- The paper introduces a novel time-aware reinforcement learning framework that integrates temporal signals into policy learning for dynamic adaptation.
- It significantly improves task efficiency by reducing completion time by 48% and cutting manipulation noise by over 90%.
- The framework enhances robustness and coordination in multi-agent systems, paving the way for adaptive and punctual robot control.
Time-Aware Policy Learning for Adaptive and Punctual Robot Control
Introduction
The concept of temporal awareness in robot control underpins intelligent behaviors similar to those observed in humans, where actions are sequenced and paced based on dynamic contexts. Yet, most conventional robot learning frameworks lack explicit mechanisms for time awareness, focusing primarily on maximizing task success without temporal scheduling. This paper, "Time-Aware Policy Learning for Adaptive and Punctual Robot Control" (2511.07654), introduces a reinforcement learning framework that endows robots with the ability to perceive and act upon time as a fundamental variable. This approach demonstrates significant improvements in task efficiency, robustness, and temporal punctuality across diverse robotic manipulation tasks.
Methodology: Time-Aware Policy Learning Framework
The framework integrates time into the robot's policy as a controllable signal, allowing the modulation of behavior from rapid execution to careful, precise movements. This is achieved through the introduction of two temporal signals: remaining time and time ratio. These signals guide the robot in balancing efficiency and stability, adapting dynamically without re-training or reward adjustment. The training pipeline is structured as follows:
- Temporal Lower Bound Estimation: Initially, the robot learns the minimum temporal duration for task completion, establishing a baseline of efficient behavior and temporal expectation.
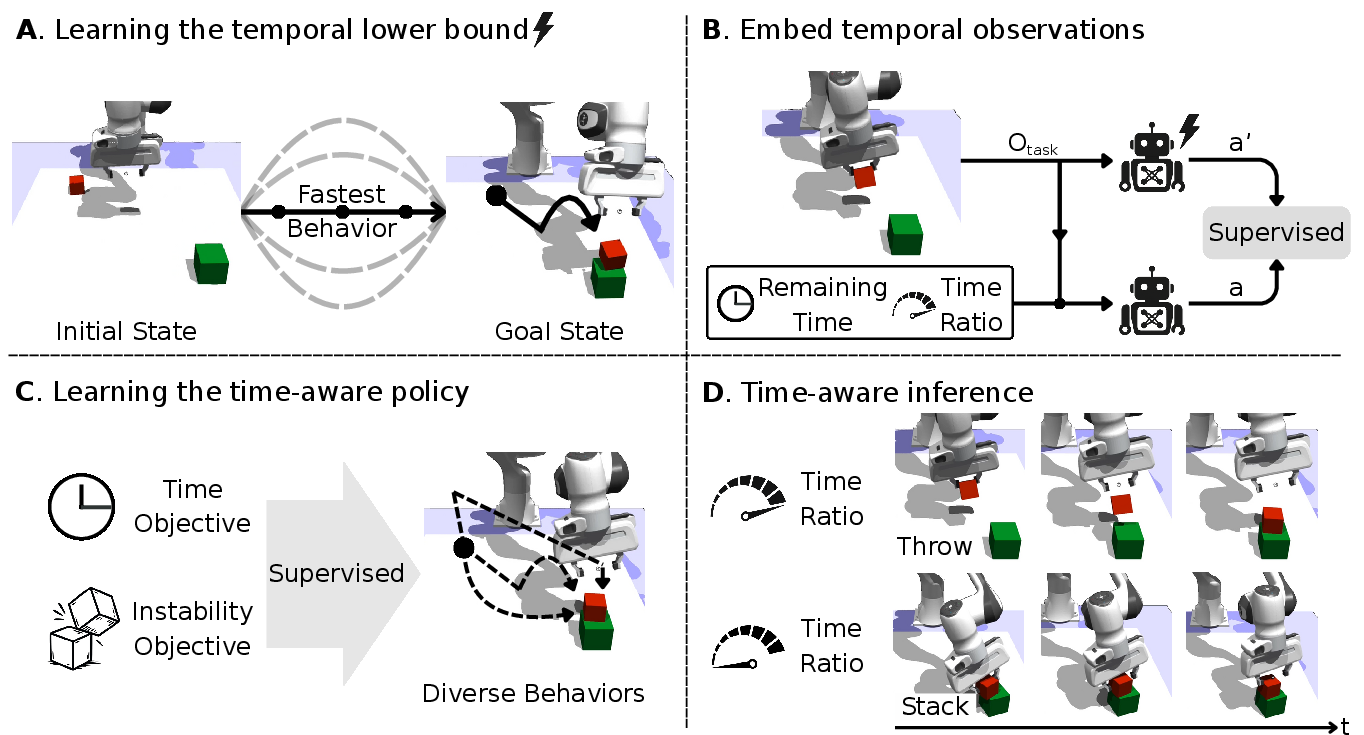
Figure 1: Time-aware policy learning pipeline. (A) A standard RL policy is refined with a minimum-time objective to obtain the fastest feasible strategy. (B) Remaining time and time-ratio signals are appended to the observation space.
