DepFlow: Disentangled Speech Generation to Mitigate Semantic Bias in Depression Detection
Abstract: Speech is a scalable and non-invasive biomarker for early mental health screening. However, widely used depression datasets like DAIC-WOZ exhibit strong coupling between linguistic sentiment and diagnostic labels, encouraging models to learn semantic shortcuts. As a result, model robustness may be compromised in real-world scenarios, such as Camouflaged Depression, where individuals maintain socially positive or neutral language despite underlying depressive states. To mitigate this semantic bias, we propose DepFlow, a three-stage depression-conditioned text-to-speech framework. First, a Depression Acoustic Encoder learns speaker- and content-invariant depression embeddings through adversarial training, achieving effective disentanglement while preserving depression discriminability (ROC-AUC: 0.693). Second, a flow-matching TTS model with FiLM modulation injects these embeddings into synthesis, enabling control over depressive severity while preserving content and speaker identity. Third, a prototype-based severity mapping mechanism provides smooth and interpretable manipulation across the depression continuum. Using DepFlow, we construct a Camouflage Depression-oriented Augmentation (CDoA) dataset that pairs depressed acoustic patterns with positive/neutral content from a sentiment-stratified text bank, creating acoustic-semantic mismatches underrepresented in natural data. Evaluated across three depression detection architectures, CDoA improves macro-F1 by 9%, 12%, and 5%, respectively, consistently outperforming conventional augmentation strategies in depression Detection. Beyond enhancing robustness, DepFlow provides a controllable synthesis platform for conversational systems and simulation-based evaluation, where real clinical data remains limited by ethical and coverage constraints.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making computer systems better at telling if someone might be depressed by listening to how they speak. Today, many systems accidentally “cheat” by focusing too much on the words people say (like sad or negative words) instead of how they sound (their tone, energy, pacing). That’s a problem in real life, because some people with depression use positive or neutral words on purpose to hide how they feel—this is called camouflaged depression. The authors build a new tool, called DepFlow, that can create realistic speech where the “sound of depression” and the “meaning of the words” are controlled separately. This helps train fairer, more reliable detectors.
What questions are the researchers asking?
- Are current speech-based depression detectors biased because the training data links negative wording with depression too strongly?
- Can we create speech that keeps a person’s voice and words the same, but changes how “depressed” the voice sounds?
- If we train detectors with this special, mixed data (depressed-sounding voice but positive/neutral words), will the detectors stop relying on word sentiment and start paying attention to the true acoustic signs of depression?
How did they do it?
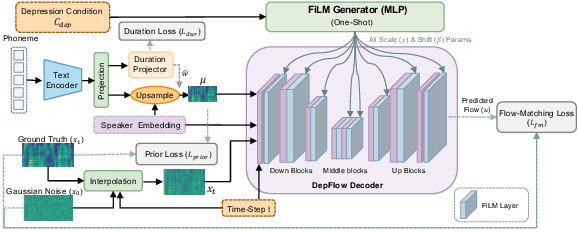
First, here’s the key idea: separate speech into three parts—what is said (words), who is speaking (voice identity), and how it sounds (acoustics linked to depression). Then, recombine them any way you want.
They build DepFlow in three stages:
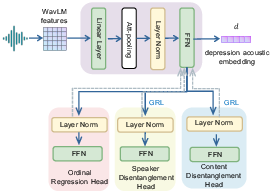
- Stage 1: Learn the “depression sound” without learning the words or the speaker
- They train a model (Depression Acoustic Encoder) to find a short “fingerprint” of how depression changes speech sound (for example, lower energy, slower speech, less clear articulation).
- To stop the model from remembering the speaker or the exact words, they use a training trick like a tug-of-war: one part tries to guess the speaker/words, while another part tries to hide that info. This pushes the fingerprint to be mostly about depression, not who or what.
- Stage 2: A voice generator that can dial depression up or down
- They use a text-to-speech model (think: high-quality voice cloning) and add a “control knob” for depression severity. This knob doesn’t change the words or the speaker’s identity—it only changes how depressed the speech sounds.
- They use a technique called FiLM, which is like applying gentle, global tone controls throughout the voice generator so the “depressed sound” affects the whole speech consistently.
- Stage 3: A clear, smooth scale for how depressed the voice should sound
- They build five “prototype” points that represent typical acoustic patterns of depression from healthy to severe (based on the PHQ-8 scale used in clinics).
- Then they smoothly move between these points when generating speech, so you can set any level from not depressed to very depressed, like sliding a volume slider.
With this setup, they create a new training set called CDoA (Camouflage Depression-oriented Augmentation): speech that has depressed acoustics paired with positive or neutral text. This “breaks” the usual shortcut (negative words = depressed) and forces detectors to learn from the sound, not just the words.
What did they find, and why does it matter?
