- The paper presents a novel M-GRPO framework that optimizes multi-agent training through hierarchical credit assignment and specialized role delegation.
- It employs batch alignment and group-relative advantages to normalize heterogeneous rollout frequencies and strengthen policy gradient updates.
- Experimental results show that co-training with trajectory synchronization significantly outperforms traditional main-only configurations on benchmark tasks.
Multi-Agent Deep Research: Training Multi-Agent Systems with M-GRPO
Introduction
The paper introduces a novel framework called Multi-Agent Group Relative Policy Optimization (M-GRPO) designed for training multi-agent systems utilizing LLMs. The approach addresses the challenges intrinsic to vertical multi-agent systems, where distinct LLMs are integrated for separate agents specialized in different roles. This methodology eschews conventional unified training and instead leverages a hierarchical structure intended to maintain hierarchical credit assignment and trajectory alignment. The main agent acts as a planner delegating roles to sub-agents specialized in multi-turn tool enactments.
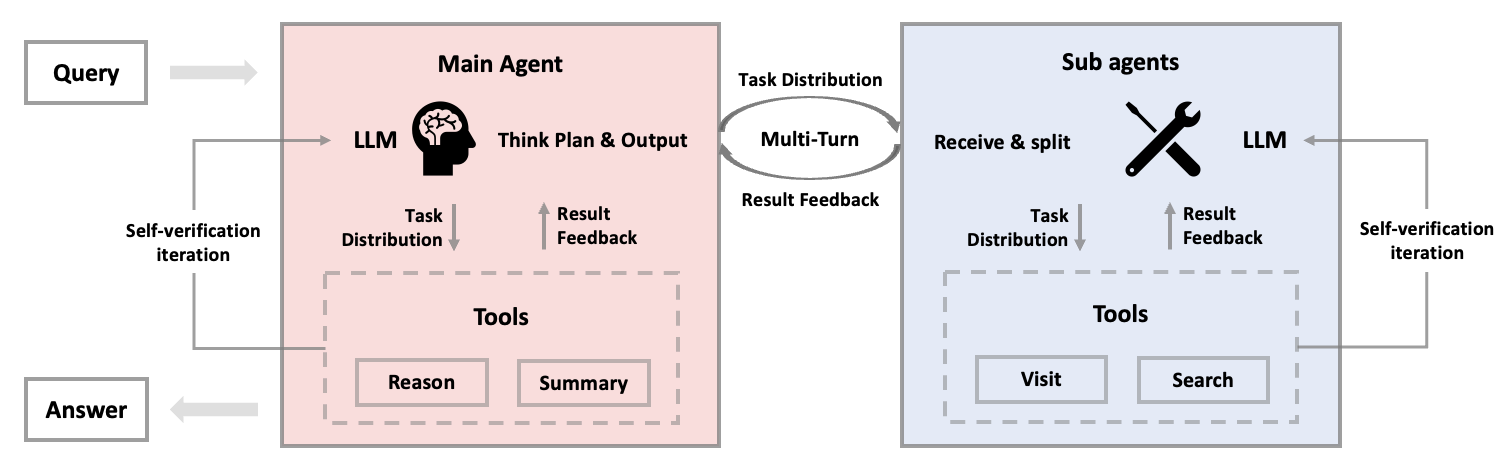
Figure 1: System workflow with coordinated main and sub-agents.
Methodology
M-GRPO Framework: Central to this approach is M-GRPO, a hierarchical policy optimization mechanism that respects inter-agent role distinctions and adaptation. It resolves the imbalance between leader and subordinate agents in terms of rollout frequencies by aligning heterogeneous trajectories through fixed-size batch generation despite varying sub-agent invocation rates.
