SkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
Abstract: General-purpose Large Vision-LLMs (LVLMs), despite their massive scale, often falter in dermatology due to "diffuse attention" - the inability to disentangle subtle pathological lesions from background noise. In this paper, we challenge the assumption that parameter scaling is the only path to medical precision. We introduce SkinFlow, a framework that treats diagnosis as an optimization of visual information transmission efficiency. Our approach utilizes a Virtual-Width Dynamic Vision Encoder (DVE) to "unfold" complex pathological manifolds without physical parameter expansion, coupled with a two-stage Reinforcement Learning strategy. This strategy sequentially aligns explicit medical descriptions (Stage I) and reconstructs implicit diagnostic textures (Stage II) within a constrained semantic space. Furthermore, we propose a clinically grounded evaluation protocol that prioritizes diagnostic safety and hierarchical relevance over rigid label matching. Empirical results are compelling: our 7B model establishes a new state-of-the-art on the Fitzpatrick17k benchmark, achieving a +12.06% gain in Top-1 accuracy and a +28.57% boost in Top-6 accuracy over the massive general-purpose models (e.g., Qwen3VL-235B and GPT-5.2). These findings demonstrate that optimizing geometric capacity and information flow yields superior diagnostic reasoning compared to raw parameter scaling.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SkinFlow, an AI system that helps diagnose skin diseases from photos. Instead of making the AI huge, the authors focus on sending the “right” visual information from the image to the language part of the model efficiently. Their goal is to make the AI look closely at the lesion (the problem area on the skin) and describe it clearly, then use that evidence to suggest safe, sensible diagnoses.
What problem are they trying to solve?
The authors focus on two big challenges:
