- The paper shows that using MTQE rewards for RL substantially enhances idiom translation, with improvements around 13.67 points on key metrics.
- It employs GRPO with four reward configurations and a training-free structured prompting pipeline to address non-compositional translation challenges.
- The approach improves both general and cross-lingual translation performance without degrading standard sentence translation quality.
MTQE-Driven RL for Idiom Translation: Systematic Gains in General Machine Translation
Introduction
This work rigorously investigates the translation of non-compositional expressions—idioms, proverbs, and metaphors—across Chinese and Hindi, with the overarching claim that focused improvement in idiom translation capabilities yields systemic improvements in general translation performance. The research prioritizes fine-tuning LLMs via Group Relative Policy Optimization (GRPO), guided by Machine Translation Quality Estimation (MTQE) models as reward functions. Experimental results demonstrate not only substantial idiom translation improvements, but also the broader elevation of models' general translation abilities.
Challenges in Non-Compositional Translation
Non-compositional phrases present three core translation challenges: (i) meanings irreducible to constituent words, (ii) lack of semantically equivalent target idioms, and (iii) high context-dependency leading to ambiguity. Existing neural MT models display a strong literal translation bias, significantly degrading idiomatic fidelity and erasing embedded cultural meaning.
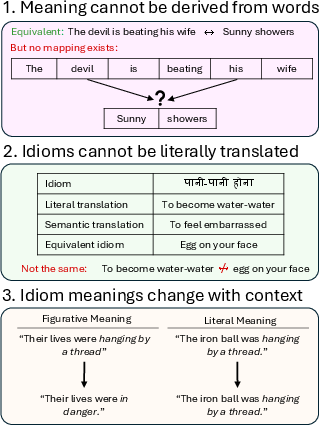
Figure 1: Three categorical challenges in the modeling and translation of non-compositional phrases (i) semantic irreducibility, (ii) literal bias, and (iii) context dependence.
GRPO with MTQE: RL-Based Fine-Tuning
The central methodological contribution is the use of GRPO reinforcement learning, with reward signals derived from MTQE models—specifically, COMET variants. MTQE reward functions are deployed in four configurations: QE-Positive (promote semantic equivalence), QE-Negative (suppress equivalence to literal translation), QE-Constrained (joint positive and negative reward), and QE-DA (reference-based direct assessment). Each reward setup operationalizes a different type of semantic supervision for idiom translation.
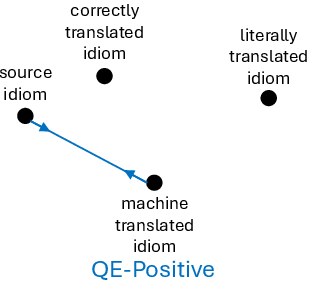
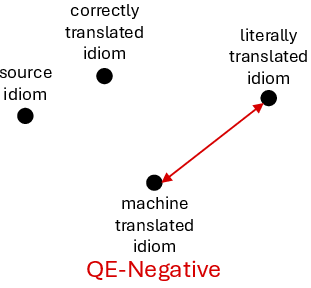
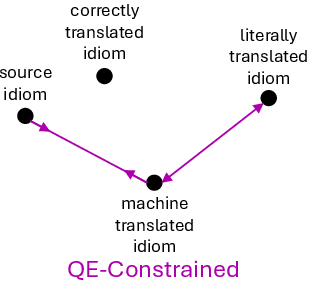
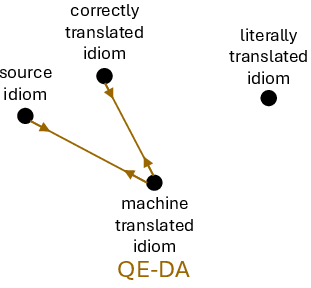
Figure 2: Schematic of the GRPO-QE reward strategies: positive, negative, constrained, and DA-based reinforcement signals for fine-tuning idiom translation models.
Training-Free Structured Prompting
In parallel, a training-free prompting pipeline is introduced to address literal bias via explicit reasoning: idiomatic explanation, literal translation, and idiomatic paraphrase generation. This three-step prompting protocol aims to disentangle surface and figurative semantics without requiring model fine-tuning, relying solely on prompt composition.
