- The paper introduces MATTRL, a framework that leverages experience-augmented, update-free adaptation to enhance multi-agent reasoning without gradient-based retraining.
- It details a three-stage process—team formation, experience-augmented deliberation, and convergence synthesis—to dynamically improve inference precision across domains.
- Empirical evaluations show significant performance gains in medicine, mathematics, and education, with Difference Rewards proving most effective for precise credit assignment.
Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
Introduction and Motivation
Collaborative LLM-driven multi-agent systems are demonstrating marked advances in complex, high-stakes reasoning tasks across diverse domains such as medicine, mathematics, and education. While ensemble-based, role-specialized collaboration augments robustness through diversity and cross-checking, current multi-agent reinforcement learning (MARL) setups suffer from non-stationary training dynamics, significant sample/budget demands, and brittle generalization under distribution shift. These limitations stem primarily from difficulties in stable credit assignment, sparse scalar reward propagation, and the tendency of fine-tuned, domain-adapted agents to lose generality.
The MATTRL (Multi-Agent Test-Time Reinforcement Learning) framework directly addresses these issues by introducing a black-box, update-free adaptation protocol. Rather than gradient-based weight updates, MATTRL leverages structured, role- and context-sensitive textual experience at inference for retrieval-augmented, experience-conditioned multi-agent collaboration. This method allows fixed-policy expert teams to rapidly incorporate high-salience reasoning priors distilled from previous deliberations without sacrificing generality or stability.
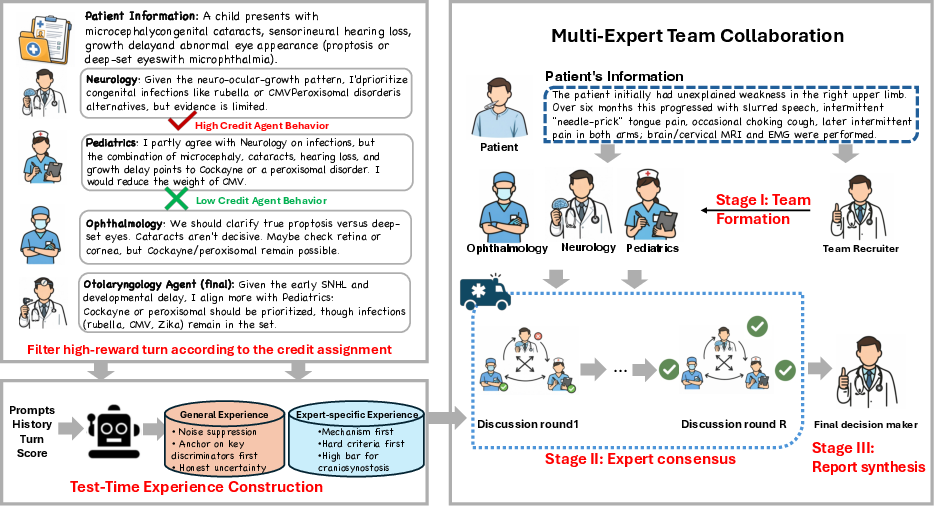
Figure 1: MATTRL framework overview using the medical diagnosis setting as the running example; the methodology is extensible to any multi-specialist reasoning process.
Methodology: Experience-Augmented Multi-Agent Collaboration
MATTRL operationalizes test-time adaptation through three main stages:
- Team Formation: The coordinator LLM agent selects a domain-specialized cohort from a fixed expert pool, based on task content and role requirements.
- Experience-Augmented Deliberation: In structured, synchronized multi-turn rounds, each non-converged specialist retrieves context-relevant experience entries—distilled, high-reward snippets from prior collaborations—through a dense retriever. Each agent revises their hypothesis or solution, with incremental updates aggregated via a meeting operator and broadcast for synchronization.
- Convergence and Report Synthesis: Once all specialists converge (or turn bounds are met), the coordinator summarizes cumulative evidence to reach the final decision.
