- The paper proposes a novel evaluation pipeline that decouples algorithmic reasoning from code generation by introducing natural-language editorials.
- Results indicate up to 30% absolute improvement in pass@1 with gold editorials, while highlighting persistent challenges in efficient code translation.
- Cross-model editorial transfer reveals that separating reasoning from coding can boost weaker models, paving the way for modular LLM enhancements.
Editorials as Explicit Evaluation Artifacts for LLMs in Competitive Programming
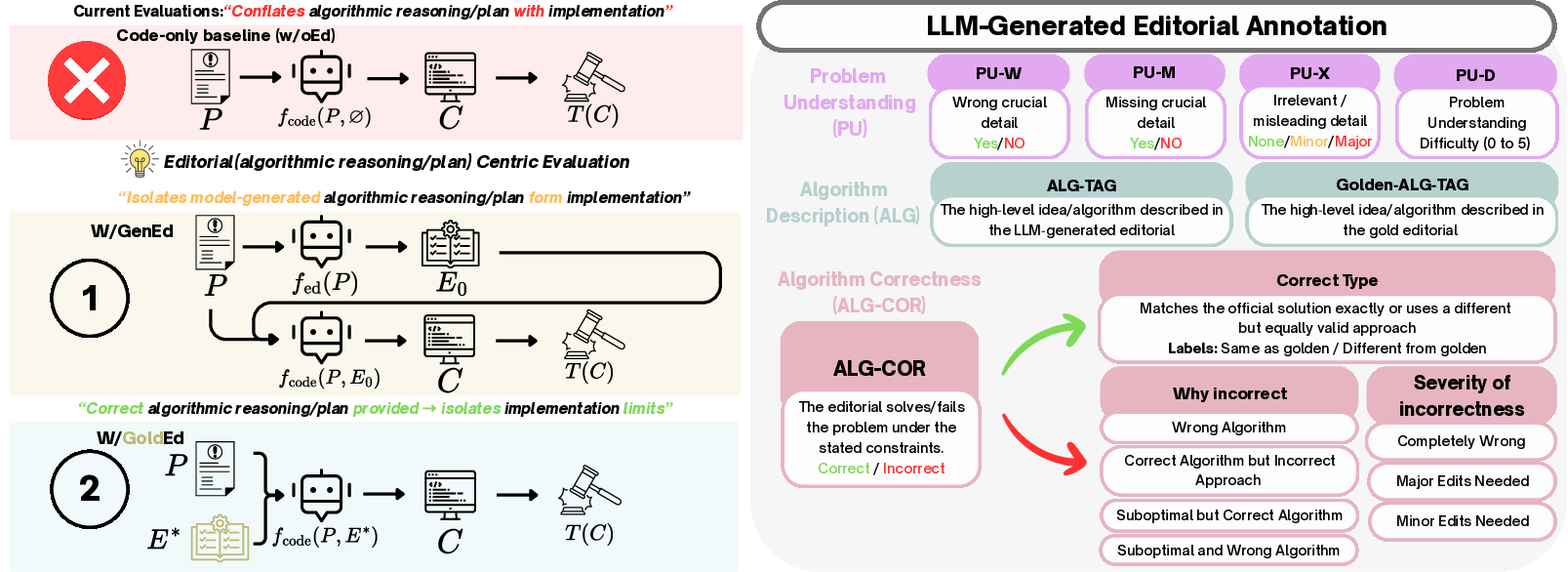
The dominant protocol for evaluating LLMs on competitive programming (CP) conflates algorithmic reasoning (plan derivation) and code-level implementation. Most prior work scores submissions solely on pass/fail outcomes against hidden or contest-style test suites, failing to localize errors to either planning or translation phases. This paper proposes an editorial-centric evaluation pipeline, explicitly introducing a natural-language editorial as an intermediate solution artifact between problem statement and code generation. The rationale is that CP is fundamentally an algorithmic problem-solving task; code is a downstream transcription of a plan specified in contest editorials.
