- The paper introduces a probabilistic deep learning framework that directly predicts Beta distributions to quantify roadway crash risks.
- It leverages multi-scale satellite imagery and dynamically generated, context-aware labels to improve recall and ensure calibrated uncertainty.
- The method achieves up to 23% recall improvement and superior uncertainty metrics, enabling efficient and interpretable risk predictions.
Beta Distribution Learning for Reliable Roadway Crash Risk Assessment
Problem Statement and Motivation
Roadway crashes result in substantial global fatalities and economic losses annually. Traditional approaches to crash risk estimation—whether through epidemiological analysis of isolated variables, simulation-based probabilistic models, or classification via DNNs—face fundamental limitations dealing with data sparsity, high-risk event rarity, and lack of reliable uncertainty quantification. Most prior deep learning approaches yield overconfident point estimates, are prone to systematic miscalibration, and do not scale to environments where ground-truth labeling is prohibitively expensive.
This work introduces a geospatial deep learning framework for crash risk estimation that provides full uncertainty quantification by directly predicting a Beta distribution over the risk score for each spatial location. The central hypothesis is that leveraging richly informative satellite imagery at multiple resolutions, formulating the task as distribution learning rather than classification, and procedurally constructing dynamic, context-aware labels yields a predictive model with significantly improved recall and genuinely calibrated uncertainty, crucial for deployment in safety-critical real-world applications.
Conventional DNNs trained on sparsely labeled crash/no-crash data are susceptible to overfitting and fail to express epistemic or aleatoric uncertainty in predictions. This framework replaces binary labels with procedurally generated Beta distributions as targets, parameterized per training instance to encode the informativeness of each augmented sample. For negative samples, targets are sharply peaked near zero; for positives, the distribution's mean and concentration are continuously modulated by a convex combination of crop centrality with respect to the crash site and the proportion of scene coverage, reflecting spatial relevance.
Labels are not fixed but adapt to the actual evidence present in the training crop—fusing data augmentation with label smoothing in a structured, semantically meaningful manner. The weighting of centrality (0.7) and size (0.3) is empirically selected to privilege spatial proximity to risk-critical features. This network, then, is trained to map image regions to the full posterior Beta distribution, from which expected risk (mean) as well as calibrated uncertainty (variance, confidence intervals) can be extracted per inference instance.
