Φeat: Physically-Grounded Feature Representation
Abstract: Foundation models have emerged as effective backbones for many vision tasks. However, current self-supervised features entangle high-level semantics with low-level physical factors, such as geometry and illumination, hindering their use in tasks requiring explicit physical reasoning. In this paper, we introduce $Φ$eat, a novel physically-grounded visual backbone that encourages a representation sensitive to material identity, including reflectance cues and geometric mesostructure. Our key idea is to employ a pretraining strategy that contrasts spatial crops and physical augmentations of the same material under varying shapes and lighting conditions. While similar data have been used in high-end supervised tasks such as intrinsic decomposition or material estimation, we demonstrate that a pure self-supervised training strategy, without explicit labels, already provides a strong prior for tasks requiring robust features invariant to external physical factors. We evaluate the learned representations through feature similarity analysis and material selection, showing that $Φ$eat captures physically-grounded structure beyond semantic grouping. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics.




































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper builds a new kind of vision model that “looks” at images in a more physics-aware way. Instead of focusing mainly on what an object is (like cat, car, or chair), the model learns to notice what the object is made of (like wood, metal, fabric), and how light, shape, and transparency affect its appearance. The big idea: train the model to recognize the same material even when it’s put on different shapes and lit by different lights.
What questions does the paper ask?
- Can we teach a vision model to recognize materials (like marble vs. plastic) by how they look under different lighting and shapes, without using human labels?
- Can such a model ignore “distracting” things like the object’s overall shape or the lighting setup, and focus on the material’s true visual clues (its reflectance, texture, and fine surface details)?
- Do these physics-aware features help on tasks like selecting all regions of the same material in an image?
How did they do it?
To keep this simple, think of the model as learning material “fingerprints.”
- Data like a science lab: The authors rendered about a million images using digital materials (wood, metal, fabric, etc.). Each material was shown on different 3D shapes and under different lighting environments. It’s like photographing the same fabric on a pillow, a curtain, and a dress, under sunny, cloudy, and indoor lights. This controlled setup helps the model learn what truly belongs to the material and what’s just lighting or shape.
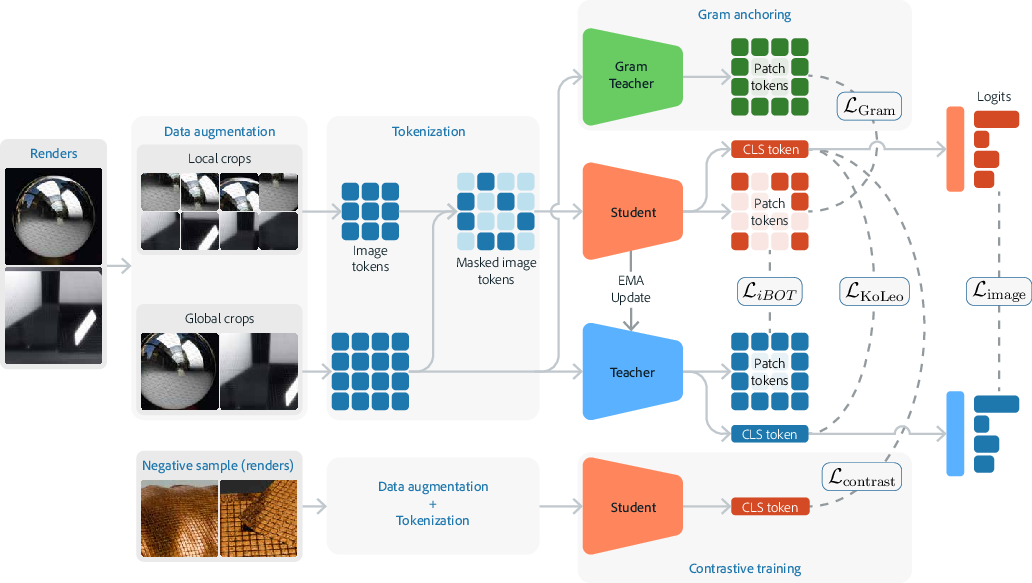
- The model’s “teacher and student”: They use a popular self-supervised setup where two copies of the model work together. The “teacher” guides the “student” to produce similar features on different views of the same material. No human-made labels are needed—just pairs of images that are known to be the same material in different conditions.
