- The paper introduces a unified Tool-to-Agent Retrieval framework that embeds both tools and agents in a shared vector space to improve query routing and context fidelity.
- It employs a dual-layer indexing and top-K retrieval process to preserve fine-grained tool metadata while optimizing multi-step query handling.
- Experimental evaluations show up to 19.4% improvement in Recall@5 and 17.7% in nDCG@5, demonstrating enhanced scalability and robustness.
Introduction
Recent developments in LLM multi-agent systems have allowed scalable orchestration through the use of sub-agents that coordinate numerous tools and Model Context Protocol (MCP) servers. Traditionally, retrieval methods matched queries with broad agent-level descriptions before routing, often masking specific tool functionalities. This paper proposes a unified Tool-to-Agent Retrieval framework that embeds both tools and agents within a shared vector space, facilitating joint retrieval and traversal while preserving fine-grained tool-level data without terminal context dilution.
Conceptual Framework
Tool-to-Agent Retrieval is designed to efficiently navigate LLM multi-agent systems by embedding tools and agents in a unified vector space, using metadata relationships to bridge them. This enables the system to reach decisions on whether to address an agent or a specific tool based on the query requirements, thus optimizing retrieval performance.
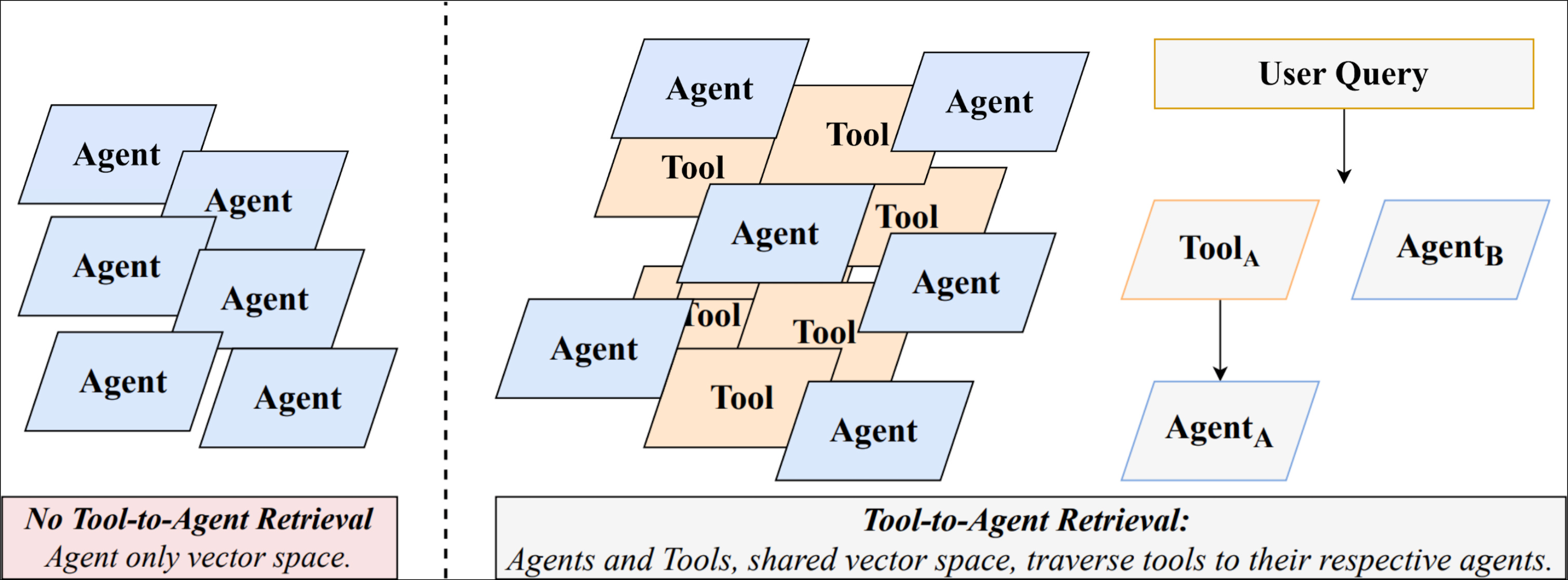
Figure 1: Comparison of agent-only retrieval (left) and the proposed Tool-to-Agent Retrieval (right), which embeds tools and agents in a shared vector space to support joint retrieval and traversal.
By employing this embedding technique, both tool and agent capabilities are assessed at retrieval, facilitating more precise routing in multi-step queries. Consequently, the framework circumvents the challenges associated with agent-first and tool-only retrieval by supporting diverse query specifications.
Retrieval Procedure
The retrieval process uses a top-K approach, where entities are ranked via semantic similarity to user queries and a unified index is utilized to fetch the most fitting tool or agent bundle. Here, N entities are initially retrieved, significantly larger than K, then appropriately sorted by agent relevance before final selection. Algorithm~\ref{alg:cta-select} provides a detailed step-by-step procedure for the retrieval process, ensuring robust scalability and adaptability to complex workflows.
Within the combined corpus, each tool is linked to its parent MCP server using explicit metadata, while agents serve as parent nodes within the retrieval graph. This structure ensures that even when a tool is retrieved individually, its operational context through the parent agent is preserved.
Experimental Evaluation
Dataset and Protocol
The evaluation uses the LiveMCPBench dataset, which encompasses an extensive collection of 70 MCP servers and 527 distinct tools linked to 95 annotated real-world queries. Through comparative evaluation against baseline methods, including BM25, ScaleMCP, and others, the Tool-to-Agent Retrieval approach demonstrates superior performance.
Across metrics such as Recall@5 and nDCG@5, Tool-to-Agent Retrieval achieves significant improvements. For example, enhancements of 19.4% in Recall@5 and 17.7% in nDCG@5 over previous best-performing agent retrieval systems were observed. This consistent performance is evident across various embedding models, including proprietary systems such as Amazon Titan and open-source alternatives like MiniLM.
Generalizability and Scalability
Scalability is largely attributed to the dual-layer indexing of both tools and agents, which enables finer semantic alignment while retaining crucial agent context. Notably, leveraging both tool and agent data allows superior retrieval outcomes, confirmed by model-agnostic improvements and increased robustness in multi-step workflow scenarios.
Conclusion
The Tool-to-Agent Retrieval framework presents a robust method to enhance agent and tool retrieval in LLM multi-agent systems. By unifying tools and agents within a shared vector space, embedded with metadata linkage, the system enhances retrieval precision and context fidelity, delivering notable gains over conventional methods. The demonstrated improvements in standard retrieval benchmarks suggest future research should explore further integration of retrieval architectures and their dynamic scalability.