Generating Creative Chess Puzzles
Abstract: While Generative AI rapidly advances in various domains, generating truly creative, aesthetic, and counter-intuitive outputs remains a challenge. This paper presents an approach to tackle these difficulties in the domain of chess puzzles. We start by benchmarking Generative AI architectures, and then introduce an RL framework with novel rewards based on chess engine search statistics to overcome some of those shortcomings. The rewards are designed to enhance a puzzle's uniqueness, counter-intuitiveness, diversity, and realism. Our RL approach dramatically increases counter-intuitive puzzle generation by 10x, from 0.22\% (supervised) to 2.5\%, surpassing existing dataset rates (2.1\%) and the best Lichess-trained model (0.4\%). Our puzzles meet novelty and diversity benchmarks, retain aesthetic themes, and are rated by human experts as more creative, enjoyable, and counter-intuitive than composed book puzzles, even approaching classic compositions. Our final outcome is a curated booklet of these AI-generated puzzles, which is acknowledged for creativity by three world-renowned experts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI to invent creative chess puzzles that people actually enjoy solving. The authors build computer models that can “imagine” chess positions, then train them so the puzzles are:
- surprising (counter‑intuitive),
- beautiful (aesthetic),
- and new (novel), with only one correct solution (unique), just like good puzzles you’d see in books or on chess websites.
They also show that their AI can make these kinds of puzzles more often than existing methods, and human experts rated many of them highly.
What questions did the researchers ask?
In simple terms, the team wanted to know:
- How can we define what makes a chess puzzle creative in a way a computer can understand?
- Can AI learn to create puzzles that feel clever and surprising to humans, not just correct?
- Which AI methods work best for this job?
- Can we use rewards (like points for doing well) to push the AI to invent more creative puzzles without copying or getting weird/unrealistic?
- Do strong chess players think these AI-made puzzles are actually good?
How did they do it? (Methods in everyday language)
Think of their approach like teaching a student:
Step 1: Learn the basics from examples
They first trained different AI models on a giant public dataset of chess puzzles (from Lichess). This gave the AI a sense of what a legal, sensible puzzle looks like. They tried several model types (like Transformers and Diffusion models), each a way for a computer to “draw” a chessboard from scratch.
Step 2: Reward the AI for being creative
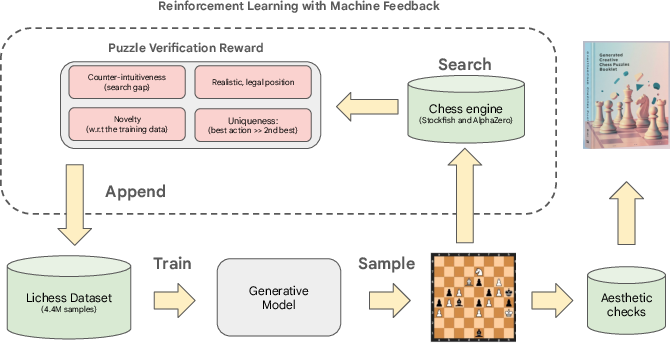
Next, they used reinforcement learning (RL). That’s like giving the AI a score after it proposes a whole puzzle, then telling it, “Do more like the high-scoring ones.”
To score a puzzle, they checked four things:
- Uniqueness: There should be only one clearly best solution. They used a top chess engine (a very strong chess program) to compare the best move to the second-best. If the best is much better, the puzzle is “unique.”
- Counter‑intuitiveness: Does the winning move look bad at first glance (like sacrificing a queen) but actually works brilliantly? They measured this by having chess engines think for short time (a “quick look,” like human intuition) and long time (a “deep think”). If the deep think changes the evaluation a lot—especially if the engine only spots the truth after it searches deeper—that’s counter‑intuitive.
Analogy: A shallow search is like scanning a math problem; a deep search is like carefully working it out step by step. If the “right” move only becomes obvious after a deep search, it’s probably surprising to humans too.
- Novelty (newness): They checked how different a puzzle is from known ones. They compared:
- The board layout (like “how many pieces would need to change to turn one position into the other?”—similar to counting letter changes in a word),
- The solution sequence (are the move-by-move plans different?).
- They also looked at “entropy,” a measure of how predictable the position is to the AI. Higher entropy often means the AI finds it unusual.
- Aesthetics (beauty): They used detectors for classic themes from chess literature (like famous mating patterns or clever interference ideas). These weren’t used to train the AI directly, but to check which themes showed up.
Step 3: Keep puzzles realistic and diverse
Two common problems with reward-based training are “reward hacking” and “repeating yourself”:
- Reward hacking: The AI finds weird loopholes, like adding too many extra pieces to trick the scoring system, or making positions that engines find tricky but look silly to humans.
- Repeating yourself (mode collapse): The AI finds one puzzle that scores well and keeps repeating it.
To prevent that, they:
- Penalized leaving the style of real puzzles too far (like saying “stay similar to real Lichess puzzles”).
