- The paper introduces a SAFE plugin that leverages GPT-4o to generate context-aware vulnerability explanations, bridging gaps in SAST usability.
- It employs a modular pipeline that parses SARIF outputs, extracts code context, and utilizes role-played prompts to tailor explanations to developer skill levels.
- Benchmarking shows that reasoning-oriented LLMs perform well under zero-shot prompting, highlighting a balance between recall and precision in vulnerability detection.
Motivation and Problem Statement
Contemporary software systems are increasingly threatened by security vulnerabilities enumerated in sources such as the CWE Top 25. Enterprises rely on static application security testing (SAST) tools for automated vulnerability detection, but SAST warning messages often lack specificity and actionable context, leading to misunderstandings or disregard by developers. Traditional SAST tools do not sufficiently adapt explanations to varying developer expertise levels, nor do they conveniently contextualize detection results using natural language. Advances in LLMs for code understanding and generation raise prospects for improving SAST explainability not by replacement, but through hybrid augmentation. This paper introduces SAFE, an IntelliJ IDEA plugin leveraging GPT-4o to generate nuanced, context-aware vulnerability explanations, thereby bridging SAST usability gaps.
System Architecture: SAFE Plugin
SAFE is architected as an IDE-integrated explainer for SAST tool results. The system pipeline comprises: parsing SARIF-formatted SAST outputs, extracting code context and data-flow information (such as threadFlows relevant for taint analysis), annotating findings from security catalogs (e.g., CWE and critical method lists), and constructing role-played prompts for the deployed LLM.
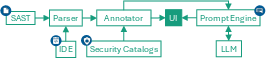
Figure 1: SAFE plugin architecture showing modular flow from SAST results, code context extraction, annotation, prompt generation, LLM explanation, and UI presentation.
The prompt template adapts explanation detail to the developer’s expertise (beginner/intermediate/advanced), integrating rule name/message, code snippet, vulnerable line, and taint data-flow. Zero-shot prompting with explicit security expert role ensures neutral, contextually relevant, and detailed vulnerability elucidation.
User Interface and Interaction
SAFE’s UI is realized as an IntelliJ tool window, combining hierarchical SARIF result visualization with tabbed panes for result details, LLM-generated explanations, and detailed data-flow views.
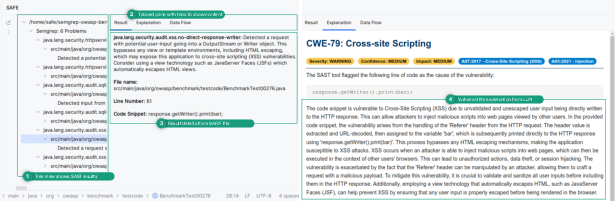
Figure 2: SAFE’s window displaying SAST findings, LLM explanations, and context-specific data-flow, facilitating developer comprehension at various expertise levels.
The explanation tab aggregates vulnerability type, severity, impact, tool confidence, mitigation strategies, and interactive feedback (thumbs up/down). This multimodal information presentation is designed to improve developer engagement and facilitate targeted remediation efforts, with the capability to tailor explanations for skill-specific comprehension.
Benchmarking LLMs for Vulnerability Detection
A systematic benchmark (VuLLMBench) was developed to compare 22 open and closed-source LLMs (e.g., GPT-5, o3-mini, Llama3.1, Deepcoder, CodeGemma, CodeLlama) using the OWASP Benchmark through various prompt strategies: zero-shot, few-shot, and chain-of-thought. Zero-shot prompting yielded best detection performance. Models with reasoning-oriented design (GPT-5 and o3-mini) achieved highest F1-scores (>$0.83$) due to advanced decision-making under code ambiguity, while general-purpose and code-specialized models (GPT-4o, Llama3.1, Deepcoder) showed high recall but lower precision, producing excess false positives.
Minor lexical obfuscations (renaming identifiers) negatively impacted LLM robustness, highlighting susceptibility to superficial code changes—unlike SAST tools, which proved more resilient. SAFE's LLM integration thus targets explanation rather than detection.
Evaluating Explanation Quality
Explanations generated by GPT-4o in SAFE were human-evaluated by software security trainers across five criteria: relevance, faithfulness, concision, coherence, and accuracy. Explanations for the three CWE-critical vulnerabilities (Path Traversal, SQL Injection, Cross-site Scripting) exhibited strong accuracy (90% rated good-to-very-good) and faithfulness (no hallucinations), with modest variability in relevance and conciseness.
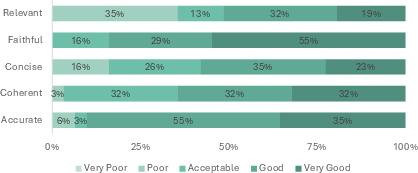
Figure 3: Human expert evaluation of SAFE explanations shows most are rated at least acceptable, with highest marks in faithfulness and accuracy but room for improvement in relevance and conciseness.
SAFE explanations were consistently superior to generic SAST messages in causal, impact, and mitigation detail. Feedback recommended further prompt refinement for skill-level specificity, automatic skill detection, and improved structuring of mitigation strategies.
Prior static analysis explainability approaches have focused on rule graph visualizations, presupposing taint analysis domain knowledge. SAST+LLM hybrid methods such as LLMVulExp and LLM4SA have explored LLMs for automated bug triage and false positive filtering, but SAFE uniquely targets post-SAST explanation granularity, integrating detection context into LLM-naturalized developer guidance.
Practical and Theoretical Implications
Integrating LLMs into developer-facing vulnerability explanation constitutes a pragmatic augmentation of SAST tools, addressing usability and cognitive accessibility gaps especially for nonspecialist developers. Hybrid approaches improve warning interpretability and remedial actionability, while maintaining SAST precision for critical systems. Theoretical implications include emergent paradigms for explainable AI in software security, skill-adaptive technical communication, and joint reasoning pipelines where SAST precision is complemented by LLM narrative and reasoning.
Limitations and Future Directions
SAFE’s evaluation relied on expert trainers; generalizability to its intended audience (beginner/intermediate developers) requires further large-scale studies. The relationship between LLM detection performance and explanation quality remains empirically underexplored. Mitigation of false positive explanation bias necessitates LLM validation steps. Automatic skill-level detection and tailored prompt refinement promise further improvements. Future development trajectories include wider IDE/tool integration, fine-tuning for explanation accuracy, and enhancing robustness against code obfuscation.
Conclusion
SAFE demonstrates that augmenting SAST tools with LLM-generated explanations markedly improves usability and comprehension for developers with limited security expertise. The hybrid pipeline capitalizes on SAST reliability and LLM narrative clarity, facilitating actionable vulnerability mitigation. Continued refinement and broader empirical validation will further clarify its potential as a standard mechanism in secure software engineering workflows.

