- The paper introduces SLAP, a novel model that aligns speech with natural language to extract speaker and health attributes using contrastive learning.
- It employs a Vision Transformer-based audio encoder and LLM-generated text features to overcome data imbalances with self-supervised and resampling techniques.
- The experiments demonstrate SLAP’s superior performance with up to 69.3% F1 score and robust zero-shot generalization for cross-linguistic and clinical tasks.
Introduction
The research paper "SLAP: Learning Speaker and Health-Related Representations from Natural Language Supervision" (2510.01860) explores an innovative model known as SLAP (Speaker contrastive Language-Audio Pretraining) that aligns speech with natural language to identify speaker and health-related attributes. The primary goal of SLAP is to facilitate zero-shot and out-of-distribution (OOD) generalization in tasks involving demographic information, voice characteristics, and clinical assessments. Despite significant advancements made by models such as Whisper and SALMONN in speech recognition, they fall short on speaker-centric tasks, particularly in the context of paralinguistic features and health markers.
SLAP leverages the CLAP (Contrastive Language-Audio Pretraining) framework by aligning audio with text descriptions using contrastive learning. This research breaks new ground by enabling the inference of speaker and health descriptors directly from natural language prompts, thereby overcoming limitations in current audio foundation models.
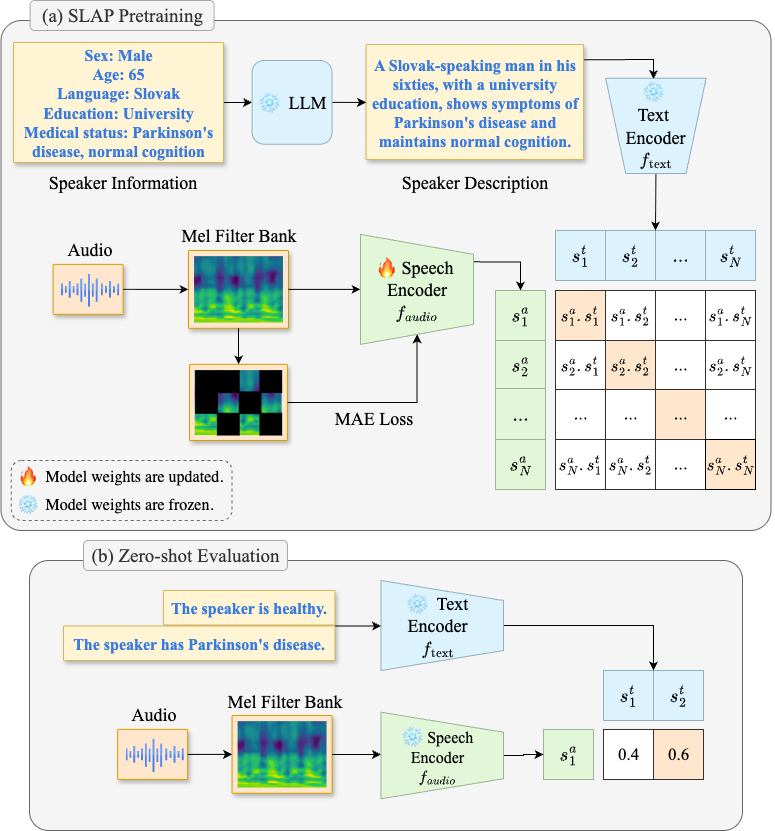
Figure 1: SLAP pipeline. (a) Pretraining. For each audio, an LLM generates a speaker description, and the Speech Encoder is trained with contrastive and self-supervised objectives. (b) Zero-shot Evaluation. A pair of text prompts are given to the Text Encoder. The class with the higher cosine similarity to the audio embedding is chosen.
Methodology
SLAP introduces Speaker Contrastive Language-Audio Pretraining, which uses a Vision Transformer (ViT) Audio Encoder and multiple Text Encoders. This model is trained on a vast dataset comprising more than 3400 hours of speech across nine datasets. Textual descriptions capturing speaker and health metadata are generated using a LLM and aligned with audio using a contrastive objective. The embeddings are learned using projection heads that map audio and text features into a shared d-dimensional space, and similarity is computed via cosine distance.
To mitigate data imbalance challenges during training, the paper describes resampling techniques and the use of masked autoencoder objectives for auxiliary self-supervised learning. For downstream inference, SLAP employs both supervised (via linear probing) and zero-shot approaches, leveraging sliding windows for variable-length audio samples.
Experiments
The effectiveness of SLAP is evaluated across a comprehensive set of 38 binary classification tasks across three primary categories: demographics, voice characteristics, and health. The model outperforms other state-of-the-art methods, notably achieving a 69.3% F1 score with fine-tuning and 62.9% F1 in zero-shot settings—a 48% relative improvement over the previous CLAP baseline.
Zero-shot and OOD generalization are key performance indicators, with SLAP outperforming baselines on cross-linguistic and health-specific tasks. The experiments underscore its potential for practical applications in healthcare monitoring and intervention, particularly for detecting mental health and neurological disorders.
