POSEIDON: Physics-Optimized Seismic Energy Inference and Detection Operating Network
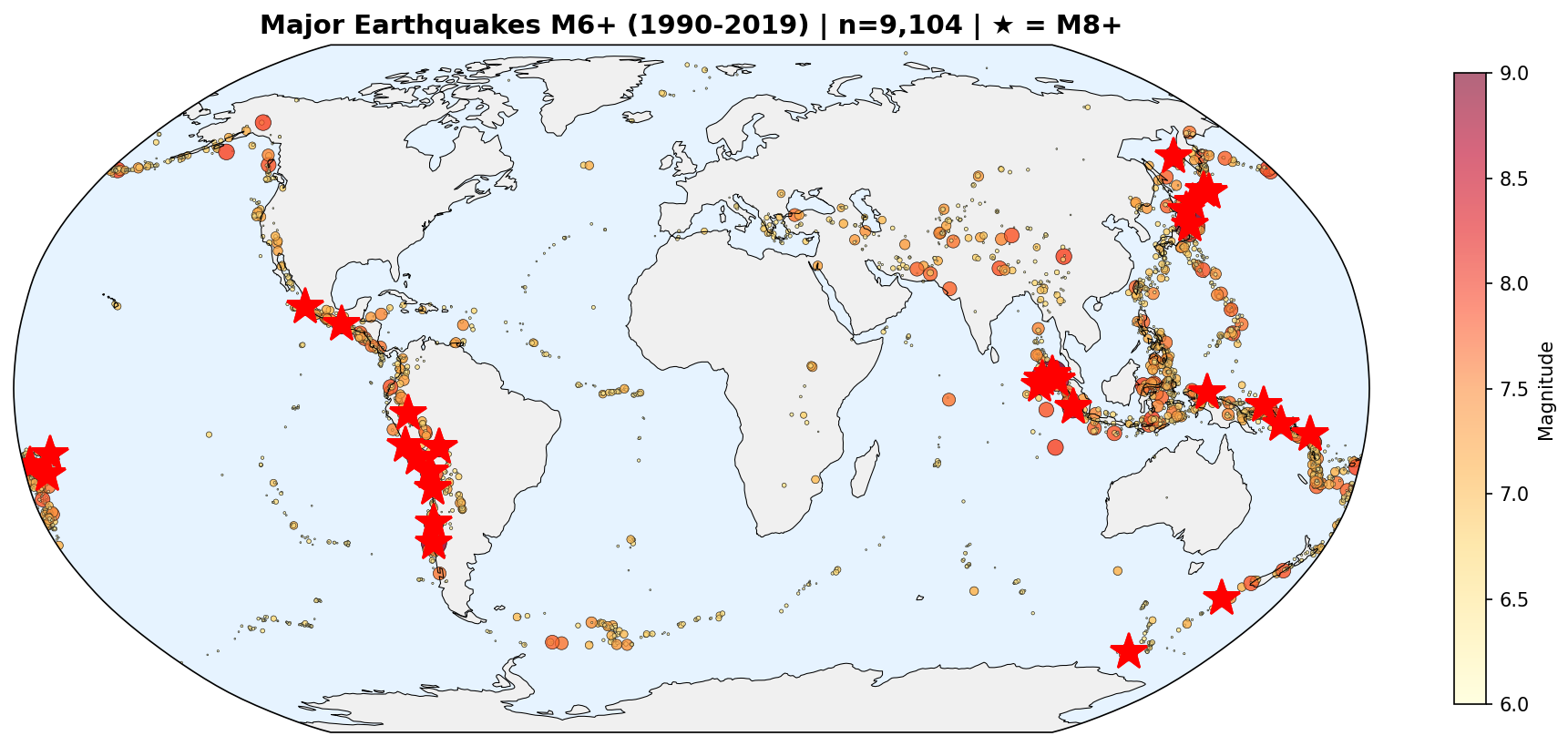
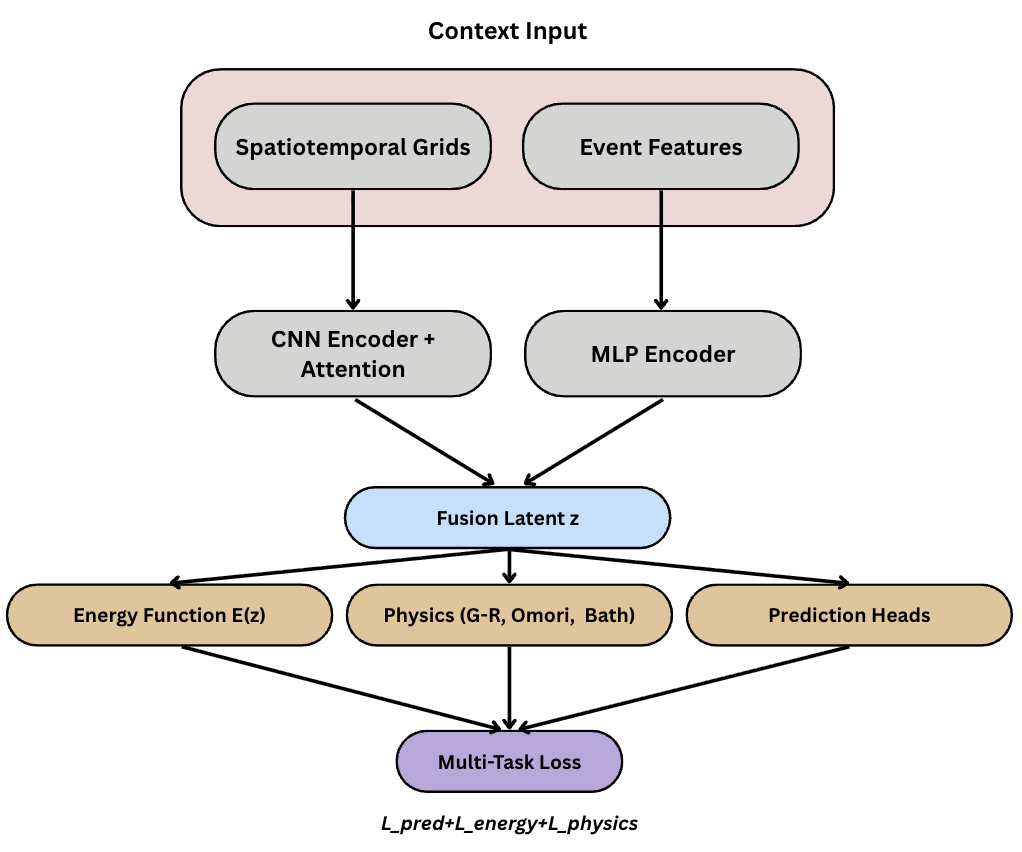
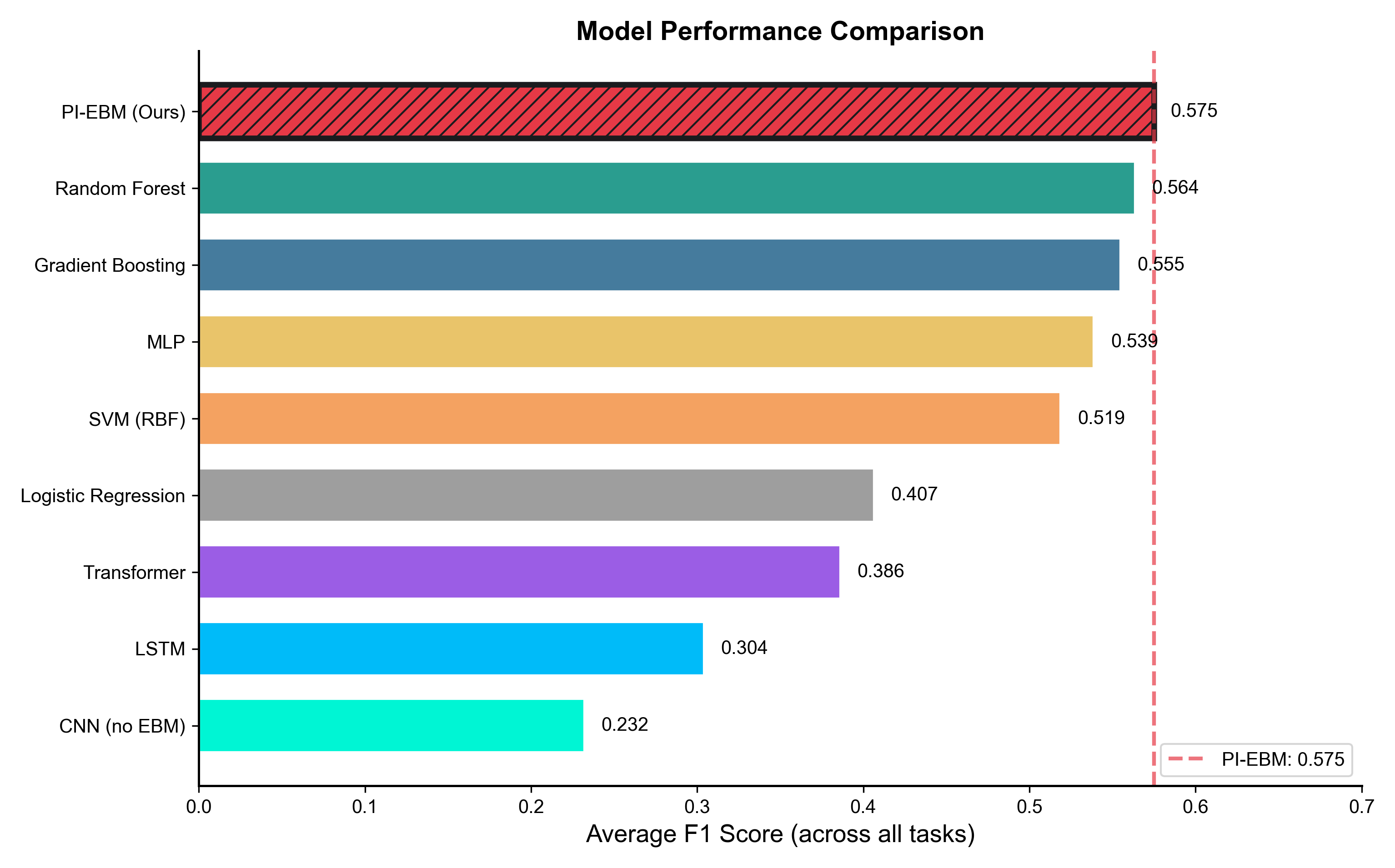
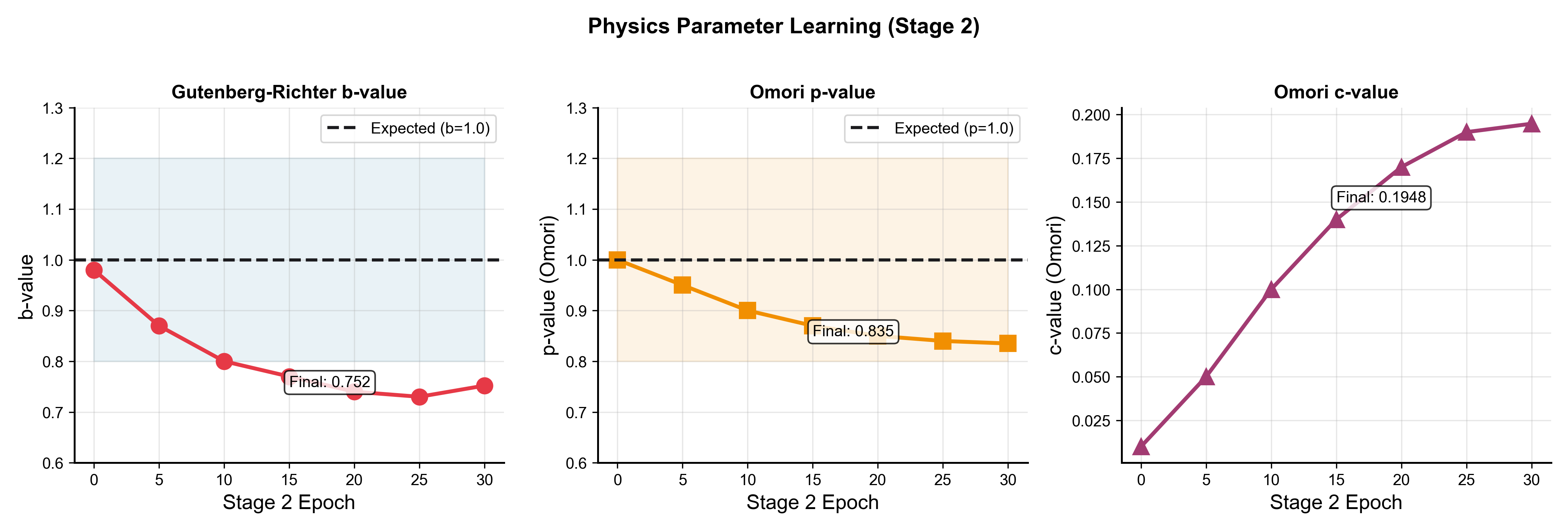
Abstract: Earthquake prediction and seismic hazard assessment remain fundamental challenges in geophysics, with existing machine learning approaches often operating as black boxes that ignore established physical laws. We introduce POSEIDON (Physics-Optimized Seismic Energy Inference and Detection Operating Network), a physics-informed energy-based model for unified multi-task seismic event prediction, alongside the Poseidon dataset -- the largest open-source global earthquake catalog comprising 2.8 million events spanning 30 years. POSEIDON embeds fundamental seismological principles, including the Gutenberg-Richter magnitude-frequency relationship and Omori-Utsu aftershock decay law, as learnable constraints within an energy-based modeling framework. The architecture simultaneously addresses three interconnected prediction tasks: aftershock sequence identification, tsunami generation potential, and foreshock detection. Extensive experiments demonstrate that POSEIDON achieves state-of-the-art performance across all tasks, outperforming gradient boosting, random forest, and CNN baselines with the highest average F1 score among all compared methods. Crucially, the learned physics parameters converge to scientifically interpretable values -- Gutenberg-Richter b-value of 0.752 and Omori-Utsu parameters p=0.835, c=0.1948 days -- falling within established seismological ranges while enhancing rather than compromising predictive accuracy. The Poseidon dataset is publicly available at https://huggingface.co/datasets/BorisKriuk/Poseidon, providing pre-computed energy features, spatial grid indices, and standardized quality metrics to advance physics-informed seismic research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces POSEIDON, a smart computer system that learns to predict earthquake-related events while following real-world physics rules. It also releases a huge, free dataset of 2.8 million earthquakes from around the world. The big idea is to make predictions (like whether aftershocks or tsunamis might happen) that are both accurate and trustworthy because the system is guided by laws that geologists already know are true.