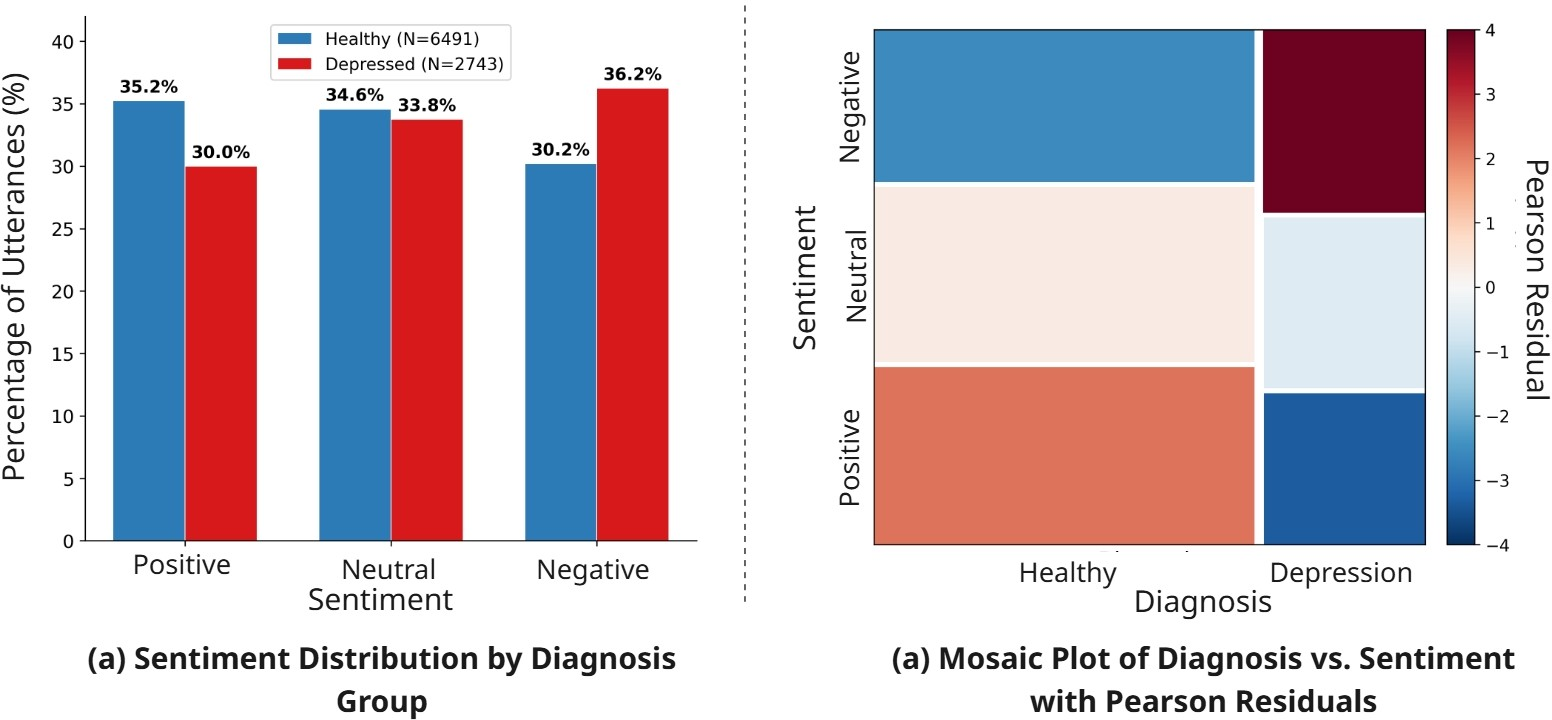
- Real data is biased: In a popular dataset (DAIC-WOZ), people labeled as depressed use more negative words. A statistical test shows this link is strong. This encourages detectors to rely on sentiment instead of true acoustic clues.
- Their depression “fingerprint” works: The encoder learns a meaningful “depression sound” space while hiding who is speaking and what they say. It still separates depressed from not-depressed fairly well.
- Smooth control is real: When they turn the depression knob up, the generated speech changes in an orderly, smooth way—both in the learned fingerprint and in real acoustic measures (like pauses, formants, voice stability). That means the control is not just numbers; it actually affects how the voice sounds in realistic, clinically sensible ways.
- Better detectors: Training with their CDoA data improved three different depression detection systems. Macro-F1 scores (a balanced accuracy measure) went up by about 9%, 12%, and 5% for the three models they tested. Their method beat common augmentation tricks like Mixup or simple audio warping.
This matters because it shows we can reduce “semantic bias” (models cheating by reading the words) and make detectors pay attention to the sound patterns that reflect mental health.
Why is this important?
- More robust in real life: Some people with depression keep their language positive. Detectors trained with DepFlow’s data are better prepared for these camouflaged cases.
- Fairer and safer: Relying less on word sentiment helps avoid mistakes based on what someone talks about, and focuses on how they speak—often a better early signal of mental health changes.
- Helps research and apps: It’s hard to collect large, varied, privacy-safe clinical speech data. DepFlow can generate controlled, realistic speech for testing, training, and building future conversational tools that are sensitive to mental health cues.
- A new foundation: By separating “what you say,” “who you are,” and “how you sound,” this approach could also help other health or emotion detection tasks where words can be misleading.
In short, DepFlow gives researchers a way to generate speech that carefully controls the “depressed sound” without changing the words or the speaker. Training with this data helps depression detectors stop taking semantic shortcuts and start listening to the real acoustic signs that matter.
Collections
Sign up for free to add this paper to one or more collections.