Crucial to MATTRL is the construction and utilization of a test-time experience pool E. Each turn of historic, multi-agent transcripts is scored via an LLM judge on axes such as correctness, information gain, relevance, and clarity, then fused with decay-weighted terminal rewards and group-to-agent credit assignment. High-value utterances are distilled into compact, structured experience entries, indexed for retrieval based on present context and role.
Credit Assignment Strategies
Group attribution for collaborative success is non-trivial. MATTRL systematically explores:
- Naive Averaging: Equal division of reward at each turn.
- Difference Rewards: Agent-specific difference via team objective knock-out (counterfactual with/without agent i).
- Shapley-Style Approximations: Coalition-permutation sampling for marginal contribution estimates.
Empirically, Difference Rewards provides superior strict-precision (Hit@1/3) credit mapping, while Naive and Shapley degrade under conditions of high redundancy or peer-alignment bias. Difference Rewards sharpens credit “peaks” by isolating decisive inference, thus surfacing turn utterances critical for downstream experience reuse.





Figure 3: General and disease-specific experience snippets distilled as reusable guidance, illustrating the range from cross-cutting process discipline (e.g., noise suppression, prioritization of key discriminators) to fine-grained, differential diagnosis rules.
Experimental Evaluation
Benchmarks and Protocols
MATTRL is evaluated on three frontier tasks:
- Medicine: Rare disease differential diagnosis (RareBench Task 4), where the framework orchestrates patient-centered, multi-specialist team consultations (421 diseases; 2185 cases).
- Mathematics: Expert-level math problem solving (Humanity’s Last Exam), with collaborative, multi-specialist deliberation and structured peer review.
- Education: Instructional effectiveness (SuperGPQA), measuring multi-stage learning gains in complex graduate-level multi-choice questions via pre/post-test student LLMs and multi-specialist teacher teams.
Baseline systems include single-agent chain-of-thought (CoT), standard role-based multi-agent deliberation without experience, and advanced multi-agent medical reasoning frameworks (e.g., MDAgents, RareAgents).
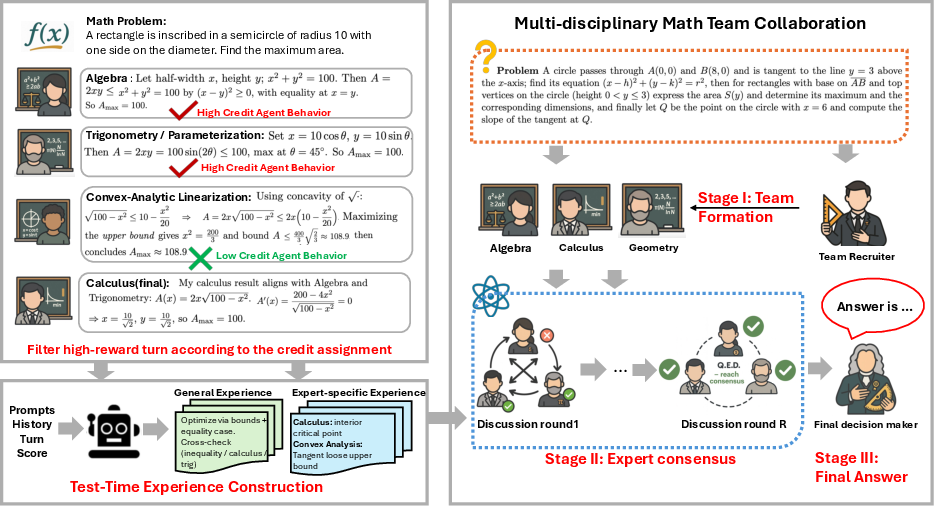
Figure 2: MATTRL applied to mathematical collaboration. Specialized agents propose, critique, and synthesize multi-turn solutions, with retrieval-augmented experience stabilizing consensus.
