- The paper introduces Time-R1, a novel framework that employs a three-stage RL curriculum to build robust temporal reasoning in LLMs.
- It leverages a dynamic, rule-based reward system and curriculum learning to fine-tune comprehension, prediction, and creative generation skills.
- Empirical results show that its moderate-sized (3B) LLM outperforms models over 200 times larger on advanced future event prediction and creative scenario generation benchmarks.
Time-R1: A Deep Dive into Comprehensive Temporal Reasoning in LLMs
The paper "Time-R1: Towards Comprehensive Temporal Reasoning in LLMs" (2505.13508) introduces Time-R1, a novel framework designed to equip LLMs with robust temporal intelligence. The core innovation lies in a three-stage @@@@1@@@@ (RL) curriculum, driven by a meticulously crafted dynamic reward system, that progressively builds understanding, prediction, and creative generation capabilities within a moderate-sized (3B-parameter) LLM. Time-R1 demonstrates superior performance compared to models over 200 times larger, including the state-of-the-art DeepSeek-R1, on challenging future event prediction and creative scenario generation benchmarks. Additionally, the authors release Time-Bench, a large-scale multi-task temporal reasoning dataset, and a series of Time-R1 checkpoints to foster further research.
Background and Motivation
LLMs often struggle with temporal reasoning due to architectural limitations, the static nature of training corpora, and the non-chronological training process. Existing methods typically target isolated temporal skills, such as question answering about past events or basic forecasting, and exhibit poor generalization. Time-R1 addresses these limitations by endowing a moderate-sized LLM with comprehensive temporal abilities: understanding, prediction, and creative generation.
Time-R1 Framework
The Time-R1 framework consists of three stages (Figure 1):
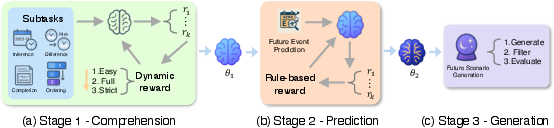
Figure 1: Overview of the Time-R1 framework. % for comprehensive temporal reasoning.
- Stage 1 - Comprehension: Reinforcement learning (RL) fine-tuning using pre-cutoff data from a cold start on four fundamental temporal tasks to develop logical mappings between events and their corresponding times.
2. Stage 2 - Prediction: Further training to predict events occurring after the knowledge cutoff, thereby teaching it to utilize general reasoning ability built in Stage 1 to extrapolate trends and anticipate future outcomes.
3. Stage 3 - Generation: Directly generating logical future scenarios without fine-tuning, leveraging the capabilities obtained from the first two stages.
Reinforcement Learning Fine-tuning
The approach employs reinforcement learning (RL) to fine-tune a LLM for complex temporal reasoning tasks. Given a prompt x detailing a specific temporal task, the LLM, parameterized by θ, generates an output sequence y autoregressively according to its current policy πθ(y∣x)=t=1∏∣y∣πθ(yt∣x,y<t). The environment evaluates the output y using a task-specific dynamic reward function R(x,y). To optimize the policy parameters θ, the authors utilize Group Relative Policy Optimization (GRPO). GRPO calculates the advantage of a generated response relative to other responses sampled for the same input prompt. The per-sample clipped objective term is:
LkCLIP(θ)=min(rk(θ)A^(x,yk),clip(rk(θ),1−ϵ,1+ϵ)A^(x,yk)).
The overall objective function $J_{\text{GRPO}(\theta)$ maximized during training balances the expected clipped advantage with a KL-divergence penalty against the reference policy $\pi_{\text{ref}$:
$\max_{\theta} J_{\text{GRPO}}(\theta) = \mathbb{E}_{x \sim \mathcal{D}, \{y_k\} \sim \pi_{\text{ref}} \left[ \frac{1}{K} \sum_{k=1}^K L_k^{\text{CLIP}}(\theta) \right] - \beta\,\mathbb{E}_{x\sim\mathcal{D}} \mathbb{D}_{\mathrm{KL}} \left[\pi_\theta(\cdot\mid x)\;\|\; \pi_{\text{ref}}(\cdot\mid x)\right]$.
Stage 1 Details
The primary goal of this initial stage is to establish a robust foundation for temporal comprehension within the LLM. A specialized dataset derived from a large corpus of New York Times (NYT) news articles is constructed, and data instances are tailored to four specific and fundamental temporally-focused subtasks:
(1) Timestamp Inference, (2) Time-Difference Estimation, (3) Event Ordering, and (4) Masked Time Entity Completion. The model is prompted to infer each event's date first and then give a task-specific answer for every subtask except the first, which prevents the model from merely guessing the final answer implicitly.
Stage 2 Details
After obtaining the foundational capabilities developed in Stage 1, the objective of Stage 2 is to further train the model to predict the timing of future events occurring after its initial knowledge cutoff (2023). This involves teaching the model to recall relevant and similar events in the past and their occurrence dates, extrapolate learned temporal development patterns and anticipate future event occurrences based on emerging, post-cutoff information. The training dataset is meticulously constructed to facilitate fair evaluation and strictly prevent data leakage from the test period. The model predicts the specific date t for a news event E based on its extracted headline h and abstract a.