- Crops and patches: Each image is split into small tiles (patches), and the model learns both a whole-image summary and tile-level features. This helps it understand global look (overall sheen of metal) and local texture (tiny weave of fabric).
- “Pull together” and “push apart”: The model is trained to pull together features from different images of the same material and push apart features from different materials. An easy analogy: it sorts picture “fingerprints” so that all wood fingerprints cluster together, while metal fingerprints form a different cluster.
- Extra training tricks (explained simply):
- Mask-and-predict patches: Hide some tiles and train the model to guess what their features should be—this improves understanding of local structure.
- Spread-out features: A small penalty discourages the model from making all features look the same, so different materials stay distinct.
- Match overall structure: Another step nudges the model to keep the “shape” of its feature space stable, so learning is balanced and not wobbly.
They start from a strong existing backbone (a Vision Transformer trained with DINOv3) and fine-tune it with these physics-aware steps so it keeps general knowledge about images but becomes specialized for materials.
What did they find, and why is it important?
In plain terms, the model gets better at “seeing” materials:
- It picks out regions made of the same material more accurately than strong baselines (like DINOv2 and DINOv3). On a public benchmark for material selection, it had higher scores (for example, a higher F1 score), meaning it grouped same-material pixels more cleanly.
- It organizes images so that all versions of the same material (even with different shapes or lights) end up near each other in feature space. That means the model truly learned “material identity,” not just object category.
- It’s more robust to changes in lighting and geometry, so its predictions don’t flip just because a material is lit differently or wrapped around a different shape.
Why this matters: Many tasks in graphics, design, AR/VR, and robotics need to understand what things are made of—so they can relight scenes, replace materials, simulate wear, grasp objects safely, or keep appearances consistent. A model that reliably reads material cues without labels is a powerful building block for all of these.
What’s the impact?
- Better material editing and selection: Designers could click a small patch of a fabric or metal in a photo and have the model find the rest, even under shadows or on curved parts.
- More realistic graphics: Understanding reflectance and fine texture helps with relighting, rendering, and swapping materials in a believable way.
- Robotics and perception: Robots benefit from knowing if a surface is slippery metal, rough concrete, or soft fabric—this improves planning and interaction.
- Less dependence on labeled data: Since the method is self-supervised (no manual labels), it can scale to huge datasets and keep improving.
The authors note two open challenges: the model doesn’t yet cleanly separate all physical factors into named sliders (like “just lighting,” “just geometry,” “just material”) and it was trained on synthetic renders, so fully bridging the gap to all real-world photos is future work. Even so, this study shows that physics-aware pretraining works: it can create features that truly “understand” what makes a material look the way it does.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Real-world generalization remains unquantified: evaluate the learned features on diverse, unpaired real photographs and videos (different cameras, noise levels, JPEG artifacts, motion blur), and report domain-gap measurements and adaptation strategies (e.g., test on OpenSurfaces/MINC, material segmentation in-the-wild, reflectance retrieval on real scans).
- Explicit disentanglement of physical factors is absent: develop and test architectures or objectives that partition the latent space into material, lighting, and geometry components (e.g., factorized heads, causal interventions, contrastive grouping by controlled renders), and validate disentanglement with controlled probes for BRDF/BSDF parameters, light direction, and shape descriptors.
- Dataset pairing bias is unquantified: systematically analyze how semantically aligned material–geometry templates (e.g., cork on rigid shapes) bias the representation, and run controlled experiments with intentionally misaligned pairings to measure whether the model still achieves invariance or starts confounding material identity with context.
- Synthetic-only pretraining is a constraint: study synthetic-to-real transfer at scale (domain randomization, style/lighting mixing, photometric camera pipelines), and benchmark with real reflectance-field captures or handheld multi-view datasets to assess robustness to non-PBR phenomena and capture artifacts.
- Coverage of complex physical effects is untested: design targeted evaluations for anisotropy, subsurface scattering, translucency, thin-film interference, iridescence, sparkle/mesostructure glints, volumetrics/participating media, and transparency refraction/caustics; quantify performance and failure modes per effect.
