation models (FMs), EmoFakes present a distinct challenge by utilizing intricate emotional cues to enhance perceived authenticity, demanding more specialized detection approaches.
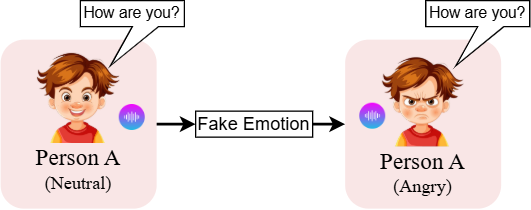
Figure 1: Demonstration of EmoFake: Speaker A's happy speech is manipulated to synthesize a sad emotional tone in the audio while maintaining the same spoken content ('I'm fine, thanks!').
Comparative Analysis of Foundation Models
The paper proposes the hypothesis that multimodal foundation models (MFMs), such as LanguageBind (LB) and ImageBind (IB), provide superior performance in EmoFake Detection (EFD) compared to audio-only foundation models (AFMs) like Wav2vec2 and Whisper. MFMs benefit from cross-modal pre-training, allowing them to learn and generalize emotional patterns across multiple modalities, thereby effectively identifying unnatural emotional transitions and inconsistencies within manipulated audio.
Experimental results substantiate the hypothesis, demonstrating that MFMs consistently outperform AFMs across varied language subsets in EFD tasks. Notably, Whisper, among the AFMs, exhibits the best performance, likely due to its multilingual pre-training which facilitates enhanced capture of pitch, tone, and intensity variations.
SCAR Framework for Enhanced Fusion
Recognizing the potential for improved performance through FM fusion, the paper introduces SCAR, a novel framework designed to enable effective FM fusion. SCAR encompasses a nested cross-attention mechanism for enriched representational integration across modalities, complemented by a self-attention refinement module that accentuates pivotal cross-FM cues while mitigating noise interference.