Stage 3 Details
In the final stage, the model is leveraged to directly generate plausible, diverse, and temporally coherent future scenarios. This moves beyond predicting specific event times to creatively generating descriptions of hypothetical events given a specific future date. This stage utilizes the model checkpoint θ2, obtained from Stage 2, exclusively for inference without any further RL fine-tuning. The process involves three sequential steps: future news generation, diversity-based filtering, and plausibility evaluation against real news.
Reward Function
A meticulously engineered reward function, R(x,y), underpins the success of the Time-R1 framework. The reward function R(x,y) serves as the primary training signal guiding the policy optimization process. A rule-based dynamic reward system assesses the correctness and quality of the model's generated output y given the prompt x. The final scalar reward R(x,y)∈[−0.8,1.1] incorporates several components: task-specific accuracy ($R_{\text{acc}$), format rewards ($R_{\text{format}$), and penalties ($P_{\text{penalty}$). A dynamic reward mechanism is employed specifically during the Stage 1 RL fine-tuning process. This mechanism utilizes curriculum learning principles by adaptively adjusting the decay coefficient α used in the date accuracy reward component based on data difficulty and training progression.
Experimental Results
Stage 1: Foundational Temporal Reasoning
The effectiveness of Stage 1 fine-tuning is demonstrated by the training dynamics in Figure 2 and the final scores in Table 1.
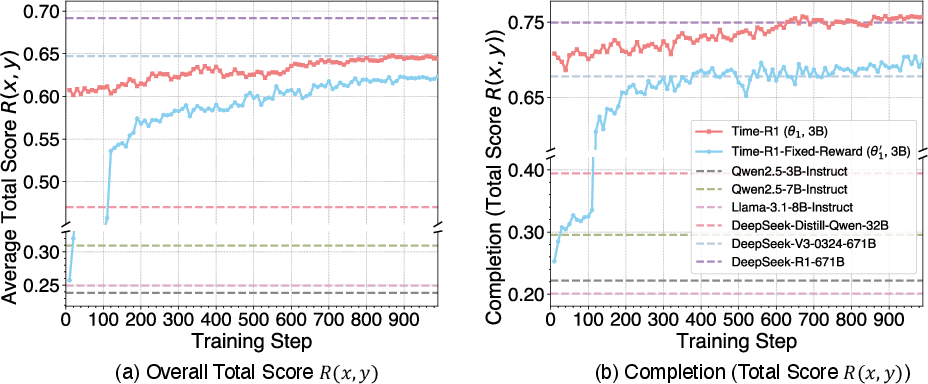
Figure 2: Stage 1 Training Performance vs. ,Baselines. Training curves for Time-R1 (theta_1) and its ablation variant, Time-R1-Fixed-Reward (theta_1'), evaluated against baseline models (indicated by horizontal dashed lines). Plot (a) shows the Overall Total Score across all subtasks, while plot (b) presents the Masked Time Entity Completion subtask. The solid lines demonstrate our models' scores improving throughout the training process, ultimately surpassing the performance levels of most baseline models, including those with significantly larger scales.
Table 1 highlights the substantial benefits of the Stage 1 RL fine-tuning, with Time-R1 demonstrating a remarkable improvement in its overall average score and outperforming the much larger DeepSeek-V3-0324-671B model.
Stage 2: Future Event Time Prediction
Stage 2 equips models to predict event timing post-knowledge cutoff (2023). Performance is compared against baselines for August 2024 - February 2025 predictions.
The overall Stage 2 performance is presented in Table 2. The DS-Qwen-32B model, despite its scale and specialized complex reasoning training, scores lower than some 3B models lacking such enhancements, underscoring the inherent difficulty of learning extrapolation and handling post-cutoff data. The primary model, Time-R1, achieves the highest score.
Stage 3: Creative Scenario Generation Quality
Table 3 presents AvgMaxSim scores, quantifying the semantic plausibility of generated news scenarios against real news events (August 2024 - February 2025).
Time-R1 achieves the highest overall AvgMaxSim score, surpassing all baseline models, including the very large DeepSeek-V3-0324-671B and DeepSeek-R1-671B. Monthly scores for Time-R1 also reveal consistently strong performance.
Ablation Studies
The paper includes ablation studies to validate the contribution of the reward design. The full Time-R1 model consistently outperforms the Time-R1-Fixed-Reward ablation variant, underscoring the importance of the dynamic curriculum. The benefits of the full curriculum are also highlighted, with the Time-R1 model (S1+S2 training) significantly outperforming the Time-R1-S2-Direct model (S2 training only).
Discussion
The paper explores a detailed analysis of the proposed methodology, focusing on the impact of the reasoning process on response length, and the challenges standard LLMs face in advanced temporal tasks. The dynamic reward mechanism achieves both higher accuracy and greater conciseness. Standard LLMs are substantially challenged when faced with more advanced temporal tasks requiring extrapolation and nuanced future-oriented generalization.
Conclusion
The paper introduces Time-R1, a 3B-parameter LLM achieving comprehensive temporal reasoning through a three-stage reinforcement learning curriculum with a dynamic reward system. Time-R1 outperforms models over 200 times its size on challenging future event prediction and creative scenario generation tasks. The authors release their Time-Bench dataset and Time-R1 model checkpoints, envisioning future work on scalability and enhanced reasoning integration.