Model Architecture and Optimization
The core architecture is a multi-scale convolutional pipeline (ResNet-50 backbone) consuming stacks of aligned satellite images at different resolutions to capture complementary micro- and macro-level visual information.
During training (Figure 1):
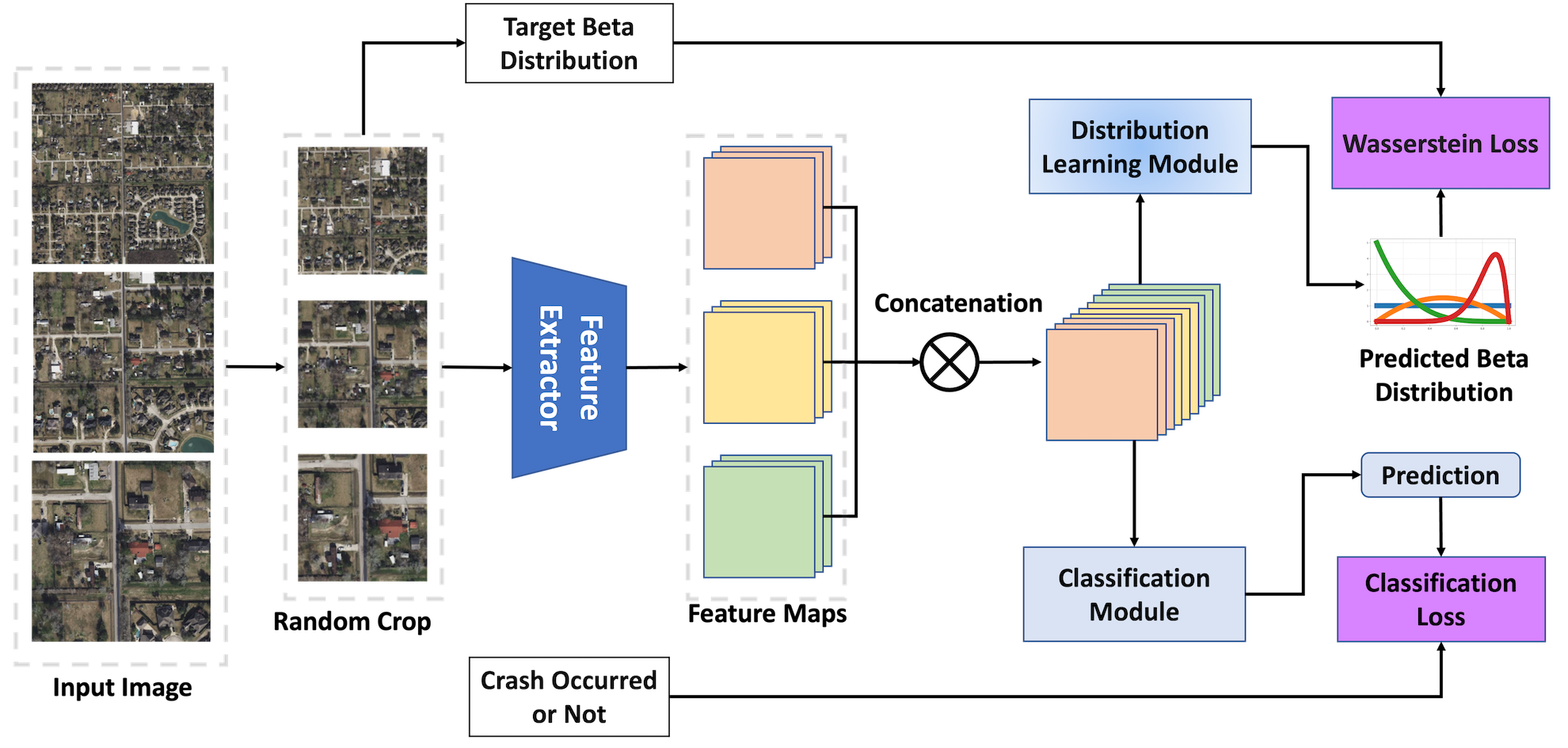
Figure 1: Model training dynamically samples random crops from multi-scale images and optimizes both Beta distribution parameters and auxiliary crash classification jointly.
Cropped, multi-resolution images are processed through a shared feature extractor. Resulting features are passed to two parallel output heads: the main distribution learning head (outputs α, β for the Beta distribution), and an auxiliary classification head (binary crash/no-crash logit). The compound joint loss includes: (1) a mean-variance Wasserstein-2-inspired surrogate, which directly enforces alignment of both mean and variance between predicted and target Beta distributions, and (2) weighted binary cross-entropy to maintain discriminative power.
At inference (Figure 2):
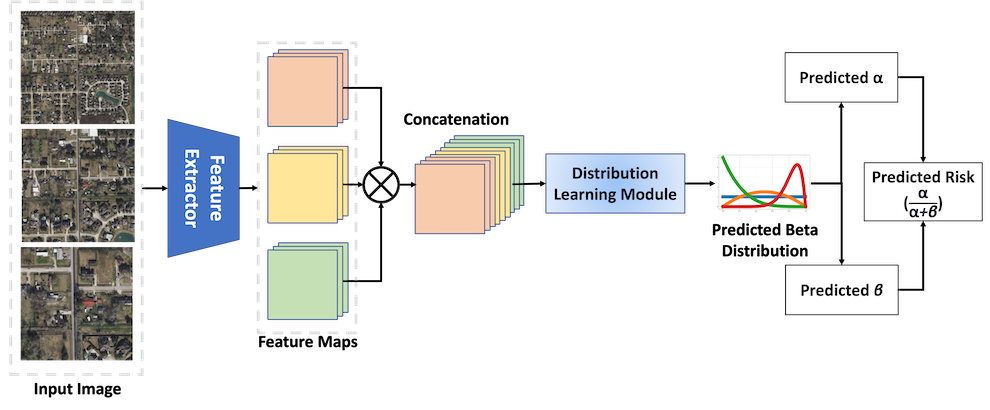
Figure 2: At inference, the streamlined model predicts the Beta distribution parameters and risk score for any spatial location without data augmentation or auxiliary heads.
The full, uncropped multi-scale image is processed to estimate crash risk with a single model evaluation per region—crucial for large-scale deployment.
The evaluation on the MSCM dataset (over 16,400 annotated crash locations) includes multiple baselines (single/multi-scale feature extractors, ImageNet, cross-matching domain pretraining) and ensemble approaches. The model's primary measured metric is Recall, considering the risks of false negatives in safety-critical outcomes. Calibration is quantified using ECE and Brier score.
Highlights:
- Prob-MS (multi-scale, Beta learning) improves Recall by 17% over MSCM-MS (state-of-the-art baseline), reaching 0.5311 compared to 0.4521.
- Prob-SS (single-scale, Beta learning) yields 23% higher recall than its best single-scale baseline.
- The method delivers the lowest (best) uncertainty calibration metrics across all models evaluated.
- The single probabilistic model matches or exceeds the performance of deep ensembles of deterministic baselines at one-third the computational cost.
Uncertainty Quantification and Case Analysis
Explicit distributional prediction allows post-hoc inspection of each risk estimate's confidence. Figure 3 illustrates how the predicted Beta distribution width encodes uncertainty for each region or crop.