- General AI models often look at the whole picture and miss small, important skin details. The paper calls this “diffuse attention,” like scanning a messy room and not noticing the one broken object you need to fix.
- Typical scoring in AI (like Top-1 accuracy) treats all wrong answers as equally wrong. In real medicine, some “near misses” are still useful and safe (for example, guessing a parent category that leads to the same treatment), while other mistakes can be dangerous (like confusing a benign rash with skin cancer). The authors want an evaluation that matches clinical reality.
What are the main questions they ask?
- Can we make a skin-diagnosis AI better by improving how visual information is encoded and decoded, rather than just adding more parameters?
- Can a model learn both clear, describable signs (like “red, scaly patch”) and subtle, hard-to-describe textures (like tiny patterns) in a structured way?
- Can we score the AI’s answers in a way that values safety and medical relevance, not just exact label matches?
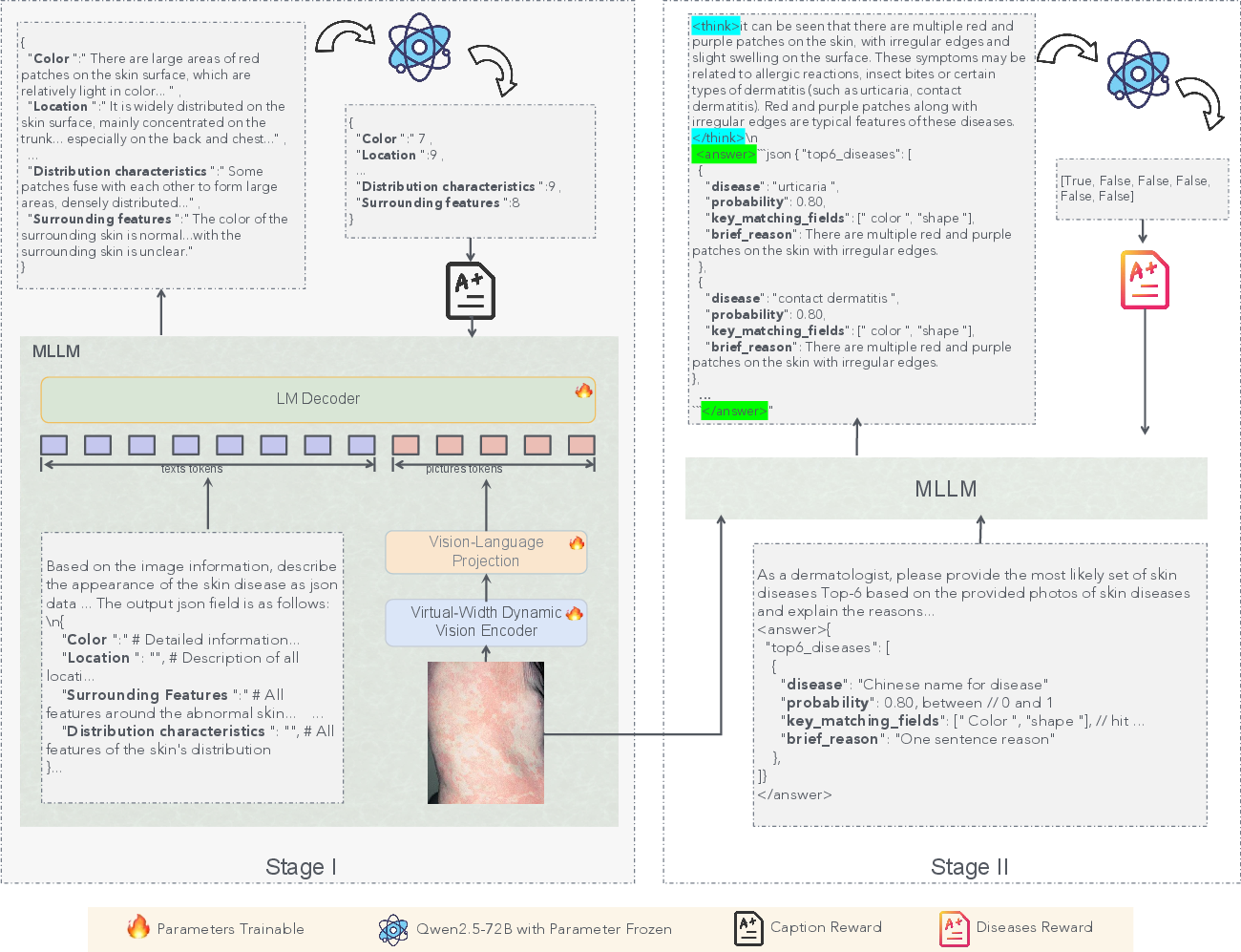
How does SkinFlow work?
To keep this simple, think of SkinFlow as a two-part learner with a smarter “camera” and a two-step training plan.
1) A smarter visual encoder (Dynamic Visual Encoding, or DVE)
- Analogy: Instead of buying a bigger camera, they add a set of smart, adjustable lenses that change based on the image. These lenses can emphasize the exact visual “frequencies” (fine vs. coarse details) that matter for skin lesions.
- Under the hood: They replace standard linear layers with a “dynamic” version (FDLinear). You can imagine FDLinear as a music equalizer for images: it splits information into different frequency bands and mixes them differently depending on the picture. This gives the model a “virtual” wider view without actually making it physically bigger, so it can separate complex patterns better and focus on the lesion instead of the background.
2) Two-stage reinforcement learning (RL)
