Manifold Approximation leads to Robust Kernel Alignment
Published 27 Oct 2025 in cs.LG, cs.AI, and stat.ML | (2510.22953v1)
Abstract: Centered kernel alignment (CKA) is a popular metric for comparing representations, determining equivalence of networks, and neuroscience research. However, CKA does not account for the underlying manifold and relies on numerous heuristics that cause it to behave differently at different scales of data. In this work, we propose Manifold approximated Kernel Alignment (MKA), which incorporates manifold geometry into the alignment task. We derive a theoretical framework for MKA. We perform empirical evaluations on synthetic datasets and real-world examples to characterize and compare MKA to its contemporaries. Our findings suggest that manifold-aware kernel alignment provides a more robust foundation for measuring representations, with potential applications in representation learning.
The paper introduces MKA, a robust metric that leverages local manifold approximations to address CKA's insensitivity to non-linear topological features.
The paper demonstrates through synthetic and real-world benchmarks that MKA reliably tracks local geometry and cluster evolution under various perturbations.
The paper shows that MKA is broadly applicable across domains such as vision, NLP, and graphs, delivering stable and topology-aware alignment for deep representations.
Manifold-Aware Kernel Alignment: A Robust Framework for Comparing Representations
Motivation and Limitations of Existing Alignment Metrics
The paper "Manifold Approximation leads to Robust Kernel Alignment" (2510.22953) critically examines the deficiencies of Centered Kernel Alignment (CKA) as a popular metric for comparing representations, particularly in deep learning. CKA is widely used for quantifying representational similarity across neural networks, layers, and even neuroscientific recordings. However, CKA fundamentally operates on dense, globally computed kernels, generally leveraging linear or RBF kernels with a fixed bandwidth. As a consequence, CKA is insensitive to non-linear topological features and is susceptible to density biases and spurious correspondences, failing under basic perturbations or when topology is distorted but not the underlying manifold.
This issue is empirically exposed in synthetic and real-world benchmarks. For instance, CKA often reports high alignment even when local data geometry or cluster structure diverges, as shown in ranking experiments on ring and cluster data, or fluctuates unpredictably when parameterized shapes morph between different topologies. The invariance of CKA to major forms of global non-linear deformation, and its excessive dependence on high-density regions, motivates the search for an alignment metric which is intrinsically sensitive to manifold structure and robust against such perturbations.
The Manifold-Approximated Kernel Alignment (MKA) Measure
The authors introduce Manifold-Approximated Kernel Alignment (MKA), a theoretically motivated metric for assessing representational similarity under the manifold hypothesis. MKA leverages sparse, non-Mercer kernels constructed by local manifold approximation, specifically using a neighborhood graph akin to UMAP's high-dimensional affinity structure (but omitting probabilistic symmetrization for computational efficiency).
Given two representation matrices X∈RN×d1 and Y∈RN×d2, MKA proceeds as follows:
For each sample, computes a k-nearest neighbor (k-NN) graph using a locally adaptive kernel:
where ρi, σi are locally computed for each point to enforce constant row sums, controlling for density outliers.
The resulting kernel is typically non-symmetric and indefinite, capturing the local ordering and density. Alignment then uses a row-centered matrix:
MKA(KU,LU)=⟨KUH,KUH⟩⟨LUH,LUH⟩⟨KUH,LUH⟩
where H is a centering matrix, with simplification possible under uniform normalizations (Theorem 1 in the paper).
MKA thus generalizes and subsumes CKA (especially k-nearest neighbor-sparsified CKA), but is strictly more robust due to its focus on local geometry and rank information rather than global pairwise relationships.
Empirical Demonstrations and Robustness Evaluation
The paper provides a systematic empirical characterization of MKA relative to CKA, kCKA, SVCCA, RTD, and IMD. The principal empirical findings are:
Sensitivity to Local and Topological Equivalences: In the experiment with Swiss-roll and S-curve shapes (topologically identical, geometrically distinct), CKA reports low similarity for the equivalent regime and higher similarity when the 1D topology is destroyed, while MKA robustly tracks topological equivalence independent of geometry or sampling (as does kCKA, but far less stably in terms of k).