- Retention of semantic performance is not measured: assess whether fine-tuning for physical invariance degrades standard semantic tasks (e.g., ImageNet linear probe, COCO/semantic segmentation) and characterize trade-offs between physics-aware and semantics-aware features.
- Limited downstream breadth: extend evaluation beyond patch-level selection and k-NN clustering to intrinsic decomposition (albedo/shading separation), SVBRDF estimation, inverse rendering (including MatCLIP-style retrieval), robotics terrain perception, and material-aware editing; report improvements from using the learned backbone in these tasks.
- Unsupervised segmentation lacks quantitative benchmarks: complement qualitative K-means results with quantitative metrics (IoU, ARI, NMI, adjusted Rand index) against ground-truth material masks and report sensitivity to K selection, initialization, and feature normalization.
- Partial ablation coverage: ablate all loss components and hyperparameters (Gram anchoring on/off and schedule, KoLeo strength/ε, iBOT masking ratio, prototype count K, teacher temperature Tt/Ts, InfoNCE temperature τ, multi-crop scales), and analyze their individual and joint contributions to physical invariance and cluster separability.
- Scaling laws and backbone diversity are unexplored: test larger/smaller ViT variants (S/B/L/H), different patch sizes (e.g., 14 vs 16 vs 8), convolutional hybrids, and multi-scale tokenization; report how representation quality scales with model capacity, training duration, and data size.
- Resolution sensitivity and tokenization effects are not characterized: study generalization across input resolutions, patch sizes, and register token configurations; quantify performance drift when switching between training and evaluation resolutions and under variable RoPE settings.
- InfoNCE false negatives are unaddressed: investigate hard-negative mining, debiasing, and curriculum strategies to mitigate cases where different materials produce highly similar appearances under specific lighting/geometry, potentially harming contrastive separation.
- Prototype dynamics are under-specified: report prototype count K, assignment entropy/stability, and cluster purity over training; explore adaptive K and prototype regularization to better reflect the granularity of material categories.
- Computational efficiency and deployment are not evaluated: measure inference latency, memory footprint, and throughput for patch-level tasks at high resolutions; propose approximations (e.g., token pruning, distillation) for practical deployment.
- Reproducibility details are incomplete: provide missing hyperparameters (e.g., teacher temperatures, prototype count), random seeds, environment-map lists, material parameter presets, and data generation scripts; release code, models, and (where licensing allows) synthetic renders to enable replication.
- Licensing and data release constraints are unclear: clarify rights and permissible use of Adobe Substance assets and renders; outline what parts of the dataset, environment maps, and code can be released and propose open alternatives if needed.
- Failure-case analysis is missing: present per-class confusion matrices and qualitative failures (e.g., marble vs ceramic, brushed metal vs plastic), and analyze patterns where geometry or lighting still leak into material identity.
- Trade-off with geometry cues is not studied: quantify whether enforcing invariance to macrogeometry suppresses useful shape signals for tasks that need both (e.g., robotics, affordances), and investigate multi-objective training that balances material and geometric information.
- Connection to physics-informed objectives is limited: explore incorporating differentiable rendering constraints, BRDF priors, or energy-conservation regularizers directly into the SSL loss to align features with physical laws rather than only data-driven physical augmentations.
- Multi-illumination/multi-view real captures are not leveraged: evaluate training with small real capture sets (lightstage-like or handheld multi-view with illumination variation) and study hybrid real+synth pretraining curricula for stronger real-world invariance.
