- The paper introduces the TalkingBabies framework, using teacher demonstrations to enhance multi-turn dialogue based on BabyLM's zone of proximal development.
- The paper employs contrastive and odd-ratio preference optimization within a dynamic post-training pipeline using a 30M-word corpus to improve dialogue cohesion.
- The paper shows that iterative teacher-student interactions yield grammatically correct and contextually relevant interactions, outperforming static curriculum-based methods.
Teacher Demonstrations in a BabyLM's Zone of Proximal Development for Contingent Multi-Turn Interaction
The paper "Teacher Demonstrations in a BabyLM's Zone of Proximal Development for Contingent Multi-Turn Interaction" introduces the TalkingBabies framework, a novel approach designed to enhance multi-turn dialogue generation capabilities of a BabyLM model. The focus is on improving dialogue contingency — the prompt, direct, and meaningful exchanges with a Teacher LLM, in the context of developmentally plausible training data.
Introduction and Background
Contingency is a crucial feature in child-caregiver interactions, forming the backbone of effective language learning. TalkingBabies aims to simulate this interaction by post-training a BabyLM, which is initially trained on 100 million words, to produce more cohesive and coherent dialogue by demonstrating this interaction in its zone of proximal development (ZPD). Inspired by Vygotsky’s concept, the ZPD represents the learner’s potential with guidance, allowing BabyLM to iteratively learn from corrected outputs by a Teacher LLM.
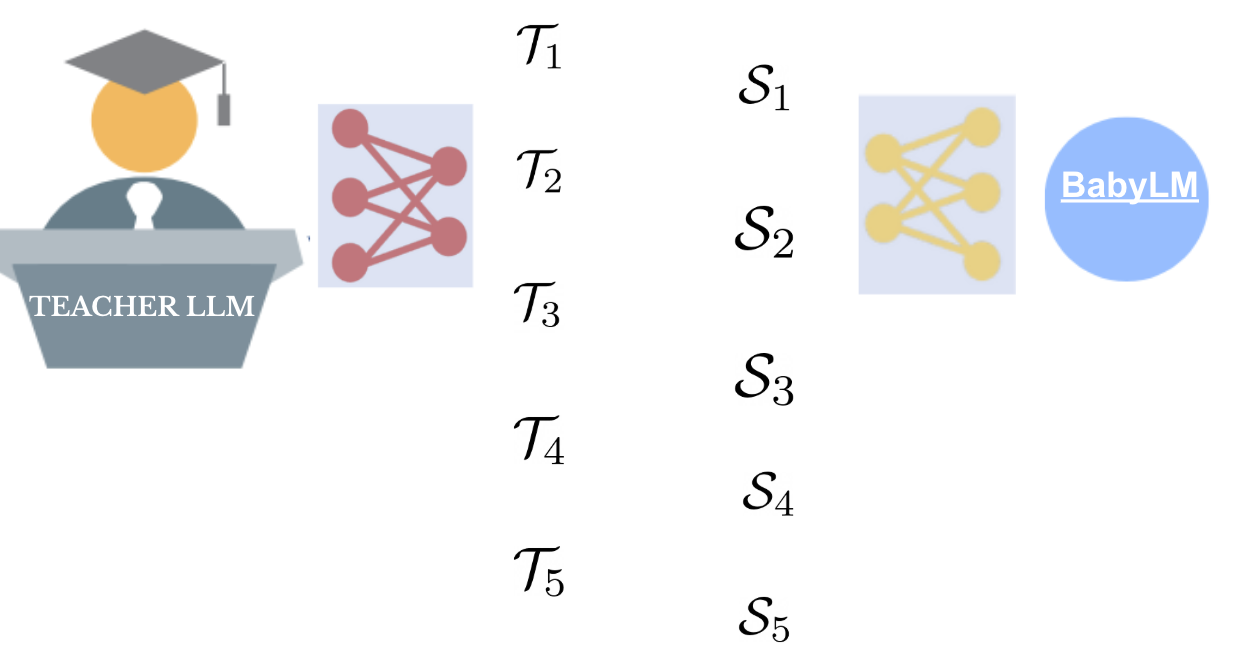
Figure 1: We consider multi-turn dialogic interactions between a BabyLM trained on 100M words (a Strict model) and a Teacher LLM. The TalkingBabies framework aims to improve BabyLM generations by rewarding more cohesive and coherent generations through trials-and-demonstrations in a post-training phase.
Methodology
The TalkingBabies framework utilizes an iterative post-training pipeline, enabling interaction between BabyLM and Teacher LLM using a 30M-word corpus derived from the Switchboard Dialog Act Corpus. These dialogues are annotated with cohesion metrics, transforming BabyLM’s outputs to improve cohesiveness and contextual relevance.
Experiments are structured around preference-based objectives:
- Experiment 1: Involves the use of teacher-generated continuations to form preference pairs, optimized with Contrastive Preference Optimization (CPO) and Odd-Ratio Preference Optimization (ORPO).
- Experiment 2: Employs a curriculum inspired by CEFR (Common European Framework of Reference for Languages), progressively adjusting the complexity of the teacher’s responses to align with the BabyLM’s proficiency.