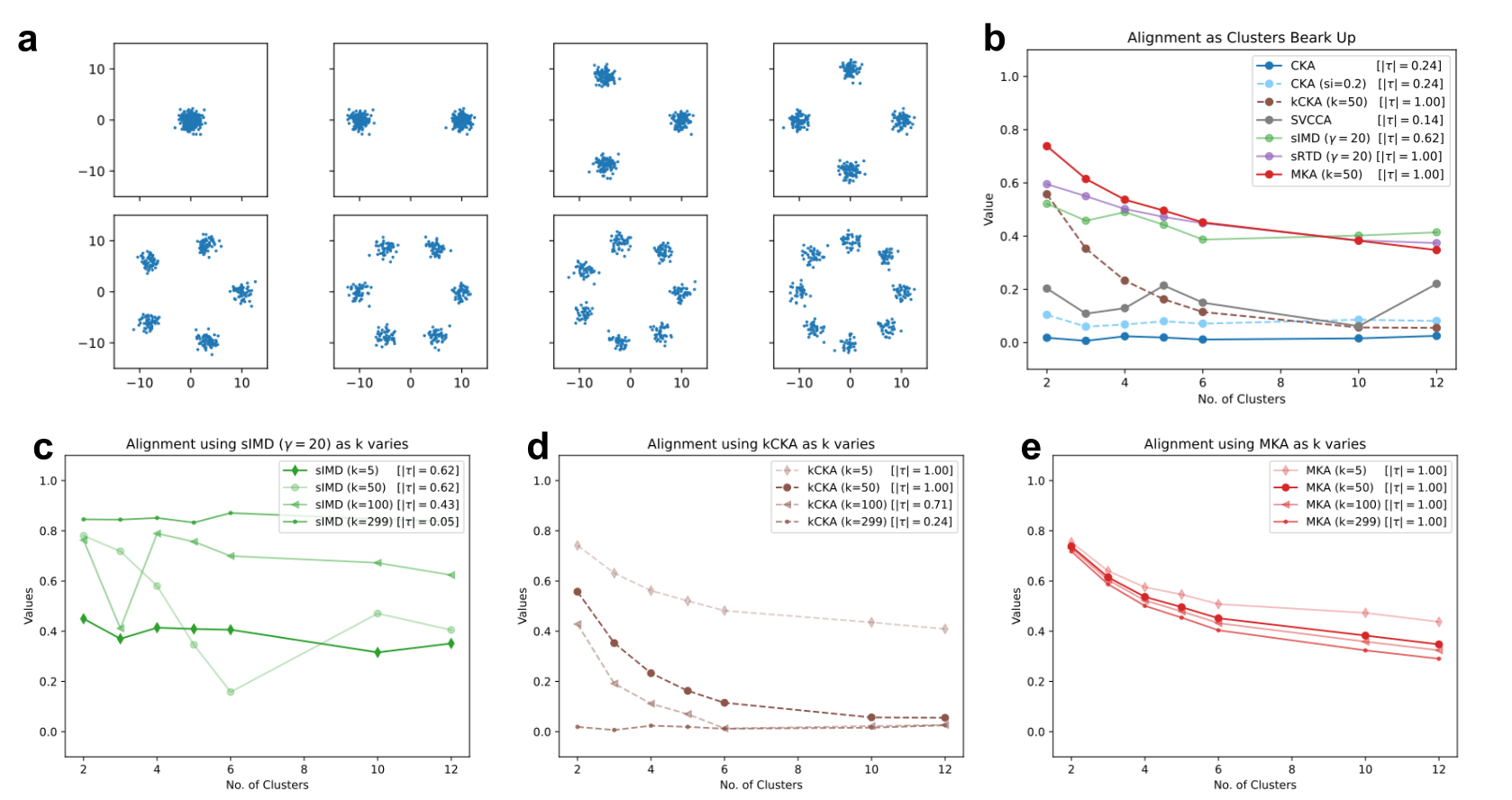
Tracking Cluster Evolution: On synthetic data where ground-truth clusters are progressively merged or split, CKA and SVCCA fail to consistently capture clustering evolution; only methods with explicit manifold modeling (MKA, kCKA, RTD) show rank correlations that correctly track the true progression.