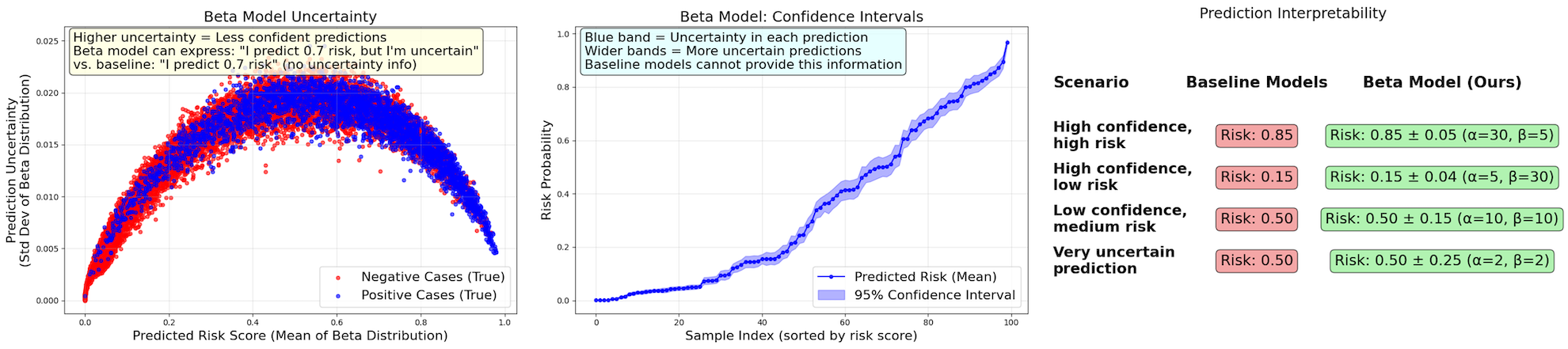
Figure 3: Top: Uncertainty is lowest for highly confident predictions (risk near 0 or 1) and maximal for ambiguous intermediate predictions; confidence intervals provide per-decision reliability.
Empirically, the Beta-based model avoids the overconfident mode-collapsed predictions typical of standard classifiers, producing a risk distribution across the entire [0,1] interval (Figure 4), while baselines produce only edge-case outputs.
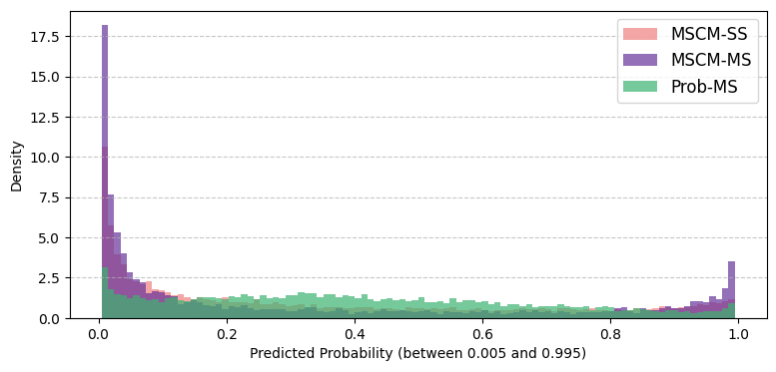
Figure 4: The distribution of predicted probabilities is much more rational and nuanced for the Beta model, indicating the ability to express varying confidence.
Case studies in urban, visually complex environments (San Antonio River Walk) show the model delivers not only higher recall for true crash sites, but also spatially coherent risk fields that better reflect the built environment's contextual hazards (Figure 5).
