- The paper presents DPWriter, a reinforcement learning framework using semi-structured planning and diverse branching to enhance creative writing without compromising quality.
- It decomposes generation into high-level planning, plan-conditioned reasoning, and response synthesis to better control output diversity and mitigate mode collapse.
- Empirical evaluations demonstrate up to 15% improvement in embedding-based diversity and robust quality gains over existing RL-based methods.
Reinforcement Learning with Diverse Planning Branching for Enhanced Creative Writing
Reinforcement learning (RL) has demonstrated efficacy in aligning and sharpening the behavior of LLMs, but existing RL-based fine-tuning frameworks often induce a substantial collapse in generative diversity, particularly in open-ended domains such as creative writing. This diversity loss arises from a lack of explicit mechanisms encouraging exploration of diverse solution paths and a focus on single-path sample efficiency. As RL advances, it becomes critical to simultaneously optimize both the quality and diversity of model outputs, avoiding mode collapse and fostering richer model behavior.
The DPWriter framework introduces a novel reinforcement learning paradigm grounded on a semi-structured long Chain-of-Thought (CoT) generation scaffold. This paradigm explicitly injects a global planning stage prior to reasoning and response phases, structuring the generation process into: (1) high-level plan generation, (2) plan-conditioned CoT reasoning, and (3) final plan-/CoT-conditioned response synthesis. This explicit decomposition allows direct interventions to guide diversity during plan generation and opens new avenues for controlled exploration—a sharp contrast to the implicit, monolithic CoT reasoning used in prior RL-based LLMs.
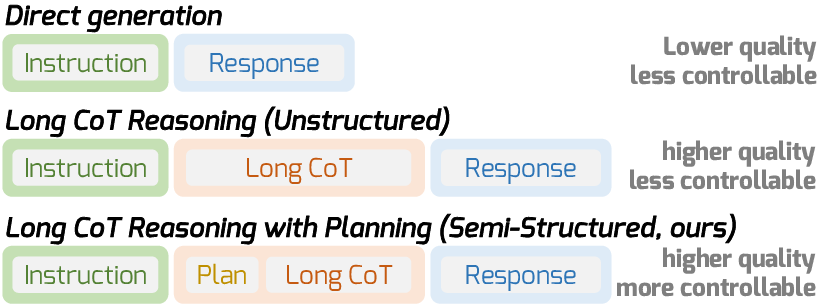
Figure 1: Overview of generation paradigms, where semi-structured reasoning inserts a dedicated planning phase for global, high-level guidance prior to reasoning and response.
Semi-structured Long Chain-of-Thought and Data Construction
DPWriter's training relies on a semi-structured long CoT format, constructed in two steps: First, a multi-aspect plan is synthesized for each instruction/response pair, decomposed into aspects such as goal/audience, information/perspective, structure/logic, language/style, and presentation/experience, marked with explicit tokens. Second, the original reasoning trajectory is revised for plan-consistency, ensuring the ensuing CoT explicitly aligns with all elements of the plan. This results in instruction-plan-CoT-response quadruples that serve as training data.

Figure 2: Conversion of raw CoT data into semi-structured data with explicit planning aspects incorporated.
Diverse Planning Branching: RL Mechanism for Enhanced Trajectory Diversity
The central method, Diverse Planning Branching (DPB), restructures RL rollout during plan generation by recursively branching out multiple continuations from each candidate at every planning segment. The branching process, control points, and selection are explicitly coordinated using diversity metrics (n-gram-based or semantic embedding-based), resulting in a candidate pool from which the most diverse group is advanced to the next planning segment. This structured exploration is not limited to stochastic token-level forking (as in prior entropy-based methods), but is governed by interpretable plan segments that afford fine-grained controllability.
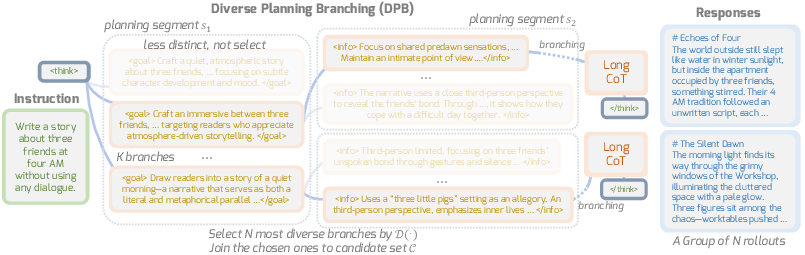
Figure 3: Diverse Planning Branching overview—multiple candidates are expanded at each planning segment, and the most diverse set is selected for subsequent reasoning and response synthesis.
The diversity of candidates across branches is quantified by both lexical (n-gram distinctness) and semantic (embedding dissimilarity) metrics, preventing redundancy and ensuring exploration of orthogonal content spaces.
