- The paper critically evaluates how bypassing supervised fine-tuning in R1-Zero-like training uncovers inherent pretraining biases and presents Dr. GRPO as a solution.
- It employs empirical analysis on models like Qwen2.5 and DeepSeek-V3-Base, demonstrating how template application and inherent model traits influence reasoning and RL performance.
- The study highlights emergent model behaviors such as self-reflection and provides actionable insights for refining RL-based training of large language models.
Understanding R1-Zero-Like Training: A Critical Perspective
Introduction
This paper presents a critical examination of R1-Zero-like training, emphasizing its application to LLMs via reinforcement learning (RL) without the preliminary step of supervised fine-tuning (SFT). The analysis focuses on base models and the RL component to understand how pretraining characteristics influence RL performance, investigating both theoretical and empirical perspectives.
Analysis on Base Models
The paper investigates various base models' pretraining attributes, particularly models from the Qwen2.5 family and DeepSeek-V3-Base. This analysis reveals that some models demonstrate advanced reasoning before RL fine-tuning, raising questions about pretraining biases.
Trainability and Template Impact
Different templates can significantly affect a base model's answer patterns and reasoning capabilities. For instance, applying appropriate templates can engender a question-answering base policy from models initially trained for sentence completion. Notably, Qwen2.5 shows strong reasoning capabilities without templates, suggestive of pretraining characteristics specific to these models.
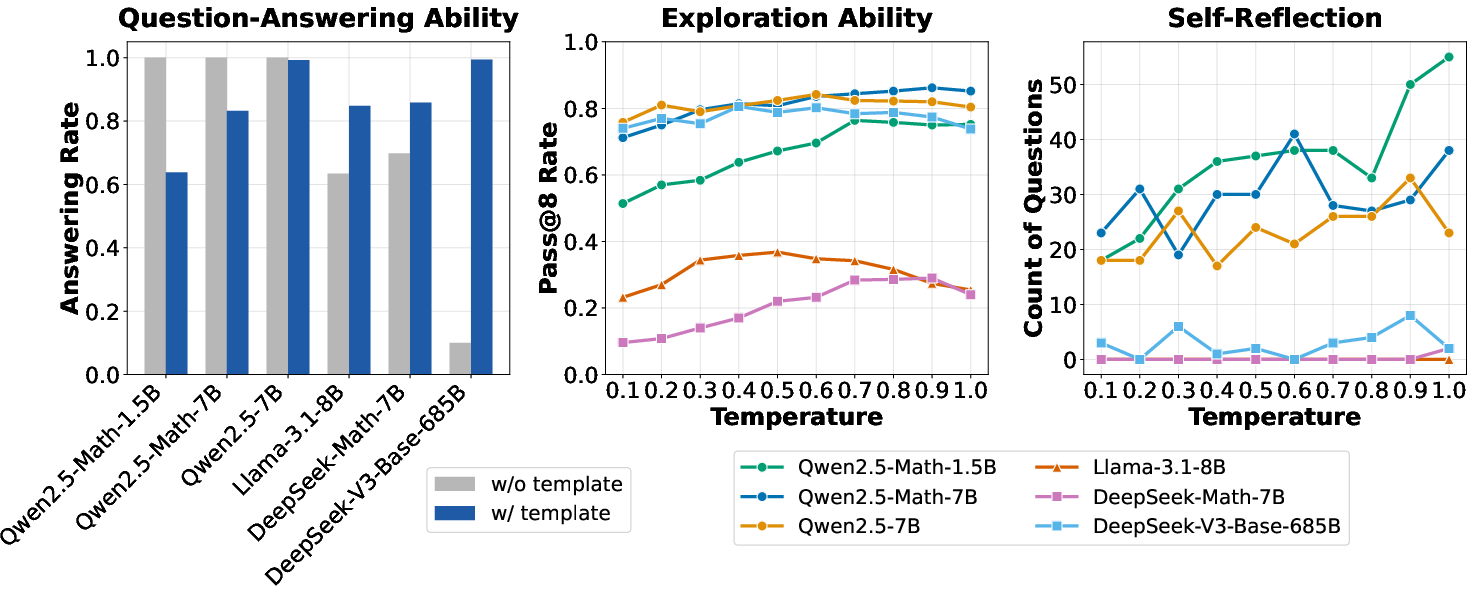
Figure 1: Model attributes across three aspects, highlighting the differences in question-answering ability, exploration ability, and self-reflection.
Base Model Self-Reflection
The emergence of behaviors like self-reflection in base models is essential. Through analysis, it is displayed that even before RL fine-tuning, certain models exhibit such emergent behaviors, supporting hypotheses regarding inherent model characteristics.