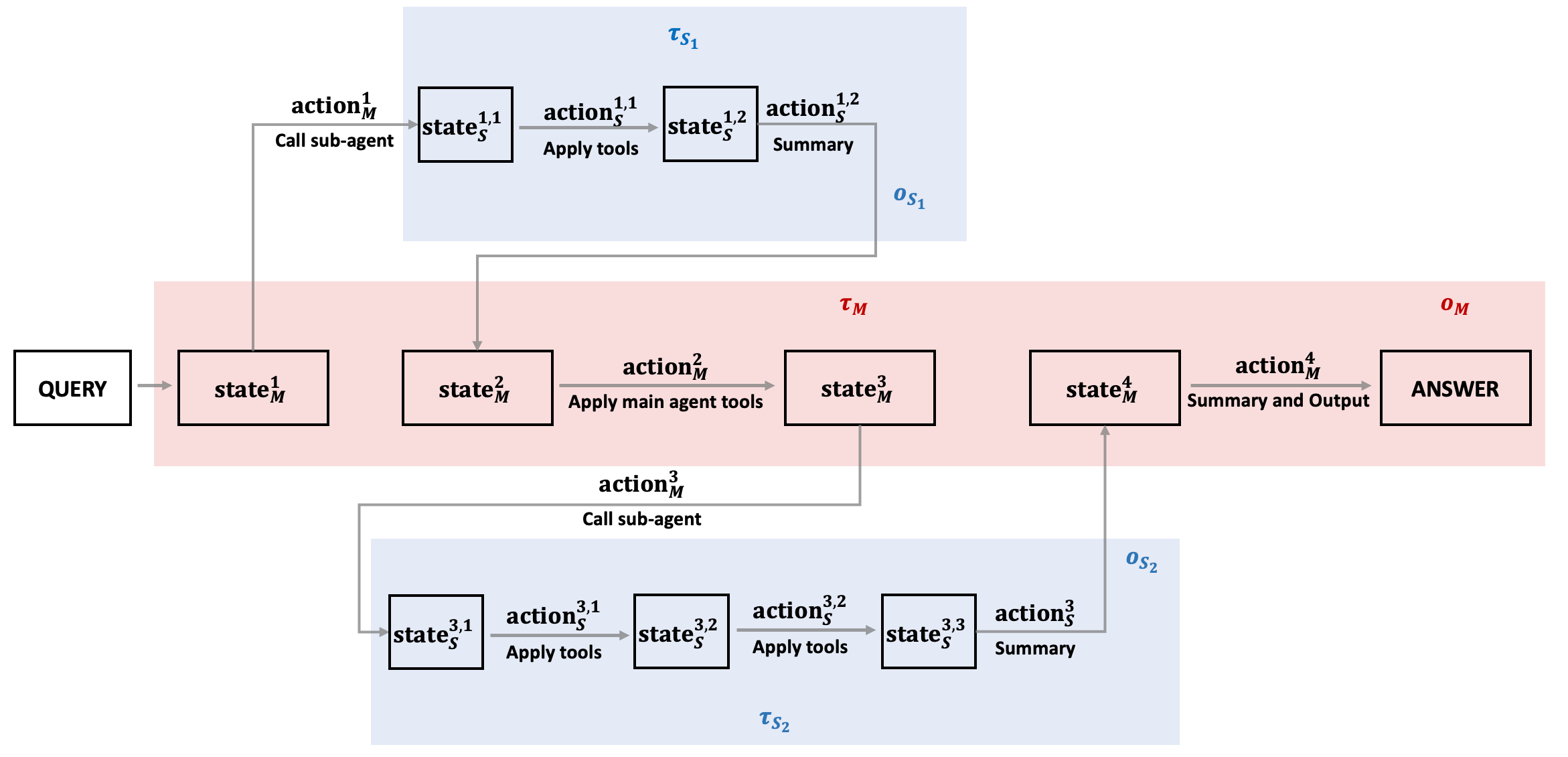
Figure 2: One rollout with nested $\mathcal{M\!\to\!\mathcal{S}$ interactions.
Policy Advantage Mechanism: M-GRPO employs group-relative advantages to ensure hierarchical credit assignment, supporting both the main agent's and sub-agent's optimization independently and collectively. The design accommodates decentralized architecture while providing scalability without cross-server backpropagation, by sharing minimal statistics across agent servers.
