- The paper introduces a framework that quantifies excessive repetition (‘slop’) in LLM outputs using frequency analysis and pattern fingerprinting.
- It proposes the Antislop Sampler for real-time suppression with backtracking and configurable probability adjustments during decoding.
- FTPO fine-tunes models by optimizing logit gaps, achieving 85–92% suppression of slop patterns with less than 1% loss in writing quality.
Antislop: A Comprehensive Framework for Identifying and Eliminating Repetitive Patterns in LLMs
Introduction and Motivation
The proliferation of LLMs has led to the emergence of highly characteristic repetitive phraseology—termed "slop"—which degrades output quality and renders AI-generated text easily identifiable. Empirical analysis reveals that certain patterns, such as specific character names and clichéd sensory descriptions, occur up to 103–105 times more frequently in LLM outputs than in human-authored text. This overrepresentation is not limited to surface-level repetition but extends to deep stylistic biases, impacting both creative and functional writing domains. Existing suppression methods, including token banning and instruction-based avoidance, suffer from collateral damage, limited efficacy, and lack of scalability.
Forensic Analysis of Slop Patterns
The paper introduces a robust pipeline for quantifying slop by comparing n-gram and word frequency distributions between LLM outputs and human baselines. The slop fingerprinting process leverages large-scale generation from creative writing prompts and computes frequency ratios ρ(p)=fLLM(p)/fhuman(p) for each pattern. This enables model-specific profiling and clustering of overused patterns, revealing both intra-family similarities and inter-family divergences.
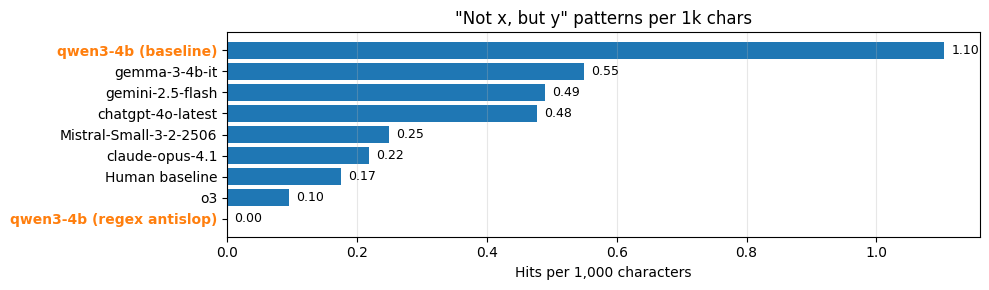
Figure 1: Occurrences per 1k characters of the "not x, but y" family across several models. The Antislop variant of qwen3-4b enforces regex bans with backtracking and yields 0.00 hits.
The Antislop Sampler: Inference-Time Suppression
The Antislop Sampler is a decoding-time intervention that detects banned patterns—words, phrases, or regex-defined constructions—in the inference trace. Upon detection, it backtracks to the first token of the offending sequence, reduces its probability by a configurable ban-strength parameter s, and resamples using min-p filtering to maintain coherence. This mechanism supports both hard and soft bans, allowing for context-sensitive suppression and avoiding the destructive side effects of token-level banning.
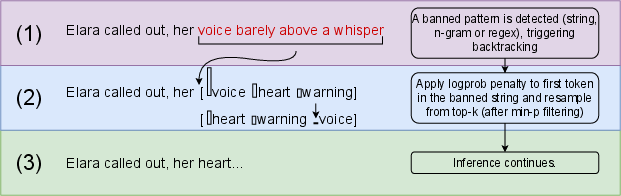
Figure 2: The Antislop backtracking mechanism detects unwanted patterns in the inference trace, backtracks to the first token of the banned sequence, lowers its probability, then resamples.
The sampler is implemented for both HuggingFace Transformers and OpenAI-compatible vLLM endpoints, supporting production-scale deployment. However, throughput is significantly reduced (up to 96% at large banlist sizes), motivating the need for a training-based solution.
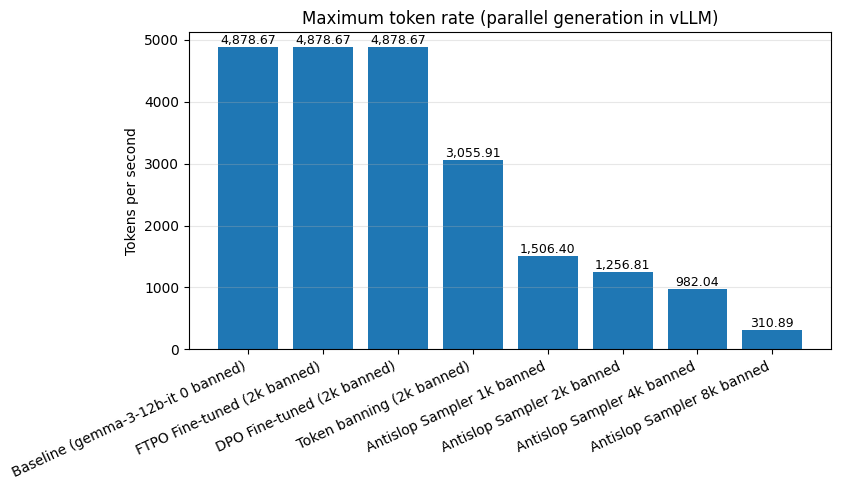
Figure 3: Rate of inference is measured for each method when generating with optimal parallelism with vLLM.