What questions did the researchers ask?
The researchers focused on three connected questions about earthquakes:
- Aftershocks: After a big earthquake, which nearby quakes are likely to be aftershocks?
- Tsunami risk: Did an earthquake likely create a tsunami?
- Foreshocks: Was a smaller quake actually a warning sign (foreshock) of a bigger one that followed?
How did they do it?
They combined a massive global earthquake dataset with a physics-guided AI model so the computer “plays by the rules of nature” while learning patterns.
The dataset (Poseidon)
- It contains 2.8 million earthquakes over 30 years, worldwide.
- For each earthquake, it includes location, time, depth, magnitude, quality info, and extra features.
- It also includes “energy” for each quake, computed from a known rule: bigger magnitude means much more energy (about 32 times more energy for each +1.0 in magnitude). The formula they use is like a recipe: log10(E) = 1.5 × magnitude + 4.8.
Physics-informed learning (teaching the model the rules of earthquakes)
Most AI models are “black boxes.” This one is different. It’s trained to follow key seismology laws:
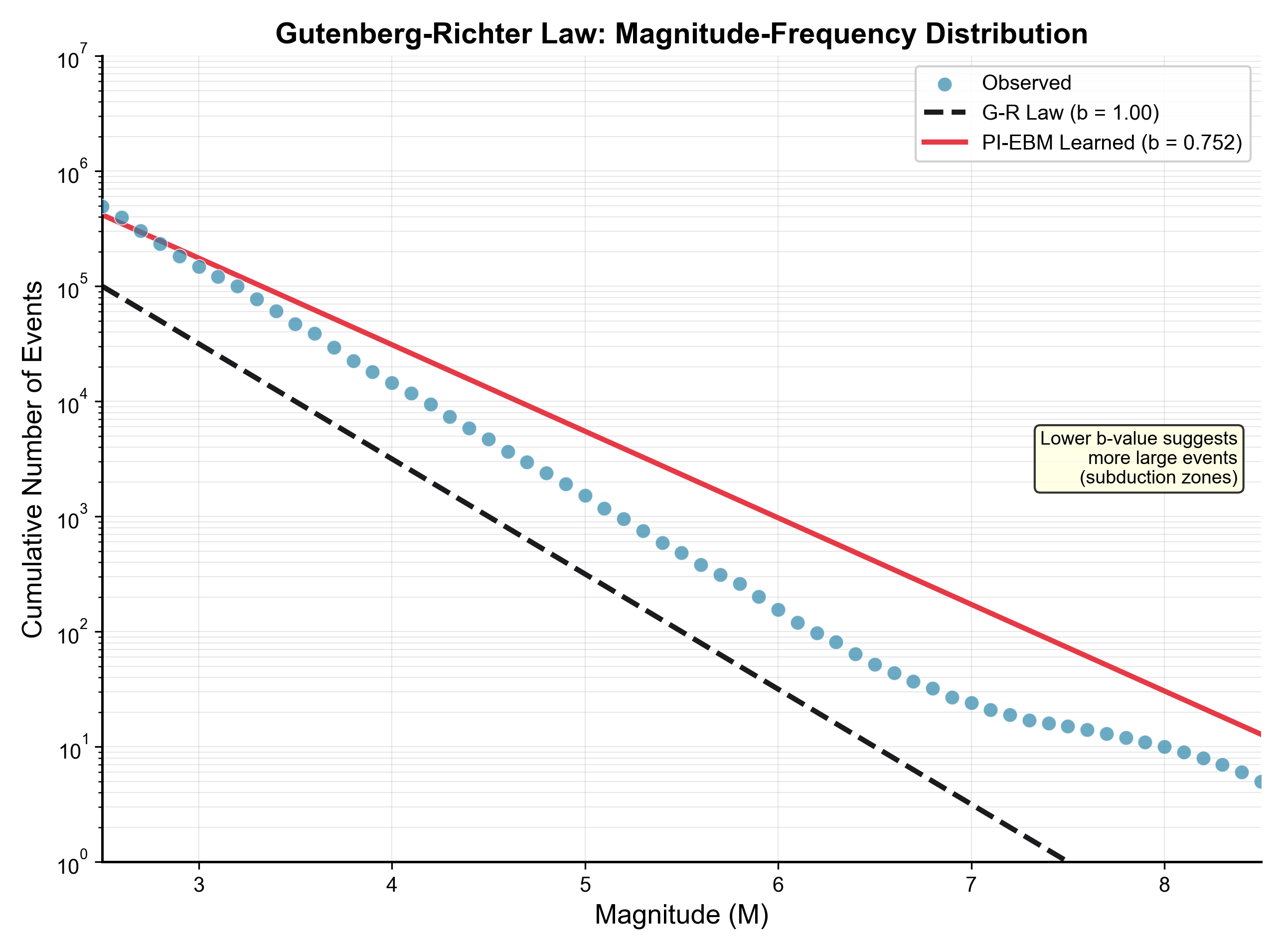
- Gutenberg–Richter law: Small quakes happen far more often than big ones. Think of it like a pyramid—lots of small blocks at the bottom, very few big blocks at the top.