Diversity-Aware Group Rewarding
DPWriter further introduces group-wise diversity contribution rewards in RL. Each response in a group rollout is rewarded not only for quality (as measured by an RLAIF reward model trained on human preference data) but also according to its unique contribution to group-level diversity. The diversity reward for a candidate reflects the uniqueness of its content relative to peer responses. Critically, the diversity reward is only activated for responses passing a required quality threshold, ensuring that the pursuit of diversity does not incentivize content that is low in quality.
Through a convex combination of quality and diversity rewards with an adjustable coefficient, the method explicitly guides policy optimization towards diverse, high-quality generation trajectories. The DPB mechanism and group-aware rewards are synergistic in promoting robust diversity without quality collapse.
Empirical Evaluation and Quantitative Results
DPWriter was evaluated on multiple creative writing benchmarks, including WritingBench, Creative Writing v3 (EQ-Bench), ArenaHard v2.0, and NoveltyBench. Across both Qwen3-4B and Llama-3.2-3B backbones, DPWriter achieved consistent improvements in diversity metrics (both lexical and semantic) compared to baselines such as GRPO, GRPO-Unlikeliness, Darling, and GAPO.
Notably, on WritingBench using the Qwen3-4B backbone, DPWriter improves embedding-based diversity by 15% and EAD (n-gram) diversity by 9.9% relative to GRPO, while also attaining the best mean quality score. NoveltyBench evaluations further demonstrate superior distinctness (i.e., novel equivalence classes of outputs) compared to all baselines.
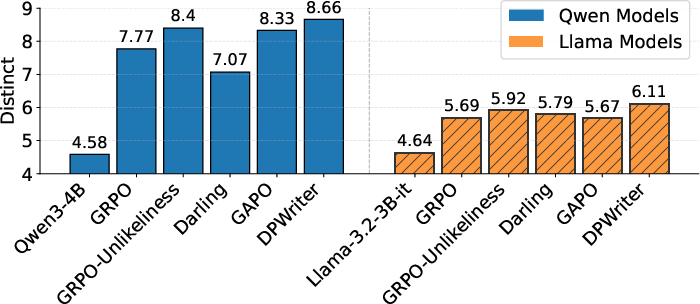
Figure 4: DPWriter achieves superior Distinct scores over baselines on NoveltyBench, indicating improved output diversity.
Ablation studies dissect the contributions of SFT with planning, DPB branching, and the diversity reward. Full-system ablations reveal that removing the diversity reward induces the largest loss in diversity metrics, and performance drops monotonically with the removal of planning and branching elements.
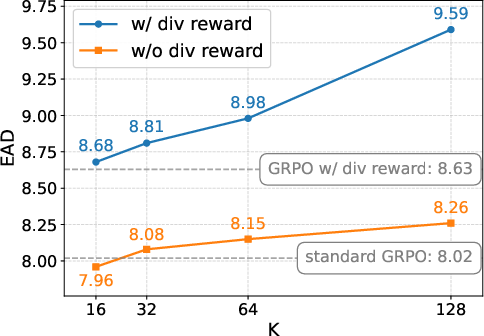
Figure 5: Analysis of synergy between branching factor and diversity reward—diversity metrics increase with branching and are further boosted by the reward signal.
Qualitative case studies on NoveltyBench expose that DPWriter produces a broader spectrum of creative responses for a fixed prompt, whereas competitive RL methods yield significant answer redundancy or concentration (mode collapse).

Figure 6: Case study—DPWriter generates unique responses per prompt, in contrast to GRPO’s redundancy; same answers are highlighted by color.
Theoretical and Practical Implications
From a theoretical standpoint, DPWriter's explicit plan-level branching mechanism diverges from standard RLHF or single-path RL in LLMs, decoupling the optimization trajectory from the output’s surface-level entropy and ensuring diversity is injected at the abstract, high-level generation stages. This enables the exploration of semantically distinct themes in open-ended writing.
Practically, DPWriter is directly applicable to creative writing systems and other domains valuing diversity (e.g., ideation support, brainstorming facilitation, or data augmentation for downstream tasks). The method sidesteps the well-documented diversity-quality tradeoff: empirical results show robust diversity gains without any degradation in measured quality. Key limitations relate to increased compute due to combinatorial plan branching and the assumption that plan structure is universally relevant for all forms of creative writing; future research might investigate adaptive plan structures and scalable branching selection.
Conclusion
DPWriter provides a technically rigorous RL-based architecture for open-ended language generation, introducing explicit semi-structured planning, diverse branching, and group-aware diversity rewards to systematically address RL-induced diversity collapse. Empirical evidence robustly supports that this approach advances both response diversity and quality over strong modern RL baselines. This paradigm offers immediate utility for applications demanding diversity and lays the groundwork for further exploration of transparent, controllable diversity mechanisms in LLM-based generation.
Reference: "DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing" (2601.09609)