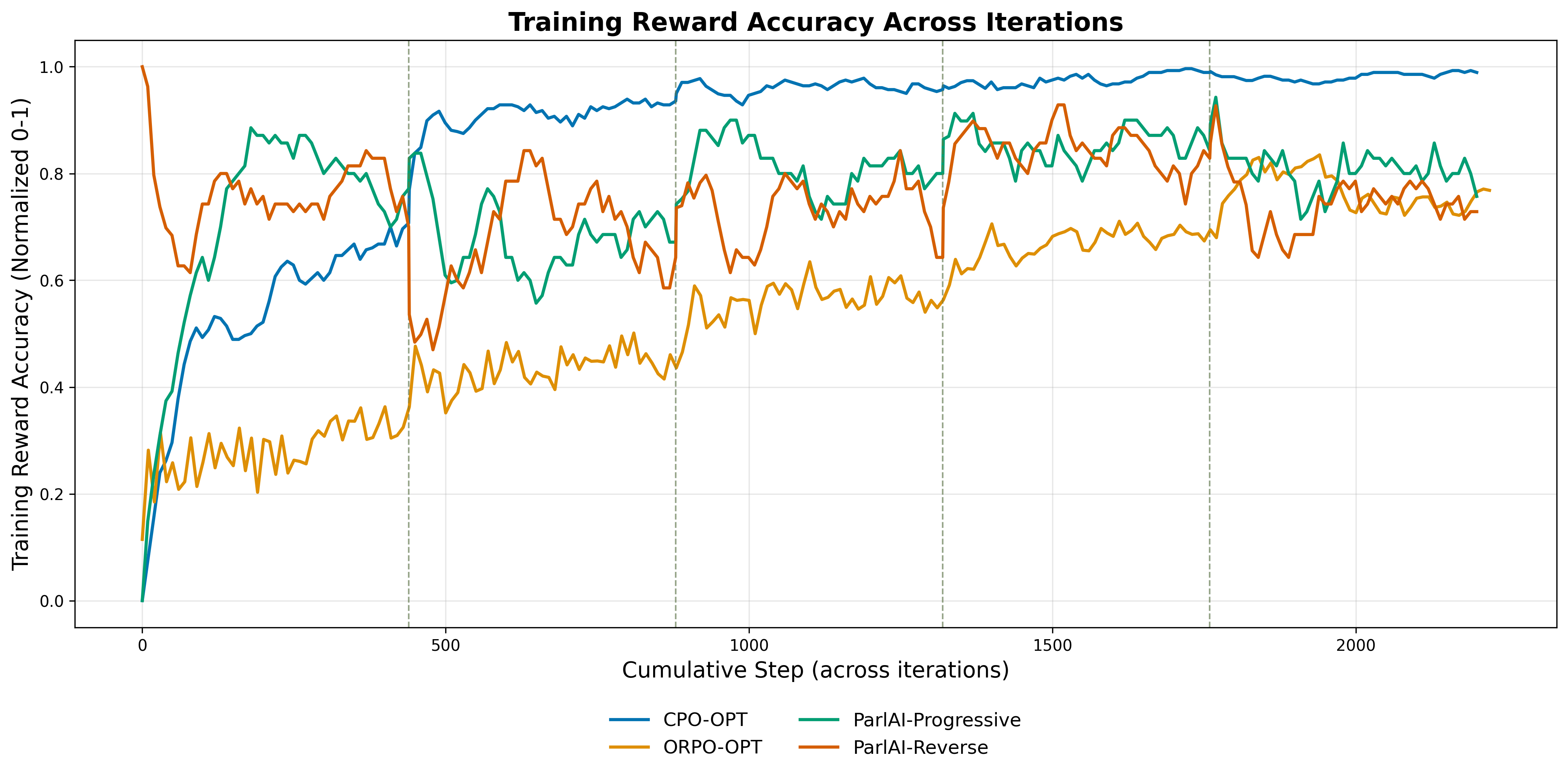
Figure 2: Reward accuracy during post-training of OPT (with 1024 sequence length) with CPO/ORPO (Experiment 1) and Progressive/Regressive CEFR (Experiment 2).
Results
The framework demonstrates significant improvement in dialogue quality, achieving more grammatically correct and contextually appropriate outputs compared to baseline models. Models fine-tuned using CPO showed superior alignment, maintaining the conversation within the BabyLM’s ZPD better than ORPO, which offered greater exploration potential but less stability.
Training methods that attempted to structure dialogues around CEFR-influenced complexity showed limited improvement, indicating the significance of dynamic feedback over static curriculum inputs.
Implications
This research highlights the potential of utilizing ZPD-inspired frameworks in LLM post-training, effectively guiding BabyLMs to produce dialogues that are not only grammatically competent but also pragmatically contingent. The findings pose implications for future developments in conversational AI, particularly in applications requiring nuanced and adaptive interaction capabilities.
Conclusion
TalkingBabies provides a compelling demonstration of how structured, iterated teacher-student interactions can greatly augment the quality of LLMs trained on limited datasets. The persistent challenges of achieving full contingency, however, underscore the complexity of human-like dialogue modeling. Future research could benefit from exploring diverse teacher models and integrating real-time dynamic feedback mechanisms to further enhance learning efficacy.