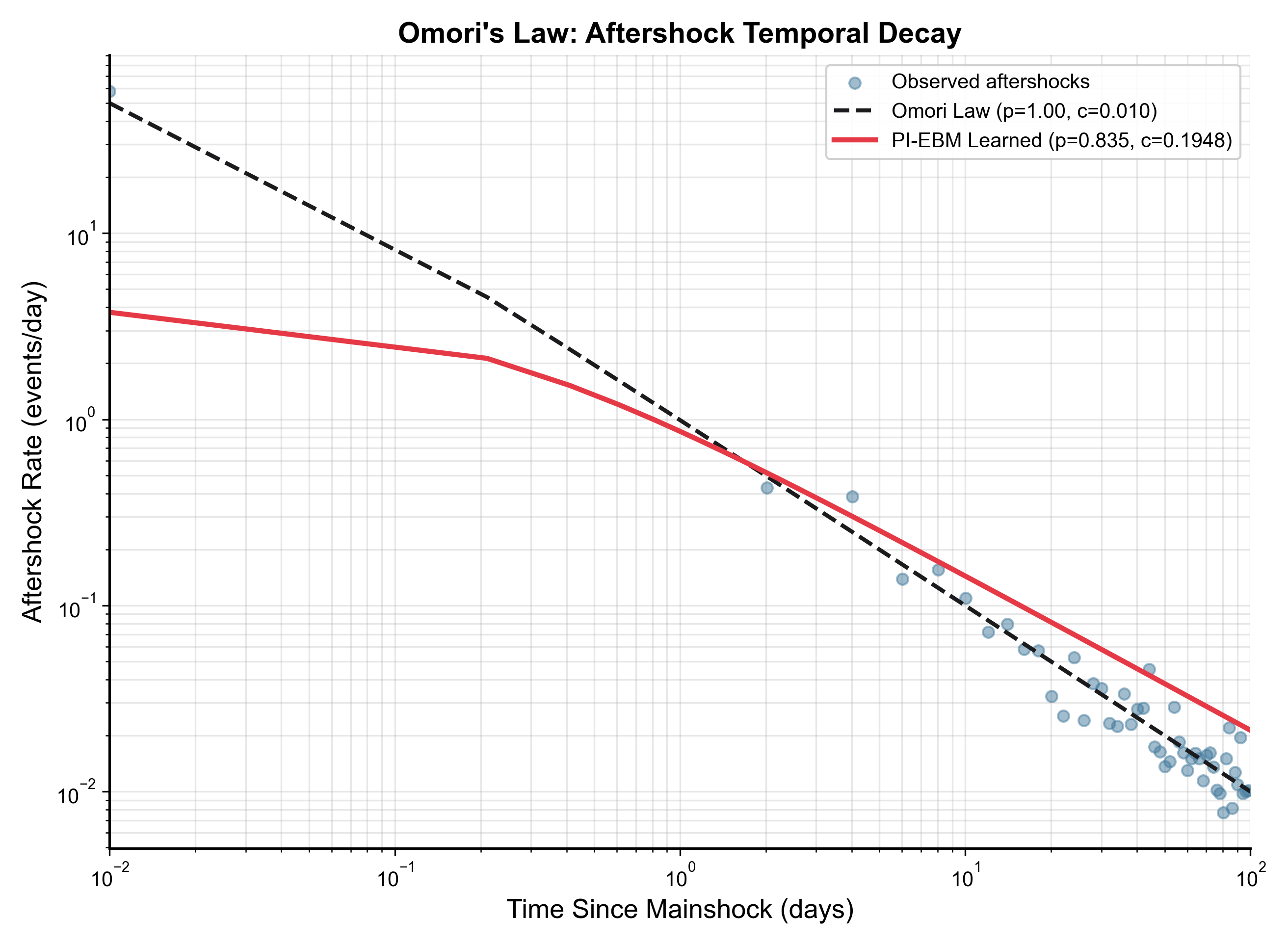
- Omori–Utsu law: Aftershocks are common right after a big quake and then fade over time.
- Bath’s law: The biggest aftershock is usually about 1.2 magnitude units smaller than the main earthquake.
The model treats these laws like “gentle guide rails” during training: if it starts to learn something that breaks these rules, it gets a penalty and adjusts.
Energy-based model (an everyday analogy)
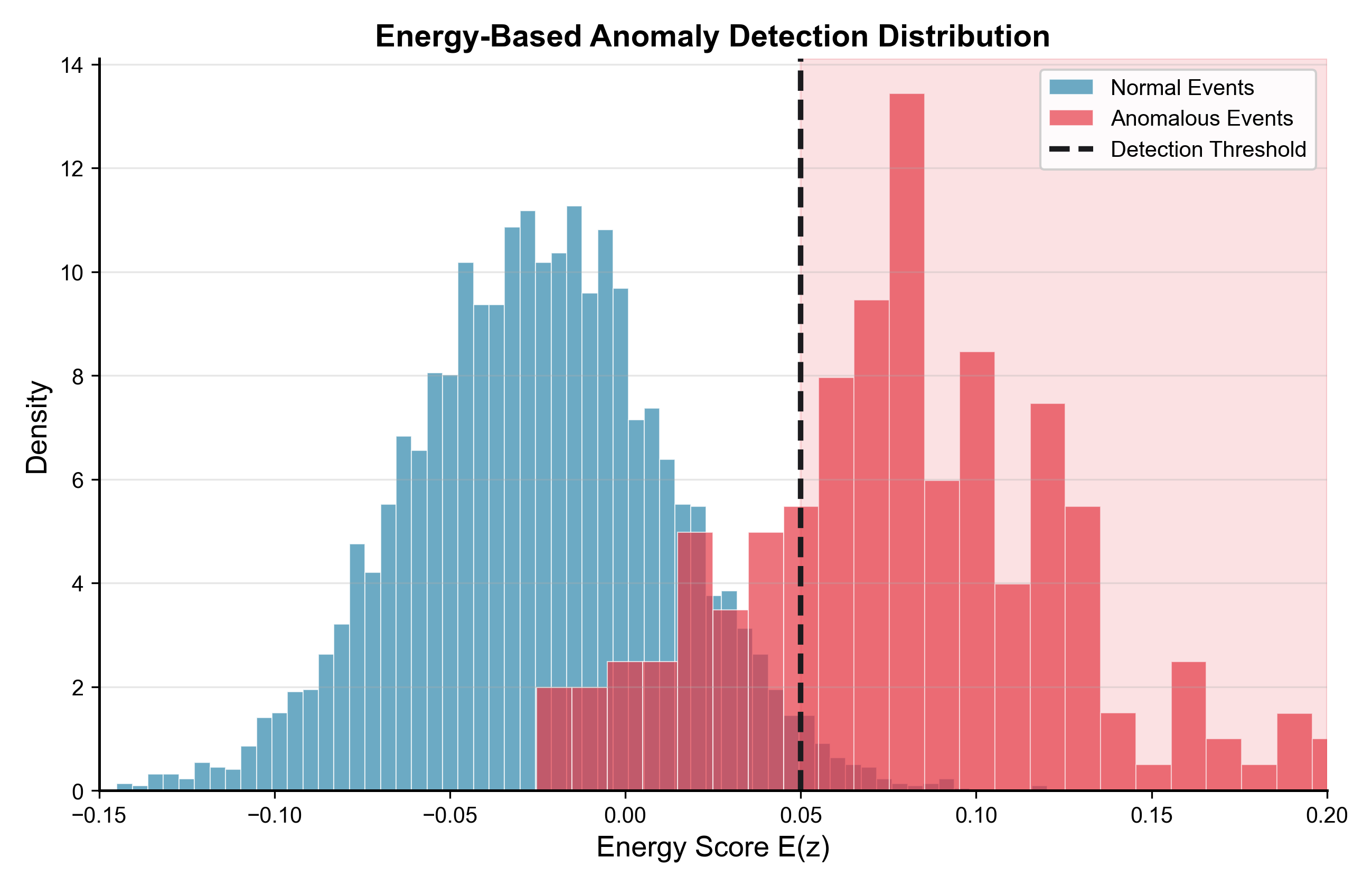
The model gives each possible situation a single number called “energy.” Lower energy means “this looks realistic and matches the rules,” higher energy means “this looks unlikely.” Imagine a marble rolling on a landscape: it settles in valleys (low energy, realistic) and avoids peaks (high energy, unlikely). This helps the model spot unusual or risky cases.
Looking across space and time
- The model turns recent earthquake activity into world maps (grids) at three time scales: the past 7 days (short-term), 30 days (medium-term), and 90 days (long-term).
- It learns which regions and which time scales matter most for each task. For example, aftershocks are most influenced by the last week, while foreshocks can depend more on longer-term patterns.
Handling rare events