Final Token Preference Optimization (FTPO): Training-Time Suppression
FTPO is a fine-tuning algorithm designed to surgically suppress slop patterns with minimal collateral damage. Unlike DPO, which is prone to diversity collapse and output degradation, FTPO operates on final-token preference pairs, optimizing the logit gap between chosen alternatives and rejected (slop-initiating) tokens. The loss function comprises:
- Preference loss with margin: Encourages chosen tokens to exceed the rejected token's logit by a margin m, with automatic gradient deactivation when the margin is achieved.
- Target regularization: MSE loss on chosen and rejected logits, with a zero-penalty window τtarget.
- Non-target regularization: Strong MSE tethering of the remaining vocabulary to reference logits, preventing distribution drift.
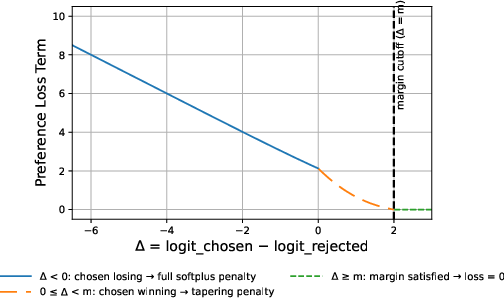
Figure 4: Preference loss component as a function of the logit gap Δ. When Δ<0 (chosen losing), the penalty is large. As Δ increases toward the margin m, the penalty smoothly tapers. Once Δ≥m, the weight goes to zero and the preference loss no longer contributes.
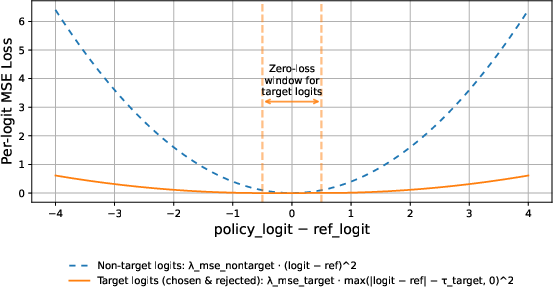
Figure 5: MSE loss components as functions of logit deviation from the reference. The non-target term penalizes any deviation quadratically. The target term allows a dead zone around zero, where no penalty applies, then grows quadratically once the deviation exceeds the zero-penalty window.
FTPO's design ensures that only the necessary logits are adjusted, with self-limiting updates and strong regularization, enabling high preference accuracy without model collapse.
Automated Pipeline and Data Generation
The Antislop Sampler is leveraged to generate training data for FTPO. At each backtracking event, a preference pair is recorded: the rejected token and a set of viable alternatives. This enables fully automated, model-specific slop suppression pipelines without human annotation.
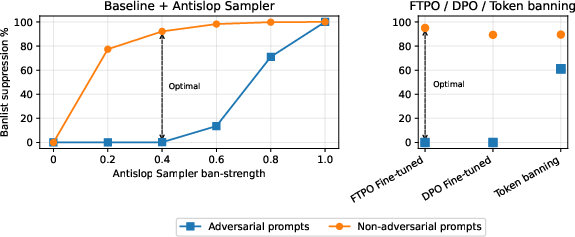
Figure 6: Our methods can suppress 90+ percent of banlist occurrences while allowing the banlist through when contextually necessary. Antislop Sampler, FTPO, DPO and token banning are compared on banlist suppression efficacy under normal writing conditions (non-adversarial prompts) and when the model is explicitly instructed to use the banned vocab (adversarial prompts).
Experimental Evaluation
Suppression vs. Quality Tradeoff
FTPO achieves 85–92% suppression of slop patterns with <1% loss in writing quality, outperforming DPO (80–82% suppression, 6–15 point quality degradation) and token banning (catastrophic collapse at large banlists). The Antislop Sampler achieves perfect suppression with improved quality but is limited by throughput.
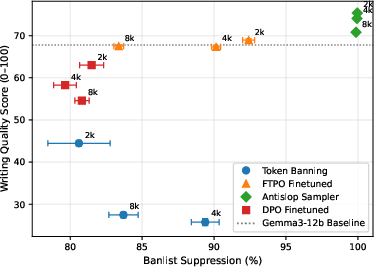
Figure 7: FTPO achieves 90% slop suppression with minimal quality loss, outperforming DPO and token banning. The figure evaluates four suppression methods on gemma-3-12b across banlist sizes of 2k, 4k, and 8k patterns. FTPO maintains baseline writing quality while suppressing 85-90% of unwanted patterns. In contrast, DPO degrades quality by 6-15 points despite achieving only 80-82% suppression. Token banning shows catastrophic quality collapse. Error bars show 95% confidence intervals.
