MAD-Fact: A Multi-Agent Debate Framework for Long-Form Factuality Evaluation in LLMs
Abstract: The widespread adoption of LLMs raises critical concerns about the factual accuracy of their outputs, especially in high-risk domains such as biomedicine, law, and education. Existing evaluation methods for short texts often fail on long-form content due to complex reasoning chains, intertwined perspectives, and cumulative information. To address this, we propose a systematic approach integrating large-scale long-form datasets, multi-agent verification mechanisms, and weighted evaluation metrics. We construct LongHalluQA, a Chinese long-form factuality dataset; and develop MAD-Fact, a debate-based multi-agent verification system. We introduce a fact importance hierarchy to capture the varying significance of claims in long-form texts. Experiments on two benchmarks show that larger LLMs generally maintain higher factual consistency, while domestic models excel on Chinese content. Our work provides a structured framework for evaluating and enhancing factual reliability in long-form LLM outputs, guiding their safe deployment in sensitive domains.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making sure long answers from AI LLMs are factually correct. When AIs write long pieces—like essays or reports—they can mix correct and incorrect information, or drift into “hallucinations” (confident but false statements). The authors propose new tools and tests to check long answers more fairly and carefully, especially in Chinese. They introduce:
- a new Chinese long-answer dataset called LongHalluQA,
- a multi-agent debate system called MAD-Fact (like a team debate to verify facts),
- and “weighted” scoring that treats important facts as more valuable than minor details.
Objectives
In simple terms, the paper aims to:
- Build a high-quality Chinese dataset for testing the factual accuracy of long AI answers.
- Design a better checker that uses multiple AIs debating together, not just one model making judgments alone.
- Score answers in a smarter way, giving more weight to critical facts than to fun, extra details.
- Compare different AI models to see which ones are more reliable on long, factual writing.
How They Did It
1) Building the LongHalluQA dataset
Think of this like creating a tough test for AIs that write in Chinese:
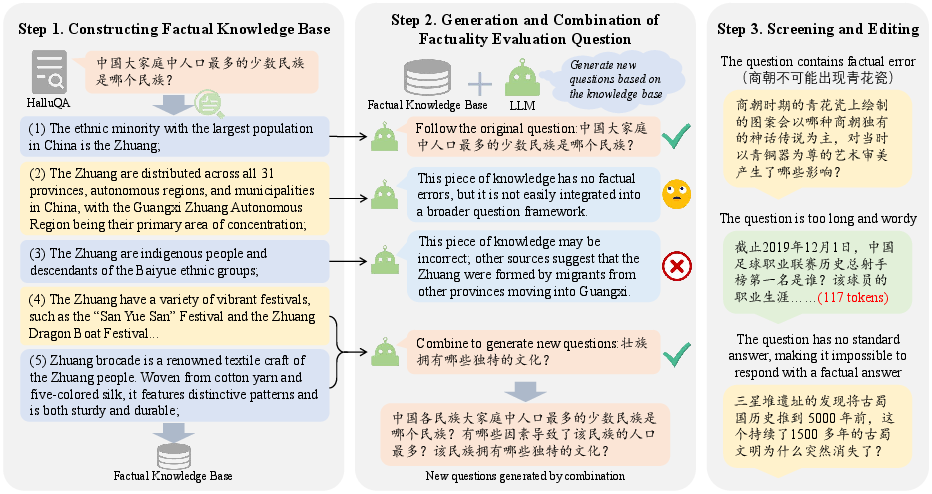
- Step 1: Gather trusted knowledge. They used web search to collect reliable facts related to existing questions, cleaned the results, and stored them in a structured “knowledge base.”
- Step 2: Expand questions into long-form tasks. They turned each question into several connected sub-questions that together demand a long, fact-rich answer (like turning “Who is Li Bai?” into “Describe Li Bai’s major works, style, and influence.”).