- Time-Aware Policy Training: The robot's policy is augmented with temporal variables, conditioned on both scheduled durations and dynamic adaptations based on environmental feedback.
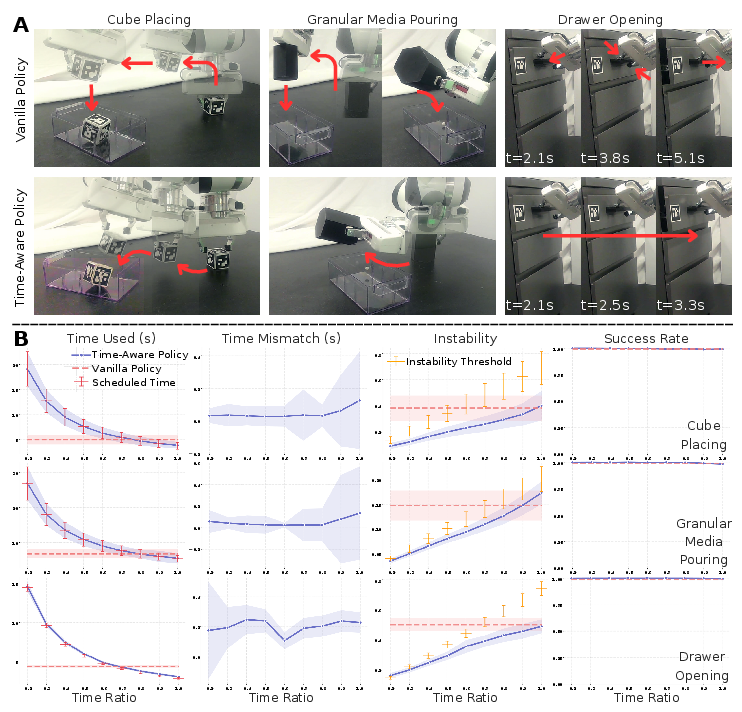
Figure 2: Time awareness improves efficiency and punctuality across simulated benchmarks, demonstrating faster task completion and adherence to scheduled durations.
Experimental Results
Experimental evaluations showcase the framework's efficacy across multiple task domains, including cube stacking, granular media pouring, drawer opening, and collaborative object delivery. These tasks were tested both in simulation and real-world environments to validate the robustness and adaptability of the time-aware framework.
- Efficiency and Punctuality: The time-aware policy significantly reduced task completion times while maintaining punctuality even under tight time constraints. For example, in cube placing tasks, the policy completed actions 48% faster than the baseline.
Figure 2: Time awareness improves efficiency and punctuality by leveraging dynamic strategies and temporal modulation.
- Stability and Robustness: The introduction of temporal awareness enables the policy to adapt to unseen dynamic changes and disturbances, enhancing generalization and reducing manipulation noise by over 90%.
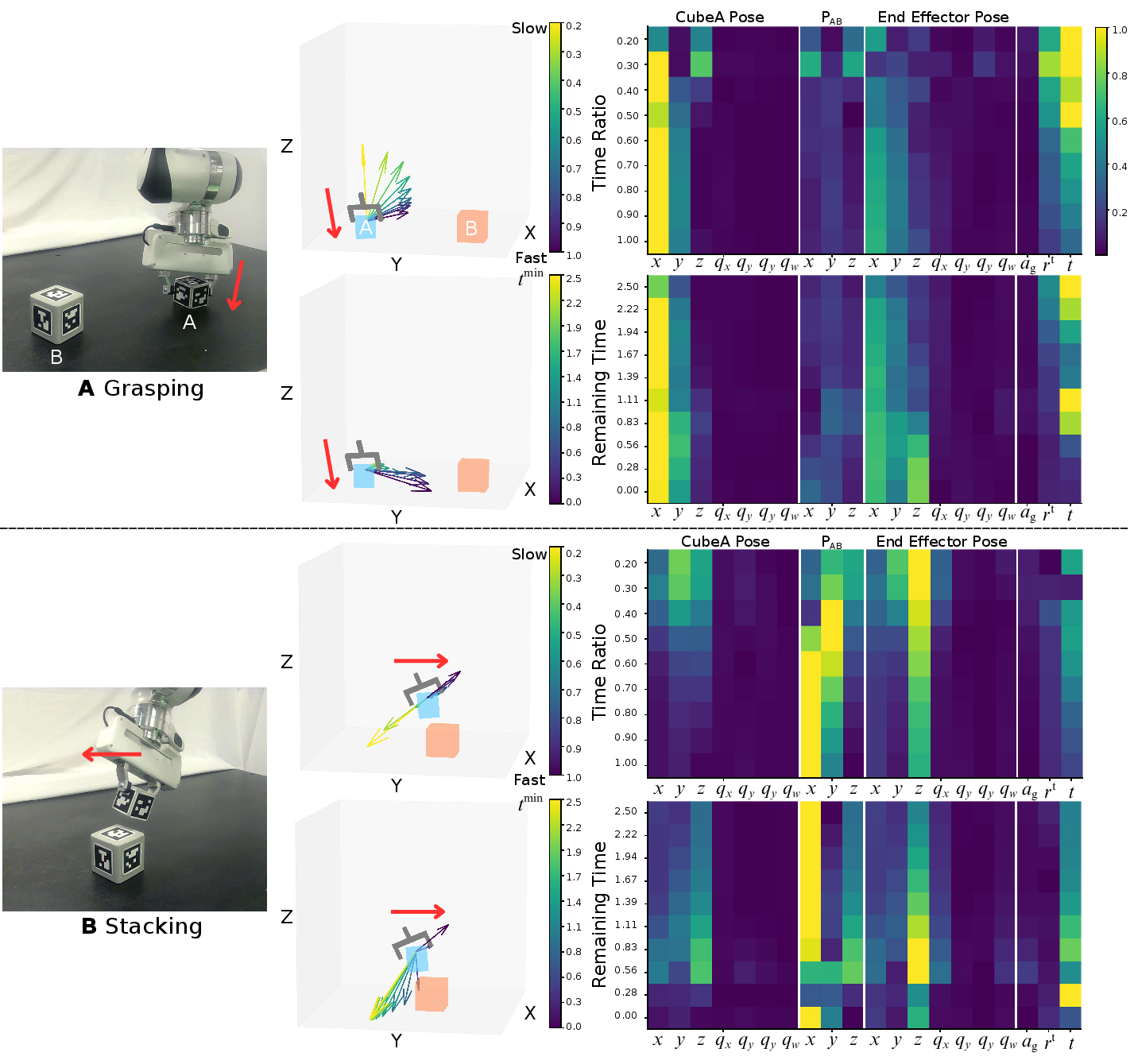
Figure 3: Temporal observations modulate action generation and observation saliency during manipulation tasks.