Experimental Setup
Datasets cover Chinese idioms (PETCI) and a curated Hindi idioms set, both cleaned for validity and ambiguity. Experiments are conducted on two small-scale LLMs (Qwen 3B, Llama 8B), focusing on accessibility. The evaluation protocol integrates semantic (DA, QE, LLM-as-a-Judge), lexical (ROUGE), and embedding-based metrics.
Empirical Results
Idiomatic translation ability improves by approximately 13.67 points (mean across all metrics), non-idiomatic translation by 8.39 points, and cross-lingual transferability by 5.73 points due to GRPO-MTQE fine-tuning. Notably, RL-based models consistently outperform both base and SFT approaches, with all four reward variations yielding highly similar improvements, confirming the robustness of MTQE-guided supervision.
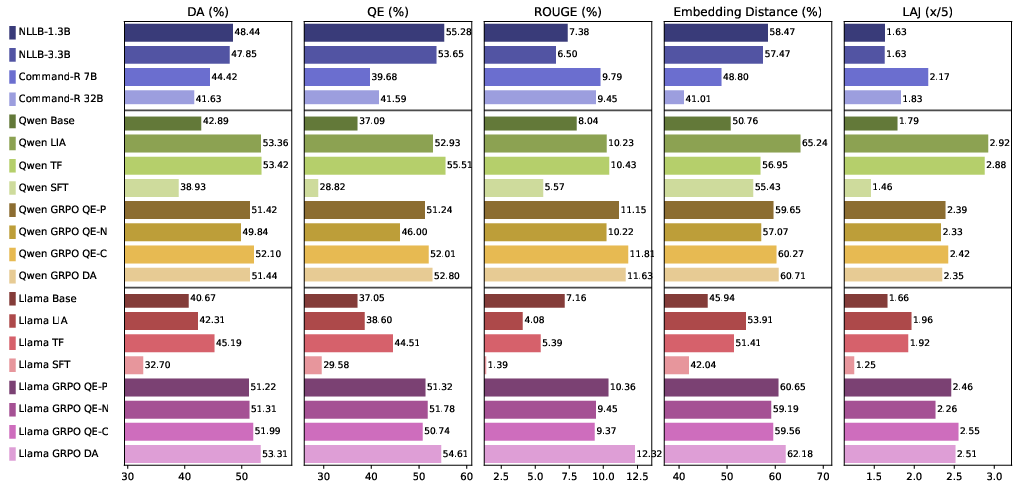
Figure 3: Comparative evaluation of Chinese idiom translation; GRPO-based models achieve consistent top performance and reliability across model sizes.
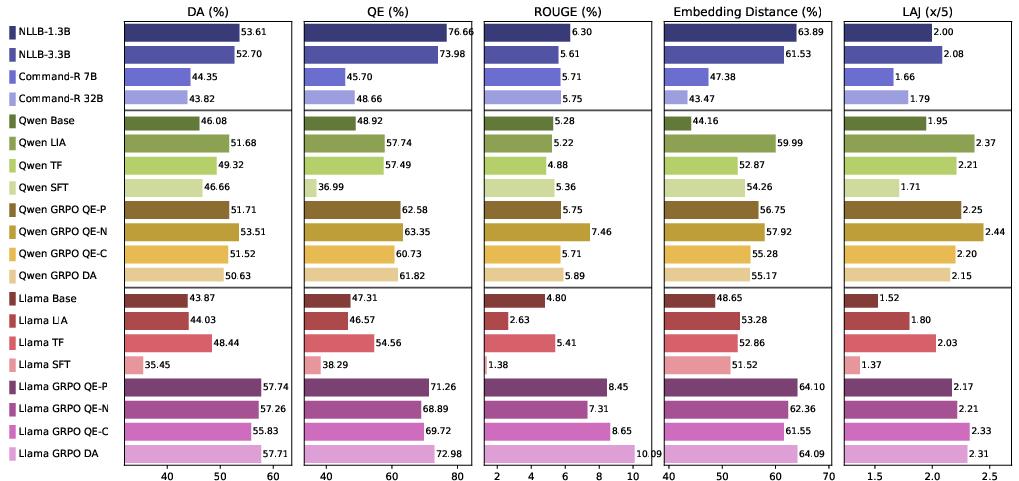
Figure 4: Hindi idiom translation assessment; core MT models retain high baseline performance, but GRPO fine-tuned LLMs match or surpass these results.