Practical Applications
Below are practical, real-world applications that follow from the paper’s physically-grounded, self-supervised visual backbone trained to be invariant to geometry and lighting while remaining sensitive to material identity, reflectance, transparency, and mesostructure. Each item indicates sectors, likely tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Material-aware selection and masking in creative tools
- Sectors: software, media/entertainment, design
- Tools/products/workflows: “Select by Material” and “Material Brush” features in photo/video editors; plug-ins for Photoshop/After Effects/Premiere/Substance to auto-mask glossy vs matte, fabric vs metal; K-means or similarity-based material clustering directly from patch embeddings
- Assumptions/dependencies: Works best on consumer photos where materials are visually distinct; requires integration into existing UIs; relies on the learned features without explicit parameter recovery
- Similar-material search and retrieval across asset libraries
- Sectors: software, gaming, VFX, e-commerce
- Tools/products/workflows: Embedding-based indexing for Substance/PBR libraries; “find similar material” search from a query patch; automated tagging of large texture collections
- Assumptions/dependencies: High-quality embedding database; consistent feature extraction pipeline; performance may vary on non-PBR or stylized assets
- Robust product photo editing (glossy/transparent objects)
- Sectors: e-commerce, advertising, retail
- Tools/products/workflows: Cleaner foreground/background separation for shiny/transparent items; consistent masking and compositing across varied lighting; batch workflows to standardize catalog images
- Assumptions/dependencies: Domain gap between synthetic pretraining and real product photos; may require light fine-tuning with small labeled sets
- Quality inspection and sorting by material class on production lines
- Sectors: manufacturing, logistics
- Tools/products/workflows: Camera-based sorting of plastics/metals/fabrics using k-NN over embeddings; anomaly/defect detection via similarity to acceptable exemplars; fast deployment with small labeled reference sets
- Assumptions/dependencies: Controlled imaging conditions; narrow set of material categories; potential per-factory calibration
- Robotics perception: terrain and object-surface understanding
- Sectors: robotics
- Tools/products/workflows: Patch-wise embeddings to inform friction/traction heuristics and slippage risk; material-informed grasp planning (e.g., soft vs hard, smooth vs rough)
- Assumptions/dependencies: Needs task-specific mapping from embeddings to physical properties; domain adaptation to robot camera streams; safety validation
- Restoration and construction documentation from site photos
- Sectors: architecture/construction, civil infrastructure
- Tools/products/workflows: Automatic material labeling in building/site images for BIM updates, maintenance logs, cost estimates; identification of surface types (asphalt, concrete, brick, wood)
- Assumptions/dependencies: Outdoor variability and weathering; may require curated exemplars; ambiguous composites or coatings can reduce accuracy
- Environmental monitoring and municipal asset inventory
- Sectors: public sector, smart cities
- Tools/products/workflows: Identify road, sidewalk, wall materials for maintenance planning; track surface degradation with embedding shifts over time
- Assumptions/dependencies: Geospatial data association; consistent capture protocols; policy constraints on data collection
- Everyday mobile apps: material identification and care guidance
- Sectors: consumer apps
- Tools/products/workflows: Scan a surface to identify likely material (e.g., leather vs faux leather) and suggest cleaning products or paint types; home DIY guidance
- Assumptions/dependencies: On-device inference with lightweight ViT; variability in smartphone imaging; user-facing confidence and fallback behavior
- Academic research baselines for intrinsic/material tasks
- Sectors: academia
- Tools/products/workflows: Use the backbone as a material-aware pretraining for inverse rendering, intrinsic decomposition, material segmentation; simple k-NN evaluation pipelines for new datasets
- Assumptions/dependencies: Access to pretrained weights and synthetic dataset generation pipeline; transparent evaluation protocols
Long-Term Applications
- End-to-end inverse rendering with disentangled latent controls
- Sectors: graphics, vision, software
- Tools/products/workflows: Extend the backbone to disentangle material, lighting, geometry in the latent space; sliders to adjust lighting or material factors; direct SVBRDF parameter estimation from features
- Assumptions/dependencies: Requires explicit disentanglement objectives and ground-truth or weak labels; more complex training regimes and datasets
- Physically-aware AR and virtual staging at scale
- Sectors: AR/VR, real estate, retail
- Tools/products/workflows: Consistent placement and relighting of virtual objects based on inferred real-world material context; occlusion and reflection handling improved by material-aware features
- Assumptions/dependencies: Real-to-synthetic domain gap closure; tight integration with AR runtimes; temporal stability for video
- Robotics manipulation and control driven by material embeddings
- Sectors: robotics
- Tools/products/workflows: Policy-learning that maps embeddings to grasp force, tool selection, or cleaning techniques; adaptive controllers that adjust to material changes in real-time
