- The paper presents a novel three-stage interpolation approach between Instruct and Thinking models that enhances LLM reasoning and efficiency.
- It demonstrates that the method outperforms traditional merging techniques, achieving a Mean@64 score of 80.5 on the AIME’25 benchmark.
- The approach allows precise tuning via a lambda parameter, balancing computation cost with reasoning quality and mitigating overthinking.
Revisiting Model Interpolation for Efficient Reasoning
Introduction
The paper "Revisiting Model Interpolation for Efficient Reasoning" explores a systematic approach to model interpolation exclusively between Instruct and Thinking models to enhance reasoning capabilities in LLMs efficiently. The authors challenge the existing paradigm by demonstrating how simple model interpolation, without necessitating complex pre-trained model pairs, can yield significantly superior reasoning performance over more sophisticated methodologies. This paper systematically revisits the traditional model merging strategy, providing in-depth analyses and empirical validations that establish model interpolation as a potent contender for efficient reasoning.
Model Interpolation Dynamics
The research introduces a comprehensive examination of model interpolation, revealing a novel three-stage evolutionary paradigm as weights transition between the Instruct and Thinking models. This dynamic is crucial as it provides a structured approach to managing performance-cost trade-offs.
Stage 1: The weights predominantly reflect the Instruct model, transitioning gradually with rapid output lengthening but minimal explicit reasoning. The mean token use increases as responses become verbose without substantial reasoning.
Stage 2: Exhibiting a significant transition, explicit thinking patterns emerge, marked by substantial gains in Mean@k metrics, even as Pass@k gains stagnate. This phase is characterized by a brief balance where both performance and reasoning efficiency peak.
Stage 3: Dominated by the Thinking model's traits, this phase sees continuous increases in token use without corresponding gains in reasoning efficacy, addressing the overthinking phenomenon where increased reasoning does not equate to better outcomes.
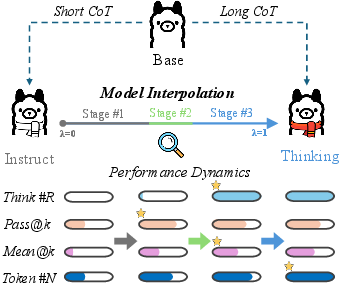
Figure 1: The performance dynamics for the model interpolation between Instruct and Thinking models. Token #N denotes the number of tokens in responses.
Comparative Analysis with Merging Baselines
Empirical comparisons highlight the superiority of the model interpolation (MI) method over state-of-the-art model merging approaches like Task Arithmetic and TIES-Merging. MI consistently outperforms in key metrics such as Mean@k and Pass@k across challenging benchmarks, indicating its practical efficacy.
Performance: For instance, MI-0.8 achieves a Mean@64 score of 80.5 on the AIME’25 math benchmark, significantly higher than the best Task Arithmetic baseline.
Efficiency: MI outperforms baseline methods in maintaining lower token use due to its controlled reasoning expansion, achieving a better performance-cost ratio.
Controllability: The MI approach allows for a smooth tuning of reasoning behavior through λ, proving its practical utility by precisely balancing reasoning quality and token efficiency.
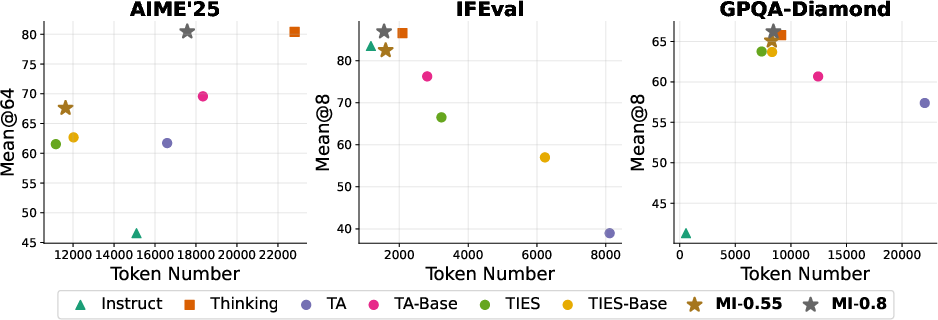
Figure 2: Performance of vanilla Instruct, Thinking, and model merging methods on AIME'25, IFEval, and GPQA-Diamond, showing superiority of MI.
Implementation Insights
The MI approach is computationally straightforward yet powerful, allowing it to merge weights from distinct LLM variants without needing base models. By interpolating model weights directly, MI simplifies the process, offering considerable flexibility in implementation. Various LLMs can benefit from this, as evidenced by its successful application beyond the Qwen3 series, like with models such as Qwen3-30B-A3B.