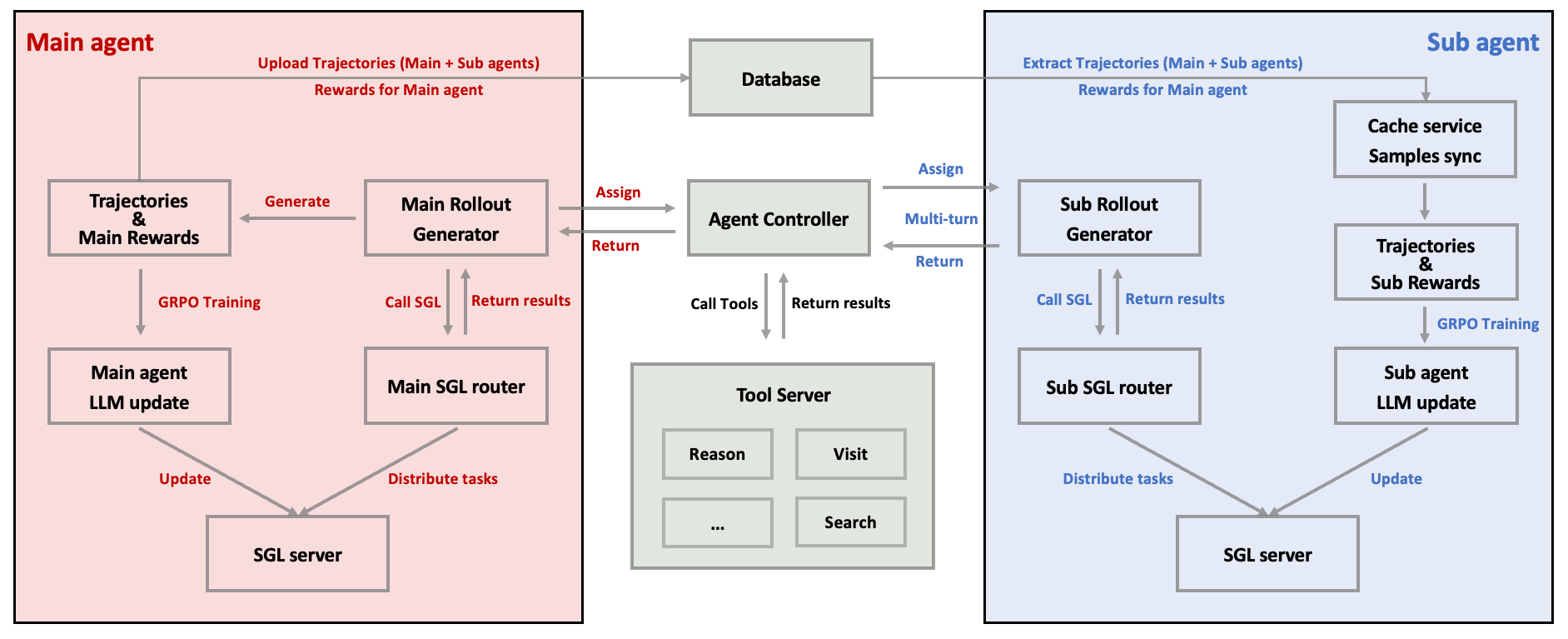
Figure 3: Workflow of the decoupled two-agent architecture with M-GRPO.
Trajectory Alignment: Variable sub-agent invocations are normalized by adopting a batch alignment scheme that standardizes invocation counts across rollouts, enabling efficient policy gradient updates. This practice aids in maintaining on-policy dynamics crucial for training reliability and efficacy.