Reinforcement learning is like training with a coach who gives rewards for good behavior rather than just copying answers.
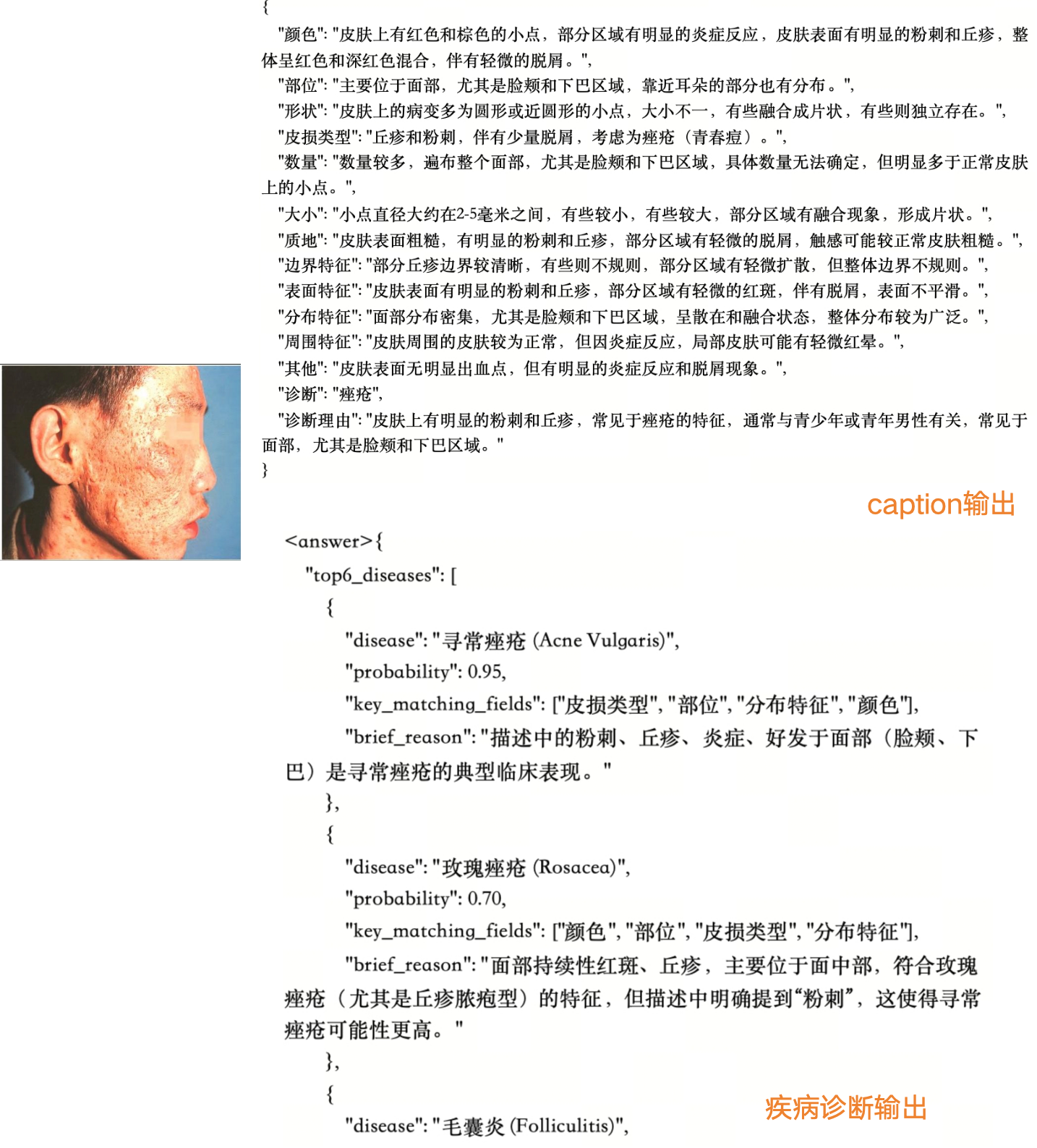
- Stage I: Caption learning (“Compression”)
- The model looks at a skin photo and writes a structured medical description (color, shape, borders, surface, etc.).
- An LLM (a LLM) checks each part (like “Is the color described well?”) and gives scores. Good descriptions get rewarded.
- Analogy: First, learn to describe a suspect accurately before trying to pick them from a lineup.
- Stage II: Diagnosis learning (“Decoding”)
- Using those strong descriptions, the model suggests the top K possible diseases (like a ranked list of guesses).
- The model earns more reward if the correct diagnosis appears higher in the list, especially if it’s clinically safe and relevant.
- Analogy: Now, use your good notes to make confident, well-ranked identifications.
Clinically grounded evaluation
- Instead of only exact matches, they judge predictions by medical safety and usefulness:
- Exact matches or accepted synonyms count as fully correct.
- Subclass or parent-class matches can be “true” if they lead to appropriate care.
- Dangerous mistakes (like confusing malignant vs. benign) are penalized heavily.
- This mirrors how doctors think and act in real clinics.
What did they find?
- Their 7B-parameter model beat much larger general models (up to 235B parameters) on a public skin-disease dataset (Fitzpatrick17k).
- Top-1 accuracy improved by about +12 percentage points.
- Top-6 accuracy improved by about +29 percentage points.
- On a carefully checked internal test, their model built better ranked lists of diagnoses (stronger Top-2 to Top-6), which is important in real cases where doctors consider multiple possibilities.
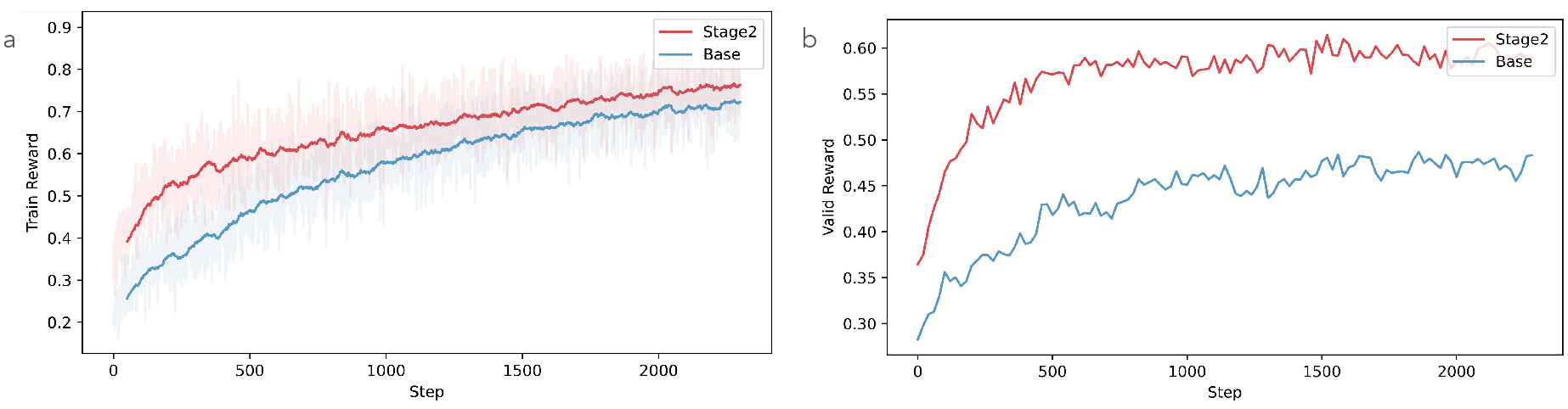
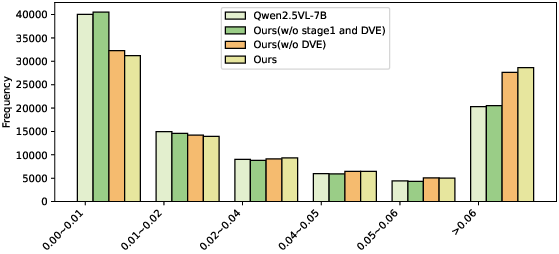
- Ablation tests (turning parts off) showed:
- Stage I caption training clearly boosts performance by helping the model align visual features with trusted medical descriptions.
