- The paper demonstrates that increased architectural complexity does not yield significant performance gains over a simple, well-tuned late-fusion baseline across 19 methods and 9 datasets.
- Rigorous experimentation reveals that many multimodal architectures struggle to outperform strong unimodal baselines, particularly in small data regimes, underscoring the importance of meticulous tuning.
- The study highlights that robust methodological practices and computational efficiency are more critical than intricate fusion mechanisms for improving practical multimodal learning performance.
Complexity and Methodological Rigor in Multimodal Learning: An Analysis of "Fusion or Confusion? Multimodal Complexity Is Not All You Need" (2512.22991)
Introduction and Motivation
The paper examines prevailing practices in multimodal deep learning, specifically challenging the assumption that increasing model complexity through architectural innovations is the primary route to improved performance. The authors conduct a rigorous, large-scale empirical evaluation of 19 recent multimodal learning methods—spanning missing data strategies, encoder improvements, fusion mechanisms, and optimization techniques—across nine real-world datasets (encompassing up to 23 modalities and over 488,000 samples). Critically, all methods are re-implemented under highly standardized protocols (including controlled hyperparameter tuning and weight initialization) to isolate architectural effects from confounding methodological factors.
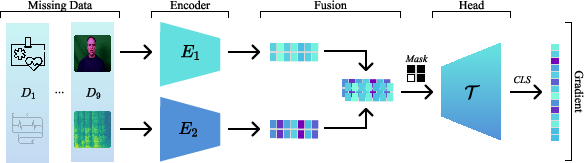
Figure 1: Taxonomy of multimodal learning methods, with late-fusion SimBaMM as the organizing baseline for architectural variants and extensions.
The central claim is that—contrary to common belief—increased architectural complexity does not result in robust, consistent performance improvements over a carefully tuned yet simple late-fusion baseline (SimBaMM). Furthermore, complex multimodal models often struggle to consistently outperform strong unimodal baselines, especially in small data regimes. The findings raise significant concerns regarding the interpretation and generalization of reported gains in the multimodal literature.
Experimental Design and Taxonomy
The paper's large-scale benchmark covers:
- Architectures: 19 representative methods grouped by innovation focus: missing modality handling (e.g., IMDer, MMP, ShaSpec), encoder-level (e.g., RegBN, AUG), fusion mechanisms (e.g., MBT, LMF, PDF, Coupled Mamba, OMIB), head-based (e.g., MulT), and gradient-based techniques (e.g., OGM, DGL, ARL, MMPareto, etc.).
- Datasets: Nine diverse tasks spanning healthcare (MIMIC-HAIM, MIMIC-Symile, INSPECT, UK Biobank) and affective computing (MOSI, MOSEI, CH-SIMS, CH-SIMS2, Crema-D).
- Evaluation Protocol: All hyperparameters (model-specific, optimizer, architectural) are tuned via a controlled Bayesian optimization process, identical data splits are used (with subject independence and missing modality simulation), and statistical outcome analysis leverages Bayesian hierarchical models with practical equivalence testing.
- Proposed Baseline - SimBaMM: A late-fusion transformer with modality-specific encoders followed by a fusion head, designed to robustly handle missingness through masking in self-attention. Two variants are explored: (i) variable-length token aggregation per modality, (ii) single-token (CLS) per modality for efficiency in non-sequential tasks.
Main Empirical Findings
1. Architectural Complexity Does Not Guarantee Gains
Across all datasets, no multimodal architecture demonstrates a high posterior probability of outperforming SimBaMM; most differences fall within a statistical region of practical equivalence (±1% AUROC, for example). Even the strongest complex contenders (e.g., Coupled Mamba, MMPareto) are only practically equivalent to the baseline, with a ∼70% probability of no meaningful difference.