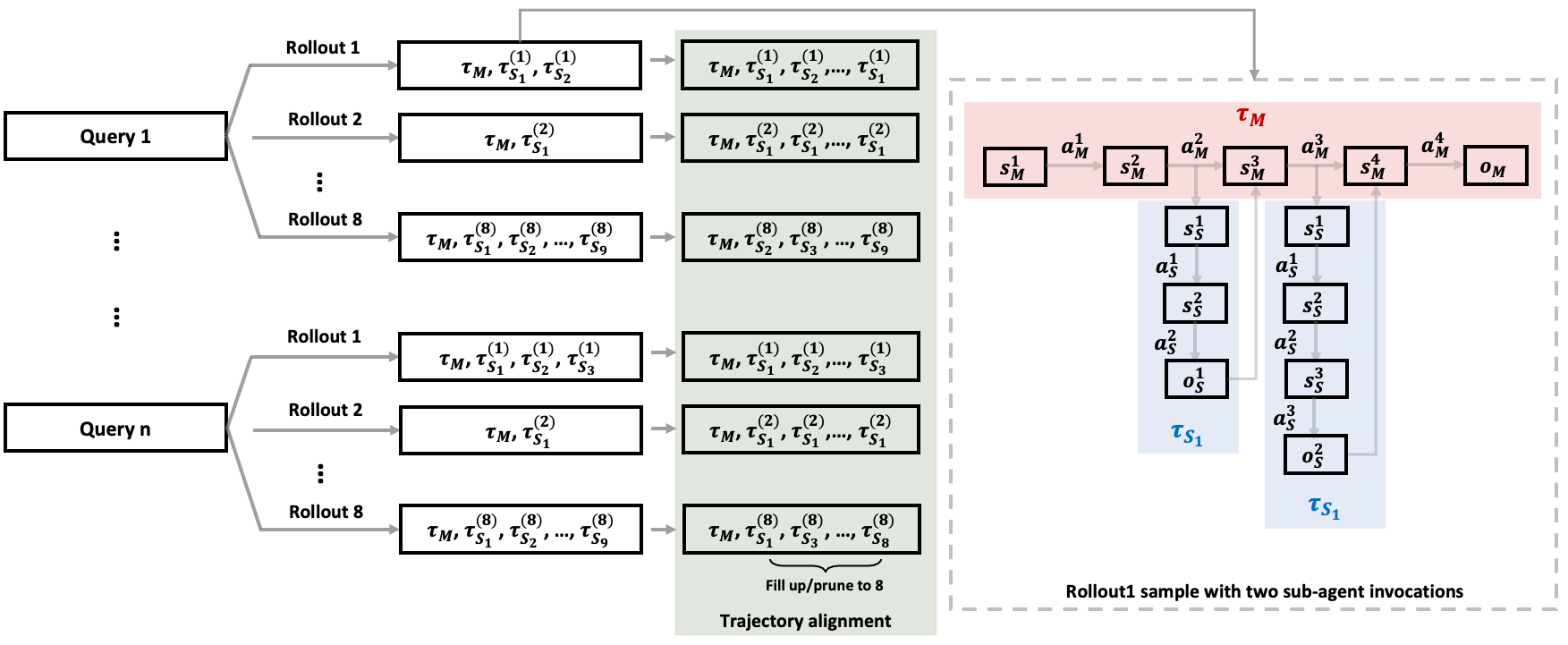
Figure 4: Trajectory alignment for batch training with variable sub-agent invocations.
Experimental Results
Two-Stage Training Curriculum: The experimentation commences with a two-stage curriculum, fostering both format learning and collaborative capability in the system. Stage 1 establishes foundational format competencies with simple dataset training, demonstrating substantial rewards acquisition.