Tsunami-making earthquakes are very rare in the data. The team adjusted training so the model still pays attention to these rare but critical cases (by rebalancing the data and using special loss functions).
What did they find?
Here are the key results in simple terms:
- Overall, POSEIDON beat other common methods (like random forests, gradient boosting, or basic CNNs) when looking at performance across all three tasks together.
- Aftershock prediction: It reached a balanced accuracy score (F1) around 0.76. In plain terms, it did well at both finding aftershocks and not over-calling them.
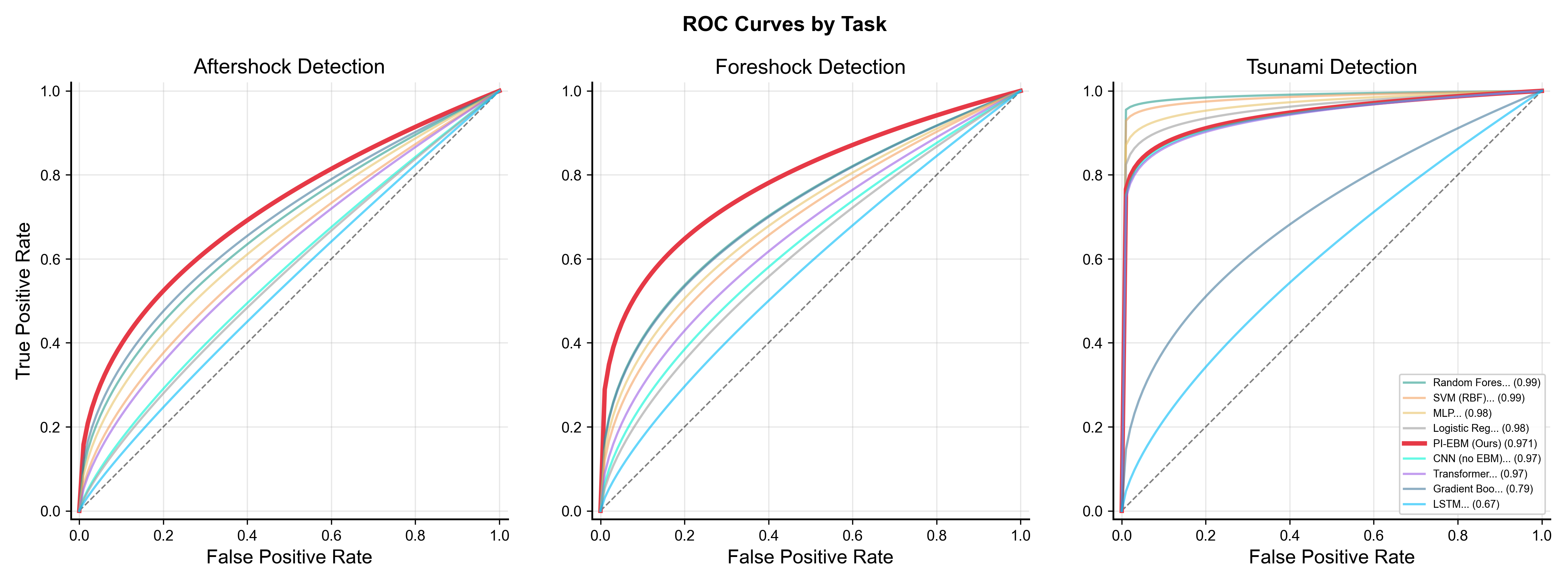
- Tsunami detection: It was very good at ranking which quakes might cause tsunamis (AUC ≈ 0.97). AUC is a score from 0.5 (guessing) to 1.0 (perfect). 0.97 is excellent, especially with so few tsunami events in the data.
- Foreshock detection: It also performed strongly (AUC ≈ 0.87), meaning it could often spot quakes that were “warnings” for bigger ones.
Just as important, the physics values the model learned matched what scientists expect:
- Gutenberg–Richter b-value ≈ 0.75 (within known ranges; lower values put more weight on bigger quakes, which fits the training focus on stronger events).
- Omori–Utsu parameters: p ≈ 0.835 and c ≈ 0.195 days (both reasonable and realistic).
- These matches make the model’s predictions more trustworthy because they align with decades of seismology research.