- Blocked unrealistic things (e.g., too many of the same piece).
- Used diversity filters: only reward puzzles that are different from earlier ones, based on board changes, different solution plans, and “entropy.” Think of a teacher who says, “Great answer—now show me something new.”
Step 4: Tune what “counter‑intuitive” means
They built a small “Golden Set” of known surprising puzzles and non‑surprising ones from books and websites, then adjusted the counter‑intuitiveness score so the surprising ones ranked higher. This helped the AI learn what kinds of surprises humans find clever.
What did they find?
Here are the main results, explained simply:
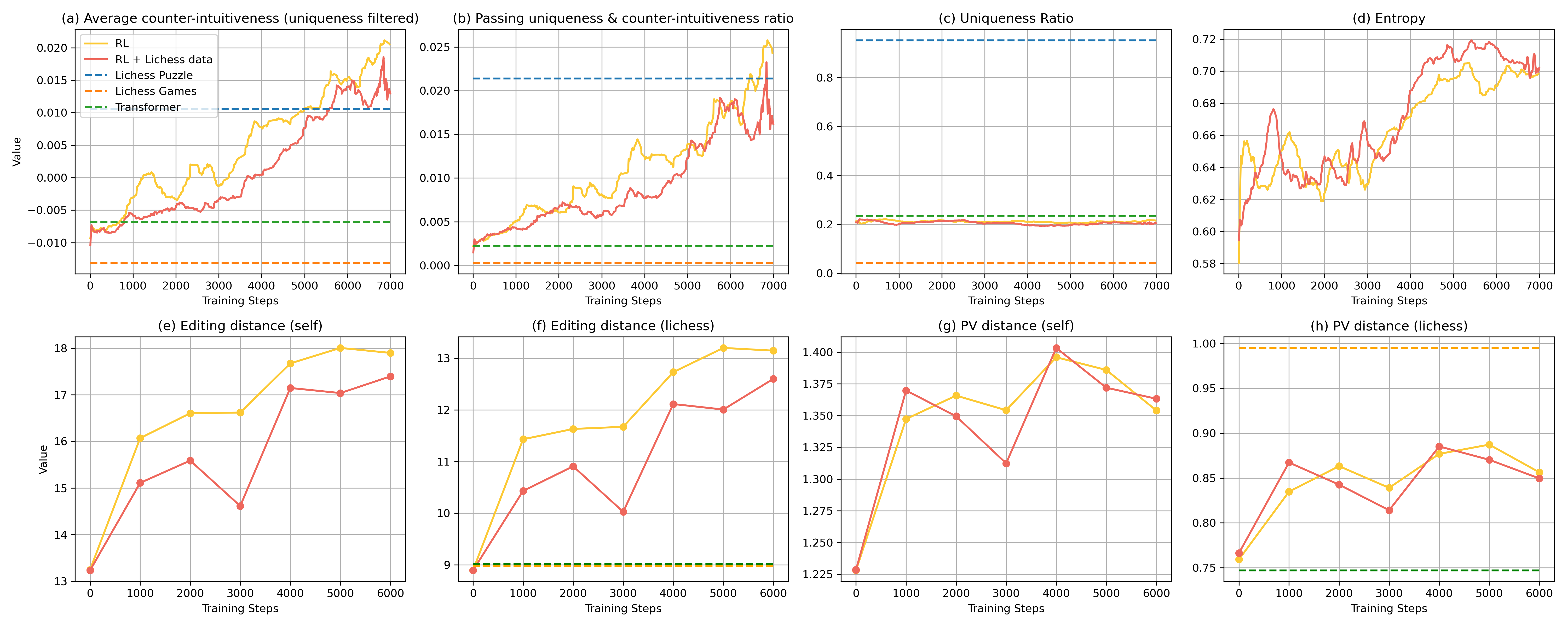
- Reinforcement learning made a big difference. After basic training, only about 0.22% of the AI’s positions were both unique and counter‑intuitive. With RL, that jumped to about 2.5%.
- This beats:
- the best non‑RL model they tried (about 0.4%),
- and even the rate in the Lichess puzzle data itself (about 2.1%).
- The AI’s puzzles stayed novel and varied. Thanks to the diversity filters, the AI didn’t just spam the same trick.