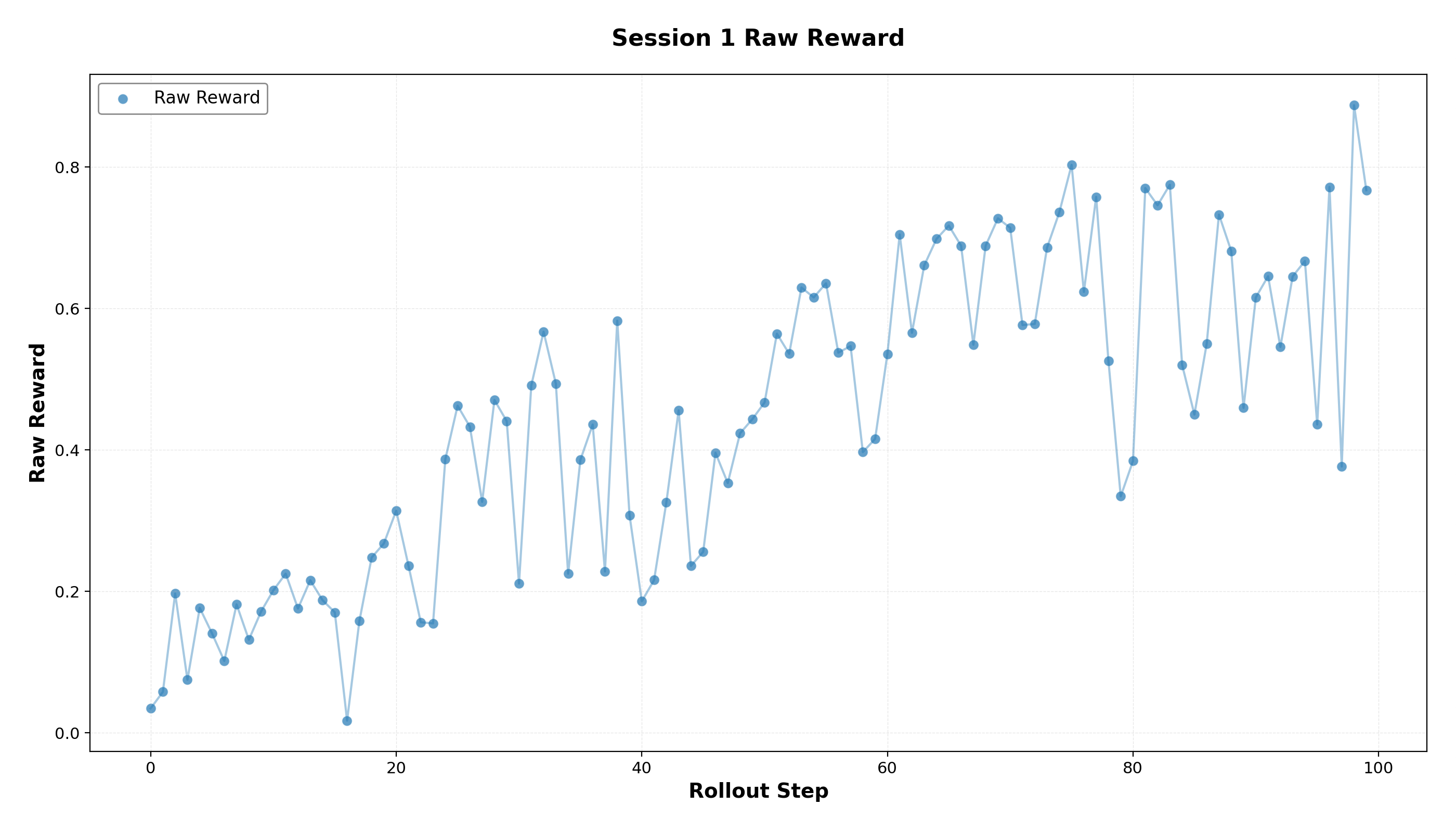
Figure 5: Reward curve during Stage 1 RL training on simple data.
Benchmark Evaluation: During Stage 2, co-training of agent systems, evaluated over benchmarks such as GAIA, XBench-DeepSearch, and WebWalkerQA, consistently outperformed the single-agent and main-only configurations, affirming the efficacy of joint optimization approaches in real-world task scenarios.