Hyperparameter Robustness: MKA is notably stable against wide variations in the k parameter (the local neighborhood size). In contrast, other local methods (IMD, kCKA) exhibit severe sensitivity, sometimes inverting true rankings or oscillating across k (see cluster and ring benchmarks).
Dimensionality and Sample Size Dependence: In tests with isotropic Gaussian blobs under perturbation and "lost correspondence" conditions, CKA and topological metrics (RTD, SVCCA) display unpredictable drift, especially in high dimensions or with disruptive reordering. MKA and (at large enough k) kCKA are much more invariant and consistent.
Figure 2: Alignment for the "clusters" data. (a) Point clouds used in the clusters experiment. (b) Alignment using various methods, along with Kendall's rank correlation (τ), higher is better. (c-e) Alignment by varying nearest neighbors, k, in (c) IMD, (d) kCKA, and (e) MKA. MKA shows the most robustness to parameters.
Invariance to Global Transformations and Outliers: On uniform translated blobs and synthetic datasets, MKA yields stable alignment scores regardless of spatial translation or dimension, unlike CKA or RTD.
Large-Scale Benchmarking and Neural Representation Analysis
MKA is evaluated on the comprehensive ReSi benchmark [klabunde2024resi], encompassing six tests covering vision (ImageNet-100, multiple network families), NLP (MNLI, BERT/ALBERT), and graph domains (Cora, Flickr, OGBN-Arxiv, GCN/SAGE/GAT/PGNN). Analyses span accuracy correlation, output difference correlation, randomization sensitivity, augmentation, shortcut affinity, and layer monotonicity:
Vision Domain: MKA attains top central performance and tightest rank distribution on ImageNet models across all tests, outperforming or matching kCKA, CKA, and RTD. Monotonicity with layer depth is best preserved by MKA and kCKA, undermining CKA's reliability in internal layer structure.
NLP and Graphs: For language and graph tasks, no single alignment measure dominates. MKA remains robust across modalities, while classical CKA is often knocked out by local methods or hyperparameter choices. The family of manifold-aware neighborhood metrics (MKA, kCKA, and low-bandwidth CKA) cluster together in performance, but MKA is best when generality and insensitivity to k are prioritized.
Neural Block Structure: On neural network layers, MKA reveals less pronounced block structure compared to CKA, indicating that the conventional clustering effects seen with standard CKA are driven by global densities that MKA correctly de-emphasizes. This is evident both within networks (across layers) and across different random initializations—MKA identifies 'manifold-level perturbations' regardless of shared architecture or accuracy.
Theoretical and Practical Implications
The MKA framework addresses critical pitfalls in classic kernel alignment metrics:
CKA is dominated by density and is scale-sensitive; it provides illusory similarity where only global features align, neglecting manifold geometry.
Sparsified or kNN-based CKA metrics become unstable or require hyperparameter sweeps, often leading to inconsistent or irreproducible results.
Topological metrics (RTD, IMD) can fail on basic low-dimensional tasks and behave unpredictably under global transformations.
MKA, by leveraging local manifold geometry with adaptive normalization and local kernel scaling, achieves practical invariance, interpretability, and efficiency. Computationally, MKA is scalable (matching CKA and kCKA in cost), and provides explicit control of locality while avoiding the need for bandwidth tuning or manifold persistence sweeps.
The implications are significant: MKA offers a robust, theoretically principled, and broadly applicable similarity measure for:
Representation analysis, layer assessment, and model selection in deep learning.
Neuroscientific comparison of neural population activations.
Empirical analysis of graph and manifold learning models.
Future research directions include integrating alternative kernel functions (e.g., effective resistance, diffusion distance), improved centering and debiasing, and more nuanced topological information without sacrificing computational tractability.
Conclusion
This work rigorously demonstrates that manifold approximation yields a robust foundation for kernel-based alignment. MKA transcends the limitations of CKA by embedding local geometry directly into the kernel construction and normalization, resulting in a similarity measure that is both topologically faithful and highly resistant to parameter or data perturbations. It should be considered a standard tool for representation similarity analysis wherever local or manifold structure is important, especially in high-dimensional or complex-data domains.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.