- Assumptions/dependencies: Safety-critical validation; multi-modal integration (vision + force/tactile); robust mapping from embeddings to physical affordances
- Industrial compliance and counterfeit detection
- Sectors: manufacturing, supply chain, policy
- Tools/products/workflows: Embedding-based checks to verify material usage against specs; flagging of counterfeit products via reflectance/texture mismatch; audit trails for procurement
- Assumptions/dependencies: Standardized capture protocols; regulatory acceptance; periodic recalibration across suppliers and cameras
- Medical and scientific imaging extensions (material-analog tissues)
- Sectors: healthcare, scientific imaging
- Tools/products/workflows: Adapt features to segment tissue types or materials in microscopy/dermatology based on texture/reflectance; aid in sample triage
- Assumptions/dependencies: Extensive domain adaptation; ethical and safety requirements; careful validation and clinical trials
- Video-level material tracking and temporal consistency
- Sectors: media/entertainment, robotics, surveillance
- Tools/products/workflows: Track material segments over time for editing, VFX, or monitoring; propagate masks across frames even under significant lighting/pose changes
- Assumptions/dependencies: Temporal feature smoothing; motion/occlusion handling; computational efficiency for real-time use
- Data standards and policy guidance for synthetic pretraining
- Sectors: policy, standards, academia/industry consortia
- Tools/products/workflows: Best-practice guidelines for physically-plausible material-geometry pairings; standards for synthetic dataset generation to reduce unrealistic bias
- Assumptions/dependencies: Multi-stakeholder agreement; documentation and auditing frameworks; periodic benchmarking
- Insurance and risk assessment from property imagery
- Sectors: finance/insurance
- Tools/products/workflows: Identify exterior/interior materials to estimate hazard (e.g., roofing type, cladding materials); inform maintenance recommendations and premium adjustments
- Assumptions/dependencies: Regulatory approval; transparent model governance; potential human-in-the-loop verification
- Large-scale “visual material” search for commerce and sustainability
- Sectors: e-commerce, sustainability
- Tools/products/workflows: Search platforms that retrieve products by material look/feel; sustainability audits that identify plastics or coatings from images to guide recycling workflows
- Assumptions/dependencies: Robust cross-domain generalization; careful handling of mixed or coated materials; metadata integration
- Digital twins with material-aware perception
- Sectors: industrial IoT, construction, manufacturing
- Tools/products/workflows: Integrate material labels into digital twin pipelines to enable accurate simulation (thermal, acoustic, wear); automated updates from site imagery
- Assumptions/dependencies: Multimodal fusion (images, scans, sensors); standardized taxonomies of materials; long-term maintenance of models
Notes on overarching assumptions and dependencies across applications:
- Current model is trained on synthetic renders with PBR assumptions; domain adaptation to real-world imagery will improve reliability.
- Latent space is not explicitly disentangled into material/lighting/geometry; applications needing direct control will require further research.
- Best performance is achieved when materials are visually separable; composites, coatings, and heavy weathering may reduce accuracy.
- Integration into production systems requires scalable inference, dataset curation aligned with target domains, and governance for safety/ethics where applicable.
Glossary
- anisotropy: Direction-dependent variation in a material’s appearance or physical properties. "through reflection, refraction, anisotropy, subsurface scattering, and other effects"
- CLS token: A special transformer token used to aggregate an image-level representation. "A special global token (often referred to as the \code{[CLS]} token) is prepended for image-level representation."
- contrastive learning: A self-supervised paradigm that learns by pulling together positive pairs and pushing apart negatives. "The field shifted with contrastive learning~\cite{chen2020simple,he2020momentum}, where models learn augmentation-invariant features by pulling together view of the same image and pushing apart the rest."
- cosine similarity: A measure of similarity between feature vectors based on the cosine of the angle between them. "Given a query patch, we compute cosine similarity between its feature embedding and those of all image patches, producing a dense similarity map."
- displacement map: A texture map that modifies geometry by displacing surface points to add fine detail. "We tessellate each object using the materialâs displacement map to synthesize realistic local shadows and inter-reflections."
- EMA (Exponential Moving Average): A running average of model parameters used for the teacher network in self-distillation. "The teacher is an EMA of the student, and the Gram teacher is a frozen snapshot used only for Gram anchoring."
- environment map: A high dynamic range image used to define scene illumination from all directions. "illuminated under four high dynamic range environment maps randomly selected from a list of twenty"
- Gram anchoring: A loss that aligns second-order (Gram matrix) structure of patch features between networks. "Gram anchoring aligns second-order structure on global crops."
- Gram teacher: A frozen reference network used solely to provide Gram-matrix targets for structural alignment. "the Gram teacher is a frozen snapshot used only for Gram anchoring."