- The DVE “smart lens” module further improves accuracy, especially on diverse and tricky images.
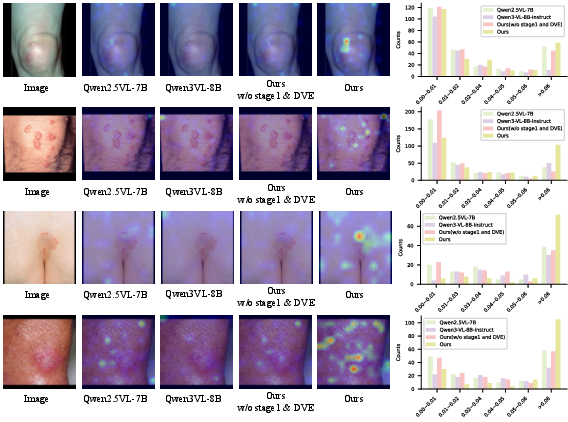
- Attention visualizations showed the model learned to focus tightly on the lesion, rather than spreading attention across background skin.
Why is this important?
- It shows that a smaller, smarter model can beat much larger ones by improving how information flows from the image to the diagnosis.
- It encourages safer, more clinically useful evaluations—rewarding predictions that are on the right medical path and punishing unsafe errors.
- It supports open-vocabulary diagnosis, meaning the model isn’t locked to a fixed list and can handle new or rare skin conditions better.
What could this mean for the future?
- Better telemedicine: Patients could send photos and get quick, helpful analysis to support doctors.
- More reliable decision support: Doctors get a ranked, safety-aware list of possibilities, reducing missed or risky diagnoses.
- Lower costs and faster deployment: Since the model is efficient, hospitals and clinics might deploy it without massive computing resources.
- Broader impact: The idea of “smart encoding + staged RL + safety-aware evaluation” could improve AI in other medical imaging areas (like radiology or pathology), not just dermatology.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address.
- External clinical validation: No prospective or retrospective clinician-led studies (e.g., blinded reader studies, multi-center trials) confirm real-world diagnostic utility, safety, or downstream outcomes.
- Fairness across skin tones: No stratified analysis by Fitzpatrick skin types, ethnicity, age, or imaging conditions; unclear performance disparities on darker skin or under varied illumination.
- Domain shift robustness: No evaluation across devices (smartphone vs. dermoscopy vs. clinical cameras), lighting, compression artifacts, occlusions, or common telemedicine degradations.
- Rare/long-tailed disease performance: Claims of open-vocabulary handling are not backed by stratified results across frequency bins (common vs. rare classes) or tail robustness analyses.
- Uncertainty calibration: No metrics (ECE, Brier score, NLL), confidence intervals, or selective prediction/abstention strategies; unclear how the model signals uncertainty to avoid harm.
- Safety-aware training: Stage II reward only promotes ranking correctness; lacks cost-sensitive penalties for safety-critical errors (e.g., malignant vs. benign, infectious vs. non-infectious).
- Human-grounded evaluation: The clinically grounded protocol is LLM-mediated (Gemini-2.5-Pro) rather than clinician adjudicated; reproducibility, bias, and validity against expert panels remain unverified.
- Reproducibility of evaluation: Prompts, taxonomy mappings, and verification rules (synonyms, hierarchy thresholds) are not released; unclear how to replicate “clinical actionability” judgments.
- Correlation validation: The “strong positive correlation” between caption reward and diagnostic accuracy is asserted but lacks statistical reporting (e.g., Pearson/Spearman, CIs, p-values) and dataset-level consistency checks.
- Structured caption quality: Stage I descriptions are scored by LLMs; limited clinician auditing of caption fidelity, completeness, and adherence to dermatology guidelines.
- Reward function sensitivity: No ablation on attribute weights, scoring thresholds (≥6), top-K positional weights w_i, or GRPO hyperparameters (group size G, ε, KL β); stability and sensitivity remain unknown.