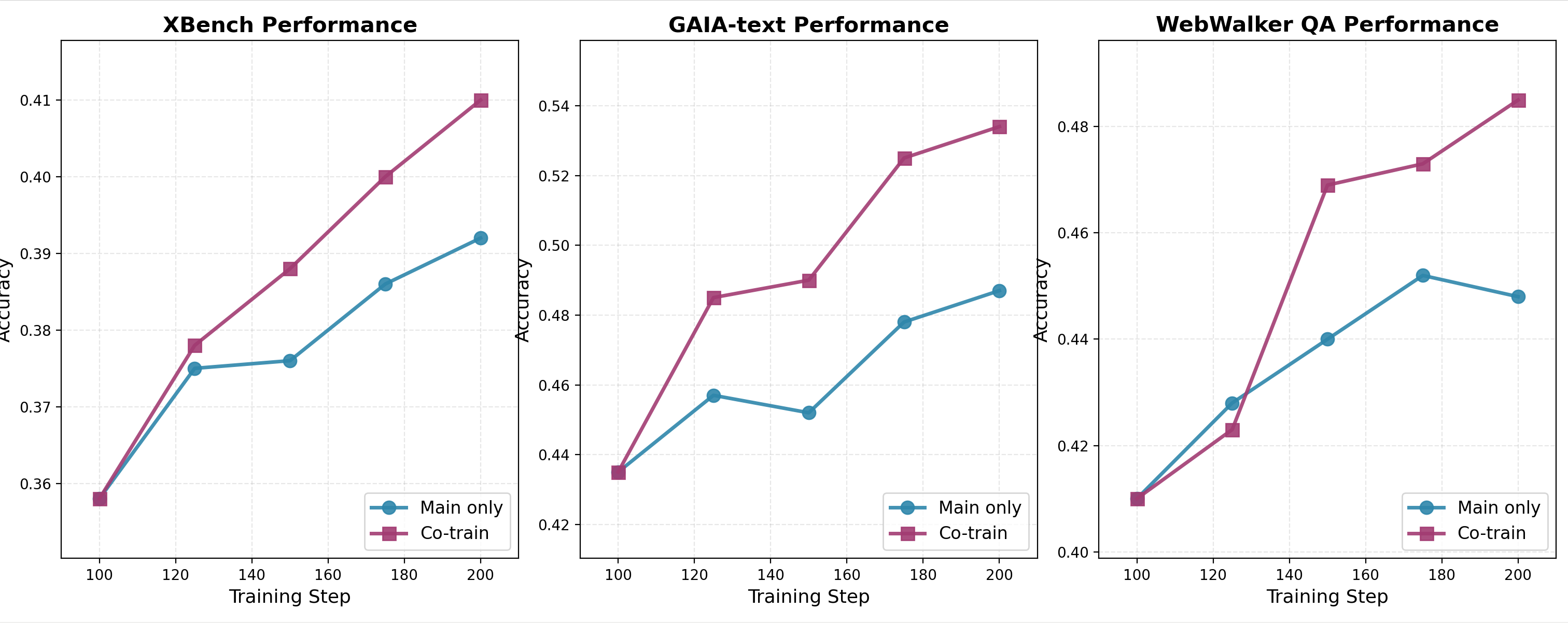
Figure 6: Benchmark performance during Stage 2 training.
Training Configuration Ablation: Investigations comparing configurations during Stage 2 highlight that co-training facilitates higher rewards than main-only approaches, underscoring the superiority of synchronized multi-agent behaviors in collaborative problem-solving.