The proposed pipeline consists of three distinct settings:
Dataset and Experimental Regime
A new benchmark is introduced, comprised of 83 ICPC-style problems sourced from contests spanning 2017–2025, each bundled with gold editorials from problem setters/testers and complete official test suites. The evaluation faithfully emulates contest scoring protocols: submissions are judged in C++ (primary language for ICPC), stratified by difficulty tertiles reflecting real human solve rates. Nineteen contemporary LLMs—spanning closed-source, chat, and open-weight families—are evaluated under all three editorial settings. Pass@1 and virtual rank percentile (relative to human teams) are reported.
Quantitative Results
Providing gold editorials yields substantial and consistent performance gains across all models and difficulties (up to ~30% absolute improvement in pass@1 for some families). However, even with perfectly-specified plans, hard problems remain unsolved for the majority of models (e.g., T3 pass@1 for all models with gold editorials averages only 16.5%), revealing a bottleneck in robust and efficient code translation.
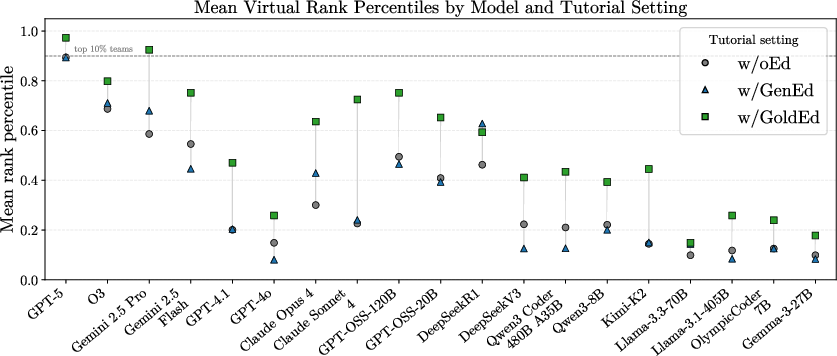
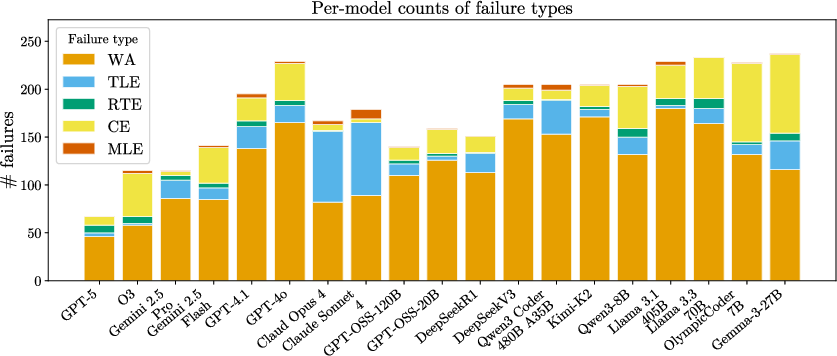
Figure 2: Mean virtual rank percentile and aggregate failure verdicts for all models and editorial settings; gold editorials drive large improvements, but failures are still predominantly wrong answers and timeouts.
Model-generated editorials (w/GenEd) provide highly variable improvements; stronger closed models and DeepSeek-R1 exhibit modest gains (up to ~15%), but performance may stagnate or degrade for others, especially on hard problems. The gap between w/GenEd and w/GoldEd quantifies the problem-solving bottleneck: many models produce editorials that are incomplete, inefficient, or fundamentally incorrect, which in turn restricts implementation to flawed plans.
WA verdicts dominate failure modalities, with TLE (complexity bottlenecks) disproportionately arising for stronger models such as Claude.
Qualitative Analysis of Reasoning and Implementation
Expert competitive programmers annotate model-generated editorials for select contests, using a rubric that grades problem understanding, algorithm description, and algorithmic correctness. Most editorials accurately reproduce problem constraints; hallucinated or missing crucial details are rare but catastrophic. The most prevalent reasoning errors involve incomplete or incorrect plans (e.g., missing invariants, inefficient algorithms), which propagate directly to downstream code failures. Even editorials that precisely describe correct algorithms often result in TLE or RTE due to complexity oversights.