- Comparative training paradigms: Stage II RL is not compared against strong SFT baselines for diagnosis (same data, prompts, and resources), leaving unclear whether RL drives most gains.
- Incomplete ablations: Impact of FDLinear (DVE) is shown, but there is no systematic study of basis count K, partition scheme, layer placement (why layers 8/16/24/32), or alternatives (MoE, dynamic convs, low-rank adapters).
- Theoretical rigor: Cover’s Theorem argument is heuristic for structured images; no formal capacity/generalization bounds or proofs connecting FDLinear’s “virtual width” to separability on natural medical images.
- Frequency partitioning choices: No justification or comparison for frequency group design (e.g., concentric bands vs. learned partitions), masking strategies, or potential spectral artifacts in learned weights.
- Compute and latency: No measurements of FLOPs, memory footprint, inference latency, or throughput under realistic deployment constraints; unclear on-device feasibility for clinics/telemedicine.
- Backbone generality: DVE is only tested with Qwen2.5-VL-7B; portability to other backbones (e.g., LLaVA, InternVL), scales (13B, 34B), or encoder architectures remains unverified.
- Dataset provenance and leakage: Training data sources are not fully specified; unclear overlap with evaluation sets (e.g., Fitzpatrick17k) or potential leakage/near-duplicate contamination.
- Multi-label and comorbidity: Dermatological cases often have multiple concurrent conditions; the method and evaluation assume single-label diagnosis without multi-label adaptation or triage-level outputs.
- Actionable guidance: Beyond diagnosis, no assessment of treatment recommendation consistency, triage prioritization, or care pathways; clinical utility beyond label ranking is untested.
- Open-vocabulary mapping: Synonym/alias normalization is LLM-based; no authoritative ontology integration (SNOMED CT, ICD-10, Derm1M ontology) or error analysis for taxonomy mismatches.
- OOD detection: No mechanisms for detecting out-of-distribution images or unknown conditions; unclear how the system handles unfamiliar or ambiguous cases safely.
- Explainability verification: Cross-attention visualizations are qualitative; no quantitative explainability metrics (e.g., pointing game, insertion/deletion tests) or clinician-rated evidence alignment.
- Longitudinal and multi-view data: Real cases often require multi-angle, temporal progression, or paired clinical metadata; the approach and evaluation are single-image only.
- Prompt and instruction effects: “Identical prompts” are claimed but not disclosed; no ablation of prompt phrasing or instruction tuning effects on diagnostic behavior.
- Data scale constraints: The Stage I description dataset (~5k images, 4k machine-labeled) is modest; unclear scalability to millions of diverse cases and whether gains persist with larger, noisier corpora.
- Privacy and compliance: No discussion of patient consent, de-identification, data governance, or regulatory alignment (e.g., FDA, GDPR, HIPAA) for real-world deployment.
- Release and auditability: Code, models, evaluation scripts, and datasets are not stated as public; independent verification and community benchmarking are hindered.
- Integration into clinical workflow: No user studies on acceptability, cognitive load, or how top-K candidate pools are presented to clinicians; human-in-the-loop protocols are unspecified.
- Cross-specialty generalization: Claims about “information transmission efficiency” are not tested beyond dermatology; transfer to other visually subtle medical domains remains an open question.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, given the paper’s methods and findings, along with sector links, potential tools/workflows, and feasibility notes.
- Teledermatology triage assistant (Healthcare; Software)
- Use case: In telehealth portals, automatically generate a top-K differential diagnosis list with structured captions of visual findings, and flag safety-critical boundaries (e.g., malignant vs. benign) for clinician review.
- Tools/workflows: SkinFlow API integrated into patient upload flows; clinician dashboard showing top-K diagnoses, attention maps, and Stage I captions; escalation triggers for high-risk cases.
- Assumptions/dependencies: Sufficient image quality; oversight by licensed dermatologists; taxonomy mapping for synonyms/subtypes; adherence to local privacy regulations; deployment on modest GPU servers (7B model feasible).
- Clinical intake and documentation automation (Healthcare; EHR/Health IT)
- Use case: Auto-populate structured lesion descriptions in the EHR using Stage I captioning (color, size, morphology, distribution) to standardize exams and save clinician time.
- Tools/workflows: EHR plugin that ingests images and inserts structured captions; mapping to SNOMED CT/ICD-10 terms.
- Assumptions/dependencies: Controlled vocabularies alignment; human verification; local compliance and audit trails.
- Dermatology decision support as a “second reader” (Healthcare; Clinical software)
- Use case: Provide a clinician-facing assistant that focuses attention on lesion areas, limits diffuse attention, and supplies clinically grounded near-miss reasoning (hierarchical disease lineage) rather than rigid label matching.
- Tools/workflows: PACS/image viewer plugin displaying cross-attention overlays and rank-ordered differential diagnoses; safety-boundary alerts.
- Assumptions/dependencies: Regulatory positioning as assistive decision support; continuous post-market performance monitoring.