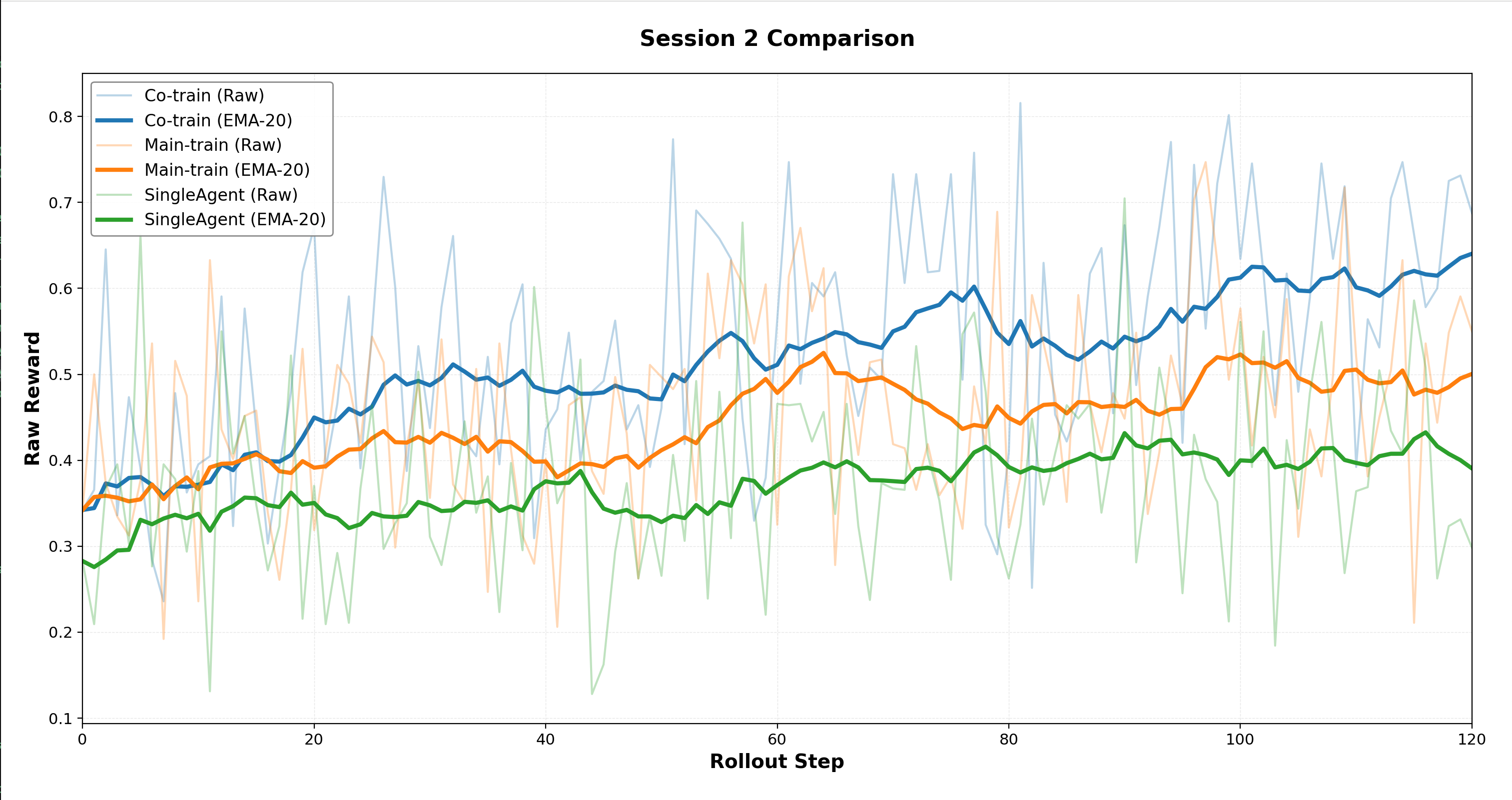
Figure 7: Stage 2 RL learning curves on challenging data.
Trajectory Synchronization Impacts: The study further confirms the advantage of trajectory synchronization strategies, which uphold policy-data correspondence and mitigate volatile training dynamics, contributing to enhanced learning stability.
