PretrainZero: Reinforcement Active Pretraining
Abstract: Mimicking human behavior to actively learning from general experience and achieve artificial general intelligence has always been a human dream. Recent reinforcement learning (RL) based large-thinking models demonstrate impressive expert-level abilities, i.e., software and math, but still rely heavily on verifiable rewards in specific domains, placing a significant bottleneck to extend the performance boundary of general reasoning capabilities. In this work, we propose PretrainZero, a reinforcement active learning framework built on the pretraining corpus to extend RL from domain-specific post-training to general pretraining. PretrainZero features the following characteristics: 1) Active pretraining: inspired by the active learning ability of humans, PretrainZero learns a unified reasoning policy to actively identify reasonable and informative contents from pretraining corpus, and reason to predict these contents by RL. 2) Self-supervised learning: without any verifiable labels, pretrained reward models, or supervised fine-tuning, we directly pretrain reasoners from 3 to 30B base models on the general Wikipedia corpus using RL, significantly breaking the verification data-wall for general reasoning. 3) Verification scaling: by tackling increasingly challenging masked spans, PretrainZero substantially enhances the general reasoning abilities of pretrained base models. In reinforcement pretraining, PretrainZero improves Qwen3-4B-Base for 8.43, 5.96 and 10.60 on MMLU-Pro, SuperGPQA and math average benchmarks. In post-training, the pretrained models can also serve as reasoning foundation models for downstream RLVR tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train LLMs called PretrainZero. The big idea is to help models become better at thinking and reasoning by learning actively from everyday text (like Wikipedia), without needing human labels, answer keys, or special tools to check answers. Instead of only learning to guess the next word, the model learns to pick out useful parts of a paragraph, hide them, think through the problem, and then predict the hidden words—using reinforcement learning (a trial-and-error style of learning guided by rewards).
What questions does the paper try to answer?
The paper focuses on three simple questions:
- Can an LLM improve its reasoning skills using only general text, like Wikipedia, with no answer labels or human help?
- How can we make reinforcement learning work during pretraining (the early stage of learning) and not just during post-training (the later stage that usually needs special tools or human feedback)?
- How do we choose which parts of text to learn from so that the model gets better faster, even when the text is noisy or not very informative?
How does PretrainZero work?
To keep this simple, imagine studying from a textbook:
- You cover up a few words in a paragraph (like a fill-in-the-blank).
- You think through the context to figure out the missing words.
- If you get them right, you get a reward. If not, you try a better approach next time.
PretrainZero does something similar, but with two smart steps working together:
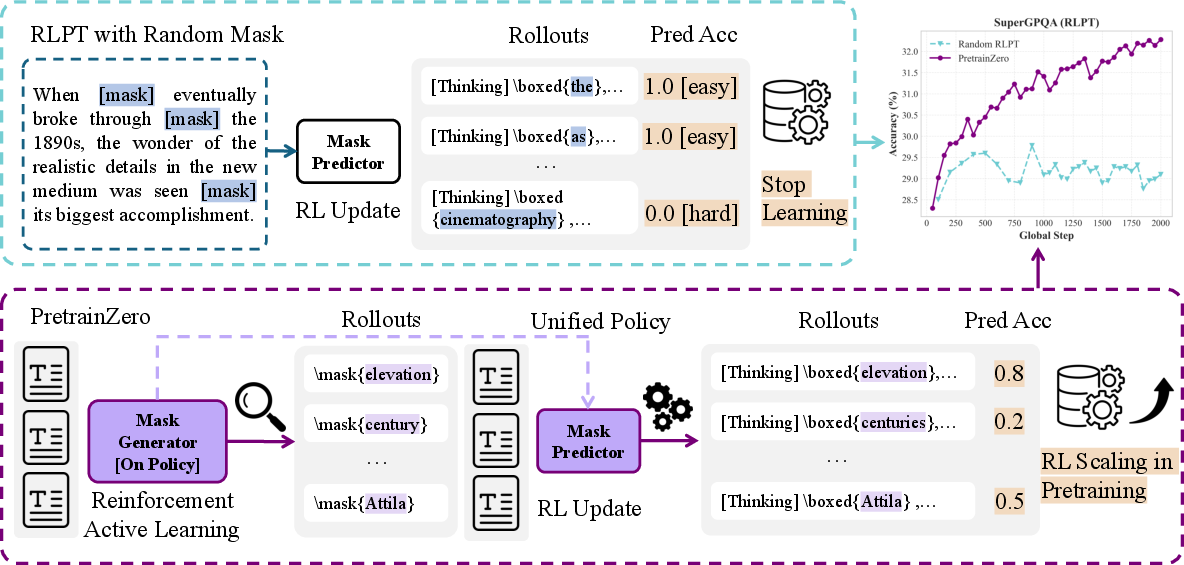
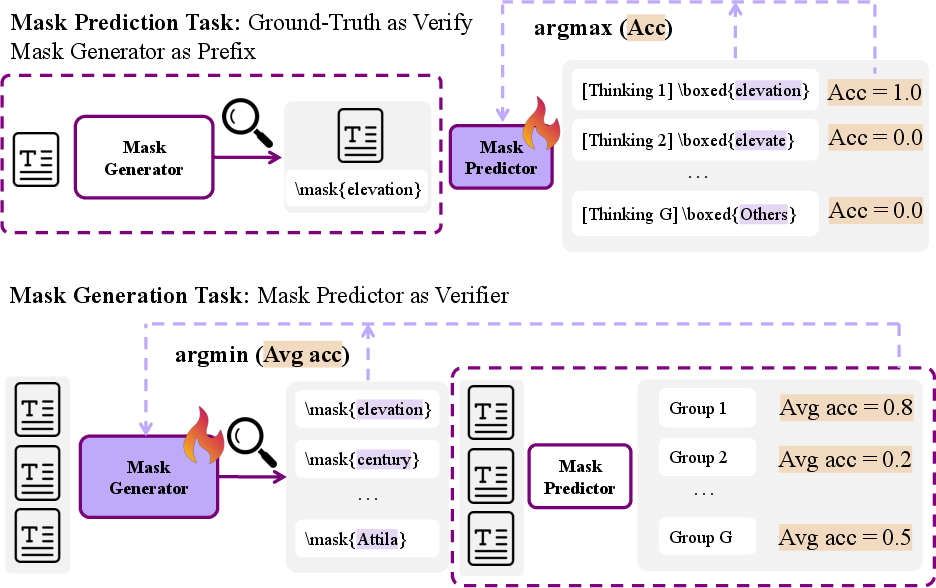
Step 1: Mask Generation (picking good blanks)
- The model learns to actively choose which words or short phrases to hide (the “mask”).
