- The paper introduces a decoding-level type alignment algorithm that infers SQL type constraints for LLM functions, ensuring well-typed query outputs.
- It demonstrates that applying type hints with constrained decoding reduces query latency by 53% and improves denotation accuracy by 7%.
- The system, implemented in BlendSQL, seamlessly integrates LLM-powered UDFs with multiple DBMS backends to support scalable hybrid reasoning.
Declarative Type-Constrained LLM Functions for Hybrid Reasoning
Introduction
The paper "Play by the Type Rules: Inferring Constraints for LLM Functions in Declarative Programs" (2509.20208) addresses the integration of LLM-powered operators into declarative query languages, focusing on the challenge of aligning LLM-generated outputs with the strict type and value constraints of database management systems (DBMS). The authors propose a decoding-level type alignment algorithm that infers constraints from SQL expression context, enabling efficient and accurate execution of hybrid queries that combine structured and unstructured data sources. The work is situated within the context of program synthesis for multi-hop reasoning, leveraging BlendSQL—a dialect that compiles to SQL and supports LLM functions for compositional reasoning.
BlendSQL: Program Representation and LLM Functions
BlendSQL extends SQL with user-defined functions (UDFs) powered by LLMs, denoted by double curly brackets. These functions, such as llmqa (reduce operation) and llmmap (map operation), allow for the integration of unstructured reasoning into SQL queries. The system supports multiple DBMS backends (SQLite, DuckDB, Pandas, PostgreSQL) and leverages temporary tables for intermediate results, facilitating scalable execution over large hybrid datasets.
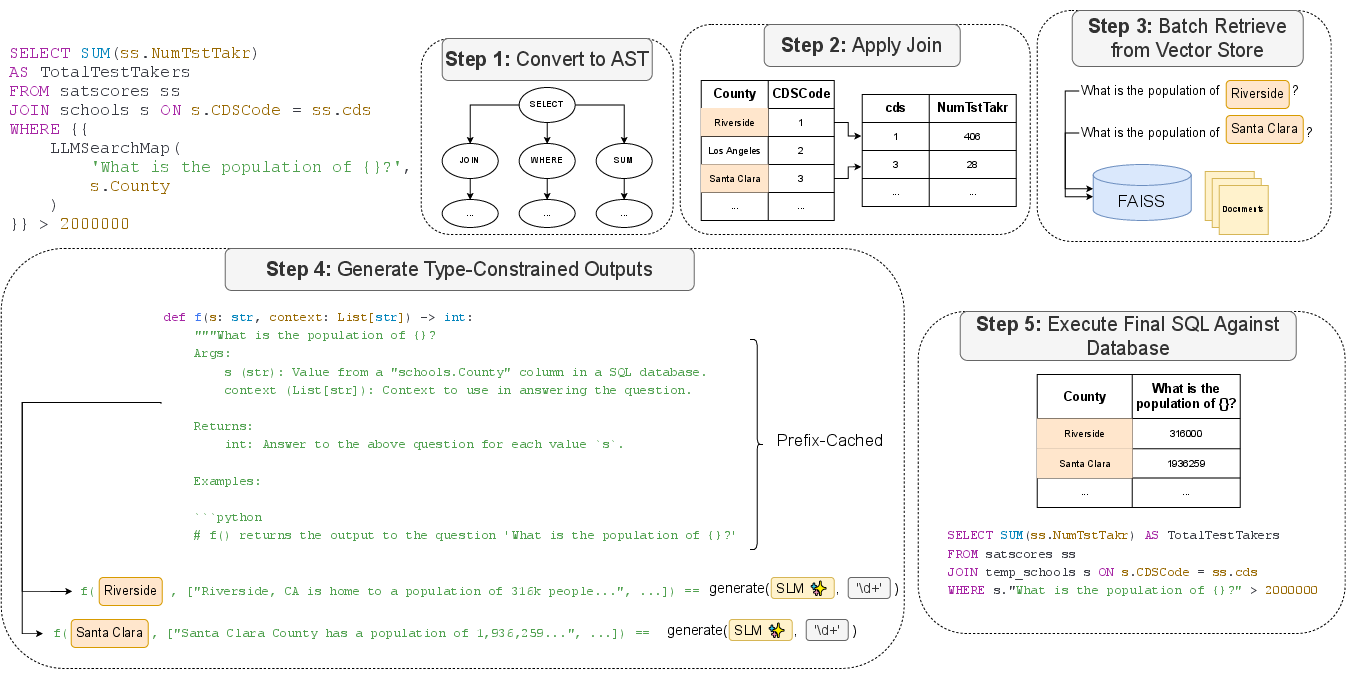
Figure 1: Execution flow of a map function, showing depth-first join execution and eager LLM function application with temporary table integration.