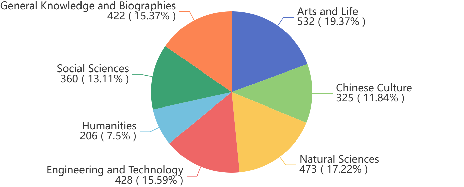
- Step 3: Human review. Trained reviewers checked the questions and content, removing unclear or possibly misleading items. The final dataset has 2,746 long-form Chinese samples across 7 topics (e.g., culture, science, society). On average, answers became about 9.4 times longer than in the original short datasets, creating a stronger test for long-form writing.
2) MAD-Fact: a multi-agent debate system
Imagine a team of specialists checking an essay:
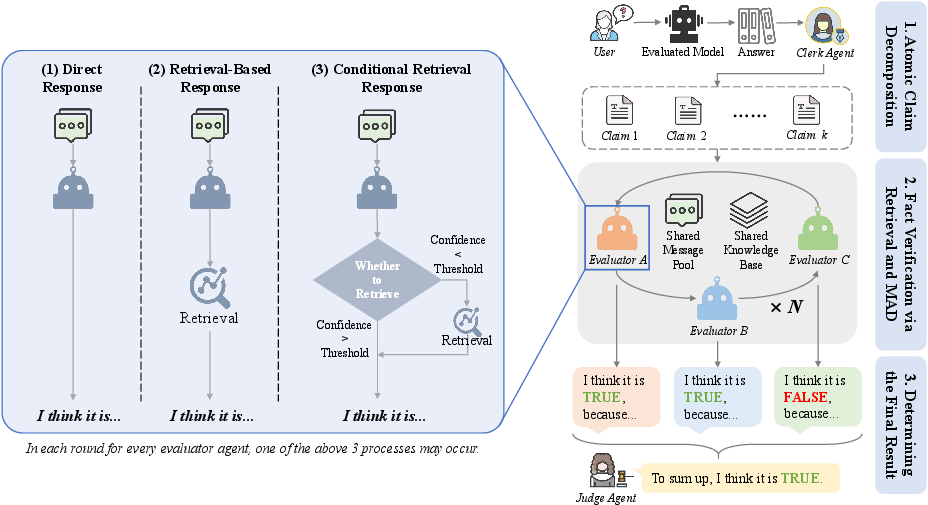
- Clerk: Breaks the long AI answer into small, checkable “atomic claims.” Think of atomic claims as Lego bricks of truth—each is a single, clear statement you can verify.
- Jury: Several AI “roles” (like Critic, Scientist, News Author) debate each atomic claim. They can look things up (using search tools), explain their reasoning, and challenge each other.
- Judge: Collects the jury’s votes and explanations, then decides the final TRUE/FALSE for each claim. The overall factual score is computed from these decisions.
This setup avoids relying on one model’s opinion. Instead, multiple agents cross-check each other, reducing bias and catching more mistakes.
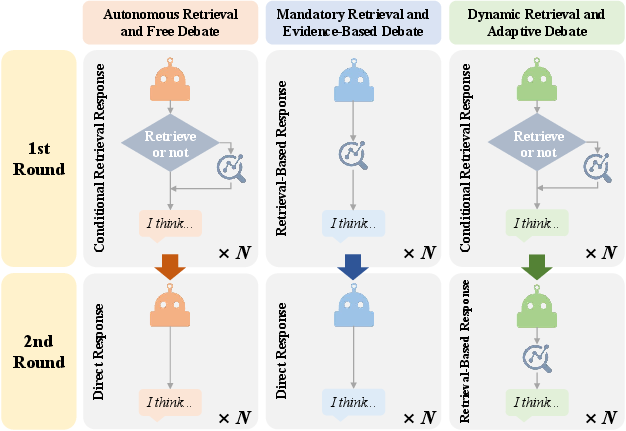
They also tried different debate styles:
- Autonomous: Agents choose whether to search first, then discuss.
- Mandatory evidence: Everyone must search for evidence before speaking (more careful, less overconfidence).
- Dynamic: If agents agree early, stop to save time; if not, force more searching to resolve conflicts.