They also showed the “energy” score can help flag unusual or significant events, giving a second layer of warning beyond simple yes/no predictions.
Why does this matter?
This research shows we can build AI that is both:
- Accurate: It performs at or near state-of-the-art levels across several hard earthquake tasks.
- Trustworthy: It follows known laws of earthquake behavior, which makes scientists and safety planners more confident in its predictions.
Potential impacts include:
- Better early warnings for aftershocks and tsunamis, which can save lives and guide emergency responses.
- More transparent AI for high-stakes decisions, because the model’s learned physics parameters are interpretable.
- A large, public dataset that other researchers can use to improve earthquake science and build new physics-aware tools.
In short, POSEIDON is a step toward smarter, safer, and more reliable earthquake prediction by combining big data, modern AI, and the rules of nature.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that are either missing, uncertain, or left unexplored in the paper, framed to enable concrete follow-up by future researchers:
- Labeling methodology is under-specified: precise rules for defining aftershocks, foreshocks, and tsunami-generating events (spatiotemporal windows, spatial radii, mainshock association algorithm, magnitude thresholds) are not detailed, hindering reproducibility and assessment of label bias.
- Prospective, real-time evaluation is absent: performance is reported retrospectively; no event-by-event forward testing, lead-time analysis, or streaming evaluation to quantify operational early-warning utility and avoid hindsight bias.
- Energy conversion assumes moment magnitude () but dataset includes mixed magnitude types: the use of without magnitude-type harmonization likely introduces systematic errors; requires magnitude conversion (e.g., , , ) or filtering to only.
- Catalog completeness and heterogeneity are not corrected: varying magnitude of completeness () across regions and time is acknowledged but not modeled; needs per-region/time estimation (e.g., MAXC, GFT, Entire-Magnitude-Range methods) and reweighting/filtering to avoid bias in GR-law learning and downstream predictions.
- Global physics parameters mask regional variability: a single learned b-value and Omori-Utsu parameters are used globally; evaluate and/or condition physics constraints by tectonic regime, depth, and region (e.g., subduction vs. continental crust), and produce regional maps and uncertainty for b, p, c.
- Bath’s law constraint is inconsistent with seismology: learned versus expected ≈1.2; investigate whether the loss is mis-specified (sign/definition), whether trigger selection biases the estimate, and perform per-region analyses and constraint reweighting/regularization.
- Tsunami prediction lacks key geophysical drivers: no focal mechanisms, rake/dip/strike, centroid depth, trench proximity, slab geometry, bathymetry, or seafloor deformation proxies; incorporate these features and validate against continuous tsunami intensity metrics (wave height/run-up) rather than a binary flag.
- Missing comparisons to domain-standard baselines: aftershock forecasting is not benchmarked against ETAS/STEP or Coulomb stress transfer models, and tsunami potential is not contrasted with operational hydrodynamic models; add these baselines and hybrid physics-ML comparisons.
- Probability calibration is unassessed: report calibration curves, Brier score, expected calibration error, and decision-analytic performance (cost curves, utility under false-alarm/false-miss trade-offs) for operational thresholds.
- Out-of-distribution robustness is claimed but not demonstrated: define OOD scenarios (new regions, time periods, induced seismicity, volcanic swarms) and quantify EBM-based OOD detection and performance degradation under distribution shift.
- Train/validation split strategy risks leakage: clarify whether splits are by time and region to prevent cross-sequence leakage (e.g., aftershock clusters spanning folds); implement strict temporal blocking and spatial partitioning.
- Spatial resolution limitations: 1-degree grids are coarse for fault-scale phenomena; perform sensitivity analyses to grid resolution, adopt multi-resolution tiling, and integrate fault traces, plate boundaries, and slab models into spatial encoding.
- Uncertainty quantification is minimal: energy thresholds are used heuristically; provide calibrated predictive intervals (e.g., Bayesian EBMs, conformal prediction), quantify epistemic vs. aleatoric uncertainty, and propagate catalog measurement errors into predictions.
- Reliance on catalog metadata only: integrate waveform-derived features (e.g., P/S phase attributes, source time functions), finite-fault models, and moment tensors; perform ablations to quantify their incremental value.
- Multi-task learning benefit is not isolated: include controlled ablations comparing joint training vs. single-task heads and report transfer gains/negative transfer across tasks.
- Interpretability is global, not localized: attention visualizations and physics parameters are not linked to local physical drivers; provide regional attention maps, causal/ counterfactual analyses, and case studies tying attention to known tectonic features.
- Operational readiness untested: report inference latency, computational footprint, data ingestion pipeline, and end-to-end timelines; conduct retrospective case studies (e.g., 2004 Sumatra-Andaman, 2011 Tohoku) with prospective replay to assess actionable performance.
- Dataset curation and quality controls are limited: detail filtering of non-earthquake events (e.g., quarry blasts), handling of magnitude/depth uncertainties, and quality thresholds; release standardized splits and label-generation code for reproducibility.
- Extreme class imbalance for tsunami remains problematic: high AUC but low precision indicates many false positives; explore cost-sensitive training, threshold optimization per basin, and hierarchical models that first screen “tsunamigenic contexts” (near-trench, shallow thrusts) before final classification.
- Sensitivity to hyperparameters and constraint weights is not reported: systematically vary physics-loss weights, contrastive margin, sampling weights, and learning rates to quantify stability and identify robust configurations.
- Case-study validation is missing: provide detailed analyses on landmark sequences (aftershock cascades, foreshock clusters, tsunamigenic megathrusts) with error diagnostics to understand failure modes and constraint interactions.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging POSEIDON’s released dataset, model design, and demonstrated performance for aftershocks, tsunami potential, and foreshock detection.
- Seismic operations triage and decision support
- Sectors: emergency management, civil protection, seismological agencies, software
- Use case: After a moderate-to-large mainshock (M5+), auto-generate 7–30 day aftershock probability maps and ranked hotspot lists to prioritize inspections, cordons, and resource staging.
- Tools/workflows: REST API or microservice that ingests latest catalog entries (e.g., USGS/EMSC feeds) and outputs p_aftershock, p_tsunami, p_foreshock with uncertainty (energy scores); web dashboard or QGIS plugin for spatial overlays.
- Assumptions/dependencies: Real-time catalog completeness and latency; regional calibration of thresholds; trained primarily on M5+ triggers; 1° grid resolution does not capture local site effects.
- Tsunami pre-screening for warning centers
- Sectors: coastal safety, maritime, ports, policy
- Use case: Use the model’s high AUC (0.971) to rank new events for rapid hydrodynamic simulation and instrument confirmation, reducing time-to-decision for watches/warnings.