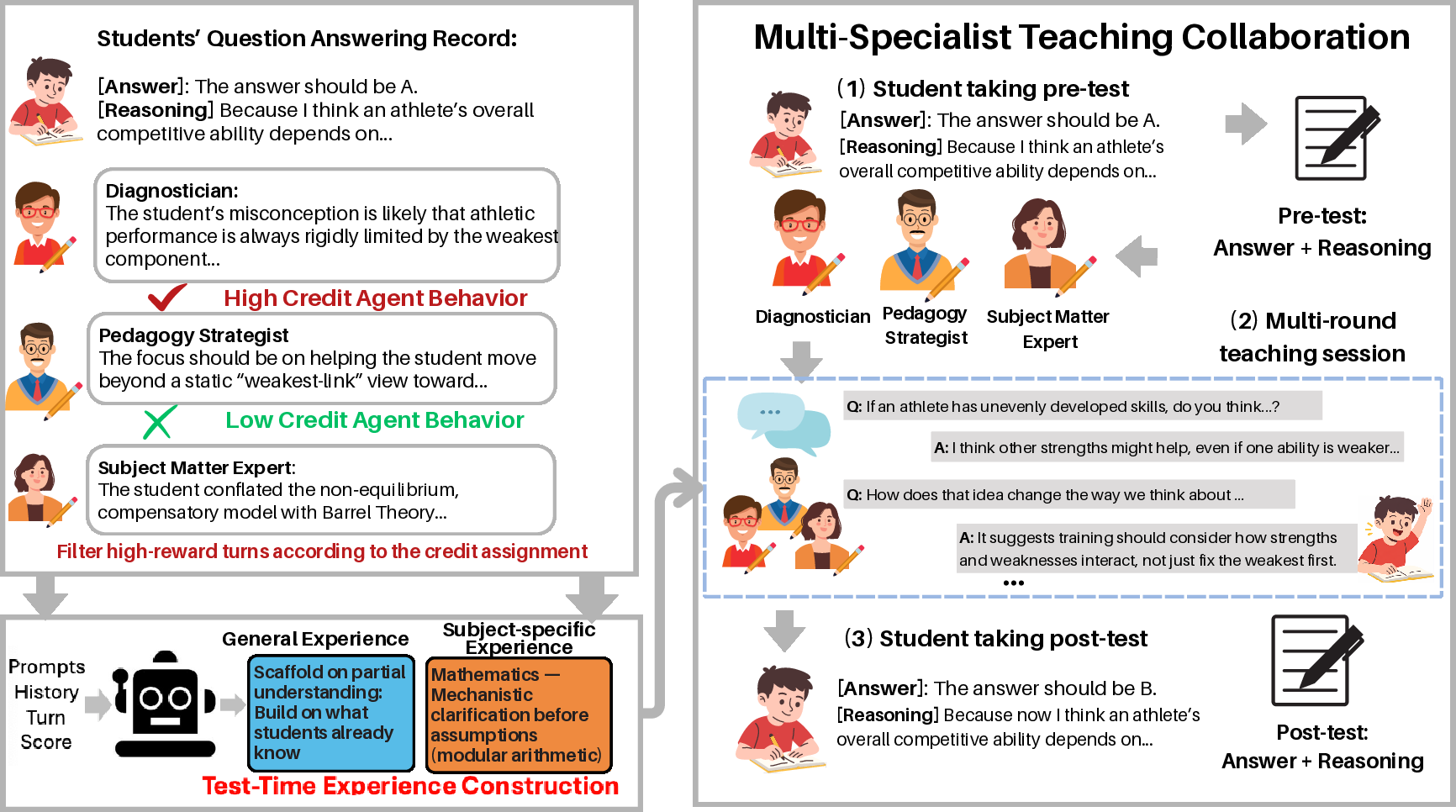
Figure 4: MATTRL in a pedagogical context: collaborative teacher agents leverage both instructional best-practice and subject-specific teaching experiences to diagnose and address learner misconceptions.