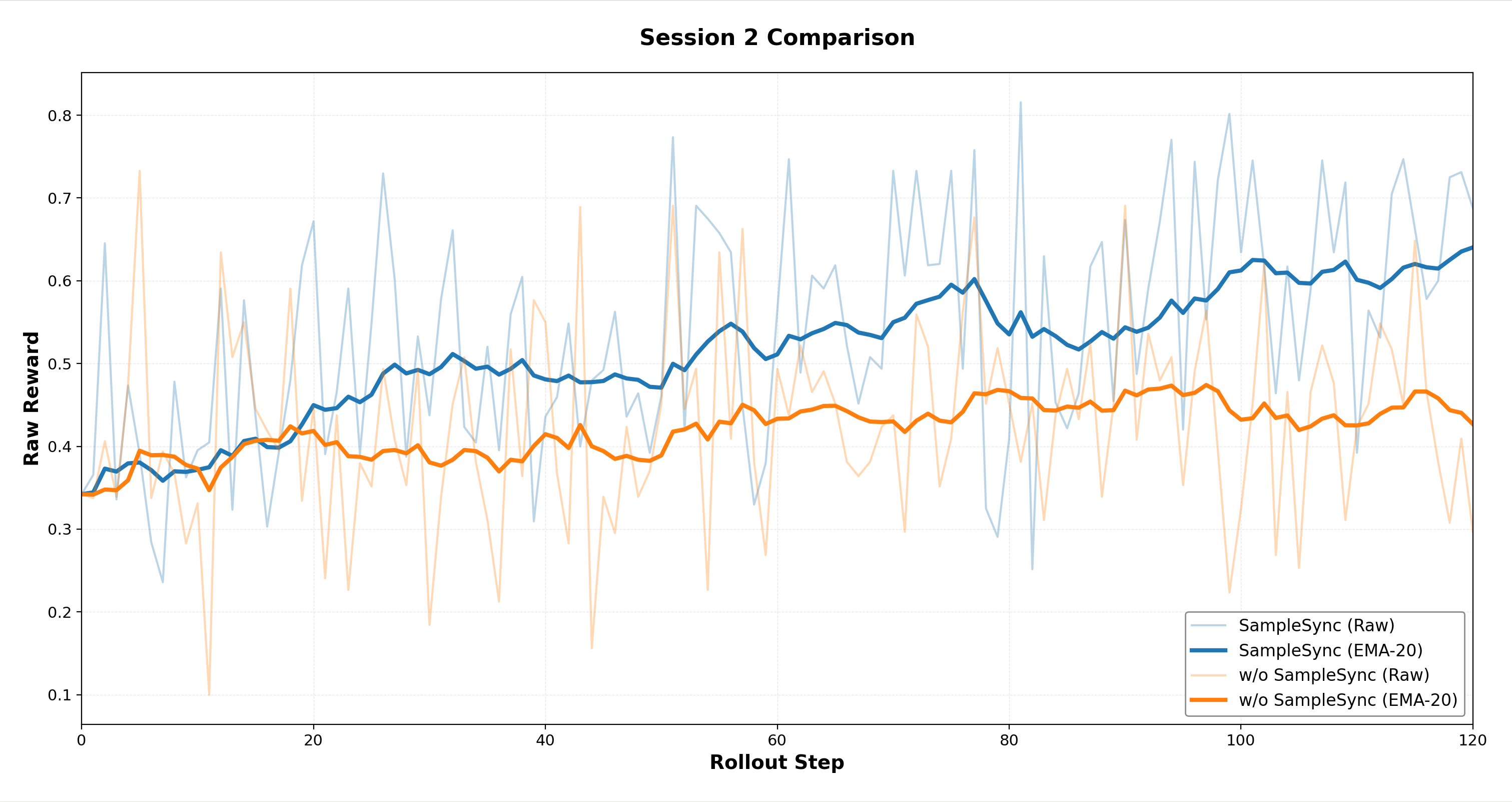
Figure 8: Stage 2 RL learning curves comparing implementations with and without trajectory synchronization.
Conclusion
The findings elucidate the substantial improvements brought about by M-GRPO in tool-enhanced reasoning tasks, accentuating the value of specialized role training over traditional approaches. By prioritizing hierarchical credit assignment and trajectory alignment, M-GRPO not only augments the reliability of LLM-driven multi-agent frameworks but also enables application in complex, real-world scenarios requiring diverse skill sets. The paradigm shift facilitated by this approach suggests promising avenues for future research in AI-driven collaborative systems.