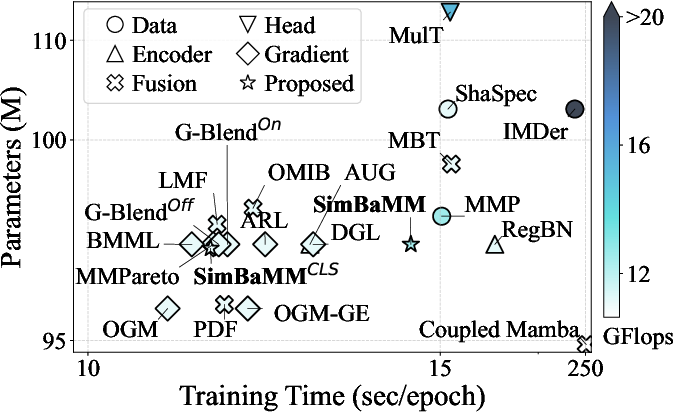
Figure 2: Comparative efficiency analysis of methods versus SimBaMM, showing that increased parameters, compute (FLOPs), and training time do not translate into significant consistent downstream performance improvements.
Moreover, many complex designs (e.g., LMF, MulT) have prohibitive quadratic scaling in the number of modalities or tokens, resulting in vanishing gradients or infeasible memory requirements on high-modality datasets (e.g., UKB with M=23).
Statistical comparisons across tasks reveal that, except for a limited subset of complex models, most multimodal architectures are outperformed by the best single-modality baseline. For example, strong unimodal performances (e.g., EHR for INSPECT or laboratory values for MIMIC) often match or surpass multimodal and fusion architectures, indicating that the true performance is anchored to the unimodal representations, rather than the fusion approach.
3. Effectiveness under Missing Modalities
Analysis under controlled missingness (simulated at the split level) demonstrates that model-specific missing modality mechanisms confer no practical advantage over SimBaMM's native (masking-based) handling, contradicting claims that such mechanisms are necessary.
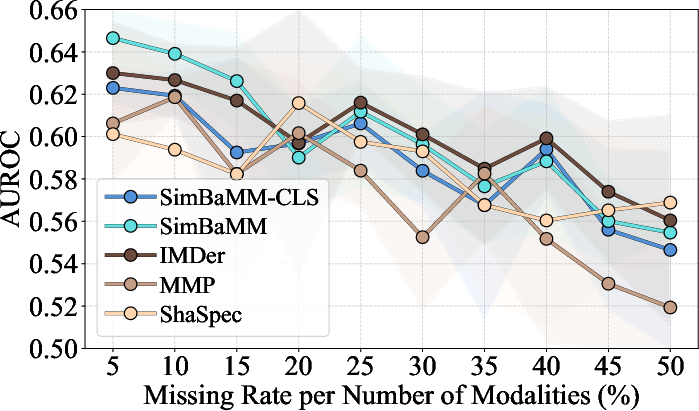
Figure 3: Missing modality analysis on MIMIC Symile—performance of all methods degrades similarly as missing rate increases, with overlapping standard deviations.
4. Computational Efficiency
Empirical results show that SimBaMM strikes a superior trade-off between efficiency (runtime, parameter count, FLOPs) and performance. For instance, certain advanced schemes (e.g., Coupled Mamba, IMDer) incur 10-20x greater runtime or FLOPs for no significant gain in accuracy/AUROC over the baseline.
5. Methodological Weaknesses in the Literature
A targeted case study on the Crema-D dataset highlights that previously reported superiority of some recent methods (e.g., AUG) disappears under subject-independent splits and proper hyperparameter tuning; in some settings, baseline methods outperform the more complex alternatives.