- Education and training for clinicians and students (Healthcare; Education)
- Use case: Use structured captions plus attention visualizations to teach fine-grained dermatologic feature recognition and diagnostic hierarchies.
- Tools/workflows: Teaching modules with case libraries; interactive quizzes graded with clinically grounded metrics.
- Assumptions/dependencies: Curated datasets representative across skin tones and conditions.
- Dataset curation and label auditing using clinically grounded metrics (Academia; Industry)
- Use case: Replace exact-match-only accuracy with hierarchical, safety-aware evaluation for auditing datasets and models, ensuring “near misses” are rewarded when therapeutically consistent.
- Tools/workflows: Benchmarking dashboards applying the proposed protocol; taxonomy alignment tools (e.g., parent/subclass mapping).
- Assumptions/dependencies: Agreed-upon disease hierarchies and synonym lists; expert oversight for contentious mappings.
- Parameter-efficient vision encoder upgrades in other medical imaging tasks (Academia; Software)
- Use case: Integrate FDLinear/DVE into existing ViT backbones for pathology slides, ophthalmology fundus photos, or wound care images to reduce diffuse attention and improve lesion salience without scaling parameters.
- Tools/workflows: Drop-in FDLinear modules at specified MLP layers; training with GRPO or compatible RL frameworks.
- Assumptions/dependencies: Stable integration with current training stacks; minimal code changes; evaluation against domain-specific safety criteria.
- RL-based post-training recipe for open-vocabulary diagnosis (Academia; Software)
- Use case: Apply the two-stage RL (caption alignment; diagnosis ranking) to tasks where explicit features and implicit textures must be jointly optimized (e.g., dermatology, microscopy).
- Tools/workflows: VERL-based pipelines; group-normalized GRPO policies; reward shaping templates for structured attributes and top-K ranking.
- Assumptions/dependencies: Availability of structured caption fields and reward rubric; careful prompt engineering for LLM evaluators.
- Consumer skin-check guidance app with escalation (Daily life; Healthcare-adjacent)
- Use case: Provide non-diagnostic guidance (e.g., “likely acne vs. eczema,” “consider seeing a clinician,” “monitor changes”) with safety-aware boundaries and referral suggestions.
- Tools/workflows: Mobile app front-end; cloud inference using the 7B model; risk stratification to drive scheduling with telederm services.
- Assumptions/dependencies: Clear disclaimers (not a diagnosis); robust UX for image capture; guardrails to minimize harmful advice; fairness across skin tones.
- Internal insurance/payer triage support (Healthcare finance)
- Use case: Support referral prioritization by highlighting likely malignant/infectious cases and documenting visual evidence for pre-authorization workflows.
- Tools/workflows: Claims triage dashboard; reports with structured captions and risk flags.
- Assumptions/dependencies: Policy compliance; physician-in-the-loop; auditability and fairness checks.
- Quality assurance in annotation via structured caption pipeline (Academia; Industry)
- Use case: Use LLM-assisted, RL-rewarded caption generation and expert refinement to scale annotation of dermatology datasets with consistent attribute fields.
- Tools/workflows: Semi-automated captioning with acceptance thresholds (attribute scores ≥6/10); human-in-the-loop revision.
- Assumptions/dependencies: Reliable LLM evaluators; governance for iterative corrections; inter-annotator agreement processes.
Long-Term Applications
These opportunities require further research, scaling, clinical validation, or development before broad deployment.
- Regulatory-grade diagnostic assistant with RCT validation (Healthcare; Policy)
- Vision: Pursue clinical trials to validate safety, efficacy, and fairness; obtain regulatory clearance (e.g., FDA/CE) for specific indications.
- Dependencies: Prospective studies; performance across diverse skin tones and demographics; post-market surveillance; robust failure-mode analyses.
- Open-vocabulary rare disease detection at scale (Healthcare; Academia)
- Vision: Expand to thousands of conditions, long-tail and rare diseases, leveraging continual learning and hierarchical taxonomies for generalization.
- Dependencies: Large, diverse datasets; expert-curated ontologies; dynamic synonym/subtype handling; robust handling of ambiguity.
- Multimodal fusion with dermoscopy, histopathology, and patient history (Healthcare; Software)
- Vision: Combine smartphone photography with dermoscopy images, biopsy histology, and clinical notes to improve precision and reduce false positives/negatives.
- Dependencies: Data integration standards; privacy-preserving pipelines; multimodal RL reward design; clinical workflow integration.
- Federated learning across hospitals for privacy-preserving improvement (Healthcare; Software)
- Vision: Train SkinFlow variants across distributed institutions without centralizing patient images, improving robustness while protecting privacy.
- Dependencies: Federated infrastructure; secure aggregation; harmonized taxonomies and annotation protocols; legal agreements.