Results
- Medicine (RareBench): MATTRL achieves state-of-the-art, with Hit@1 of 0.39, Hit@3 of 0.51, Hit@10 of 0.75, and MRR of 0.51—outperforming role-based multi-agent baselines and single-agent reasoning by 3.67% and 8.67% mean improvements, respectively.
- Mathematics (HLE): Exact-match solve rate advances from 0.27 (single-agent) to 0.33 (multi-agent), and finally to 0.36 with MATTRL test-time experience. The experience contribution is significant relative to parallelized deliberation alone.
- Education (SuperGPQA): Learning gains (ΔAcc) progress from 0.16 (single-agent) to 0.29 (multi-agent) to 0.33 (MATTRL), with MATTRL nearly doubling the effect size of single-agent instructors.
Ablations reveal that structured experience, not merely increased context, drives performance: naive few-shot augmentation fails to replicate MATTRL’s gains, especially on broad-recall metrics (Hit@10).
Analysis: Credit Schemes, Team Size, and Adaptivity
Difference Rewards dominate for tight-precision use cases, since counterfactual knockout targets causally influential utterances, mitigating free-riding noise and redundancy dilution evident in naive and Shapley schemes. Shapley-style allocation, while fairer and more robust for peer consensus, exhibits higher variance and fails to prioritize critical inference steps, harming strict precision (Hit@1/3).
Team scaling experiments show optimality for small expert teams: performance in Hit@1 peaks near 3 agents; larger groups enhance broader recall (Hit@10) but introduce consensus challenges and opinion divergence. Thus, MATTRL supports adaptive routing: a classifier selects between single-agent, MATTRL, or hybrid pipelines based on task structure and evidence integration needs, yielding further gains (e.g., achieving 10% improvement over single-agent and 5.5% over fixed MATTRL in rare-disease diagnosis).



Figure 5: Test-time instructional experience guiding cross-disciplinary teacher teams, illustrating both domain-general (e.g., scaffolding, misconception surfacing) and subject-specific strategies at retrieval.
Practical and Theoretical Implications
MATTRL demonstrates that update-free, experience-augmented adaptation enables robust, distribution-shift-resilient multi-agent reasoning without retraining. Dense, context-aware retrieval of distilled experience outperforms both naive prompt expansion and static multi-agent deliberation by stabilizing consensus formation and providing precise, actionable priors. Group-to-agent credit assignment, especially via Difference Rewards, is essential for experience pool quality, striking a trade-off between computation, variance, and attribution sharpness.
Practically, MATTRL’s modularity makes it deployable across any LLM-driven multi-agent reasoning context, supporting dynamic team assembly, explainable rollouts, and incremental experience accumulation without risking catastrophic forgetting or overfitting through continuous training. Its test-time inference protocol is compatible with future LLM releases, and with judicious experience management (e.g., recency-weighted curation), can adapt at runtime to ongoing distributional shift.
Future Directions
Key outstanding areas include: (i) dynamic budget and rollout control to cap inference cost and minimize deliberation latency, (ii) structured experience lifecycle management (e.g., deduplication, anomaly screening, staleness filtering) to avoid drift in the experience pool, and (iii) further extension of experience structure to support stratified retrieval by agent, role, and context. Integration with neural execution monitoring and team-level uncertainty calibration are also promising avenues.
Conclusion
MATTRL establishes a new paradigm for robust, collaborative multi-agent LLM reasoning under distribution shift. Its combination of multi-expert, experience-informed adaptation, dense retrieval, and rigorous credit assignment results in empirically validated gains across complex benchmarks—without gradient updates, domain-specific finetuning, or model retraining. As LLM deployment moves toward real-world, high-stakes, evolving environments, MATTRL provides a scalable, interpretable foundation for safe, adaptive, and high-precision multi-agent reasoning.