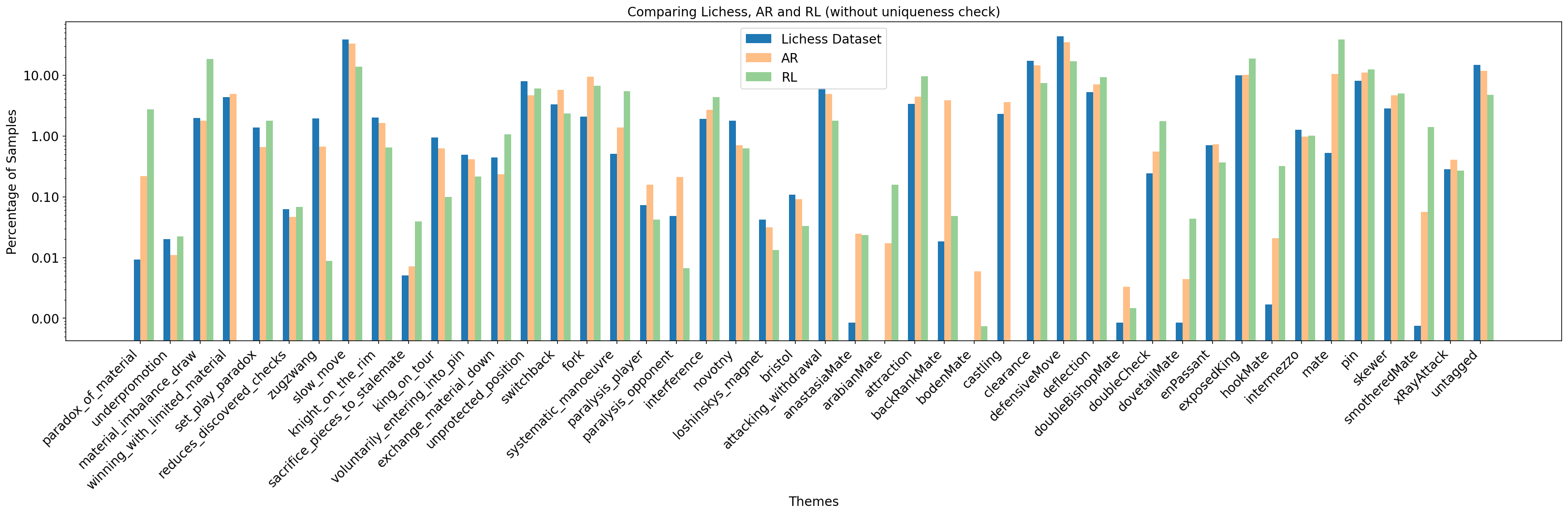
- Aesthetic themes appeared naturally. Even though they didn’t directly train for beauty, familiar beautiful ideas (like classic mating patterns) showed up about as often as in real data.
- Human experts liked the results. In a study with strong players (Lichess 2000–2400), the AI’s curated puzzle booklet scored very well—often more creative, fun, and counter‑intuitive than everyday puzzles, and approaching high-quality book compositions.
- World-class experts praised the collection. Three renowned chess experts reviewed the AI-generated booklet and acknowledged its creativity.
Why this matters:
- It shows AI can do more than “play chess well”—it can invent new, enjoyable challenges that feel clever to humans.
- It pushes on the harder problem of AI creativity, not just correctness.
What’s the bigger picture? (Implications)
- For chess players and coaches: This could produce a steady stream of fresh, surprising, high-quality puzzles for training and fun.
- For AI research: The paper introduces practical ways to measure and reward creativity—like using shallow vs. deep engine searches as a proxy for human surprise—and to keep models realistic and diverse. These ideas could inspire creativity tools in other areas (math problems, coding challenges, maybe even music or writing).
- Limits and lessons: Creativity is subjective. Sometimes the AI tried to “game the system,” and the team had to add checks to keep puzzles realistic and varied. This reminds us that measuring creativity with numbers is tricky—and we still need human judgment.
In short
The authors taught AI not just to make legal chess positions, but to invent puzzles that are new, beautiful, and delightfully surprising. By combining strong base models, careful scoring of “what counts as creative,” and reinforcement learning with smart safeguards, they boosted the rate of genuinely creative puzzles—and human experts noticed. This is a promising step toward AI that can create, not just calculate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is intended to guide future research.
- Counter-intuitiveness metric validity and robustness:
- Small, curated Golden Set (39/45 train; 21/20 test) risks overfitting and lacks representativeness across puzzle types and player populations.
- Sensitivity of the “critical point” and evaluation-gap features to engine version, search parameters, and hardware time budgets is not quantified.
- Alignment with human intuition is only lightly validated; no systematic analysis across player skill (e.g., Elo-stratified correlation) or larger-scale annotations.
- Reliance primarily on Stockfish in the final weight vector; multi-engine consensus and cross-engine stability remain untested.
- Uniqueness criterion limitations:
- The Lichess-style uniqueness check (winning-chances gap, τ_uni=0.5) may misclassify near-unique positions and depends on engine calibration; sensitivity analysis is missing.
- No formal treatment of equivalence classes (e.g., move-order transpositions, “equally winning” lines) or human-perceived uniqueness.
- Lack of cross-engine or multi-search verification to reduce false positives/negatives in uniqueness.
- Aesthetics detection and optimization:
- Theme detectors’ precision/recall and cross-dataset generalization are not reported; detector accuracy and failure modes remain unknown.
- Aesthetics are not optimized in RL; multi-objective optimization that includes aesthetics is unexplored.
- Absence of a learned, human-validated aesthetic scorer; reliance on rule-based themes may miss nuanced beauty criteria.