Importantly, no performance degradation is observed for regular sentence translation after idiom-focused fine-tuning.
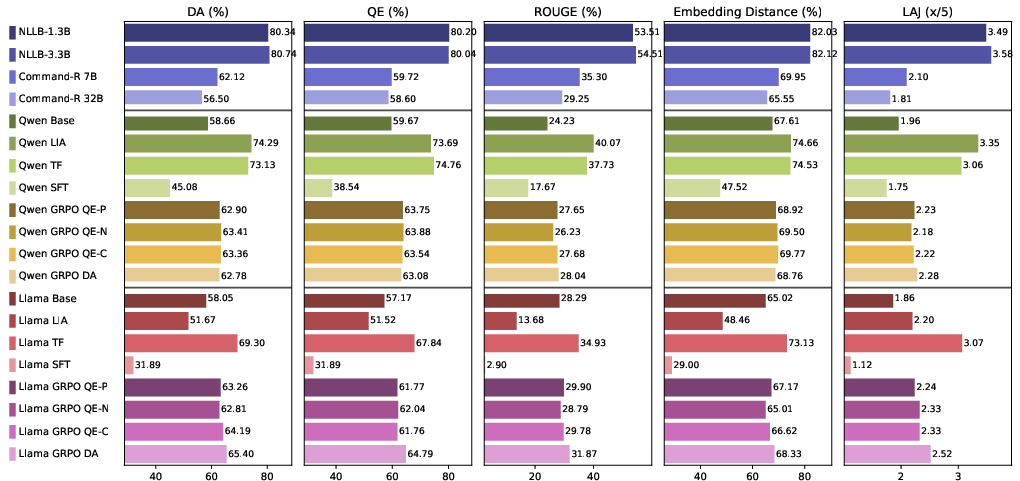
Figure 5: General Chinese sentence translation remains unaffected or improves after idiom-driven fine-tuning.
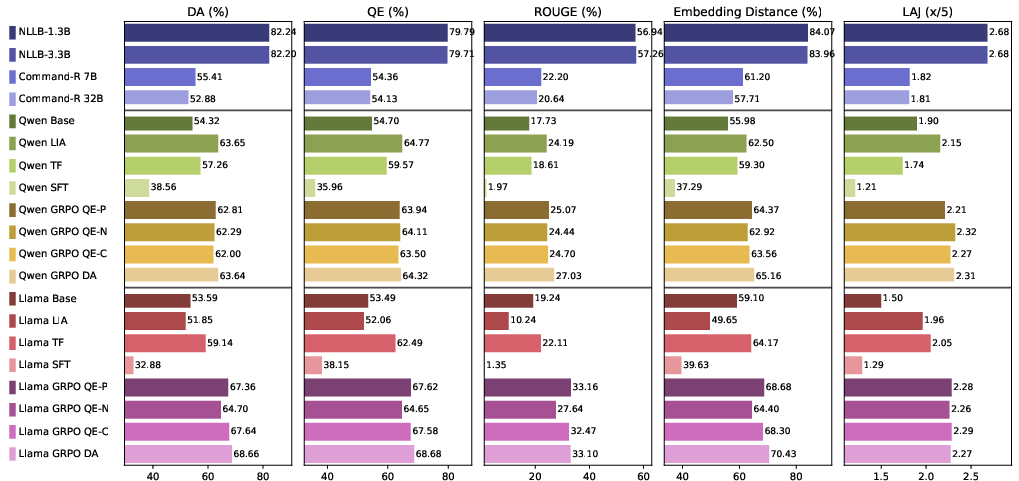
Figure 6: General Hindi sentence translation demonstrates maintained performance post idiomatic training.
The cross-lingual generalization experiments reveal that models trained on idioms in one language transfer gains to the idiomatic translation of other languages.