- It tries to pick parts that are informative, solvable from the surrounding text, and just hard enough to teach it something new.
- Think of this as the model learning to pick good practice questions for itself.
Step 2: Mask Prediction (solving the blanks with reasoning)
- The model then thinks step-by-step (called “chain-of-thought”) to predict the masked words.
- It gets a simple reward: 1 if its prediction exactly matches the original words, 0 if not.
- This encourages careful reasoning instead of guessing.
A helpful “game” between picker and solver
- The mask-picker and the mask-solver share the same model but act like two players:
- The picker tries to choose masks that challenge the solver (but aren’t impossible).
- The solver tries to correctly fill in the masks using reasoning.
- This setup is like a balanced game: the picker pushes the solver to improve, and the solver gets better at reasoning over time.
What is reinforcement learning here?
- Reinforcement learning (RL) means learning from rewards: try something, see the result, and adjust.
- The paper uses an RL method called GRPO (Group Relative Policy Optimization).
- In everyday terms: the model tries several answers, compares how well each did relative to the group, and updates its strategy to do better next time.
Why not just pick “hard” words?
- The authors tried choosing high-entropy (very uncertain) words to mask, hoping they’d be challenging.
- On clean, synthetic datasets, this worked. But on real text like Wikipedia, it often picked noisy or unpredictable words and training collapsed.
- That’s why active, on-the-fly mask selection is key: the model must learn which blanks are helpful, not just hard.
What did they find?
Here are the main results, explained simply:
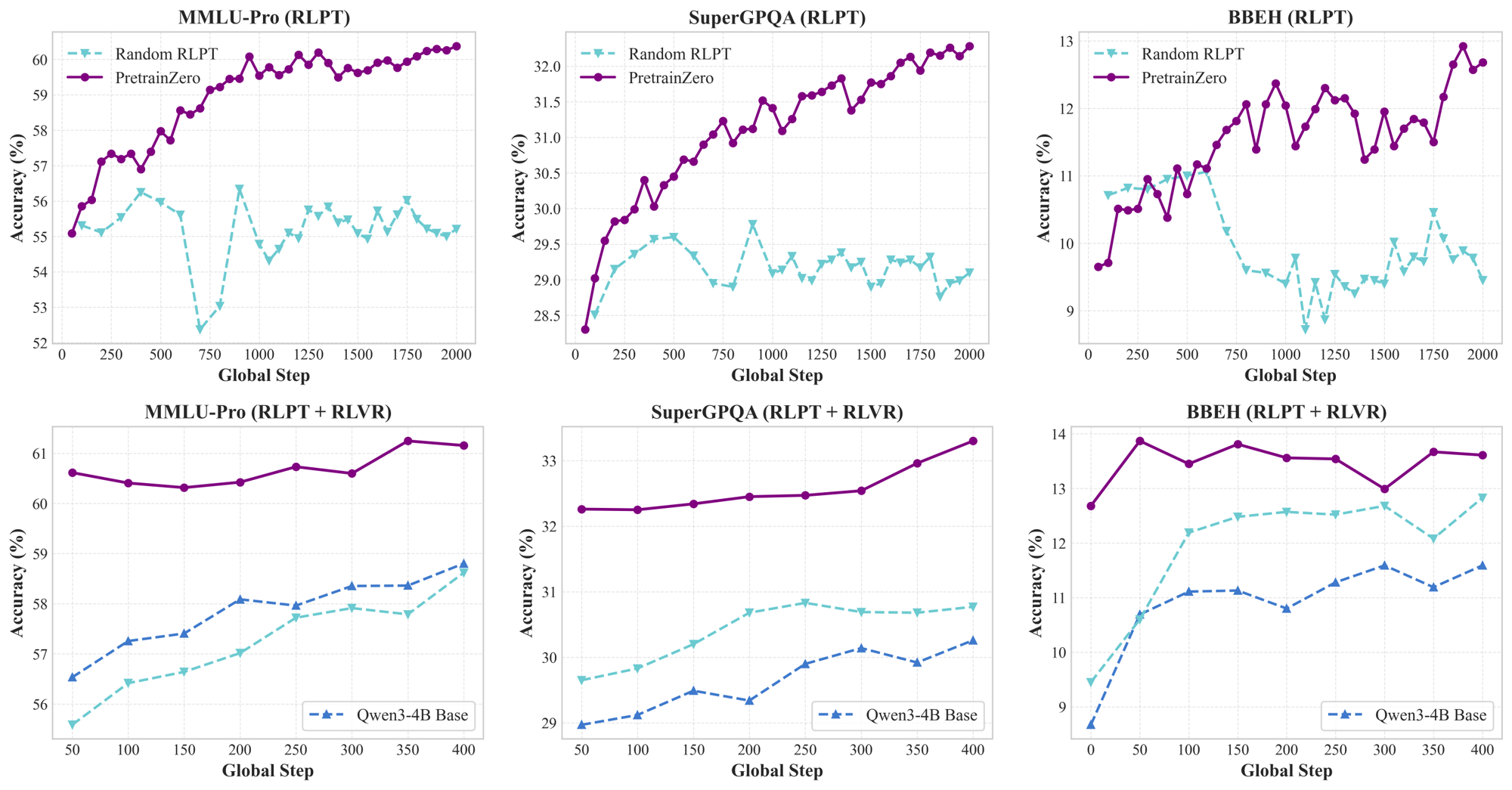
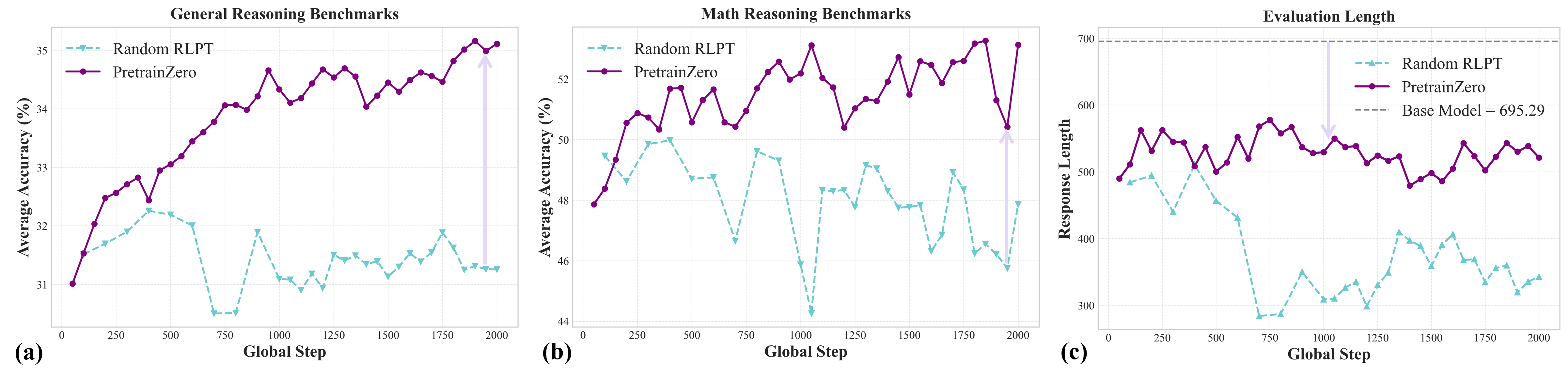
- PretrainZero helps models get better at reasoning during pretraining:
- On a 4-billion-parameter model (Qwen3-4B-Base), PretrainZero improved scores on tough general knowledge and math tests:
- MMLU-Pro (a hard general test): +8.43 points
- SuperGPQA (graduate-level questions): +5.96 points
- Math benchmarks (average across several math tests): +10.60 points
- It works across different model sizes (around 3B to 30B parameters).
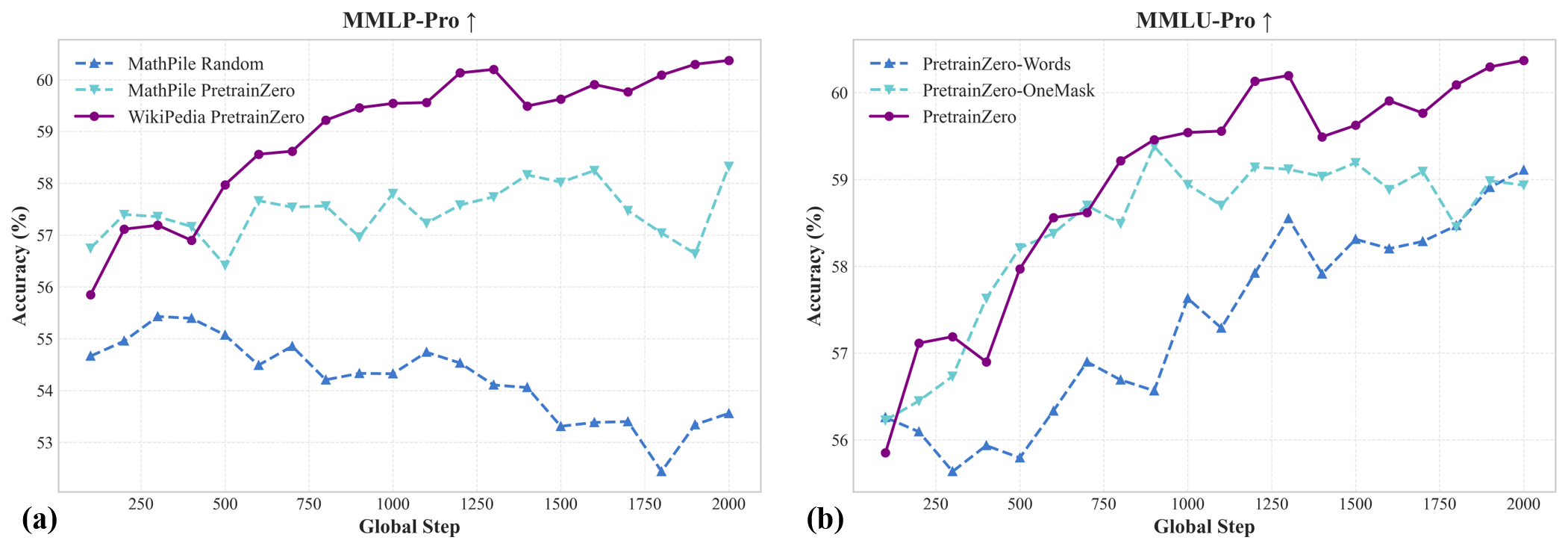
- It beats other training styles that use the same data:
- Better than simply continuing normal pretraining on Wikipedia (which sometimes made things worse).