- Tools/workflows: A “tsunami triage” queue that triggers high-fidelity simulations first for events with high p_tsunami; integration with PTWC/JMA-style pipelines.
- Assumptions/dependencies: Precision is modest (0.273), so operational thresholds should be cost-sensitive; include additional signals (depth, focal mechanism, trench proximity) to reduce false positives.
- Aftershock-aware inspection and safety protocols
- Sectors: utilities, transportation (rail, roads, aviation), energy, construction
- Use case: Conditional operational modes (e.g., derating transformers or gas pipelines, speed restrictions on rail) activated when p_aftershock exceeds a predefined threshold around critical assets.
- Tools/workflows: Asset risk overlays; automated SOP triggers linking geofenced assets to model outputs.
- Assumptions/dependencies: Regional tuning to asset fragility; not a substitute for structural assessments or shaking intensity forecasts.
- Catastrophe insurance exposure management
- Sectors: insurance/reinsurance, finance
- Use case: Real-time aftershock risk signals to adjust claims reserving and deploy loss adjusters; integrate tsunami potential for coastal portfolios.
- Tools/workflows: “CatModel augmentor” that feeds POSEIDON probabilities into existing cat models for near-term loss scenarios; dashboards for portfolio heatmaps.
- Assumptions/dependencies: Portfolio geocoding accuracy; calibrated mapping from probabilities to expected loss multipliers.
- Scientific benchmarking and reproducible research
- Sectors: academia, research labs
- Use case: Use the Poseidon dataset (2.8M events) with pre-computed energy features to benchmark physics-informed ML methods, test regional b-values, and evaluate multi-task learning under class imbalance.
- Tools/workflows: Open datasets via Hugging Face; baseline training scripts; Jupyter notebooks for curriculum and lab exercises in geophysics/ML courses.
- Assumptions/dependencies: Consistent data licensing; clear train/validation splits for fair comparison.
- Energy-based anomaly and OOD detection for network QA/QC
- Sectors: seismic network operations, software
- Use case: Use learned energy scores to flag anomalous sequences or potential catalog issues (e.g., mislocated events, quarry blasts) for analyst review.
- Tools/workflows: Threshold-based alerts (e.g., E > 0.05) integrated into analyst consoles; periodic reports of anomalous clusters.
- Assumptions/dependencies: Thresholds tuned to local event rates; anomaly does not imply hazard—route to human validation.
- Public risk communication aids after large events
- Sectors: public safety, media, daily life
- Use case: Contextual statements like “elevated aftershock probability in the next 7 days” with simple risk bands to guide behavior (checking gas lines, avoiding unstable slopes, securing shelves).
- Tools/workflows: Infographics and mobile notifications that translate probabilities into actionable guidance.
- Assumptions/dependencies: Clear disclaimers about probabilistic nature and uncertainty; coordination with local authorities.
- HPC resource orchestration for hazard simulations
- Sectors: research computing, coastal engineering
- Use case: Automatically queue high-resolution tsunami or stress-transfer simulations for top-ranked events.
- Tools/workflows: “SeisSim Orchestrator” that consumes model outputs to schedule jobs on HPC/cloud.
- Assumptions/dependencies: Access to compute; data connectors to simulation codes (e.g., MOST, COMCOT).
Long-Term Applications
These applications are feasible with additional research, scaling, or integration of new data sources (e.g., real-time waveforms, focal mechanisms) and broader validation.
- Integrated, physics-informed operational early warning
- Sectors: national warning systems, policy
- Use case: Combine real-time waveform features with POSEIDON’s multi-task outputs for continuous, regionalized hazard forecasting and automated alerting.
- Tools/workflows: Fusion of catalog + waveform streams (SeisComP/Earthworm) with physics-informed ML; continuous calibration and prospective testing.
- Assumptions/dependencies: Robust real-time telemetry; region-specific training; rigorous prospective validation and regulatory approval.
- Tsunami “autopilot” pipeline
- Sectors: coastal safety, maritime
- Use case: End-to-end automation from event detection to coastal inundation guidance, triggered by high p_tsunami and enriched with focal mechanisms and bathymetry to initialize hydrodynamic models.
- Tools/workflows: Event classifier → source characterization → adaptive mesh hydrodynamics → inundation map API for ports and emergency managers.
- Assumptions/dependencies: Rapid availability of source parameters; high-fidelity bathymetry and coastal topography; uncertainty quantification for map products.
- Dynamic infrastructure resilience management
- Sectors: energy, utilities, telecommunications, transportation
- Use case: Closed-loop control strategies (pre-emptive islanding, automated valve shutoff, drone inspections) driven by evolving aftershock/foreshock risk and model uncertainty.
- Tools/workflows: Integration with SCADA/EMS, UAS routing, and EAM/CMMS systems; digital twins for scenario rehearsal.
- Assumptions/dependencies: Cyber-physical integration; robust fail-safes to avoid overreaction to false positives; cybersecurity hardening.
- Policy and hazard model updates using learned physics parameters
- Sectors: public policy, building codes, urban planning
- Use case: Incorporate regionally tuned b-values and Omori-Utsu parameters into time-dependent seismic hazard models, inspection mandates, and post-earthquake reopening criteria.
- Tools/workflows: Regulatory guidance that maps probability bands to action thresholds (e.g., inspection tiers, occupancy limits).
- Assumptions/dependencies: Regionalization of parameters; expert review; alignment with existing PSHA frameworks.
- Parametric and micro-insurance products for near-term seismic risk
- Sectors: finance, insurance
- Use case: Short-duration covers priced dynamically based on near-term aftershock or tsunami risk, with automated triggers tied to model outputs plus independent verifiers (e.g., tide gauges).
- Tools/workflows: Smart contracts or straight-through processing; risk APIs for brokers.
- Assumptions/dependencies: Regulatory acceptance; transparent calibration; independent data for trigger verification.
- Autonomous inspection and response robotics
- Sectors: robotics, public safety, infrastructure
- Use case: Risk-prioritized dispatch of ground/air robots to survey structures, pipelines, or lifelines after mainshocks and in high aftershock windows.
- Tools/workflows: Fleet management that ingests POSEIDON risk layers to optimize routes and inspection order.
- Assumptions/dependencies: Reliable autonomy; safe airspace access; integration with asset registries.
- Supply chain and market risk signaling
- Sectors: logistics, finance
- Use case: Adjust shipping routes, inventory buffers, and hedging strategies based on projected aftershock or tsunami disruptions around key hubs (ports, industrial clusters).
- Tools/workflows: “Quake-impact signals” feeding TMS/WMS and market risk engines.