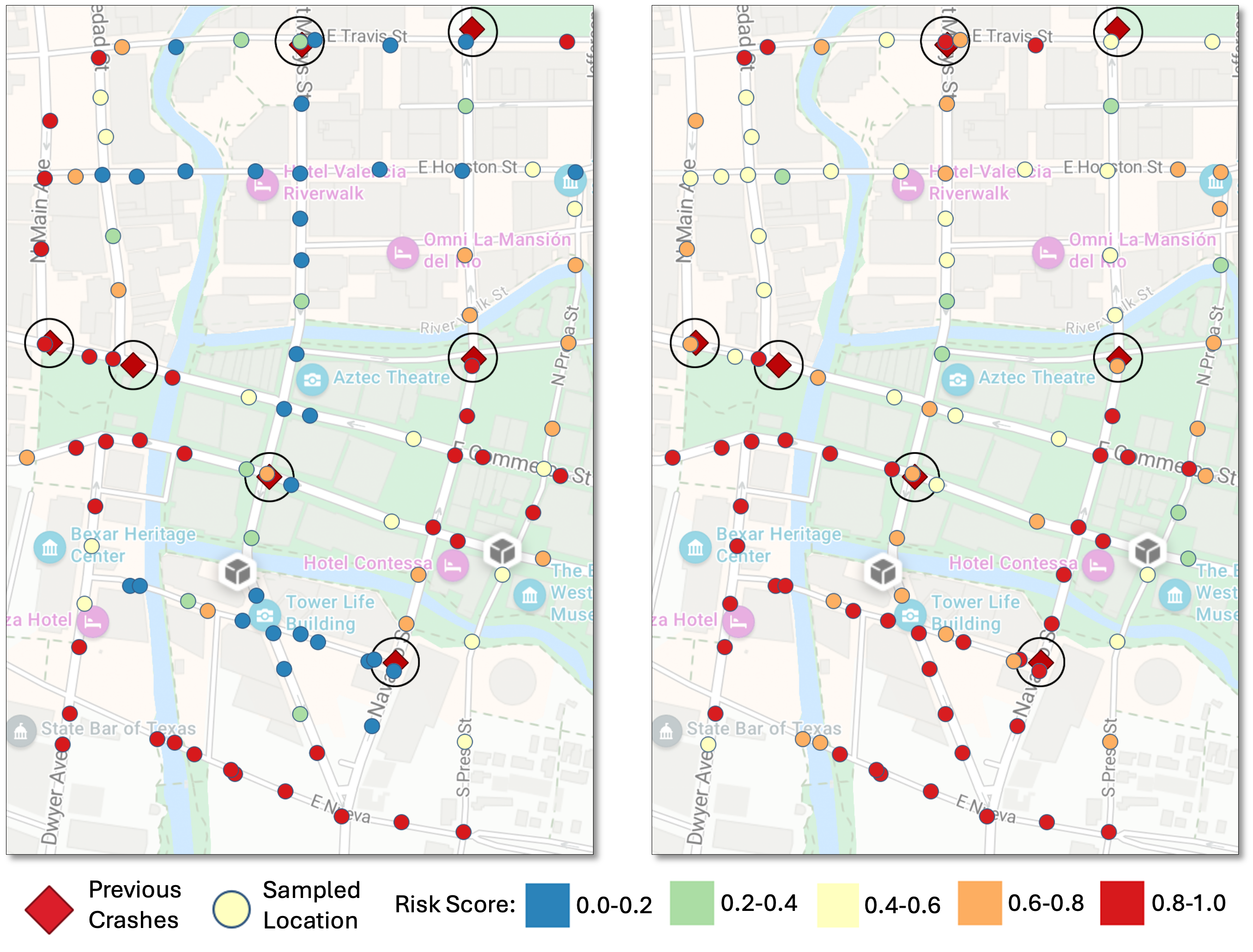
Figure 5: In a complex real-world area, the probabilistic model identifies more high-risk sites with greater spatial coherence and realistic gradation, reflecting plausible transitions in risk.
Interpretability is further enhanced; per-instance distribution width increases on ambiguous inputs, such as dense urban intersections or complex interchanges, and not just on failed cases (false positives/negatives).
Theoretical and Practical Implications
This work demonstrates the benefits of recasting crash risk estimation as a full probabilistic learning problem. The Beta distribution learning paradigm increases robustness to data sparsity and label noise, provides actionable uncertainty estimates for human-in-the-loop systems, and enables risk assessment from purely visual (satellite) inputs, decoupling performance from local data availability or privacy constraints. This approach is agnostic to the underlying sensor, scalable to regions lacking dense traffic statistics, and fundamentally more equitable for universal deployment.
Practically, the resulting model directly supports safer route planning (AV navigation), automated hazard triage for infrastructure remediation, and prioritization in resource allocation for urban planners. The explicit uncertainty provided allows domain experts to modulate risk thresholds and interpret model ambiguity, reducing overconfidence in edge cases and improving overall trustworthiness.
Limitations and Future Directions
The framework, while significantly advanced in its uncertainty quantification and interpretability, operates on static imagery and historic event data, omitting real-time variables like temporally fluctuating traffic or weather conditions. Future directions include integrating dynamic multi-source data streams (video, LiDAR, traffic sensors), extending the procedural label generator to include additional geospatial priors or learned weighting, and validating model generalization via cross-region transfer testing. There is scope for coupling the model to causal-inference approaches for mechanistic interpretability, and for exploring robust calibration under dataset shift.
Conclusion
This research formalizes crash risk as a spatial probability field and operationalizes distribution prediction using a Beta network trained with algorithmically constructed soft labels and a compound distributional loss. The resulting model achieves higher recall, better calibration, and greater interpretability compared to SOTA deterministic DNNs, with substantial implications for scalable, responsible AI deployment in public safety and urban infrastructure. This work substantiates the value of moving from point estimates to well-calibrated, uncertainty-aware models in high-stakes spatial domains.