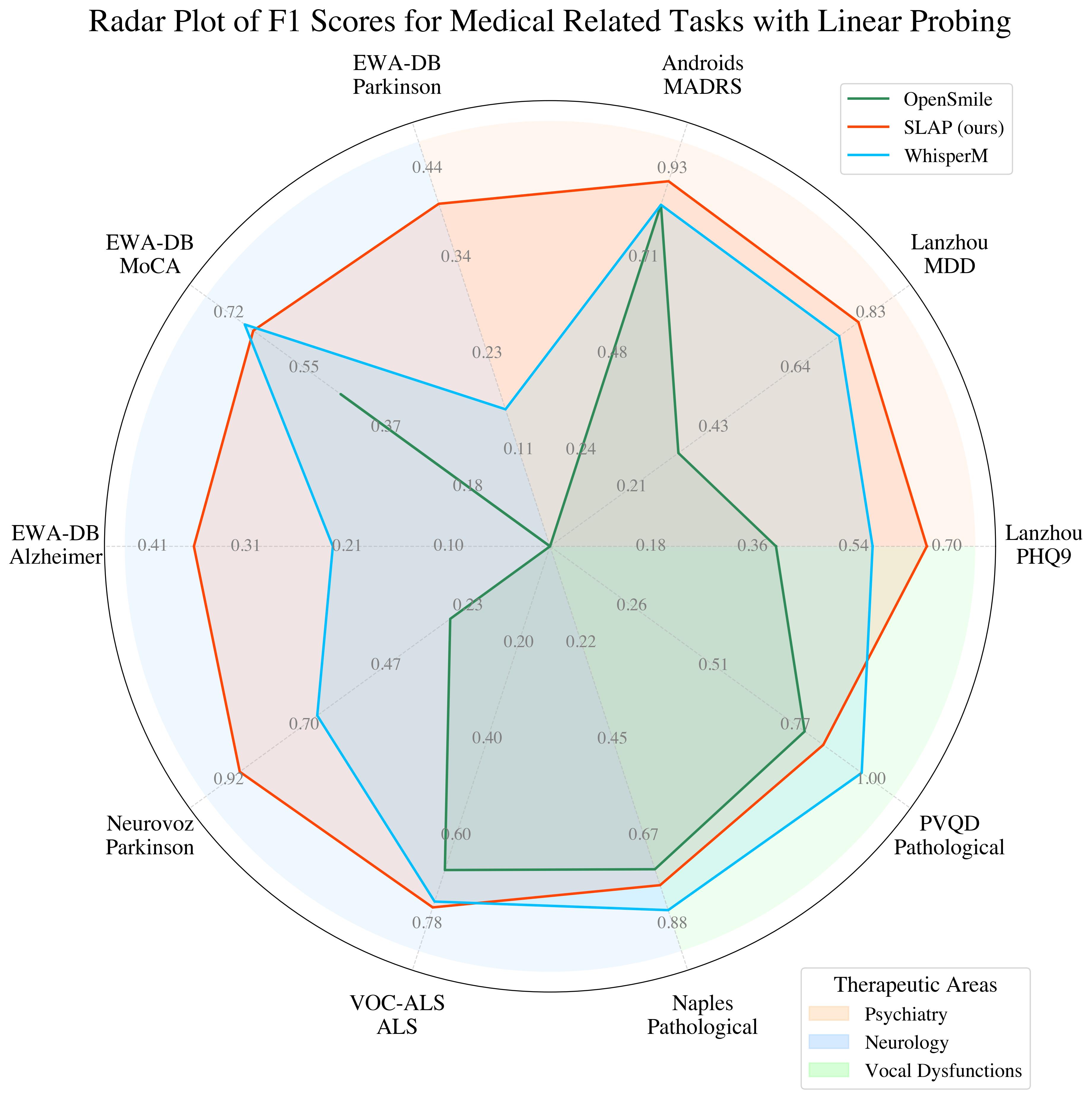
Figure 2: Performances on open source medical tasks. \F1 scores on psychiatry, neurology, and vocal dysfunctions.
Results and Discussion
SLAP significantly improves on existing benchmarks for speech representation tasks, particularly in health-related applications. It demonstrates robust performance in zero-shot scenarios by utilizing language supervision to generalize across unseen tasks, languages, and clinical populations. The combination of contrastive and self-supervised learning results in a model that is adaptable and robust, thereby fulfilling the clinical need for scalable, adaptable audio analysis tools.
The results emphasize SLAP’s superiority in extracting actionable insights from audio data, drawing a contrast with supervised models like Whisper and OpenSMILE, especially in zero-shot performance, where it approaches the accuracy of supervised settings.
Conclusion
SLAP represents a pivotal progression in audio-LLM capabilities by integrating contrastive pretraining with self-supervised objectives. Its ability to generalize across diverse speech and health tasks with limited task-specific data presents substantial implications for the deployment of speech-based analytic tools in real-world medical applications. Future research directions may explore expanding SLAP’s architectural framework to other linguistic or acoustic modalities, further enhancing its adaptability and utility across different domains.