- Assumptions/dependencies: Coupling hazard outputs to disruption models; avoiding overreaction to low-probability signals.
- Education and workforce development at scale
- Sectors: education, training
- Use case: MOOCs and lab curricula on physics-informed ML for geohazards, using Poseidon for assignments on multi-task learning, imbalance handling, and interpretability.
- Tools/workflows: Open syllabi, containerized notebooks, leaderboards for student challenges.
- Assumptions/dependencies: Sustained dataset hosting; institutional adoption.
- Cross-hazard transfer learning frameworks
- Sectors: environmental risk, earth observation
- Use case: Adapt the physics-informed energy-based approach to volcano unrest, landslides, wildfires, or permafrost risk where empirical “laws” can be embedded as constraints.
- Tools/workflows: Modular PINN/EBM libraries with pluggable domain laws and multi-task heads.
- Assumptions/dependencies: Availability of analogous empirical relations and labeled datasets; domain expert collaboration.
- Adaptive model architectures (dynamic morphing/epigenetic mechanisms)
- Sectors: AI/ML research, operational analytics
- Use case: Continual learning systems that reconfigure post-major events and across tectonic regimes to maintain calibration without retraining from scratch.
- Tools/workflows: Online learning pipelines; safe model update mechanisms with rollback and shadow testing.
- Assumptions/dependencies: Mature MLOps; drift detection; governance for model changes.
Cross-cutting assumptions and dependencies
- Prospective, region-specific validation is essential; global parameters (e.g., b=0.752) may not generalize locally.
- Foreshock and tsunami tasks exhibit class imbalance; operational thresholds must be tuned to risk tolerance and cost asymmetry.
- Bath’s law fit deviates from canonical value, signaling the need for careful interpretation and possibly task-specific reweighting.
- The 1° spatial grid and catalog-only features limit local intensity and site-effect inference; coupling with ground-motion models and structural data is recommended.
- Ethical and policy considerations: communicate uncertainty clearly; avoid deterministic “prediction” claims; ensure transparency of physics constraints and model calibration.
Glossary
- AdamW optimization: A variant of the Adam optimizer that decouples weight decay from the gradient update to improve generalization. "Training proceeds in two stages using AdamW optimization"
- Aftershock: A smaller earthquake that occurs after a mainshock, typically nearby in space and time, as part of a sequence. "aftershock sequence identification"
- Azimuthal gap: A measure of how evenly seismic stations surround an event, defined by the largest angle between neighboring stations as seen from the epicenter. "azimuthal gap measurements"
- Bath's law: An empirical seismological rule stating that the largest aftershock is typically about 1.2 magnitude units smaller than the mainshock. "Bath's law constrains the magnitude difference between mainshock and largest aftershock:"
- b-value: The slope parameter in the Gutenberg–Richter law describing how earthquake frequency decreases with increasing magnitude. "Gutenberg-Richter b-value of 0.752"
- Channel attention: A neural attention mechanism that re-weights feature channels to emphasize the most informative ones. "the channel attention module assigns highest weights to maximum magnitude (0.35) and seismic energy (0.28) channels"
- Contrastive loss: A learning objective that brings representations of similar (positive) samples closer while pushing dissimilar (negative) samples apart. "Training uses contrastive loss encouraging lower energy for observed versus perturbed configurations:"
- Cosine annealing: A learning-rate scheduling strategy that follows a cosine decay curve, often with warm restarts, to improve convergence. "the second stage activates physics constraints with reduced learning rate and cosine annealing"
- Elastodynamic principles: Physical laws governing the propagation of elastic waves in solids, used to model seismic wave behavior. "using elastodynamic principles"
- Energy-based model: A modeling framework that assigns a scalar “energy” to configurations, where lower energy indicates higher model compatibility. "Energy-based models learn to assign scalar energy values to variable configurations, offering natural uncertainty quantification and out-of-distribution detection capabilities"
- Energy landscape: The distribution of energy values over configurations learned by an energy-based model, used to interpret confidence and detect anomalies. "The energy-based framework learns meaningful energy landscapes for anomaly detection"
- Epigenetic learning: An adaptive mechanism inspired by gene regulation that modulates network behavior based on context without changing underlying weights. "Epigenetic learning draws inspiration from biological gene regulation, introducing mechanisms that modulate network parameters based on contextual signals without altering underlying weights."
- Focal loss: A loss function designed to address class imbalance by down-weighting easy examples and focusing training on hard cases. "with γ=2.0 for tsunami prediction addressing extreme imbalance"
- Foreshock: A smaller earthquake that precedes a larger mainshock, potentially indicating an upcoming significant event. "Foreshock detection reaches F1 of 0.556 with AUC of 0.865"
- Gutenberg-Richter law: An empirical relationship describing the log-linear decrease in earthquake frequency with increasing magnitude. "Gutenberg-Richter magnitude-frequency relationship"
- Hypocenter depth: The depth below the Earth’s surface at which an earthquake rupture starts (the focus). "hypocenter depth"
- KL divergence: A measure of how one probability distribution diverges from another, used here to compare modeled and observed aftershock decay. "loss minimizing KL divergence between predicted decay λ(Δ t) = K/(Δ t + c)p and observed temporal distributions."
- Magnitude deficit: A feature quantifying the shortfall of observed magnitudes relative to expected levels in a local context. "magnitude deficit"
- Magnitude–energy scaling relation: A physics-based mapping from earthquake magnitude to radiated energy (e.g., log10(E) = 1.5M + 4.8). "energy-magnitude scaling relations"
- Omori-Utsu law: A law describing the temporal decay of aftershock rates following a mainshock as a power-law function of time. "Omori-Utsu aftershock decay law"
- OneCycleLR: A cyclical learning-rate policy that increases then decreases the learning rate within a cycle to accelerate convergence. "OneCycleLR scheduling"
- Receiver Operating Characteristic (ROC) curve: A plot of true positive rate versus false positive rate across thresholds, summarizing classifier performance. "ROC curves for all prediction tasks."
- Spatial attention: A mechanism that highlights important regions in spatial inputs, improving focus on relevant areas. "Spatial attention concentrates on regions with elevated seismicity, focusing on active zones while suppressing attention to quiescent areas."
- Tsunamigenic: Capable of generating a tsunami, typically referring to earthquakes with certain characteristics. "tsunamigenic earthquakes"
- Weighted sampling: A data sampling strategy that assigns higher selection probabilities to underrepresented classes to mitigate imbalance. "Weighted sampling with w_i = 1 + 10 * 1[tsunami_i] + 3 * 1[foreshock_i] addresses class imbalance."
Collections
Sign up for free to add this paper to one or more collections.