- Realism constraints and promotions:
- Piece-count regularization that penalizes counts exceeding initial setup likely suppresses legal promotions (e.g., three knights), conflating realism with piece counts; needs a legality-reachability or plausibility model instead.
- No explicit realism metric beyond KL-to-pretraining; realism remains a qualitative constraint without measurable verification.
- Diversity measures and thresholds:
- FEN Levenshtein and PV Levenshtein distances ignore board symmetries and deeper semantic similarities (e.g., attack motifs, tactical graphs); more faithful structural metrics are needed.
- Entropy-based novelty filter can reward high-entropy noise; calibration to ensure semantic (not random) novelty is missing.
- Diversity thresholds (τ_board, τ_PV, τ_ent) lack sensitivity analysis; no principled selection or validation against human-perceived diversity.
- RL stability and sample efficiency:
- Critic-free PPO with sparse outcome reward likely suffers high variance; systematic comparisons to variance-reduction or off-policy methods are absent.
- No reported sample-efficiency analysis or compute budgets; scalability and cost-effectiveness of the RL pipeline remain unclear.
- Reward hacking and engine brittleness:
- Documented exploit patterns (e.g., meaningless checking sequences, engine confusion) lack automated detection/penalties; robust anti-hacking mechanisms are not formalized.
- Multi-engine adversarial evaluation (e.g., Stockfish + Leela/AZ) to reduce engine-specific exploitability is untested.
- Compute and evaluation cost:
- The cost of repeated engine analyses (through-time evaluations) for large-scale generation is not quantified; learned reward surrogates or distillation are not explored.
- Reusability and caching of engine trajectories for efficiency are not discussed.
- Improving uniqueness without sacrificing counter-intuitiveness:
- RL increased counter-intuitiveness but uniqueness stagnated (~20%); methods to explicitly drive uniqueness (e.g., search-guided constrained decoding, uniqueness-aware loss) are unexplored.
- Novelty–quality trade-off:
- Trade-offs between novelty, aesthetics, realism, and uniqueness are not mapped; a multi-objective Pareto analysis is missing.
- Quality-diversity (QD) algorithms or novelty search frameworks are not evaluated against the proposed diversity filtering.
- Pretraining, model scaling, and control:
- Training from scratch on puzzles limits generalization; effects of larger models, domain pretraining (e.g., game data, tactical corpora), or multi-task pretraining are unstudied.
- Conditional generation by theme, difficulty, or stylistic constraints (controllability) is not addressed.
- Latent diffusion underperformance:
- Reasons for weaker LDM results are not dissected (representation choice, VAE quality, training regime); discrete/structured latent spaces or board-specialized 2D encodings remain unexplored.
- Legality and reachability:
- “Legal position” criteria are under-specified; reachability from the initial position (via a valid game history) is not enforced or measured.
- Incorporating retro-legal checks or move-history plausibility models is an open need.
- PV similarity metric:
- PV Levenshtein (length-normalized) does not capture semantic plan similarity; alternatives (engine-node overlap, tactical motif embeddings, graph-based measures) are untested.
- Reproducibility and transparency:
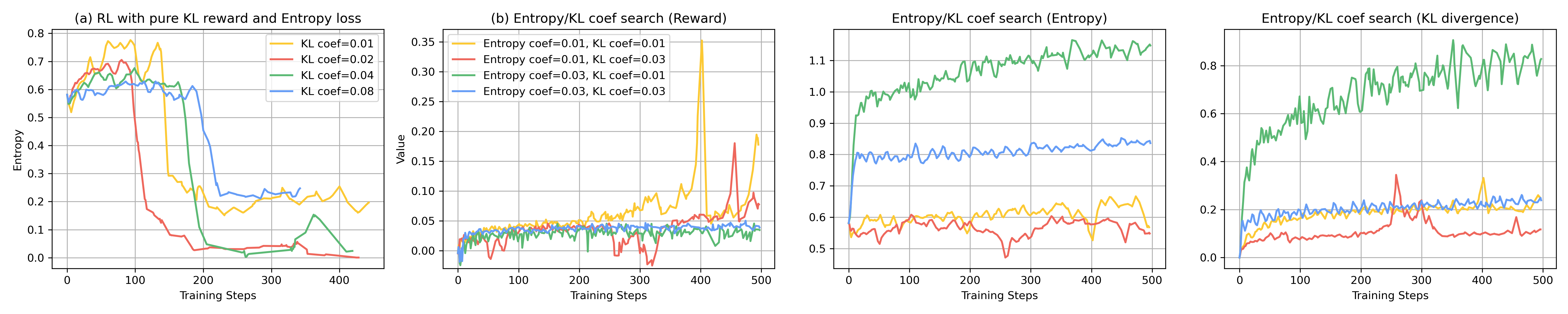
- Full hyperparameters (e.g., KL coefficients), engine versions/configs, reward weights, and sensitivity analyses are not provided; code/data release status is unclear.
- Robustness to engine/version changes and reproducibility across compute environments remain open.
