- The paper introduces mHC-lite, which directly parameterizes residual matrices as convex combinations of permutation matrices to achieve exact doubly stochasticity.
- It eliminates the need for iterative Sinkhorn–Knopp normalization, thereby improving training stability and computational efficiency in deep neural networks.
- Empirical evaluations demonstrate superior performance and gradient stability across various datasets and deep model architectures.
mHC-lite: Reparameterizing Residual Connections with Exact Doubly Stochasticity
Introduction and Motivation
The evolution of residual architectures in deep neural networks has underpinned the scalable training of deep models, enabling advances in Transformer-based LLMs and other modern architectures. Hyper-Connections (HC) extend classical residual mappings by dynamically mixing multiple streams through learnable residual matrices, accelerating convergence and potentially improving expressivity. Manifold-Constrained Hyper-Connections (m) sought to enhance stability by projecting these residual matrices onto the Birkhoff polytope—i.e., the set of doubly stochastic matrices—via iterative Sinkhorn–Knopp (SK) normalization.
However, finite SK iterations do not ensure exact doubly stochasticity, introducing an approximation gap and propagating instability, especially as model depth increases. The mHC-lite proposal leverages the Birkhoff–von Neumann theorem to parameterize these matrices directly as convex combinations of permutation matrices, thus guaranteeing exact doubly stochasticity without iterative projection or reliance on specialized kernels.
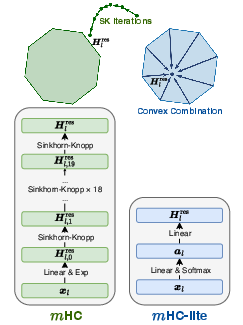
Figure 1: Schematic contrasting SK-based construction of residual matrices in m versus exact convex combination in m-lite.
Methodology
mHC-lite reforms the dynamic residual matrix, replacing the iterative SK normalization with a direct, efficient, and theoretically exact construction. For n residual streams, every doubly stochastic matrix in the Birkhoff polytope is represented as a convex combination of n! permutation matrices. The weights for these permutations are produced via a trainable softmax layer conditioned on layer inputs, with the explicit matrix assembly implemented via native matrix multiplications.
This reparameterization strictly enforces row and column sums to unity (doubly stochasticity), ensuring spectral norm control and stability under repeated matrix composition across layers. Moreover, by sidestepping specialized CUDA kernels and the need to store/recompute intermediate iteration results, this method is portable and computationally friendly.
Theoretical and Empirical Analysis
The SK algorithm is provably non-uniform in convergence for ill-conditioned matrices, requiring up to O(ϵ2n2log(n/ν)) iterations for ℓ1-error at most ϵ, where ν is the relative entry range. Empirical evaluation reveals that a substantial fraction of input matrices to SK in the m block have extremely large relative range (1/ν≥1013), resulting in persistent deviation from the doubly stochastic constraint after the standard (20) iterations.
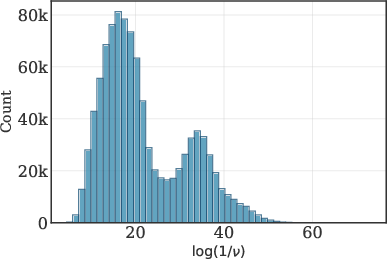
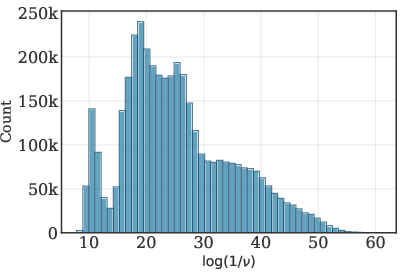
Figure 2: Distribution of log(1/ν) for SK input matrices, indicating slow convergence potential for high relative range.
This deviation manifests in unstable column sums in layerwise and stacked residual matrices, which becomes more pronounced with increased depth, threatening gradient stability and learning dynamics.