The query optimizer employs a rule-based cost model, assigning infinite cost to LLM functions to defer their execution until necessary. Queries are normalized to ASTs, traversed in SQL operator order, and transformed post-LLM execution to ensure syntactic and semantic validity.
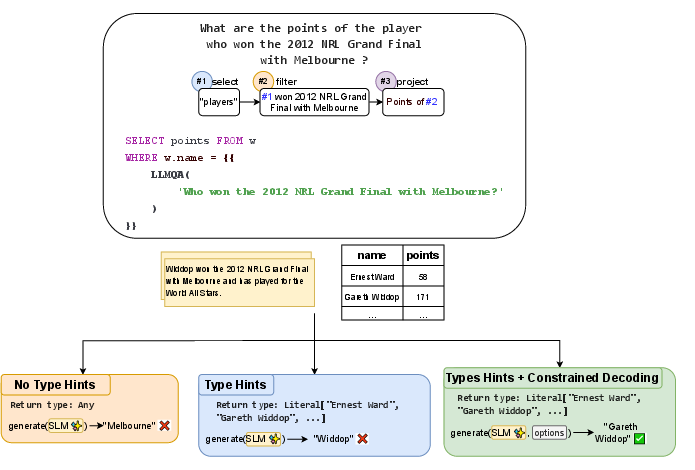
Type Constraint Inference and Decoding
A central contribution is the algorithm for inferring type constraints from SQL expression context. The system supports three modes:
Literal type constraints are supported by enumerating all distinct column values, enabling direct alignment between LLM outputs and database contents at generation time. This approach eliminates the need for post-processing LLM calls, reducing latency and improving throughput.
Experimental Evaluation
Efficiency and Expressivity
BlendSQL is benchmarked against LOTUS on the TAG-Bench dataset, which requires multi-hop reasoning over large tables (average 53,631 rows). On identical hardware (RTX 5080), BlendSQL achieves a 53% reduction in latency (0.76s vs. 1.7s) while maintaining expressivity with only two core LLM functions.
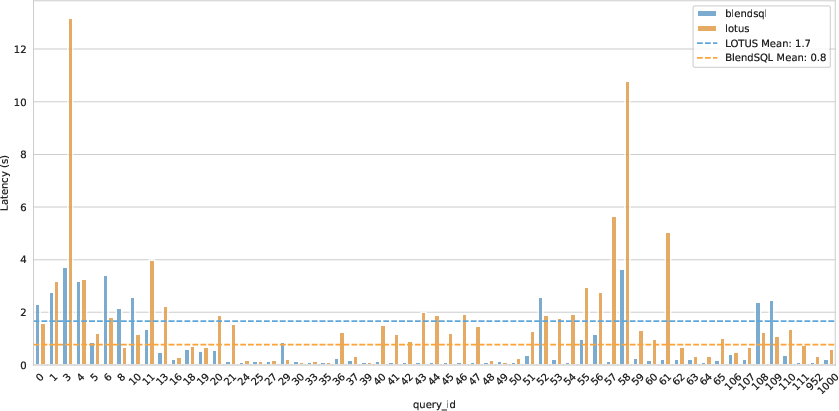
Figure 3: Sample-level latency of declarative LLM programs across question types on TAG-Benchmark.
HybridQA: Multi-Hop Reasoning
On HybridQA, which requires reasoning over both tables and Wikipedia text, the authors evaluate parsing and execution accuracy across Llama 3 and Gemma model variants. Programs are generated by a large model (70b) and executed by smaller models (1b, 3b, 8b, 12b), with type constraints enforced during execution.
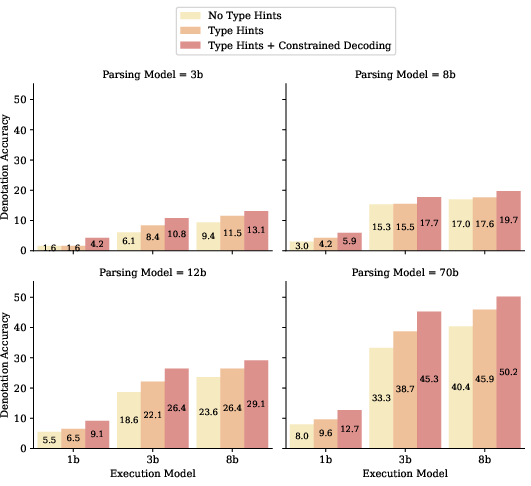
Figure 4: Impact of various typing policies on HybridQA validation performance across model sizes, showing denotation accuracy improvements with type constraints.
Type Hints + Constrained Decoding consistently outperforms other policies, yielding a 7% absolute improvement in denotation accuracy and robust gains across model sizes. Notably, a 3b executor achieves denotation accuracy comparable to an 8b model in RAG settings (45.3 vs. 45.6), despite execution errors on 10% of samples. These errors are categorized as syntax, column reference, or hallucination, and are amenable to rule-based correction or finetuning.