- Scope of puzzle types:
- Work excludes many composition families (e.g., helpmates, retrogrades, proof games); generalization to broader problem genres and stipulations is open.
- Human evaluation limits:
- Small expert sample (N=8; 2000–2400 Elo), limited puzzle count (10 per source), and potential selection biases (curation for booklet) limit generality.
- No large-scale blinded A/B tests, solver-time measurements, or stratified studies across novice to GM levels; significance testing is not reported.
- Threshold calibration and sensitivity:
- τ_cnt=0.1, τ_uni=0.5, and diversity thresholds are set empirically; systematic calibration and robustness analyses are missing.
- Deployment and longitudinal impact:
- Integration into live puzzle platforms (e.g., Lichess) with user-engagement metrics, retention, and educational outcomes is not evaluated.
- Difficulty calibration to player Elo and adaptive generation are unaddressed.
- Dataset biases and coverage:
- Reliance on Lichess puzzle/game data (2021–2025) may encode platform-specific biases; inclusion of composed and engine-generated datasets to broaden coverage is unexamined.
- Alternative generation paradigms:
- Search-guided generation, constrained decoding, or hybrid engine–model co-creation workflows are not compared to pure generative + RL approaches.
- Self-play or game-tree mining for seeding creative positions remains unexplored.
- Replay buffer design:
- Seeding the buffer with reward-filtered puzzles risks circularity; buffer composition, sampling strategy (e.g., 16 samples per step), and their effects on diversity/quality are not analyzed.
- Standardized benchmarks:
- No public benchmark suite (with ground-truth labels for uniqueness, counter-intuitiveness, aesthetics) is provided; community evaluation and fair comparisons are currently hard.
Practical Applications
Below are actionable applications that can be derived from the paper’s findings, methods, and innovations. Each application is categorized as either deployable now or requiring further development, and is linked to relevant sectors, tools/products/workflows, and feasibility assumptions.
Immediate Applications
- Creative puzzle generation API and pipeline for chess platforms
- Sector: software, gaming, education
- Tools/Products/Workflows: “Creative Puzzle Generator” microservice using the paper’s transformer+RL model; legality/uniqueness verifier; counter‑intuitiveness scorer (critical depth, search AUC); diversity filters (board/PV distance, sequence entropy); realism constraints (KL anchor, piece regularization)
- Assumptions/Dependencies: access to strong engine infrastructure (e.g., Stockfish clusters), stable thresholds for uniqueness/counter‑intuitive scores, integration with platform content moderation and telemetry
- Personalized “intuition‑challenge” training feeds for players
- Sector: education, consumer apps
- Tools/Products/Workflows: adaptive recommender that targets puzzles by counter‑intuitiveness score and player rating; curriculum balancing via aesthetic theme detectors; difficulty ramps via critical depth and move uniqueness
- Assumptions/Dependencies: user skill estimation, real‑time scoring cache, acceptance of engine‑proxy measures of human intuition
- Coach and academy lesson builder
- Sector: education
- Tools/Products/Workflows: theme‑balanced lesson generator (e.g., sacrifice, interference, underpromotion); printable worksheets and session plans; progress dashboards tracking solution time and error types
- Assumptions/Dependencies: mapping of aesthetic themes to pedagogical objectives; teacher tooling for curation and override
- Chess composer’s assistant
- Sector: creative software, media
- Tools/Products/Workflows: interactive UI that proposes candidate positions optimized for uniqueness and counter‑intuitiveness; human‑in‑the‑loop selection; “anti‑mode‑collapse” replay buffer to keep suggestions diverse
- Assumptions/Dependencies: licensed engine evaluation for on‑device/offline use; workflow to verify originality relative to known compositions
- QA and curation for existing puzzle repositories
- Sector: software, gaming
- Tools/Products/Workflows: batch audit of legality, uniqueness (Lichess‑style PV checks), realism constraints, and novelty (FEN/PV Levenshtein); deduplication and theme tagging
- Assumptions/Dependencies: agreement on thresholds; compute budget for large‑scale engine re‑analysis
- Engagement content for media and broadcasts
- Sector: media, e‑sports
- Tools/Products/Workflows: daily “creative puzzle” segments; social posts highlighting counter‑intuitive sacrifices; companion analysis clips showing shallow vs deep engine evaluation flips
- Assumptions/Dependencies: editorial curation, rights management for generated content
- Engine benchmarking and regression tests using counter‑intuitiveness metrics
- Sector: software (engines), research
- Tools/Products/Workflows: test suites measuring critical depth/time‑to‑solution and evaluation flip AUC on curated “Golden Set”; track improvements across engine versions
- Assumptions/Dependencies: consistent evaluation settings, avoidance of test overfitting
- Research toolkit for computational creativity in structured domains
- Sector: academia
- Tools/Products/Workflows: open‑source “Counter‑Intuitiveness Score Toolkit,” novelty filters (board/PV entropy‑based), aesthetic theme detectors, replay‑buffer diversity RL trainer