- Hamming distance: A metric counting differing labels between predictions to assess invariance. "We then evaluate the average pairwise Hamming distance between predictions obtained under different lighting conditions (fixed geometry) and under different geometry templates (fixed lighting)."
- iBOT: A masked patch-level latent reconstruction objective for self-supervised transformers. "Following iBOT~\cite{zhou2021ibot} and DINOv3~\cite{simeoni2025dinov3}, a masked latent reconstruction objective is applied at the patch level."
- InfoNCE: A contrastive loss that encourages similar representations for positives and dissimilar ones for negatives. "We complement the teacherâstudent alignment with an in-batch InfoNCE~\cite{oord2018representation} loss on -normalized global student embeddings."
- K-means: An unsupervised clustering algorithm used to segment images from patch embeddings. "we apply K-means clustering on patch embeddings to visualize how features organize the image space."
- Kozachenko–Leonenko (KoLeo) entropy estimator: A nonparametric estimator used to encourage feature dispersion and avoid collapse. "We use the KozachenkoâLeonenko entropy estimator on the batch of -normalized student features to encourage dispersion and avoid collapse."
- macrogeometry: Large-scale shape or structural context of an object. "invariant to the context e.g, macrogeometry (``the overall shape'') and lighting, while remaining sensitive to reflectance, transparency, and fine structure."
- Masked Image Modeling (MIM): A self-supervised task that reconstructs masked parts of an image to learn representations. "Masked Image Modeling (MIM)~\cite{he2022masked,bao2021beit,el2021large} with transformers emerged as a complementary reconstruction-based approach"
- mesostructure: Medium-scale geometric detail of a surface affecting appearance. "including reflectance cues and geometric mesostructure."
- microfacet materials: Reflectance models that assume surfaces are composed of microscopic facets. "using physically accurate light transport and microfacet materials~\cite{Trowbridge1975,walter2007microfacet}"
- Monte Carlo path tracer: A rendering algorithm that stochastically simulates light transport for photorealism. "Rendering is performed with a Monte Carlo path tracer using physically accurate light transport and microfacet materials"
- patch tokens: Tokenized image patches used as inputs to the transformer for local feature processing. "A random subset of the studentâs patch tokens is masked, and the network is trained to predict the corresponding patch embeddings produced by the teacher on the same spatial positions"
- Physically Based Rendering (PBR): A rendering approach grounded in physical light–material interaction, often using standardized maps. "PBR (Physically Based Rendering) maps~\cite{Burley2015ExtendingDisneyBRDF}"
- prototype matrix: A set of learnable vectors representing cluster centers used for assignment and self-distillation. "let be the learnable prototype matrix."
- register tokens: Additional learnable tokens in ViT that store global context and stabilize training. "learnable ``register tokens'' that act as dedicated memory slots for global context and mitigate patch-token artefacts."
- Retinex: A theory and set of assumptions for separating reflectance from illumination in images. "Retinex-based assumptions~\cite{land1971lightness,horn1974determining,bi20151}, both of which proved brittle in practice."
- Rotary Positional Embedding (RoPE): A positional encoding method for transformers that facilitates sequence extrapolation. "Positional information in the token embeddings is handled via the Rotary Positional Embedding (RoPE)~\cite{su2024roformer} mechanism"
- self-distillation: A training setup where a teacher network (often an EMA of the student) supervises the student without labels. "DINO~\cite{caron2021emerging} and its successors~\cite{oquab2023dinov2,darcet2023vision,simeoni2025dinov3} extend these ideas with a teacherâstudent self-distillation setup to learn both global and dense features."
- silhouette score: A clustering quality metric used to select the number of clusters. "choosing the value that maximizes the silhouette score~\cite{rousseeuw1987silhouettes}."
- Sinkhorn–Knopp normalization: A procedure that balances prototype assignments, improving stability in self-supervised training. "which replaces the centering and sharpening mechanisms of DINOv2 with the SinkhornâKnopp normalization from SwAV~\cite{caron2020unsupervised}."
- Vision Transformer (ViT): A transformer-based architecture that processes images as sequences of patch tokens. " builds upon the vision transformer (ViT) architecture used in DINOv3~\cite{simeoni2025dinov3}"
Collections
Sign up for free to add this paper to one or more collections.