- The paper introduces a benchmark mutation method that converts formal GitHub issues into realistic queries based on developer interactions.
- It employs telemetry data to capture concise, context-specific exchanges typical of real-world bug fixing and feature implementation.
- Experiments show that current benchmarks overestimate coding agent performance, highlighting the need for evaluations that mirror actual usage.
Benchmark Mutation for Realistic Evaluation of Coding Agents
Introduction
The paper "Saving SWE-Bench: A Benchmark Mutation Approach for Realistic Agent Evaluation" (2510.08996) addresses the discrepancy between traditional GitHub issue-based benchmarks and real-world user interactions with chat-based coding agents. By proposing a novel benchmark mutation methodology, the authors aim to transform formal benchmark problems into queries that better reflect actual developer behavior. This is accomplished through an empirical analysis of developer communications with chat-based agents, introducing a more realistic paradigm for evaluating interactive software engineering agents.
Methodology
The proposed methodology involves systematically mutating existing benchmark problems using insights drawn from real-world developer interactions captured via telemetry data. The process begins with the collection and categorization of user queries to chat-based coding agents, identifying patterns in bug-fixing communications. These patterns reveal a more concise, context-specific exchange of information, differing significantly from the lengthy, detailed problem descriptions typical of GitHub issues.
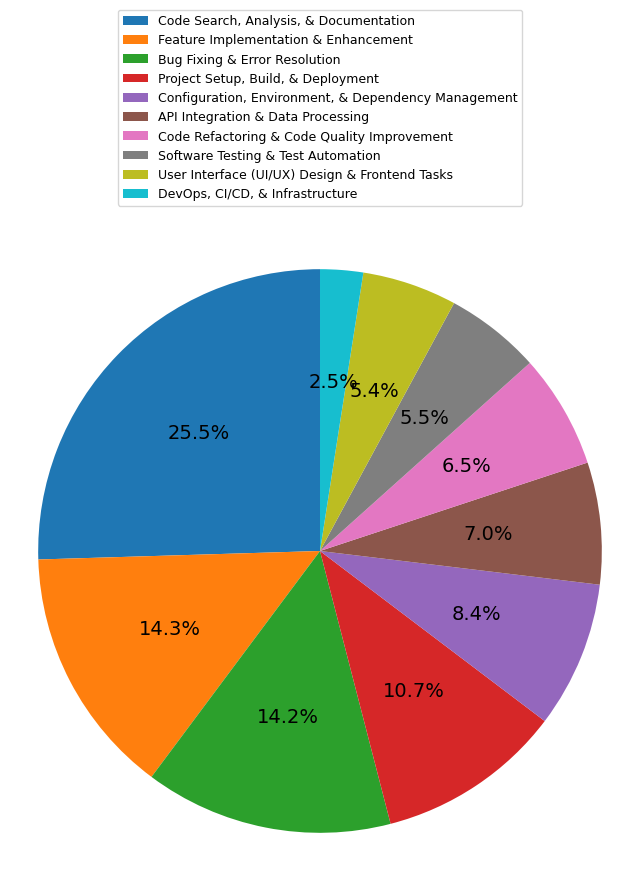
Figure 2: Distribution of High-Level categories in user queries to a coding agent. We can see that the top categories are Code Search, Analysis (Blue), Feature Implementation (Orange) and Bug Fixing (Green).
The authors employ a systematic benchmark mutation algorithm that applies these communication templates to transform formal problem descriptions into more realistic queries. This involves utilizing the characteristics of real user queries, such as error messages, stack traces, and targeted questions, while preserving the technical essence of the original problem statements.