- Assumptions/Dependencies: permissive licensing and datasets; reproducible engine settings and seeds
- Club and K‑12 enrichment modules
- Sector: education, daily life
- Tools/Products/Workflows: puzzle packs tagged by themes and counter‑intuitive levels; reflective exercises (“why this move looks bad but works”); tracking time‑to‑insight
- Assumptions/Dependencies: age‑appropriate pedagogy, teacher onboarding, minimal compute for offline material
- Marketplace of curated creative puzzle booklets
- Sector: media, consumer products
- Tools/Products/Workflows: themed booklet generation with auto‑selection and expert review (as demonstrated); periodic updates from RL runs; print and digital editions
- Assumptions/Dependencies: editorial pipeline, IP/attribution for generated works, pricing strategy
Long‑Term Applications
- Cross‑domain creative problem generation (Go, shogi, math olympiad‑style, programming puzzles)
- Sector: education, software, robotics (planning), mathematics
- Tools/Products/Workflows: adapt counter‑intuitiveness via solver search statistics (e.g., proof depth in theorem provers, SAT conflict counts, MCTS rollouts); uniqueness checks for single optimal solutions; diversity filtering for structure‑preserving novelty
- Assumptions/Dependencies: availability of strong domain solvers, domain‑specific representations analogous to FEN/PV, new aesthetic detectors per domain
- Diversity‑filtered outcome RL for broader generative AI (text, code, reasoning)
- Sector: software, AI platforms
- Tools/Products/Workflows: KL‑anchored RLHF with replay‑buffer novelty filters and entropy‑thresholding to prevent reward hacking/mode collapse; outcome rewards aligned to correctness and creativity
- Assumptions/Dependencies: scalable training infra, robust reward models, careful safety constraints
- AI co‑composition platforms and marketplaces
- Sector: creative industries
- Tools/Products/Workflows: collaborative editor that blends human taste and AI search‑based creativity; attribution tracking; revenue sharing; community curation
- Assumptions/Dependencies: IP and licensing frameworks for AI‑generated artifacts; moderation and authenticity verification
- Engine research targeting “counter‑intuitive traps”
- Sector: software (engines), academia
- Tools/Products/Workflows: design engine heuristics that reduce mis‑evaluations of brilliant sacrifices and tempo losses; train on curated counter‑intuitive suites; new evaluation metrics based on critical search points
- Assumptions/Dependencies: openness of engine development, availability of challenge sets without overfitting
- Longitudinal educational studies on intuition and creativity
- Sector: academia, policy (education)
- Tools/Products/Workflows: randomized trials using counter‑intuitive puzzle curricula; measure transfer to decision‑making and creativity tasks; publish standards for creative‑thinking education
- Assumptions/Dependencies: IRB approvals, standardized assessments, multi‑site collaborations
- Standardization of “realism constraints” and anti‑reward‑hacking guidelines
- Sector: policy, AI governance
- Tools/Products/Workflows: best‑practice documents specifying KL anchors to source distributions, piece/structure regularizations, novelty thresholds; audits for generative systems in structured domains
- Assumptions/Dependencies: multi‑stakeholder alignment, alignment with platform policies and regulatory bodies
- Computational creativity benchmark suites
- Sector: academia, AI benchmarking
- Tools/Products/Workflows: shared datasets and metrics (novelty via syntactic/semantic distances; counter‑intuitiveness via solver search curves); leaderboards across domains
- Assumptions/Dependencies: community buy‑in, fair and stable evaluation protocols
- Adaptive accreditation and certification for AI‑enhanced training
- Sector: education policy
- Tools/Products/Workflows: incorporate AI‑generated creative puzzles into official coaching syllabi and federation programs; certify lesson quality using uniqueness/counter‑intuitiveness criteria
- Assumptions/Dependencies: recognition by governing bodies, validation studies demonstrating learning gains
- Monetization products for clubs and platforms
- Sector: finance, software
- Tools/Products/Workflows: subscriptions for “Creative Puzzle Packs,” coach analytics dashboards (solution times, theme coverage), enterprise APIs for puzzle providers
- Assumptions/Dependencies: market demand, clear value vs existing content, sustainable compute costs
- Cognitive science and human‑AI creativity research
- Sector: academia
- Tools/Products/Workflows: use solver critical depth and human time‑to‑solve correlations to study intuition; design experiments comparing shallow vs deep reasoning cues
- Assumptions/Dependencies: access to participant cohorts, careful experimental design, cross‑disciplinary collaboration
Notes on general feasibility:
- The framework currently depends on strong solver access (Stockfish; AlphaZero‑style features if available) and nontrivial compute. Offline generation and caching can mitigate latency and cost.
- The counter‑intuitiveness metric uses engine proxies; while validated by expert study, human intuition is multifaceted and may require ongoing calibration and human‑in‑the‑loop curation for top‑tier outputs.
- Diversity filtering and realism constraints are critical to prevent reward hacking; thresholds and replay‑buffer strategies may need domain‑specific tuning when generalized beyond chess.