- Real-time, on-device inference for population screening (Daily life; Hardware/Software)
- Vision: Compress and quantize the 7B model and DVE to run offline on smartphones or edge devices for community screening programs and remote areas.
- Dependencies: Model compression/distillation; hardware acceleration; battery and latency constraints; offline safety guardrails.
- Safety-aware evaluation tooling for regulators and hospital QA (Policy; Healthcare)
- Vision: Standardize clinically grounded metrics and dashboards to audit models for safety-critical boundary crossing and treatment consistency.
- Dependencies: Endorsed standards; shared disease taxonomies; clinician committees; traceable audit logs.
- Cross-domain extension beyond dermatology (Academia; Industry)
- Vision: Apply the information-transmission lens, DVE, and staged RL to radiology, ophthalmology, wound assessment, and dental imaging for improved precision without parameter bloat.
- Dependencies: Domain-specific rewards and hierarchies; benchmark creation; careful generalization testing.
- Automated coding to billing pipelines (Healthcare finance; Health IT)
- Vision: Map structured captions and diagnoses to ICD-10/SNOMED for streamlined documentation and billing with error checking.
- Dependencies: High precision in code mapping; compliance audits; clinician oversight; handling ambiguous cases.
- Public health surveillance and early-warning networks (Policy; Public health)
- Vision: Aggregate anonymized, safety-aware outputs to detect spikes in infectious or environmentally triggered skin conditions (e.g., outbreaks, pollution-related dermatitis).
- Dependencies: Privacy-preserving aggregation; bias mitigation; robust geospatial sampling; cross-agency coordination.
- Personalized follow-up and monitoring (Healthcare; Daily life)
- Vision: Track lesion changes over time with structured captions, alerting users and clinicians to concerning evolution (e.g., asymmetry, border changes, color variegation).
- Dependencies: Longitudinal data capture; calibration for camera differences; adherence and engagement; clinically validated thresholds.
Cross-cutting assumptions and dependencies
- Image quality and capture variability: Performance hinges on clear images; standardized guidance and capture UX are necessary.
- Fairness across skin tones and demographics: Requires diverse training data and targeted audits to avoid performance disparities.
- Reliance on LLM-based evaluators for rewards: Reward quality depends on evaluator reliability; human validation remains important.
- Taxonomy and synonym mapping: Open-vocabulary diagnosis needs robust, consensus hierarchies and synonym handling.
- Regulatory and ethical compliance: Privacy, security, and clinician oversight are mandatory for clinical deployments.
- Compute and deployment constraints: Although 7B is relatively efficient, compression/quantization may be needed for edge/on-device use.
Glossary
- AdamW optimizer: A variant of the Adam optimizer that decouples weight decay from the gradient update for better regularization. "The AdamW optimizer was employed with a learning rate of (), and a cosine warmup strategy was used for scheduling."
- Atopic dermatitis: A chronic inflammatory skin disease commonly referred to as eczema. "Atopic dermatitis â Eczema"
- Attention attribution analysis: A technique to interpret model focus by analyzing how attention weights contribute to outputs. "As evidenced by our attention attribution analysis, DVE allows the model to 'unfold' complex visual manifolds, adaptively suppressing background redundancy and amplifying the signal-to-noise ratio of diagnostic lesions."
- Capsule networks (CapsNet): Neural architectures that represent hierarchical relationships between parts and wholes via vector “capsules.” "Capsule networks (CapsNet) have also been explored to enhance spatial hierarchical representation, enabling multi-class skin disease recognition and fine-grained classification"
- Clinically grounded evaluation protocol: An assessment method that considers disease hierarchies, therapeutic relevance, and safety rather than exact label matching. "we propose a clinically grounded evaluation protocol that prioritizes diagnostic safety and hierarchical relevance over rigid label matching."
- Cover's Theorem: A result in pattern recognition stating that nonlinearly separable patterns in low dimensions can become linearly separable in higher-dimensional spaces. "According to {Cover's Theorem}~\cite{cover2006geometrical} on the geometrical separation of patterns"
- Cross-attention maps: Visualizations of attention weights from text tokens to image tokens in multimodal models. "we visualize the cross-attention maps corresponding to the final diagnostic token"
- Derm1M: A large-scale dermatology dataset emphasizing hierarchical structure among skin diseases. "Derm1M \cite{yan2025derm1m} further highlights the strong hierarchical structure among skin diseases"
- Dermoscopic images: High-magnification skin images captured by specialized devices for clinical analysis. "Early studies on automated skin disease diagnosis mainly relied on dermoscopic images, which are captured by professional devices"
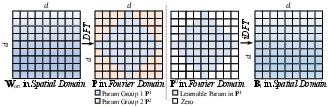
- Discrete Fourier Transform (DFT): A transform that converts signals or matrices from the spatial/time domain to the frequency domain. "to the Fourier domain via the Discrete Fourier Transform (DFT)."