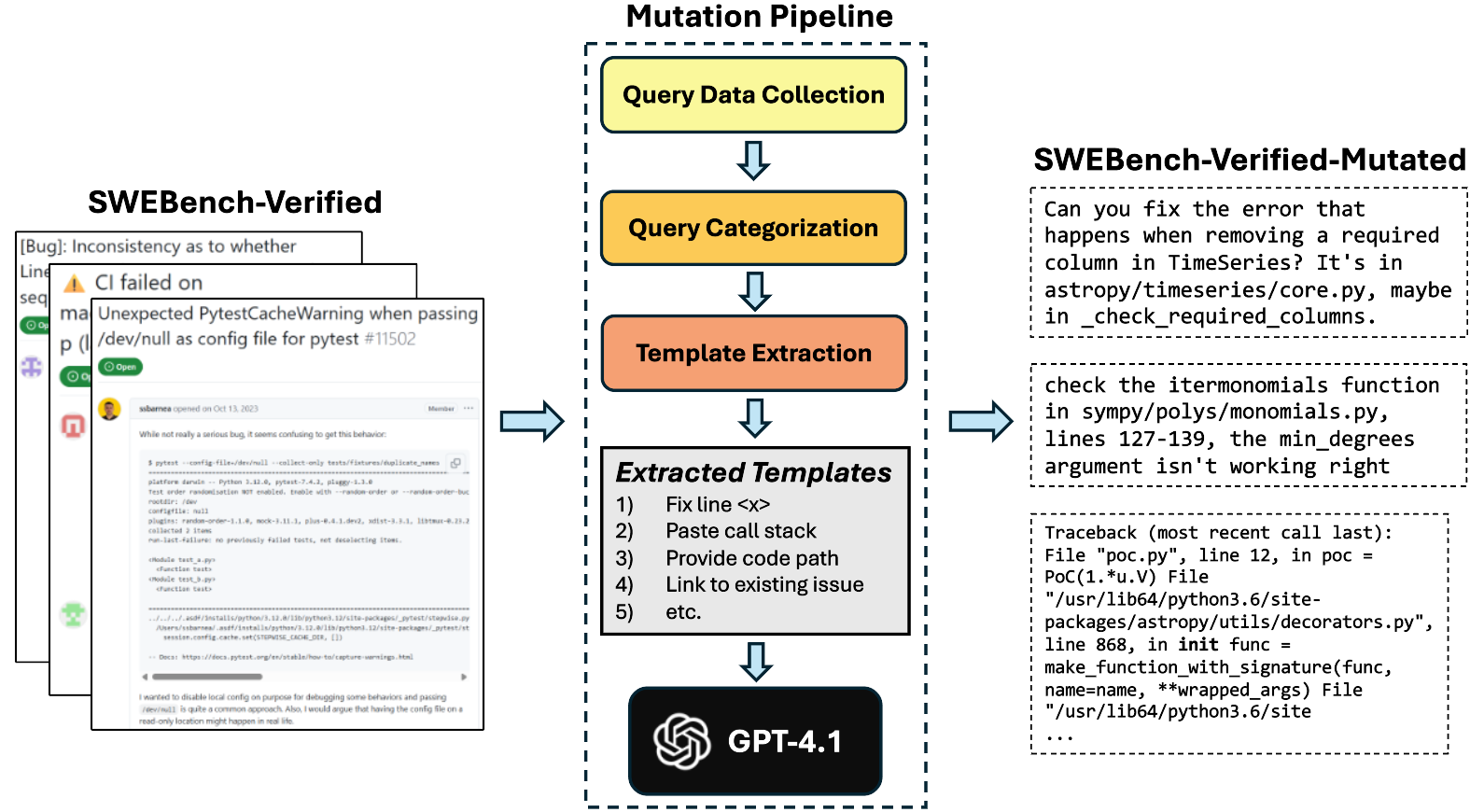
Figure 4: A high-level overview of our benchmark mutation approach.
The mutation process is validated through empirical analysis, including the visualization of mutated query embeddings against those of original benchmarks. The results indicate that the transformed queries more closely align with actual developer questions, demonstrating the method's efficacy in bridging the gap between traditional benchmarks and realistic agent evaluation scenarios.
Experiments and Results
The study evaluates the performance of the OpenHands agent on both original and mutated benchmarks across multiple languages. The success rates, computation steps, and token usage are compared to illustrate the impact of realistic query mutations on agent performance. The results show a significant decline in success rates when agents are faced with mutated, more realistic queries, highlighting the overestimation of agent capabilities in traditional benchmarks.