Decoding Strategies and Module Ablations
The study further explores the robustness of MI models against decoding parameters, showing minor performance variance under different temperature and Top-p settings, which simplifies operational concerns. Through ablation studies focused on specific model sub-layers (MHA and FFN), it is demonstrated that FFN sub-layers primarily drive CoT reasoning, confirming their critical role in reasoning tasks.
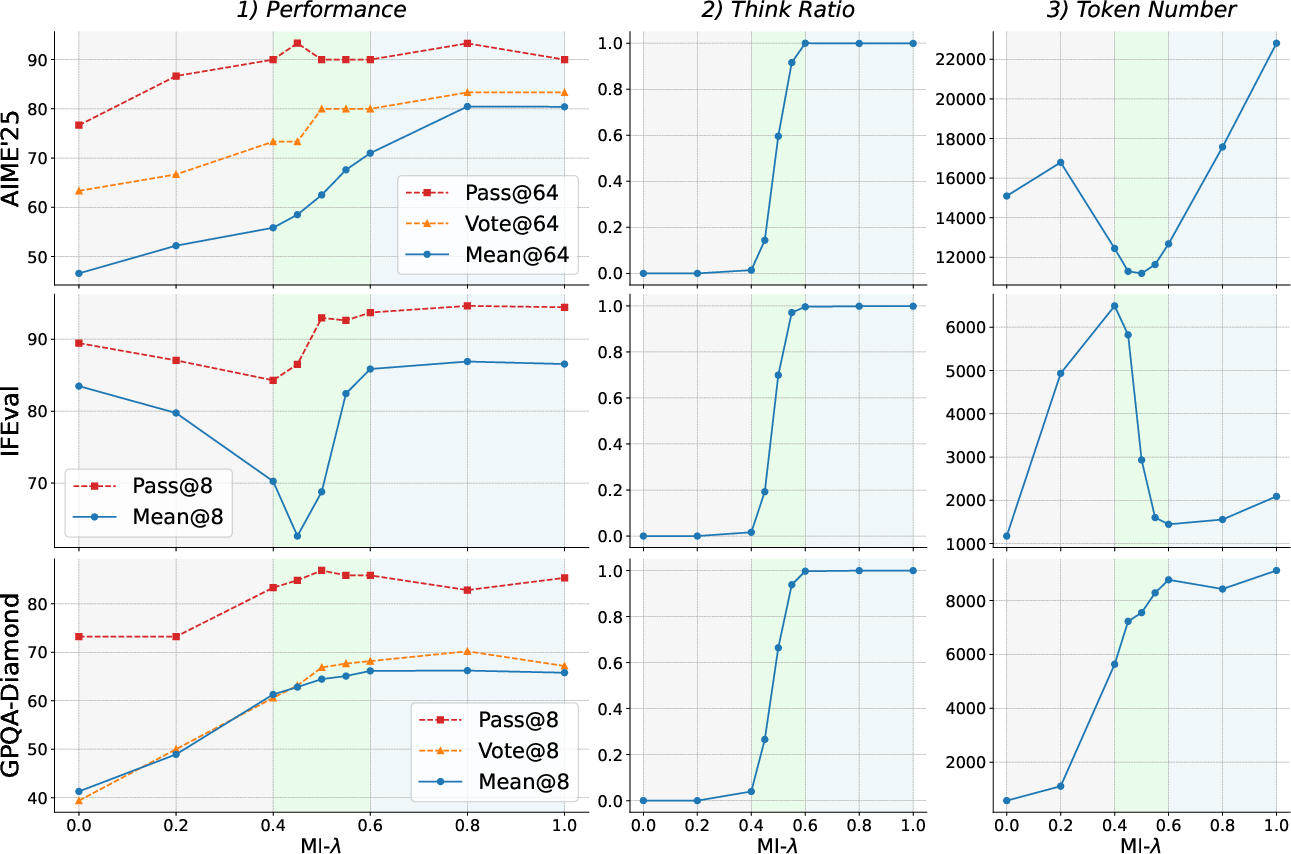
Figure 3: The performance dynamics of model interpolation~(MI) on Qwen3-4B models, illustrating the evolutionary paradigm.
Conclusion
This paper provides valuable insights into the efficiency of reasoning in LLMs, demonstrating that strategic model interpolation is not only feasible but also highly effective. By unraveling the framework into a three-stage evolutionary paradigm, it offers predictive power for handling computation-resource trade-offs. The extensive experimental results and insights pave the way for more robust and controlled reasoning in AI systems, setting the stage for broader adoption of interpolation techniques across diverse model architectures. Future work may extend these findings to even broader contexts, potentially involving multiple model interpolations or different model families.