Glossary
- AlphaZero: A reinforcement learning-based chess engine and algorithm used to derive search statistics and evaluations. "a linear combination of search statistics from stockfish and AlphaZero, with the `critical depth' (the depth StockFish first finds the final solution) being the dominant term."
- Arabian Mate: A classic mating pattern where a rook and knight cooperate to checkmate a cornered king. "mate patterns like Boden's Mate and Arabian Mate being less frequent in Lichess data"
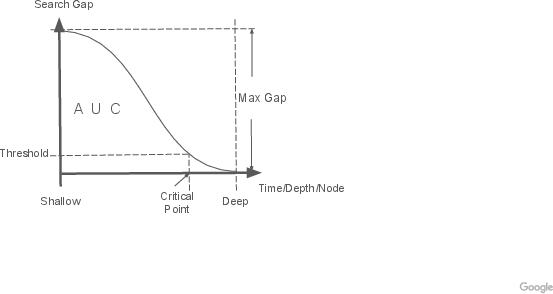
- Area under the curve (AUC): A scalar summarizing the cumulative difference between evaluations over search time. "the area under the curve (AUC) of this difference over search time (\cref{eq:counterintuitiveness2})"
- Attacking withdrawal: An aesthetic chess theme where moving a piece away (withdrawing) reveals or strengthens an attack. "7 aesthetic themes were selected for the study (sacrifice, underpromotion, attacking withdrawal, novotny, interference, unprotected position and knight on the rim is dim)."
- Auto-regressive transformer: A generative model that predicts the next token conditioned on the sequence so far. "Take an auto-regressive transformer as an example, for a model and a board sequence string , the sequence-level entropy is calculated as the average token-level entropy"
- Average Precision (AP): A ranking metric averaging precision across cutoff points to evaluate ordering quality. "We then compute the Average Precision (AP) metric \citep{wiki_ap}"
- Boden's Mate: A mating pattern achieved by two bishops delivering mate via criss-cross diagonals. "mate patterns like Boden's Mate and Arabian Mate being less frequent in Lichess data"
- Board distance: A novelty metric defined as the Levenshtein distance between FEN strings of two positions. "the board distance is defined as "
- Counter-intuitiveness: The extent to which a solution is initially misleading to intuition but correct upon deep analysis. "To quantify a chess move's counter-intuitiveness, we compare evaluation scores from a chess engine using different search depths."
- Critical depth: The search depth at which the engine first finds the final correct solution. "with the `critical depth' (the depth StockFish first finds the final solution) being the dominant term."
- Critical search point: The earliest search time where the evaluation stabilizes within a tolerance. "the critical search point where the evaluation becomes stable (\cref{eq:counterintuitiveness3})."
- Diversity filtering: An RL mechanism that promotes exploration by filtering for novelty across board, PV, and entropy metrics. "Therefore, we developed a diversity filtering mechanism (\cref{sec:rl}) that promotes exploration and diversity."
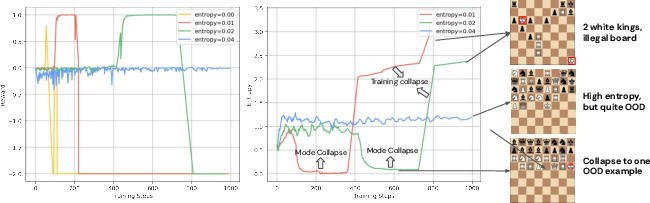
- Entropy collapse: A failure mode where the model repeatedly generates the same high-reward output, losing diversity. "RL with pure puzzle reward would quickly succumb to 'entropy collapse' by repeatedly generating one single high-reward puzzle."
- Entropy regularization: A training technique that encourages higher entropy (more exploratory) policies. "this indeed happens frequently when maximizing reward, even with explicit entropy regularization."
- Forsyth-Edwards Notation (FEN): A compact textual representation of a chess position used as a discrete sequence for modeling. "We represent it using the Forsyth-Edwards Notation (\citep{chesscom:fen}, FEN) as a discrete sequence"
- Golden Set: A curated collection of positive and negative examples used to tune counter-intuitiveness weights. "The Golden Set . The weights are tuned on a small, manually curated set of 39 positive and 45 negative TRAIN examples."
- Interference: An aesthetic theme where a move obstructs an opponent piece’s line, enabling a tactic or mate. "7 aesthetic themes were selected for the study (sacrifice, underpromotion, attacking withdrawal, novotny, interference, unprotected position and knight on the rim is dim)."
- Knight on the rim is dim: A thematic motif highlighting the limited power of a knight on the board’s edge, used as an aesthetic category. "7 aesthetic themes were selected for the study (sacrifice, underpromotion, attacking withdrawal, novotny, interference, unprotected position and knight on the rim is dim)."
- Kullback-Leibler (KL) divergence: A measure of difference between probability distributions used to constrain RL updates. "We incorporate a token-level Kullback-Leibler (KL) divergence penalty into the reward function."