Constrained Decoding and Grammar Guidance
The authors implement context-free grammar (CFG) guidance using Lark and the Guidance framework to reduce syntactic errors during BlendSQL query generation. While CFG guidance decreases syntax errors, it does not consistently improve downstream semantic accuracy, especially for larger models. The primary bottleneck remains semantic alignment rather than grammaticality.
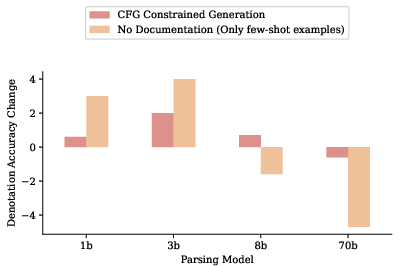
Figure 5: Impact of ablations for different parsing models, showing moderate gains for smaller models and decreased performance for larger models when removing documentation.
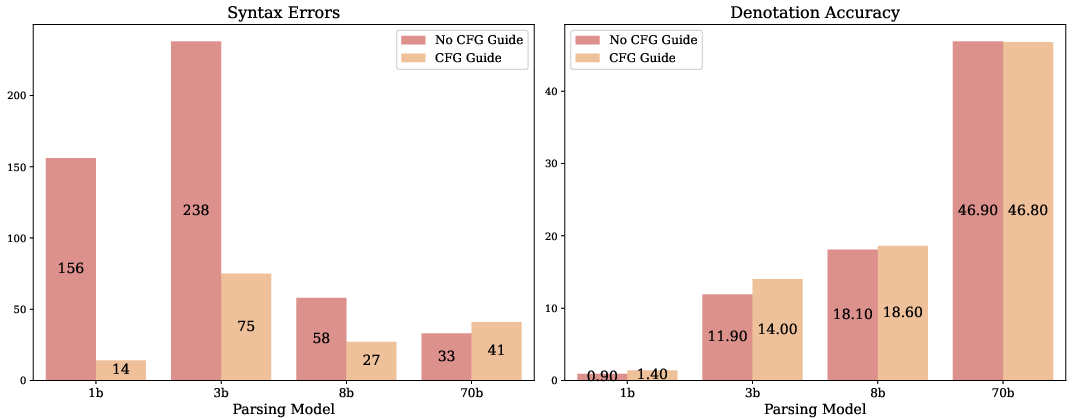
Figure 6: Decreasing syntax errors is not strongly correlated with improved downstream performance; semantic alignment is the key challenge.
Hyperparameter and Latency Analysis
The paper includes hyperparameter sweeps for vector search components and detailed runtime analysis, demonstrating the scalability of BlendSQL for large-scale hybrid QA tasks.
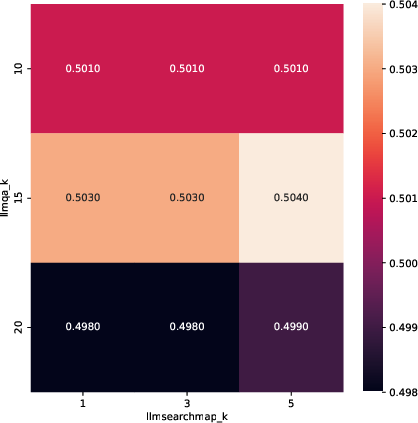
Figure 7: Hyperparameter sweeps for various settings of k in hybrid vector search components.
Implementation Considerations
- Computational Requirements: BlendSQL is optimized for low-latency execution on commodity hardware (single RTX 5080), with support for quantized models and prefix-caching for batch inference.
- Deployment: The system is DBMS-agnostic, supporting multiple backends and seamless integration with existing SQL workflows.
- Limitations: Execution errors due to syntax or semantic misalignment remain, especially for small models. CFG guidance mitigates syntax errors but does not address semantic issues.
- Scalability: The approach is suitable for large tables and hybrid contexts, with efficient vector search and temporary table management.
Implications and Future Directions
The proposed decoding-level type alignment algorithm enables efficient integration of LLM functions into declarative programs, reducing reliance on expensive post-processing and improving both accuracy and latency. The demonstrated utility of small models as function executors under type constraints suggests a path toward cost-effective hybrid reasoning systems. Future work may explore tighter semantic alignment, improved grammar guidance, and extension to other typed declarative languages beyond SQL.
Conclusion
This work presents a principled approach to inferring and enforcing type constraints for LLM functions in declarative programs, achieving strong empirical results in hybrid question answering and data analysis. The methodology supports efficient, scalable, and accurate execution of compositional queries over structured and unstructured data, with broad applicability to program synthesis and database-augmented LLM systems.