SCAR's systematic hierarchical structure ensures progressive alignment of FM representations, leading to refined feature understanding and synergy between modalities. Evaluation results reveal SCAR's dominance over traditional concatenation-based fusion techniques, especially in combining MFMs, where it achieves superior EER values, establishing a new benchmark for EFD.
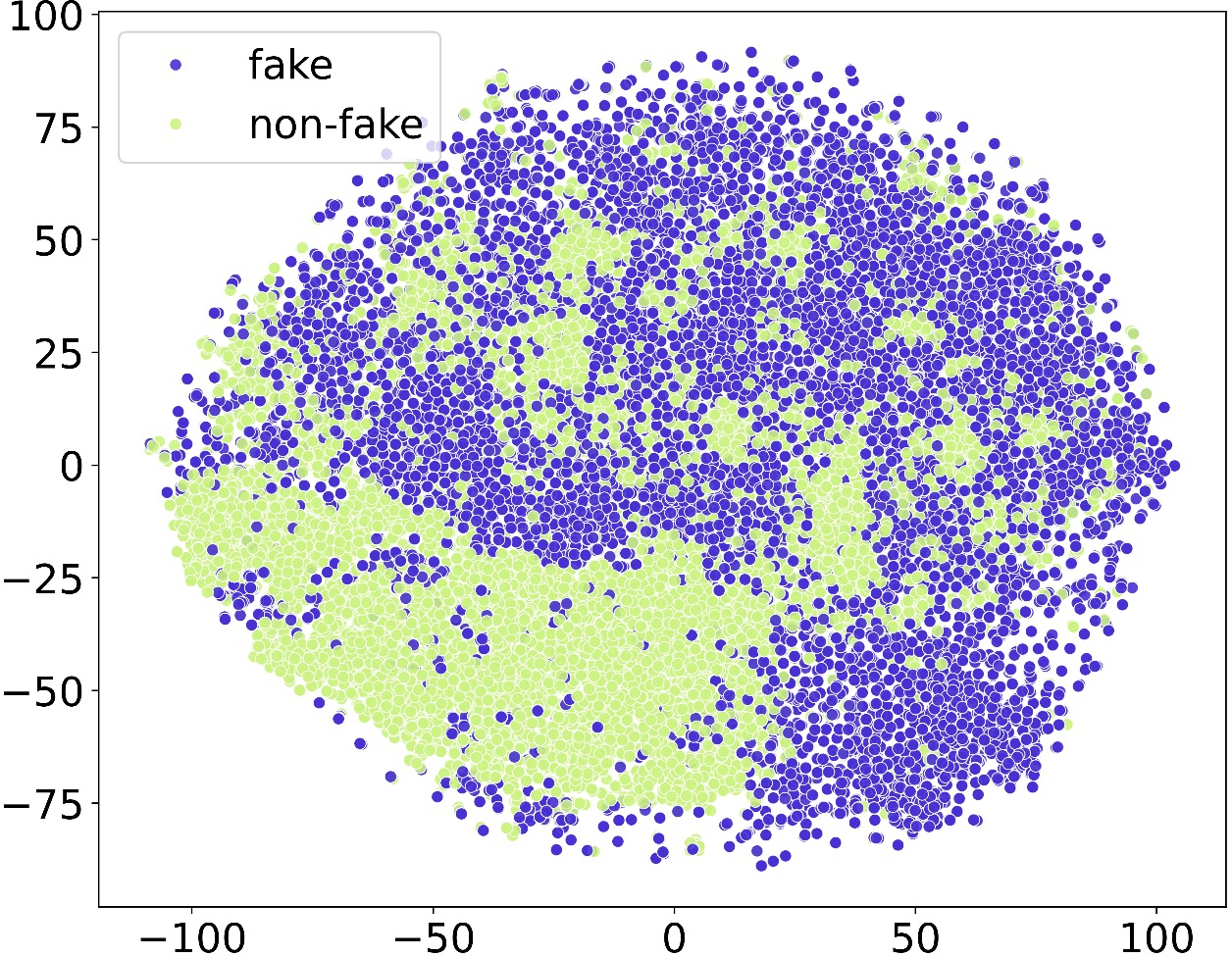
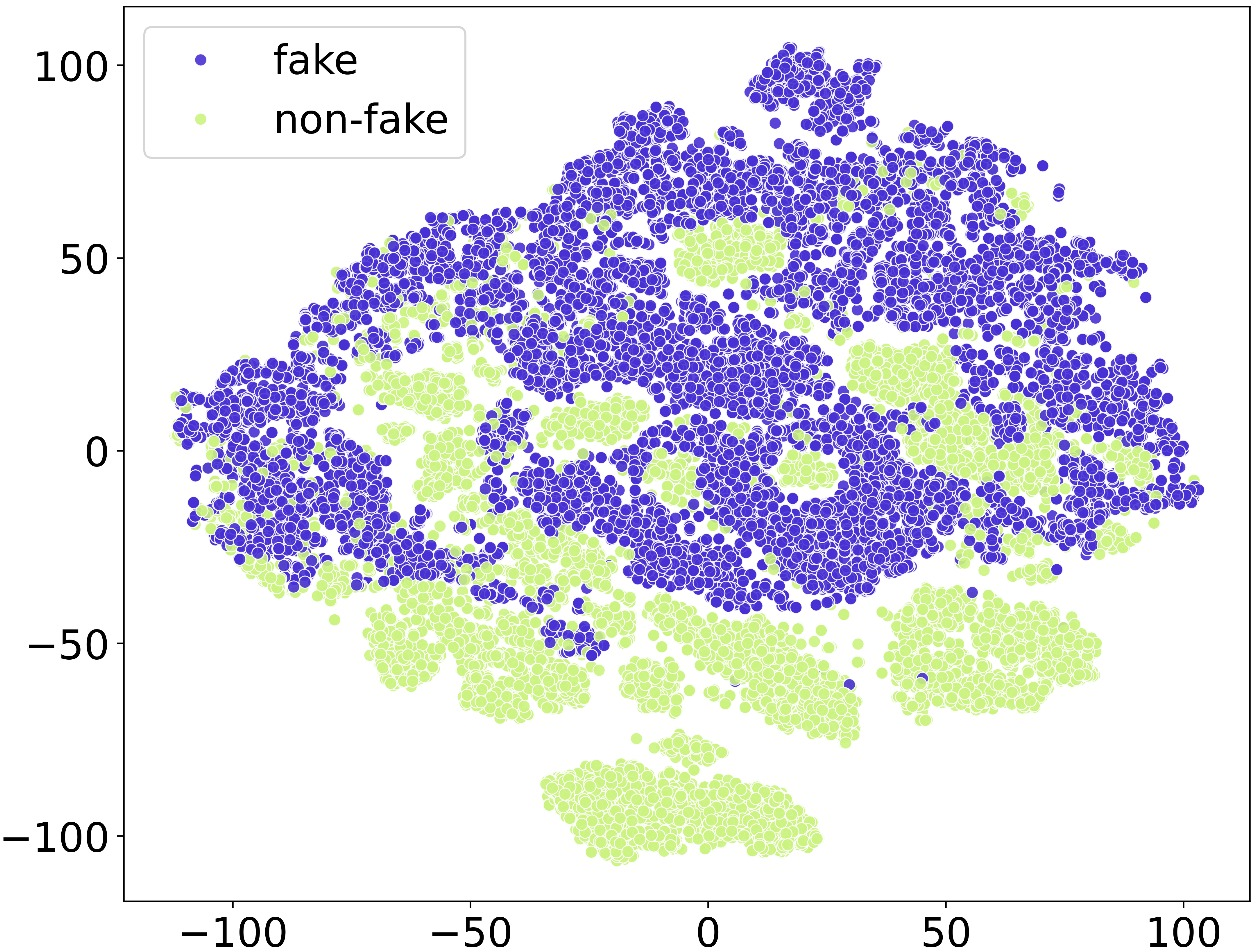
Figure 2: The subfigures (a) LB (b) IB (c) Wav2vec2 and (d) Whisper represent the t-SNE plot visualization.
Implications and Future Directions
The findings affirm that MFMs hold greater potential for advancing EFD technology by leveraging multimodal pre-training. SCAR's innovative nested cross-attention and self-attention refinement model not only surpasses standalone FM approaches but also sets a new standard for fusion methodologies in EFD. These advancements pave the way for future research, encouraging further exploration of MFMs' application in real-world scenarios, as well as the development of novel fusion strategies that could extend their applicability to other multimodal detection tasks.
Conclusion
Through comprehensive comparative analyses and the introduction of SCAR, the paper progresses towards establishing MFMs as essential tools for effective EmoFake detection. The demonstrated superiority of MFMs validates their cross-modal training advantage, enhancing emotional manipulation detection capabilities. SCAR's fusion strategy establishes a new SOTA, providing an instrumental benchmark for subsequent research efforts aimed at innovating EmoFake detection technologies.