- Better than supervised fine-tuning (turning tasks into Q&A without RL), especially because Wikipedia isn’t designed as clean training data.
- Better than “random RL” baselines that don’t actively pick informative masks.
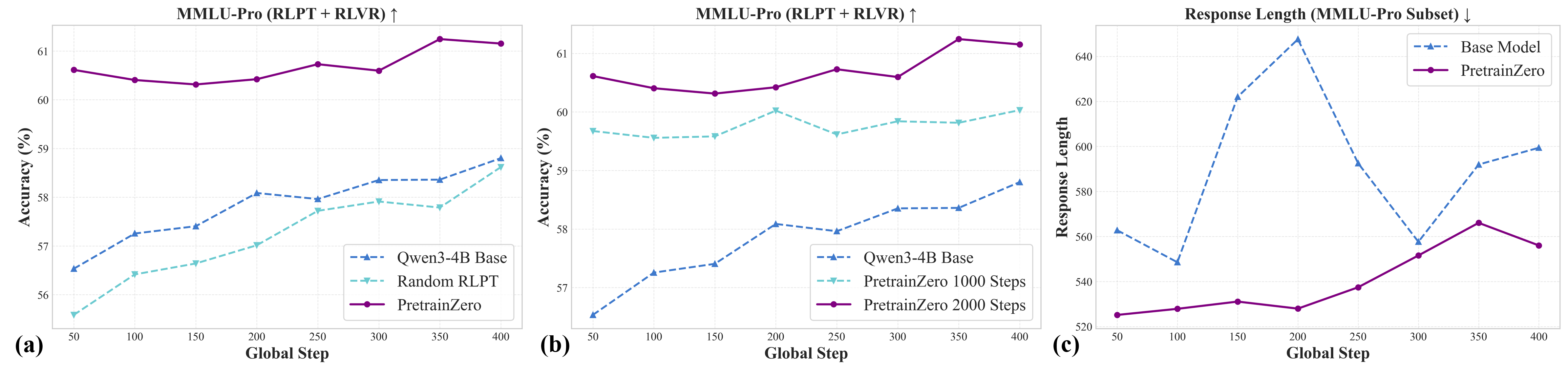
- It also helps later training:
- After doing standard RL post-training (which uses verifiable answers), the models that used PretrainZero first still performed better than those that didn’t.
- Improvements after post-training were still noticeable—for example, on MMLU-Pro (+2.35) and SuperGPQA (+3.04).
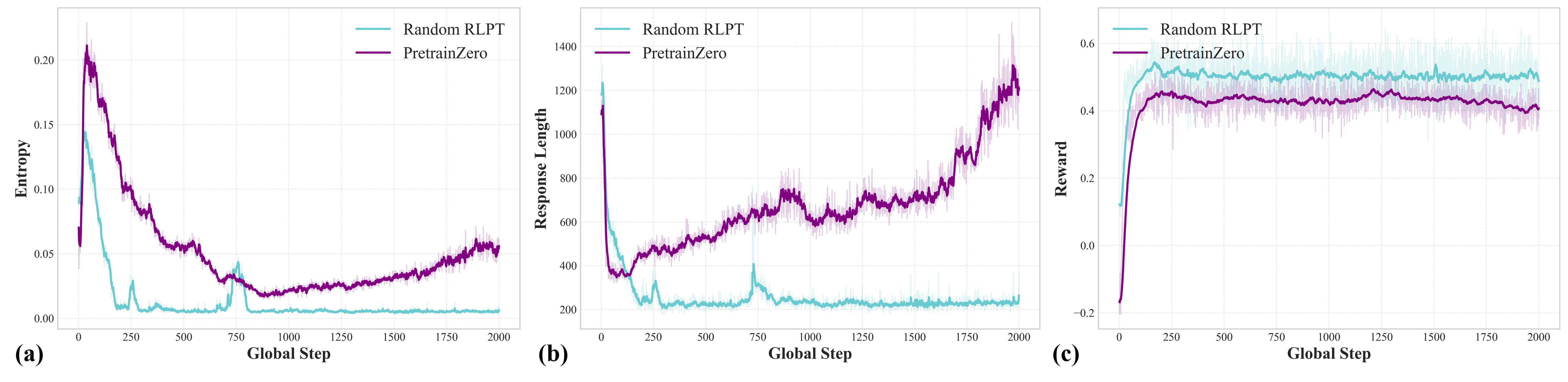
- Reasoning got stronger and more stable:
- The model learned to produce step-by-step reasoning more often and more reliably.