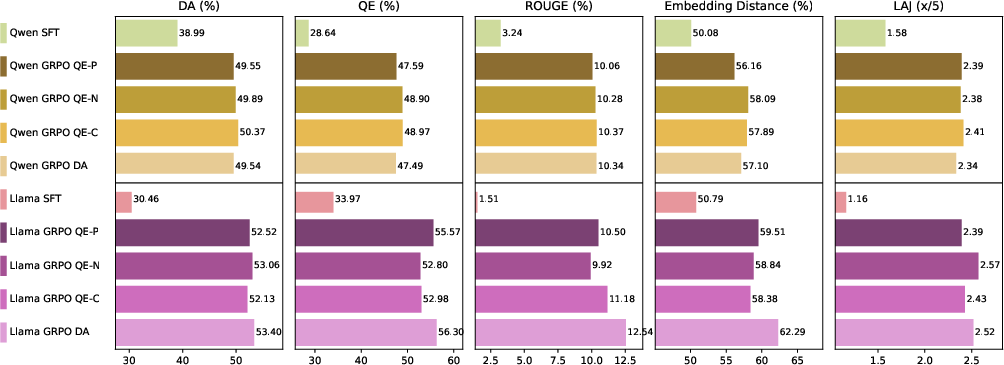
Figure 7: Hindi-trained models translating Chinese idioms outperform the base and SFT models, demonstrating cross-lingual semantic transfer.
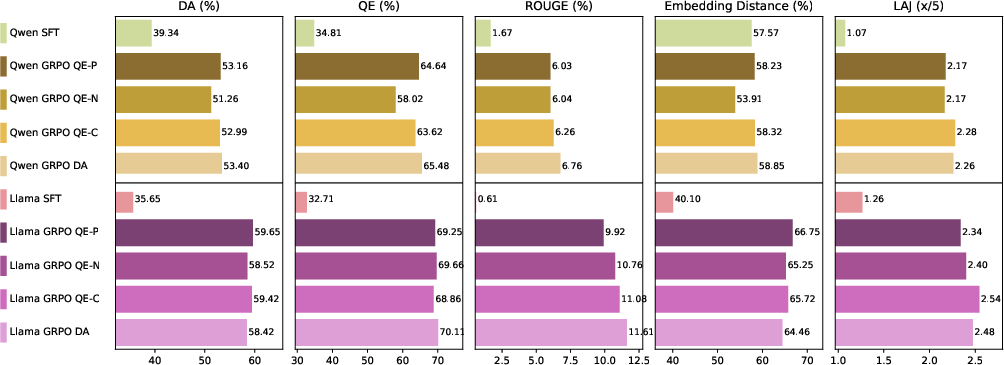
Figure 8: Chinese-trained models translating Hindi idioms similarly exhibit robust cross-lingual transfer effects.
Contradictory and Notable Claims
A striking result is that RL-based fine-tuning with idiomatic rewards not only does not degrade, but actively improves non-idiomatic translation—a bold refutation of the typical tradeoff observed in domain-focused fine-tuning. Furthermore, the least resource-intensive reward, QE-Positive, nearly matches the performance of the fully supervised QE-DA, suggesting that high-quality idiomatic translation and general improvements can be achieved with minimal supervision.
Implications and Future Directions
Practically, this implies that optimizing translation models specifically for non-compositional semantics can be systemically beneficial for general-purpose translation. Theoretically, the results support the hypothesis that cross-lingual semantic representations are unified by reinforcement-driven semantic distillation. Future research should focus on extending these findings to more languages, reducing RL computational overhead, and integrating MTQE-based reward signals with model architectures for more granular multilanguage semantic alignment. There are also implications for knowledge transfer in multilingual question-answering and cultural understanding tasks.
Conclusion
By employing MTQE rewards for GRPO-based RL fine-tuning, the work demonstrates substantial idiom translation improvement, unambiguously quantified via multimodal metrics. These gains propagate to general and cross-lingual translation capabilities, with no observed tradeoff. The research thus validates MTQE-guided RL as an efficient path to holistic multilingual translation enhancement, motivating further study in scalable reinforcement learning for diverse natural language tasks (2601.06307).