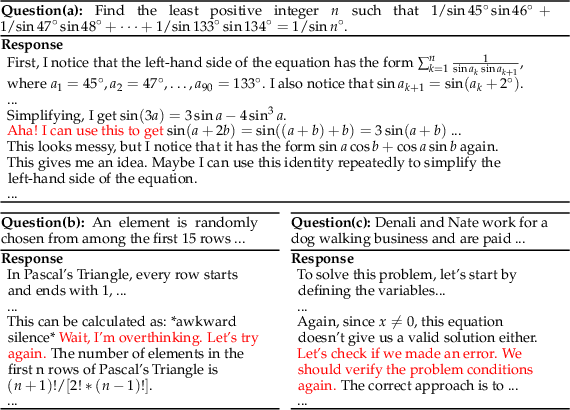
Figure 2: Cases showing that DeepSeek-V3-Base already exhibits ``Aha moment'' even before RL tuning.
Reinforcement Learning Analysis
RL strategies applied to LLMs often utilize token-level MDP frameworks and optimization methods like GRPO. However, a significant part of this study focuses on identifying and addressing biases associated with such optimization techniques.
GRPO Bias and Unbiased Optimization
The paper identifies specific biases in GRPO that impact optimization actions during RL. Namely, biases arise from response length and difficulty level, potentially skewing policy towards lengthier or incorrectly reasoned responses.

Figure 3: Illustration of the biases in GRPO, demonstrating how different weights are assigned due to response length and difficulty bias.
Dr. GRPO: An Unbiased Solution
By eliminating biased normalization terms from GRPO, Dr. GRPO presents itself as an unbiased optimizer, offering improved token efficiency and balanced RL outcomes. This method is practically validated through implementation on open-source RL frameworks, showing mitigated overthinking and more stable output lengths in practice.
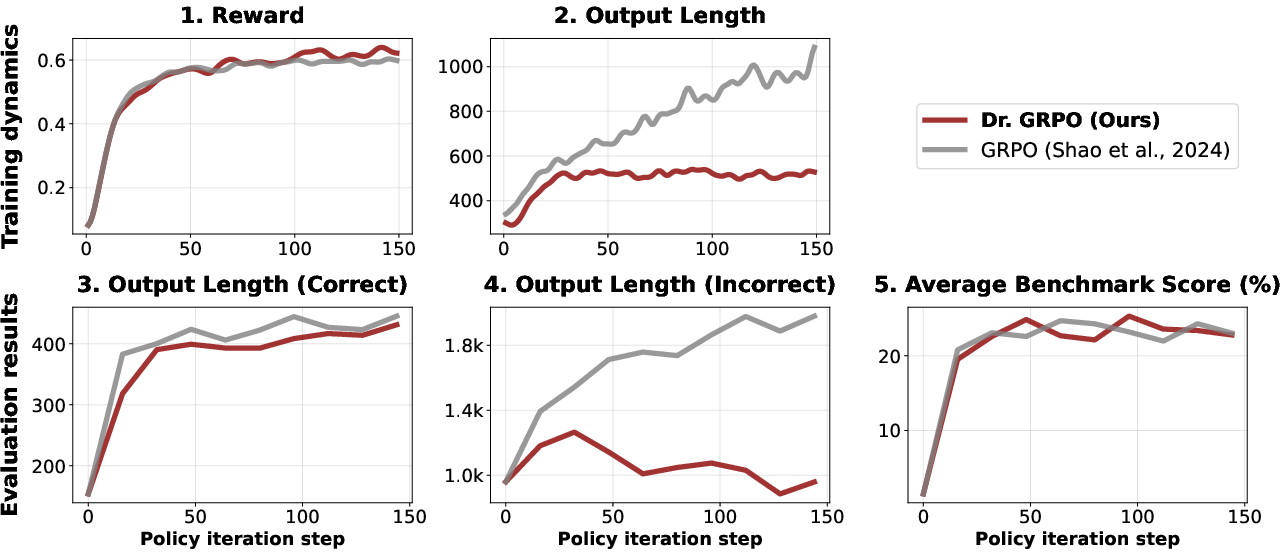
Figure 4: Comparison of Dr. GRPO and GRPO in terms of training dynamics (Top) and evaluation results (Bottom).
Implications and Future Prospects
The paper's insights into R1-Zero-like training provide critical implications for deploying RL in LLM fine-tuning beyond supervised learning paradigms. By unmasking biases and presenting an improved approach to RL training, the paper paves the way for more efficient and effective applications. Future research will likely expand on these findings, investigating unexplored pretraining influences and optimizing RL algorithms further to fine-tune capabilities.
Conclusion
This examination underscores the complex interplay of pretraining biases and RL dynamics in R1-Zero-like training, demonstrating how improvements like Dr. GRPO can offer more efficient utilization of RL resources. Such critical perspectives underline the importance of understanding and addressing biases to further the effective application of RL in developing advanced reasoning capabilities in LLMs.