3) Weighted scoring: treating important facts as more important
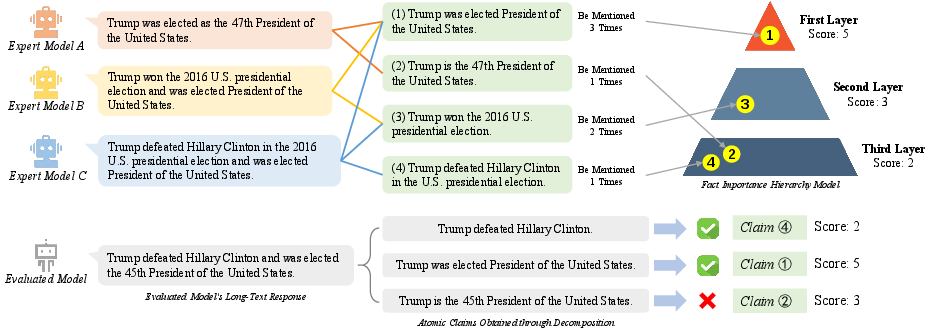
Not all facts are equal. A central fact (like “The Zhuang are the largest ethnic minority in China”) matters more than a side note (like “Zhuang brocade is a traditional textile”).
To capture this, they:
- Built a “pyramid” of importance. They asked several strong models for reference answers, broke those into atomic claims, and counted which facts appeared most often across references. The more often a fact appears, the higher its layer in the pyramid and the greater its weight.
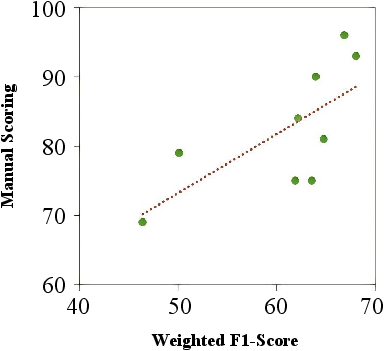
- Computed weighted precision and recall. This means an answer that gets the key facts right scores higher than one that only gets trivia right. Their weighted metric strongly matched human judgments (), which suggests it reflects what people care about in long answers.
Main Findings
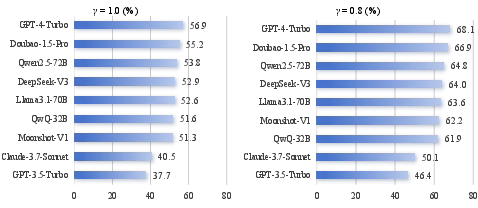
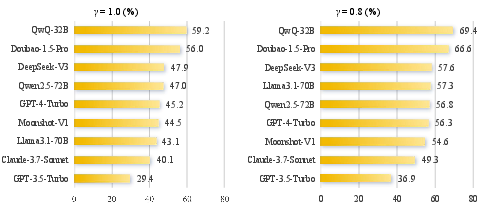
- MAD-Fact (the debate system) consistently outperforms strong baselines like SAFE and FIRE on several long-form factual benchmarks. Using multiple agents and structured debates improves both precision (how often claimed facts are truly correct) and recall (how many relevant true facts are actually covered).
- The new weighted metrics (based on fact importance) correlate well with human ratings, meaning they better capture what makes an answer “good” in the real world.
- Bigger LLMs tend to be more factual overall on long answers.
- Chinese-focused models (trained heavily on Chinese data) perform better on Chinese tasks.
- The LongHalluQA dataset fills a major gap by providing a large, high-quality Chinese benchmark for long-form factual checking.
Why this matters:
- Long answers are common in serious areas like medicine, law, and education. Measuring factuality correctly helps avoid harmful mistakes.
Implications and Impact
- Safer AI in high-stakes fields: Hospitals, courts, and schools can use systems like MAD-Fact to vet long AI-generated texts before trusting them.
- Better AI training and evaluation: Developers can use LongHalluQA and weighted metrics to train and test models in a way that focuses on truly important facts.
- Smarter model selection: Teams can pick models that are better suited for long-form factual tasks, especially in specific languages like Chinese.
- Future extensions: The multi-agent debate idea could be adapted to other languages and even multimodal content (text + images), making factual checking more robust.
In short, the paper provides practical tools and a strong framework to check long AI answers more fairly and accurately, helping reduce “hallucinations” and improve trust in AI’s output.
Collections
Sign up for free to add this paper to one or more collections.