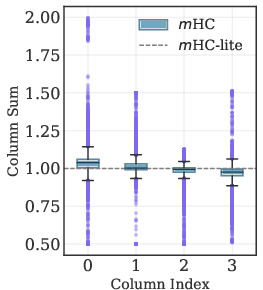
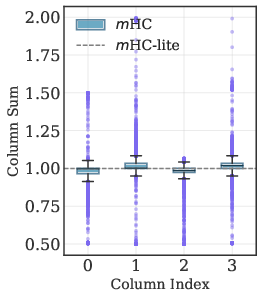
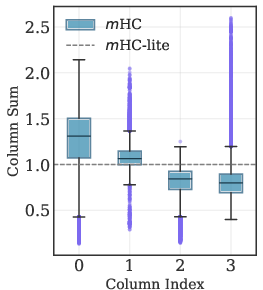
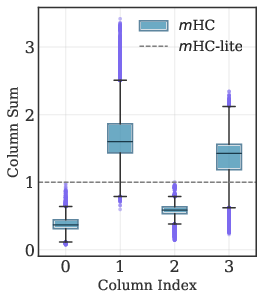
Figure 3: Boxplots of column sums for single-layer and multi-layer (stacked product) ${\boldsymbol{H}^{\text{res}}$ matrices; m-lite maintains exact unity.
mHC-lite, by construction, eliminates these approximation gaps. Empirical results demonstrate that mHC-lite matches or exceeds m in training and validation loss across all tested datasets and model scales, with superior gradient norm stability.
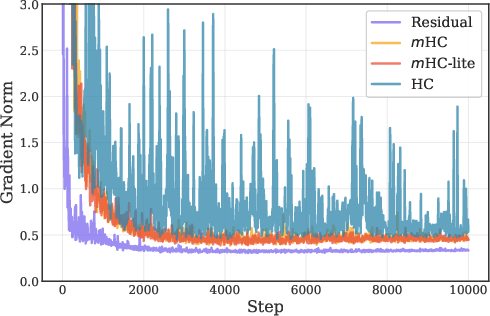
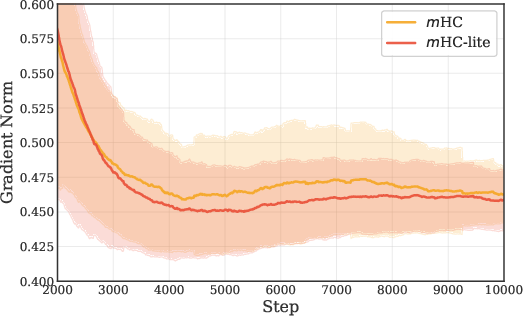
Figure 4: Gradient norm trajectories during training; m-lite exhibits lower mean and fluctuation compared to m.
Computational Efficiency
The computational efficiency of mHC-lite is a direct consequence of its implementation with standard matrix operations. Unlike m, whose efficiency depends on bespoke kernel optimization, mHC-lite achieves higher throughput, even in naive implementations. System-level benchmarks show a token throughput advantage for mHC-lite over both HC and m (the latter implemented without kernel fusion).
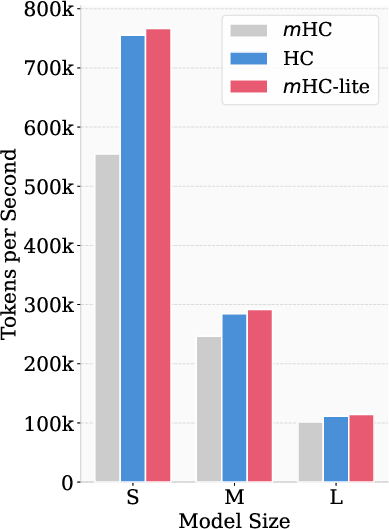
Figure 5: Training token throughput comparisons on A100 GPUs; m-lite exceeds HC and PyTorch-based m implementations.
Scalability is achievable for practical n (e.g., n=4 streams, yielding n!=24 permutations), with alternative strategies such as sampling subsets for larger n.
Practical and Theoretical Implications
mHC-lite provides a rigorous mechanism for stability in deep architectures, relevant for highly scaled models (e.g., recent 1,000-layer networks in RL). The paradigm shift from approximate projection to exact reparameterization of constrained matrices sets a template for other constraint enforcement problems in neural network design, removing sources of instability and engineering overhead.
The guaranteed stability of mHC-lite enables further architectural exploration: deeper models, more expressive multi-stream residual structures, and simplified deployment in diverse training frameworks. For adaptive or heterogenous architectures, the convex combination mechanism may also facilitate regularization or interpretability of routing through permutations.
Conclusion
mHC-lite constitutes a robust alternative to iterative projection-based manifold constraint, enforcing exact doubly stochasticity in residual connectivity with minimal computational and engineering cost. The design addresses lingering instabilities in prior architectures, maintains or improves model performance, and enhances computational efficiency and portability. The reparameterization strategy, grounded in foundational matrix theory, invites broader applications and paves the way for stable, expressive residual designs in future AI systems.