- Despite longer thinking during training, real-world inference remained efficient and stable.
Why is this important?
- It lowers the “data wall”: Many RL methods need special tools or human labels to check answers. PretrainZero shows we can push RL earlier—during pretraining—using only general text and simple checks (like whether the predicted masked words exactly match).
- It makes models better thinkers: By actively choosing good practice targets, the model learns more useful patterns from ordinary text and develops stronger chain-of-thought reasoning.
- It scales: Wikipedia is huge and cheap. PretrainZero turns it into a training ground for reasoning without requiring handcrafted datasets.
- It builds better foundations: Models pretrained this way become better starting points for future RL fine-tuning in real tasks.
Key terms in simple words
- Pretraining: The model’s “schooling,” where it learns general language patterns from lots of text before specializing.
- Post-training: Later “coaching” sessions that teach specific skills or behaviors, often with more structured feedback.
- Reinforcement Learning (RL): Learning by trying, getting rewards, and adjusting to improve.
- Chain-of-Thought (CoT): Writing out reasoning steps instead of jumping straight to the final answer.
- Mask/Span: The hidden part of a sentence the model must fill in.
- Self-supervised: Learning from the text itself without human-created labels.
- Verifiable reward: A simple, automatic way to check if the prediction is right (like exact match).
Final takeaway
PretrainZero shows a practical, label-free way to teach LLMs to reason better during pretraining. By letting the model actively choose what to learn and then reason to fill in smartly chosen blanks, it improves performance on tough tests in both general knowledge and math. This approach could make future models more powerful and easier to train, because it uses widely available data and avoids expensive human supervision.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future work:
- Data scope and diversity: The approach is validated only on the English Wikipedia corpus; its effectiveness on other domains (e.g., code, biomedical, legal), non-English languages, multi-modal data, and noisy web-scale mixtures remains untested.
- Contamination and memorization risk: Since Wikipedia likely overlaps with evaluation benchmarks (e.g., MMLU(-Pro), GPQA), the extent to which gains stem from retrieval/memorization versus genuine reasoning improvement is not quantified; controlled, contamination-aware splits are needed.
- Generalization beyond masked infilling: The method optimizes masked-span recovery with exact-match rewards; transfer to tasks requiring multi-step derivation, synthesis, tool-use, multi-turn dialogue, code generation, or planning is not evaluated.
- Reward design limitations: Binary exact-match rewards for spans can penalize semantically equivalent paraphrases and encourage lexical reproduction; graded, semantic, or structure-aware rewards (e.g., edit distance, entity normalization, equation equivalence) are unexplored.
- Generator ambiguity detection: The mask generator is lightly constrained via prompts and a zero-reward heuristic when predictor accuracy is zero, but systematic detection of ambiguous, multi-answer, or unverifiable masks (and their impact on training stability) is not studied.
- Curriculum control and difficulty calibration: The min–max training claims to generate “increasingly challenging” masks, but difficulty is not quantified (e.g., via entropy, predictability, uniqueness); mechanisms for explicit curriculum scheduling, difficulty estimation, and progression are absent.
- Stability and convergence theory: The bilevel min–max GRPO updates lack theoretical analysis (e.g., convergence conditions, stability regions), and empirical stability under longer horizons (>2000 steps) or diverse hyperparameters is not demonstrated.
- KL regularization and safety checks: The method trains without KL control; the trade-offs between exploration, stability, reward hacking, and distribution shift compared to KL-regularized RL are not examined.
- Ablation breadth: Key factors (mask span length distribution, number of masked spans per sample, rollout group size
G, learning rate schedules, prompt templates, response-length limits) lack systematic ablations to identify dominant contributors. - Parameter sharing vs. decoupling: The paper alternates between “shared LLM” and separate policies (
π_{ω'}for generation,ψ_ωfor prediction); the effects of shared vs. decoupled parameters on interference, specialization, and performance are not disentangled. - Efficiency and compute cost: RLPT batch construction (e.g., 32×8 masks, 8 rollouts per mask) increases compute; wall-clock training time, GPU-hours per improvement point, and scalability to larger models (e.g., 70B dense) or longer RLPT are not reported.
- Mask regularization strategies: Only basic filters (e.g., frequency threshold, complete words) are tested; principled strategies for ensuring informativity (entity types, syntactic roles, discourse salience, novelty) and their impact on learning are unexplored.
- Robustness to noisy or adversarial spans: How the predictor handles typos, OCR artifacts, rare entities, or adversarial masking (e.g., partial morphemes, punctuation-heavy spans) is not evaluated beyond simple word-completeness filtering.
- Process-level reasoning quality: The emergence and faithfulness of CoT is asserted qualitatively; quantitative measures of reasoning correctness, consistency, error types, or process supervision (vs. outcome-only rewards) are not provided.
- Comparison to stronger baselines: Continued pretraining and SFT baselines appear weak (and even degrade performance); comparisons against more competitive setups (e.g., high-quality curated corpora, instruction-tuned datasets, data selection methods) are missing.
- Benchmarks and verifier bias: Math evaluation uses
Qwen-Math-evalas verifier; sensitivity of results to different verifiers, formats, or graders (and to benchmark-specific artifacts) is not assessed. - Transfer to RLVR beyond QA: Post-training tests only RLVR QA with a single recipe; effectiveness for diverse RLVR tasks (coding verifiers, program synthesis, tool-use environments, web agents) and their differing reward surfaces is unknown.