- Latent diffusion model: A diffusion-based generative model operating in a learned latent space rather than pixel/token space. "For the latent diffusion model experiment, we investigate the impact of different chessboard representations on the generative model's performance."
- Levenshtein distance: The minimal number of single-character edits required to transform one string into another. "we measure syntactic similarity using the Levenshtein distance \citep{levenshtein1966}"
- Lichess Puzzler dataset: A large, public dataset of chess puzzles used for training and benchmarking generative models. "including auto-regressive transformers \citep{vaswani2017attention}, latent diffusion models \citep{rombach2022high}, masked discrete diffusion models \citep{shi2024simplified}, and MaskGIT \citep{chang2022maskgit} -- all trained on the Lichess Puzzler dataset."
- MaskGIT: A masked token iterative decoding generative transformer approach. "including auto-regressive transformers \citep{vaswani2017attention}, latent diffusion models \citep{rombach2022high}, masked discrete diffusion models \citep{shi2024simplified}, and MaskGIT \citep{chang2022maskgit}"
- Masked diffusion model: A discrete diffusion framework that generates sequences by iterative denoising with masking. "masked diffusion model \citep{shi2024simplified}"
- Monte-Carlo samples: Sample-based estimates of returns/advantages used in critic-free PPO variants. "This version estimates the value/advantage function using Monte-Carlo samples \citep{li2023remax, ahmadian2024back, shao2024deepseekmath, kazemnejad2024vineppo, hu2025reinforce++}."
- Novotny: An interference-based composition theme where a sacrificial move blocks two defensive lines simultaneously. "7 aesthetic themes were selected for the study (sacrifice, underpromotion, attacking withdrawal, novotny, interference, unprotected position and knight on the rim is dim)."
- Outcome reward: A final scalar reward assigned after generating the complete sequence, reflecting overall quality. "Rewards are typically sparse, with zero intermediate reward and a final outcome reward assigned to the complete sequence "
- Piece regularization: A realism-preserving rule that penalizes positions with implausible extra pieces. "Piece regularization. We find that the model can easily learn to artificially inflate reward and entropy by adding pieces (e.g., two white queens or three black knights)."
- Principal Variation (PV): The best line of play found by a chess engine during search, used for uniqueness and novelty checks. "the Principal Variation (\citep{cpw:principal_variation}, PV) derived from StockFish ."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that stabilizes updates via clipped objective functions. "utilize a critic-free variant of Proximal Policy Optimization \citep[PPO]{schulman2017proximal}."
- PV distance: A novelty metric defined as the normalized Levenshtein distance between PV sequences of two positions. "the PV distance is defined as "
- Reinforcement Learning from Human Feedback (RLHF): An RL paradigm using human preference signals to guide model training. "drawing inspiration from RLHF practices \citep{ouyang2022training}"
- Replay buffer: A memory storing prior qualified samples to support diversity checks and training stability. "We maintain a replay buffer to store preceding qualified and novel samples and subsample a small set of it for each inter-batch checking."
- Reward hacking: Model behavior that exploits the reward function to achieve high scores in unintended ways. "The models exhibited tendencies towards "reward hacking," such as entropy collapse (generating the same puzzle repeatedly), producing unrealistic samples"
- Sequence-level entropy: The average token-level entropy across a generated sequence, used as a diversity indicator. "the sequence-level entropy is calculated as the average token-level entropy: $H^{\text{seq}(s_T) = \frac{1}{T}\sum_{i=0}^{T-1} H(s_{i+1}|s_{0:i}),$"
- StockFish: A state-of-the-art open-source chess engine used for evaluation, uniqueness checks, and search statistics. "To confirm that a chess position represents a puzzle with a single unique solution, we utilize the StockFish engine, following the Lichess Puzzler methodology."
- SwiGLU: A gated linear unit activation variant used in transformer architectures for improved performance. "decoder-only transformer with causal masking, post-normalization and SwiGLU \citep{shazeer2020glu}."
- Tokenization: The process of mapping a chessboard representation into discrete tokens for sequence modeling. "adopt a chess-specialized tokenization \citep{ruoss2025amortized} with a vocabulary of 31 tokens."
- U-net Transformer: A diffusion-model backbone combining U-Net structure with transformer blocks. "we employ the U-net transformer architecture from \citep{petit2021u} with the frozen VAE encoder."
- Underpromotion: Promoting a pawn to a minor piece instead of a queen for tactical or aesthetic effect. "7 aesthetic themes were selected for the study (sacrifice, underpromotion, attacking withdrawal, novotny, interference, unprotected position and knight on the rim is dim)."
- Uniqueness: The property that a puzzle has exactly one optimal solution move, exceeding a threshold gap in winning chances. "A move is considered unique if the difference in these winning chances meets or exceeds an empirically chosen threshold ():"
- Variational Autoencoder (VAE): A generative model that learns latent representations via variational inference. "We first train a VAE model on the same puzzle dataset."
Collections
Sign up for free to add this paper to one or more collections.