- Multi-Agent Collaboration: The framework facilitates precise coordination in multi-agent systems, optimizing for punctual collaboration under varied and perturbed conditions.
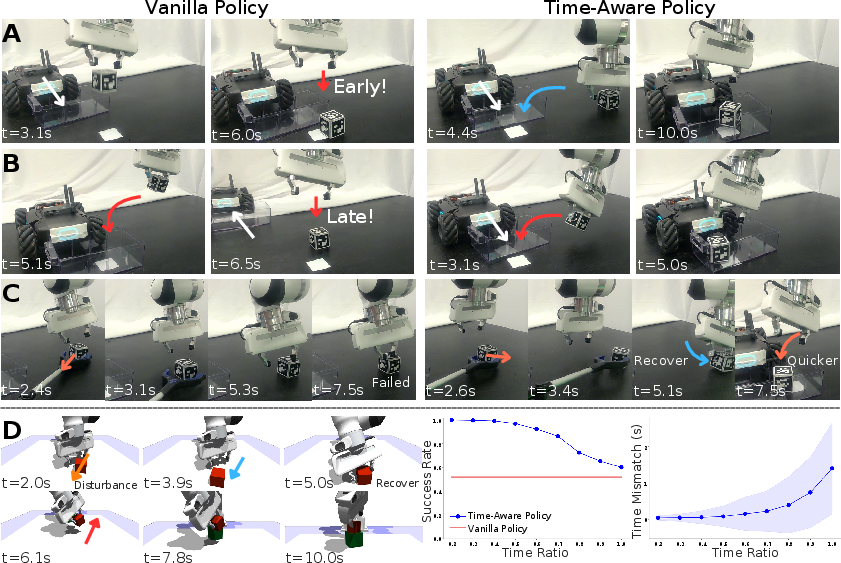
Figure 4: Time-aware policy enables punctual and robust multi-agent collaboration with effective behavior modulation in collaborative tasks.
Discussion and Future Directions
The time-aware policy learning framework represents a shift in robotic policy design, treating time as an explicit control variable rather than merely a constraint. This integration allows enhanced flexibility, robustness, and adaptability in robot behaviors across varying task constraints and environments.
Future research directions may explore:
- Advanced Stability Metrics: Incorporating more granular measures of dynamics stability such as acceleration and jerk for enhanced control fidelity.
- Multi-Task Learning: Extending the framework to learn temporal priors across multiple tasks for more generalizable skill acquisition.
- Multimodal Perception Integration: Incorporating sensory data for robustness against occlusion and to improve real-world deployability.
- Human Interaction Studies: Exploring human-in-the-loop control to understand subjective perceptions of temporal control mechanisms.
By elevating time to a first-class variable in policy learning, this framework opens novel avenues for efficient, adaptable, and human-aligned robot control, promising advancements in autonomy across domains such as assistive robotics, industrial automation, and collaborative human-robot environments.