- Safety and bias: Active masking may preferentially target named entities or sensitive attributes; the impact on bias amplification, toxicity, or privacy risks is not analyzed, nor are mitigation strategies (e.g., safety filters for generator outputs).
- Negative side effects on language modeling: The paper notes “continued PT” can harm performance; potential adverse effects of RLPT on perplexity, fluency, calibration, or downstream generative quality are not measured.
- Long-horizon training behavior: Training beyond 2000 steps, including potential reward hacking, collapse, or cyclic dynamics in the min–max game, remains unexplored; monitoring metrics and intervention strategies are not defined.
- Curriculum transfer across models: While multiple base models are tested, how RLPT benefits vary with architecture (dense vs. MoE), pretraining recipe, tokenizer, or training data history is not systematically studied.
- Mask selection learning dynamics: The generator’s learning trajectory (e.g., distribution of selected spans over time, domain/topic shift, entity types) is not tracked; analyses to confirm it focuses on “not-yet-mastered” content are missing.
- Span granularity control: Optimal span lengths and structures (token-level vs. phrase-level vs. sentence-level) for driving reasoning are unknown; adaptive span sizing and its effects on reward density and efficiency are not evaluated.
- Interaction with supervised objectives: The paper excludes cross-entropy losses during RLPT; whether mixing supervised losses (e.g., LM or denoising) or adding auxiliary self-supervised tasks improves stability and generalization is an open question.
- Reproducibility and release: Code, masks, prompts, trained checkpoints, and detailed training logs are not indicated; reproducibility across hardware, seeds, and minor implementation choices is uncertain.
Practical Applications
Immediate Applications
The following applications can be deployed now based on the paper’s demonstrated methods and results. Each item includes sectors, concrete use cases or workflows, and feasibility notes.
- Reinforcement-pretraining stage for LLM training pipelines (Software/AI)
- Use case: Add PretrainZero’s RLPT stage (active mask generation + masked-span prediction trained with GRPO) between base-model pretraining and downstream post-training to boost general reasoning without labels or reward models.
- Workflow/product: “PretrainZero Trainer” module that plugs into existing training stacks (e.g., Megatron-LM/DeepSpeed); prompts for mask generation/prediction; GRPO with clip-higher strategy; 2000-step RLPT recipe on general corpus (Wikipedia).
- Assumptions/dependencies: Access to base models (3–30B+), general-domain corpora, moderate GPU budget (e.g., single node with 8× H800 for post-training; RLPT may vary), GRPO implementation, prompt templates; stability techniques (sample filtering when reward degenerates; mask regularization).
- Stronger starting weights for downstream RLVR finetuning (Software/AI, Robotics)
- Use case: Initialize web agents, tool-use agents, math/code reasoners with PretrainZero-pretrained weights to reduce RLVR steps, improve stability and final accuracy.
- Workflow/product: “Reasoning Foundation Weights” trained with RLPT, then fine-tuned on verified QA datasets/reward models (e.g., General Reasoner recipe).
- Assumptions/dependencies: Availability of verifiers/reward models and domain datasets for RLVR; compute to run short RLVR (e.g., 400 steps); benefits scale with pretraining steps (≥1000–2000).
- Information-density scoring and data curation (Data Engineering, MLOps)
- Use case: Use the mask-generation/prediction accuracy signals to rank passages by “learning value,” filter noisy segments, and prioritize high-signal data for pretraining or retrieval augmentation.
- Workflow/product: “Active-Mask Data Valuator” scoring spans by predictability and challenge; pipeline flags low-value or noisy spans and surfaces informative spans.
- Assumptions/dependencies: Predictor accuracy correlates with semantic informativeness; simple exact-match rewards suffice at span level; requires integration with data ingestion pipeline.
- Label-free domain adaptation on enterprise text (Enterprise Knowledge Management, Education)
- Use case: Run RLPT on internal wikis, manuals, or reports to improve reasoning about company-specific processes without creating labeled QA datasets.
- Workflow/product: “Enterprise RLPT Engine” that ingests internal corpora and outputs improved domain-adapted reasoning weights.
- Assumptions/dependencies: Domain corpora contain verifiable spans predictable from context; privacy controls; careful filtering of duplicated or incomplete masks.
- Small-model reasoning uplift for constrained deployments (Mobile/Embedded, Edge AI)
- Use case: Apply RLPT to compact models (e.g., ~3B) to gain step-by-step reasoning improvements for on-device assistants or offline agents.
- Workflow/product: Distribution of PretrainZero-pretrained small weights; optional periodic server-side RLPT refreshes.
- Assumptions/dependencies: Training occurs off-device; inference-efficient CoT behaviors persist post-training; performance gains observed on SmolLM3-3B general/math benchmarks.
- Prompt and pedagogy patterns for step-by-step reasoning (Education, Daily Life)
- Use case: Adopt the paper’s mask-generation and recovery prompt templates in tutoring/chat systems to elicit structured analysis before answers, improving explainability and self-checking.
- Workflow/product: “CoT Mask-Predict Prompt Pack” for curriculum generation, reading comprehension, and cloze assessments.
- Assumptions/dependencies: Base LLMs already support CoT; the approach does not require changes to verifiers; better outcomes when combined with short RLPT.