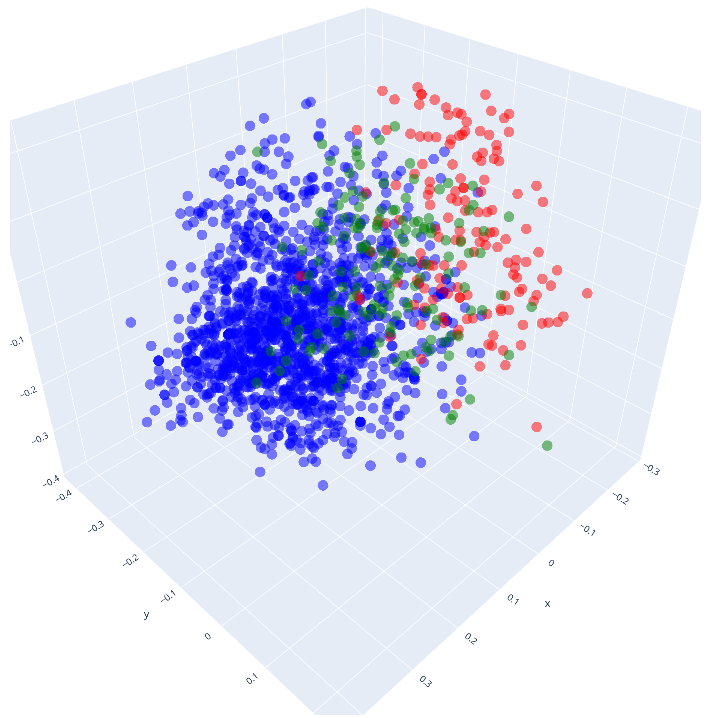
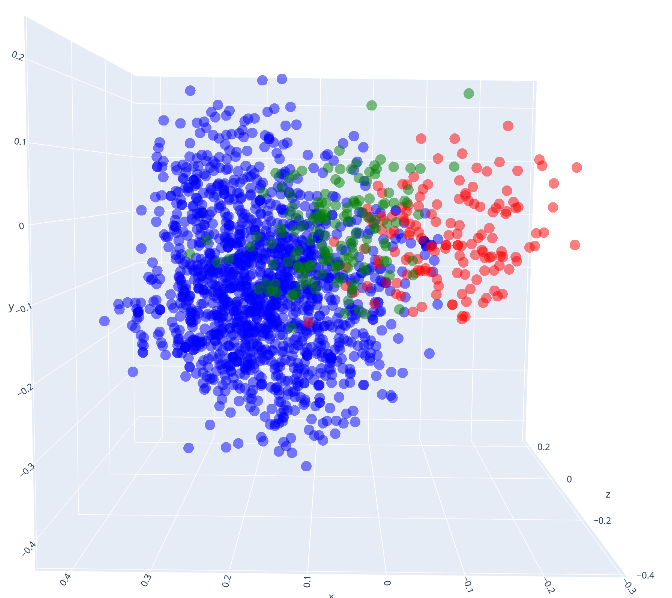
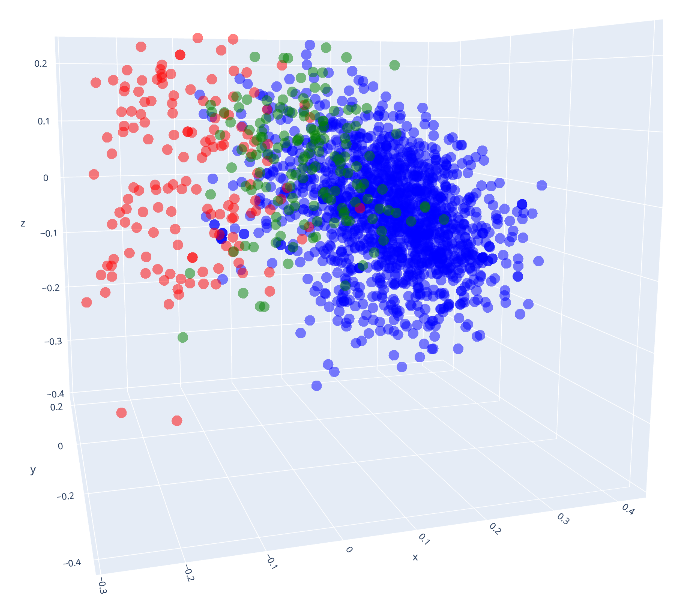
Figure 1: Views of point clouds corresponding to queries from different sources, after being embedded using OpenAI's text-embedding-3-large model. We can see that the queries corresponding to the mutated benchmark overlap more with the cloud corresponding to telemetry data.
The experiments underscore the necessity for benchmark methodologies that reflect real-world usage patterns. The detailed analysis provides concrete evidence that traditional benchmarks fail to capture the nuances of human-chat interactions within coding agent environments.
Implications and Future Directions
The introduction of a benchmark mutation approach presents a pivotal advancement in evaluating AI agents in software engineering. By aligning benchmarks with actual developer interactions, this method addresses the critical need for realistic agent assessments and mitigates the impact of overfitting seen in public benchmarks.
This work invites future developments in adaptive benchmarking for a broader range of tasks beyond bug fixing, encompassing diverse software engineering activities such as feature implementation or test automation. Additionally, the exploration of dynamic benchmark generation methods could further enhance the realism and robustness of AI agent evaluations.
Conclusion
This research establishes a foundational approach to transforming formal software engineering benchmarks into realistic user queries, fundamentally altering the landscape of AI agent evaluation. By highlighting the gaps in current methodologies and offering a tangible solution, the paper paves the way for more accurate assessments of agent capabilities in real-world scenarios. This innovative benchmark mutation framework marks a significant step toward closing the gap between theoretical evaluations and practical deployments of AI coding agents.