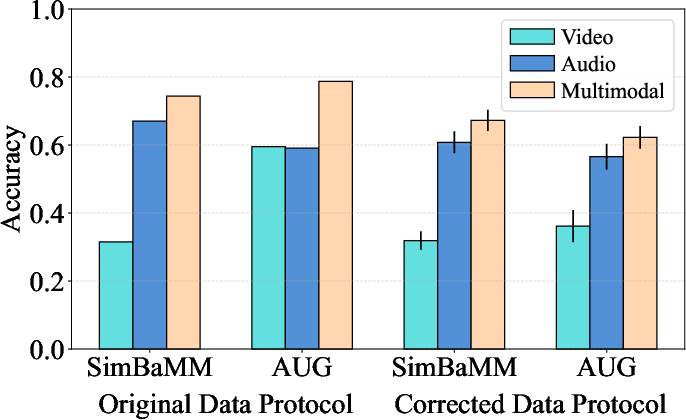
Figure 4: Case study on CREMA-D: Correcting for subject leakage and inconsistent optimization protocols reverses the comparative ranking of AUG versus SimBaMM.
Theoretical and Practical Implications
The results sharply emphasize that:
- General ML practice—methodological rigor, standardized protocols, and thorough hyperparameter search—dominates over incremental fusion or architecture-specific innovations in practical settings.
- Performance “gains” reported in the literature are often artifacts of confounded experimental practice (non-standard splits, optimizer/hyperparameter discrepancies, or permissive data leakage).
- Unimodal backbone quality is the principal driver of downstream multimodal performance—multimodality-specific innovations rarely yield benefit once methodical tuning is performed, especially when using state-of-the-art unimodal encoders.
- Claims of modality-specific learning dynamics requiring bespoke algorithms are not substantiated: most challenges in multimodal modeling (dominant modality suppression, non-alignment, distribution mismatch, etc.) are present in “unimodal” settings with heterogeneous feature blocks and do not require bespoke fusion solutions.
Recommendations and Future Directions
A checklist for reliable multimodal evaluation is proposed:
- Hold all experimental variables fixed except the tested contribution;
- Employ rigorous hyperparameter optimization for all compared methods;
- Use proper cross-validation with subject-stratified splits and report distributional results, not point metrics from single runs;
- Include both strong unimodal and simple multimodal baselines as reference;
- Benchmark across a diverse collection of non-synthetic, large-scale datasets;
- Ensure all code and splits are reproducible and openly available.
Future work is suggested in several directions:
- Extending similar analyses to other model families (early-fusion, mixture-of-experts, large-scale pre-trained or contrastive frameworks);
- Proposing unified, inclusion-maximal late-fusion architectures to serve as strong domain-agnostic baselines;
- Developing meta-benchmarks or leaderboards explicitly anchored in robust statistical methodology.
Conclusion
The exhaustive empirical evidence presented in this work mandates a reevaluation of the community’s emphasis on architectural novelty in multimodal deep learning. Gains attributed to complex fusion mechanisms or multimodal-specific architectural features vanish when subject to rigorous, uniform empirical scrutiny. Methodological rigor and the use of strong unimodal encoders constitute the main levers for performance improvement in realistic multimodal tasks. Thus, future advances in multimodal learning should focus on principles of empirical comparability, reproducibility, and validation, rather than proliferating architectural innovation without rigorous benchmarking.
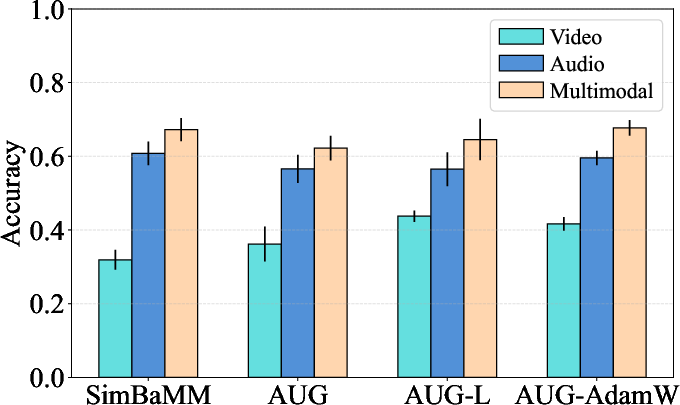
Figure 5: Alternative AUG configurations in the corrected protocol confirm that method ranking is robust to head/optimizer variations, further attesting that empirical protocol choices, not architectural tweaks, drive main performance differences.