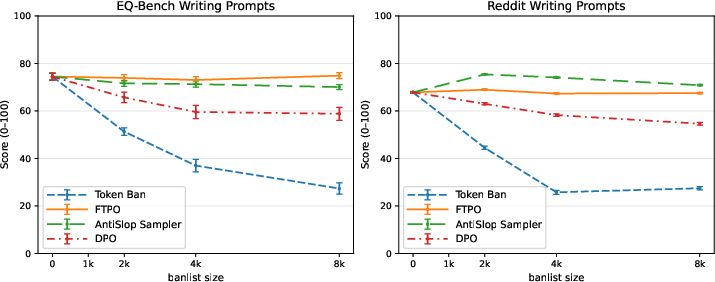
Figure 8: Impact on writing quality per our LLM-judged rubric at several banlist sizes, for each suppression method (Token banning, FTPO, Antislop Sampler and DPO).
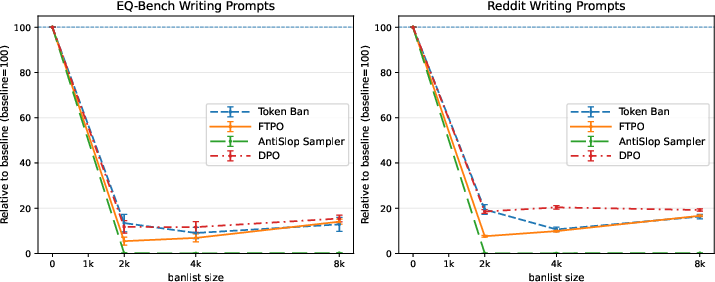
Figure 9: Impact on banlist suppression rates at several banlist sizes, for each suppression method (Token banning, FTPO, Antislop Sampler and DPO).
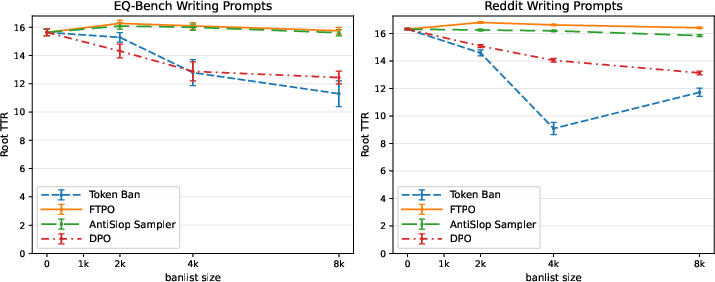
Figure 10: Impact on lexical diversity at several banlist sizes, for each suppression method (Token banning, FTPO, Antislop Sampler and DPO).
Robustness to Overtraining
FTPO can be trained to near-perfect preference accuracy without degradation, while DPO degrades sharply beyond 40% accuracy. FTPO's margin-based deactivation and logit-space regularization are critical for stability.
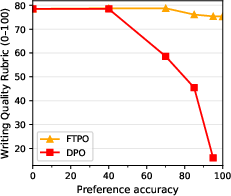
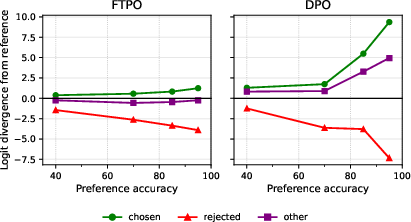
Figure 11: FTPO maintains writing quality as training progresses to higher pref accuracies, while DPO degrades sharply after the 40% accuracy mark. This experiment trains gemma-3-12b on a banlist of 1,000 items.
Hyperparameter Ablations
Ablation studies confirm the necessity of margin clipping and target MSE regularization. Disabling these features leads to model collapse and severe output degradation.
Regex and Long-Range Pattern Suppression
The Antislop Sampler supports regex-based bans, enabling suppression of variable sentence-level constructions. This is demonstrated for the "not x, but y" family, achieving zero occurrences post-intervention.
Implementation Considerations
- Computational Overhead: The Antislop Sampler incurs significant throughput penalties due to frequent backtracking, especially with large banlists. FTPO fine-tuning is preferred for production deployment.
- Scalability: FTPO supports banlists up to 8,000 patterns with negligible quality loss, whereas token banning fails beyond 2,000.
- Generalization: FTPO preserves performance on GSM8K, MMLU, and longform writing, with minimal impact on lexical diversity.
- Deployment: The framework is released under MIT license, with code and datasets available for reproducibility.
Implications and Future Directions
The Antislop framework provides a scalable, automated solution for mitigating stylistic degeneration in LLMs. Its modular design enables domain-specific adaptation and integration into existing inference and training pipelines. The demonstrated superiority of FTPO over DPO for targeted suppression tasks suggests broader applicability for surgical behavior modification in LLMs. Future work should explore extension to other domains, human-rater validation, and integration with AI-text detection systems.
Conclusion
Antislop introduces a comprehensive framework for identifying and eliminating repetitive patterns in LLM outputs. The Antislop Sampler enables inference-time suppression with backtracking and soft/hard ban control, while FTPO provides a training-time solution with precise logit-space optimization and robust regularization. Empirical results demonstrate that FTPO achieves high suppression rates with minimal quality loss, outperforming existing methods. The open-source release facilitates adoption and further research into stylistic alignment and degeneration mitigation in generative models.