- Rapid academic replication and benchmarking (Academia)
- Use case: Reproduce RLPT min–max training with GRPO on Wikipedia to study self-supervised RL signals, robustness to noise, and emergent CoT quality; extend to new benchmarks.
- Workflow/product: Reference training scripts; ablation knobs (entropy selection vs random vs active masks; mask regularization).
- Assumptions/dependencies: Compute to run 1000–2000 steps; access to open benchmarks (MMLU-Pro, SuperGPQA, math suites); reproducible seeds/logging.
- Post-training efficiency improvement via more stable CoT (Software/AI)
- Use case: Start RLVR from PretrainZero-pretrained models to reduce variance in CoT lengths and stabilize optimization, cutting inference costs for agent pipelines.
- Workflow/product: Monitoring tools for response-length stability; “CoT Efficiency Guardrails” derived from the paper’s findings.
- Assumptions/dependencies: RLVR environment and reward models ready; the observed coherence/stability transfers to target tasks.
Long-Term Applications
These applications are promising but require further research, scaling, or operational development to be practical at production scale.
- Fully self-supervised reasoning foundation models at scale (Software/AI)
- Use case: Train high-capacity LLMs with PretrainZero-like RLPT on massive general corpora to achieve strong reasoning without labeled QA or reward models.
- Workflow/product: Industrial-grade RLPT pipelines (multi-node, curriculum schedules, dynamic mask policies); open weights for broad use.
- Assumptions/dependencies: Stability and sample efficiency at much larger scale; robust mask-generation policy across diverse domains; engineering to avoid collapse and reward degeneracy.
- Automated curriculum learning via active masks (Education, Software/AI)
- Use case: Treat mask generation as a learned curriculum that continuously probes “not-yet-mastered” concepts, driving progressive learning across topics (math, code, science, law).
- Workflow/product: “Active Curriculum Engine” that ramps difficulty, avoids noisy masks, and retires mastered concepts; cross-domain extensions.
- Assumptions/dependencies: Reliable difficulty estimation; safeguards against adversarial masking; domain-aware prompts; monitoring for overfitting to mask patterns.
- Domain-specific self-supervised RL in regulated sectors (Healthcare, Legal, Finance)
- Use case: Improve reasoning on EHR notes, clinical trials, case law, and financial reports without human labels by learning from predictable spans and context semantics.
- Workflow/product: Sector-specific RLPT suites with compliance auditing; “Information Density Index” for document triage; domain verifiers for downstream RLVR.
- Assumptions/dependencies: Data privacy and security; validation against expert gold standards; controlled deployment with safety layers; mitigation of hallucinations and bias.
- Continual learning and lifelong adaptation (Software/AI, Robotics)
- Use case: Deploy agents that periodically refresh reasoning via on-policy mask generation over new logs, focusing on mistakes and unfamiliar concepts to steadily improve.
- Workflow/product: “Lifelong RLPT Update” jobs; drift detection; update scheduling; rollback and safety tests.
- Assumptions/dependencies: Reliable on-policy selection under distribution shift; robust guardrails to prevent catastrophic forgetting or reward hacking; scalable evaluation.
- Data valuation and acquisition strategy (Policy, Data Marketplaces)
- Use case: Use mask-prediction difficulty and learning gains to quantify “value per token” for datasets, guiding procurement and public investment in open corpora that raise general reasoning.
- Workflow/product: Data valuation dashboards; contribution metrics for open repositories; procurement guidelines.
- Assumptions/dependencies: Agreement on metrics; repeatable scoring across models; transparency in data cleaning; incentives for quality over quantity.
- Safety and governance for self-supervised RL (Policy, AI Governance)
- Use case: Establish standards for training without reward models or labels, including noise handling, mask regularization, and collapse prevention to minimize harmful behaviors.
- Workflow/product: Safety checklists; auditing protocols for RLPT; certification for “safe self-supervised RL” pipelines.
- Assumptions/dependencies: Community consensus on robustness tests; tooling for anomaly detection in rewards/advantages; reporting norms.
- Education technology for adaptive cloze and reasoning drills (Education)
- Use case: Build adaptive drill systems that mask key entities/relations with tuned difficulty, eliciting step-by-step reasoning and metacognitive reflection in learners.
- Workflow/product: “Active Cloze Tutor” integrating mask generation, CoT guidance, and verifiable short answers; analytics for mastery tracking.
- Assumptions/dependencies: Domain alignment for mask choices; content quality controls; integration with classroom platforms; fairness/accessibility considerations.
- Cross-modal extensions to code, vision, and audio (Software/AI, Robotics)
- Use case: Extend RLPT to code repositories (mask functions/identifiers), vision (mask regions/captions), and audio (mask phrases), nurturing multi-modal reasoning without labels.
- Workflow/product: “Multimodal Active Masking Suite”; co-training predictors across modalities; verifiable span/region rewards.
- Assumptions/dependencies: Designing verifiable, informative masks in each modality; stable GRPO-like updates; avoiding mode collapse and hallucinations.
- Compression/distillation pathways for reasoning-centric small LLMs (Software/AI)
- Use case: Pretrain large models with RLPT, then distill reasoning behaviors into compact deployable models for cost-sensitive applications.
- Workflow/product: Distillation curricula guided by active masks; student-teacher pipelines emphasizing CoT robustness and efficiency.
- Assumptions/dependencies: Transferability of reasoning signals; student model capacity; evaluation of step-by-step fidelity.