- Dynamic Visual Encoding (DVE): A module that adaptively boosts salient visual features and suppresses noise for better diagnostic representation. "we design the Dynamic Visual Encoding (DVE) module~\cite{chen2025frequency}."
- Entropy collapse: A training pathology where model outputs become overconfident and lack diversity. "reinforcement learning mitigates the problem of entropy collapse and achieves better generalization"
- Erythema: Redness of the skin due to capillary dilation, often a diagnostic sign. "(texture, erythema, scale, ulcers)"
- FDLinear (Frequency Dynamic Linear): A dynamic linear operator that composes weights from frequency-partitioned bases to expand effective capacity without increasing physical width. "we introduce {FDLinear (Frequency Dynamic Linear)}~\cite{chen2025frequency}, a parameter-efficient dynamic operator."
- Fitzpatrick17k: A public dermatology benchmark dataset of clinical skin images. "The first benchmark is derived from the publicly available Fitzpatrick17k dataset."
- FLOPs: Floating-point operations, a measure of computational cost. "would cause computational complexity (FLOPs) to skyrocket"
- Frequency Disjoint Partitioning: A method of partitioning the frequency spectrum into non-overlapping groups to build specialized weight bases. "These bases are not randomly initialized but are constructed via {Frequency Disjoint Partitioning}."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that normalizes rewards within sampled groups and removes the need for a critic. "Group Relative Policy Optimization (GRPO) \cite{guo2025deepseek} is an efficient RL algorithm that eliminates the need for a separate critic model."
- Herpes zoster: A viral skin disease also known as shingles. "Herpes zoster â¡ Shingles"
- inverse DFT (iDFT): The inverse transform that reconstructs spatial-domain data from frequency-domain representations. "Finally, an inverse DFT (iDFT) reconstructs the spatial basis matrix."
- KL divergence (Kullback–Leibler divergence): A measure of how one probability distribution diverges from a reference distribution. "with a KL penalty to a reference policy:"
- Large Vision-LLMs (LVLMs): Foundation models that jointly process visual and textual inputs at large scale. "General-purpose Large Vision-LLMs (LVLMs), despite their massive scale, often falter in dermatology"
- Malignancy: The property of being cancerous and potentially harmful, crossing a critical clinical boundary. "(e.g., malignancy)."
- Mixture of Experts (MoE): An architecture that routes inputs to different expert subnetworks to scale capacity. "associated with MoE (Mixture of Experts) architectures."
- Multimodal LLMs (MLLMs): Models combining vision and language to reason over both modalities. "While existing Multimodal LLMs (MLLMs) achieve great succuss"
- Open-vocabulary dermatological diagnosis: Recognition that is not restricted to a fixed label set, enabling free-form disease naming. "Our framework naturally supports open-vocabulary dermatological diagnosis"
- Recoverable information: The portion of visual information that can be encoded and decoded into clinically useful semantics. "identifying the 'recoverable information' bottleneck."
- Reinforcement learning (RL): A learning paradigm optimizing actions via reward signals rather than supervised labels. "Training is again conducted under an RL framework rather than SFT"
- ResUNet++: A U-Net variant with residual and enhanced blocks for improved medical image segmentation. "U-Net and its variants (e.g., ResUNet++) have been widely used"
- RLVR: An outcome-driven reinforcement learning approach that leverages verifiable feedback instead of explicit reasoning traces. "RLVR \cite{guo2025deepseek,team2025kimi} relies solely on outcome-driven feedback, facilitating scalable reinforcement learning across extensive task datasets."
- Signal-to-noise ratio (SNR): A measure comparing signal strength to background noise. "amplifying the signal-to-noise ratio of diagnostic lesions."
- Supervised fine-tuning (SFT): Post-training with labeled examples to adapt a model to specific tasks. "While supervised fine-tuning (SFT) remains the mainstream post-training paradigm,"
- U-Net: A convolutional neural network architecture for image segmentation with encoder–decoder and skip connections. "U-Net and its variants (e.g., ResUNet++) have been widely used"
- VERL framework: A software framework used to implement reinforcement learning pipelines for LLMs. "The entire RL pipeline was implemented using the VERL framework \cite{sheng2024hybridflow}."
- Virtual Width Expansion: The idea of emulating larger model width through dynamic basis composition without physically increasing parameters. "This empirically validates the 'Virtual Width Expansion' hypothesis."
- Virtual-Width Dynamic Vision Encoder (DVE): A vision encoder that achieves high effective capacity via virtual width rather than physical scaling. "Our approach utilizes a Virtual-Width Dynamic Vision Encoder (DVE) to 'unfold' complex pathological manifolds"
- Vision Transformers: Transformer-based architectures for vision that process images as token sequences. "Standard Vision Transformers rely on static linear layers for feature mixing."
Collections
Sign up for free to add this paper to one or more collections.