- Benchmarking and standardization of RLPT (Academia, Standards Bodies)
- Use case: Create shared tasks, datasets, and metrics to compare RLPT algorithms, mask policies, and training stability, enabling scientific progress and reproducibility.
- Workflow/product: RLPT benchmark suites; public leaderboards; reference implementations and logs.
- Assumptions/dependencies: Community adoption; inclusive coverage of domains; governance for synthetic vs real corpora; agreement on reward definitions and anti-collapse measures.
Glossary
- Active learning: A learning paradigm where the model selects informative samples to learn from, improving efficiency on sparse or noisy data. "inspired by the active learning ability of humans,"
- Adversarial min–max formulation: An optimization setup where one component minimizes and another maximizes an objective to drive robustness. "thereby forming a coupled min--max formulation:"
- Auto-regressive pattern: A modeling approach where the next token is predicted conditioned on all previous tokens. "under an auto-regressive pattern:"
- Bilevel reinforcement learning objective: A hierarchical optimization with inner (predictor) and outer (generator) RL problems optimized jointly. "minâmax bilevel reinforcement learning objective,"
- Chain-of-thought (CoT): Explicit intermediate reasoning steps generated before producing a final answer. "synthetic chain-of-thought (CoT) datasets,"
- Clip-higher strategy: A PPO-style stabilization heuristic that clips policy updates preferentially when ratios increase beyond a threshold. "we adopt the clip-higher strategy for stability."
- Cosine scheme (learning-rate schedule): A learning-rate schedule that follows a cosine decay over training. "we adopt the learning rate and the cosine scheme."
- Data-wall (verification data-wall): A bottleneck caused by limited verifiable signals needed to train RL methods at scale. "faces a severe data-wall:"
- Distillation (post-training distillation): Transferring behaviors from a strong model or policy into another model after initial training. "vanilla RPT depends on post-training distillation;"
- Entropy-based Next Token Reasoning: A masking strategy that targets high-entropy tokens for prediction to induce challenging training signals. "Entropy-based Next Token Reasoning."
- Exact match verifiable reward: A binary reward that grants credit only when the predicted token(s) exactly match the ground truth. "uses the exact match verifiable reward "
- GRPO: A PPO-like group-based reinforcement learning algorithm that normalizes and compares rewards across multiple rollouts. "RPT applies GRPO algorithm with group size ,"
- Hallucination: The tendency of a model to produce confident but ungrounded or incorrect outputs. "severe hallucination issues"
- Information density (low information density): The amount of useful, learnable signal per token; low density hampers efficient training. "low information density"
- KL regularization: A regularizer that penalizes divergence between the updated policy and a reference policy to stabilize RL. "without KL regularization"
- Mask generation (on-policy): A policy-driven process that selects which spans to mask during training based on the model’s current behavior. "we introduce an on-policy mask generation task"
- Masked span prediction: Predicting a contiguous masked sequence of tokens, typically to encourage structured reasoning. "masked-span prediction task"
- Mean@32 accuracy: An evaluation metric averaging accuracy across 32 independent trials or samples. "report the mean@32 accuracy."
- Mixture-of-Experts (MoE): An architecture routing inputs to specialized expert subnetworks to improve capacity and efficiency. "Qwen3-30B-A3B-MoE-Base"
- Next token prediction (NTP): The standard language-modeling objective of predicting the next token given the previous context. "next token prediction (NTP)"
- On-policy: An RL setting where data is generated by the current policy being optimized. "on-policy mask generation task"
- Post-training: A stage after initial pretraining where models are further tuned (often via RL) on more targeted objectives. "post-training RL faces a severe data-wall:"
- Reinforcement Learning from Human Feedback (RLHF): RL using rewards derived from human preference judgments via a learned reward model. "Reinforcement Learning from Human Feedback (RLHF)"
- Reinforcement Learning Pre-Training (RLPT): Applying reinforcement learning directly during pretraining on large unlabeled corpora. "Reinforcement Learning Pre-Training (RLPT)"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL that relies on automatic, domain-specific verifiers to compute objective rewards. "Reinforcement Learning with Verifiable Rewards (RLVR)"
- Reinforcement Pre-Training (RPT): An approach that augments next-token prediction with RL-driven reasoning before producing tokens. "Reinforcement Pre-Training (RPT)"
- Reward hacking: Exploiting flaws in the reward function to achieve high reward without truly solving the intended task. "to avoid reward hacking."
- Reward model: A learned model that estimates reward or preference signals to guide RL optimization. "relying on reward models"
- Rollout: A sampled trajectory or generation used to evaluate rewards and update policies in RL. "8 rollouts"
- Self-play: An unsupervised RL technique where a model generates its own training data by interacting with itself. "self-play and test-time scaling"
- Self-supervised pretraining: Learning from unlabeled data by predicting parts of the data (e.g., next or masked tokens). "self-supervised pretraining"
- SFT cold-start (Supervised Fine-Tuning cold-start): Using supervised fine-tuning to initialize a model before applying RL. "Supervised Fine-Tuning (SFT) cold-start"
- Test-time scaling: Improving performance by increasing inference-time compute (e.g., more samples or longer reasoning) without changing training. "test-time scaling"
- Verifiable environment: A setup where model outputs can be automatically checked for correctness by a programmatic verifier. "verifiable environments"
- Verifier (domain-specific verifiers): An automated checker that determines whether an answer is correct, enabling reward computation. "requires domain-specific verifiers"
Collections
Sign up for free to add this paper to one or more collections.