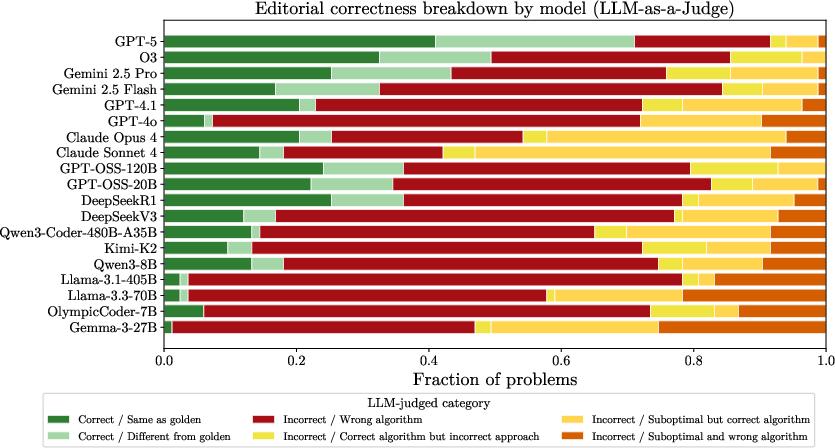

Figure 3: LLM-as-a-judge breakdown of editorial correctness and relationship to code verdicts; dominant cause of failure is incorrect problem-solving, with editorial correctness stratifying downstream code pass rates.
Notably, model-written editorials tend to be longer and more explicit than gold ones, trading concision for step-by-step clarity. Alignment in algorithmic paradigm tags is only a weak proxy for correctness; models may correctly describe key paradigms but omit critical details, or, conversely, match tags without producing correct results.
LLM-as-a-Judge and Editorial Transfer
Scaling human annotation is impractical; hence, an LLM-as-a-judge protocol is validated against expert annotation. This judge reliably diagnoses algorithmic correctness, error types, and failure severity, with high agreement on core signals.
Editorial correctness, as labeled by the judge, is strongly predictive of code-level pass rates (binary success correlates >0.6 across models). Editorals with suboptimal complexity systematically lead to TLE verdicts.
Crucially, the editorial itself is a transferable artifact: cross-model experiments demonstrate that pairing strong writers (reasoners) with distinct coders improves or matches the writer's own end-to-end performance. In some configurations, a weaker model implementing a stronger model's editorial even exceeds both models’ w/GenEd performance, confirming that reasoning and implementation can be modularized.
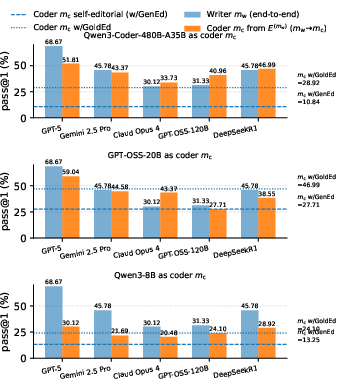
Figure 4: Cross-model editorial transfer: using editorials from strong reasoners boosts coding for weaker models, sometimes competitive with end-to-end scores.
Language and Contest Variance
Primary evaluation is conducted in C++ due to language-specific constraints in CP, with Python pass rates consistently lower. Absolute ranking must therefore be interpreted as CP-specific rather than general software engineering proficiency.
Contest-relative rank percentiles highlight that even with gold guidance, only a handful of models approach strong human-team competitiveness in real settings.
Implications and Future Directions
Editorial-centric evaluation exposes fine-grained bottlenecks in LLMs for CP—disentangling the challenge of correct algorithm specification from its robust and efficient implementation. It enables modular composition, diagnostic error attribution, and transfer learning. Future developments should address:
- Fine-tuning for editorial writing as a task distinct from code synthesis
- Scalable editorial judging via LLM protocols for more granular benchmarking
- Feedback-aware loops for plan refinement and code repairing, leveraging intermediate diagnostics
- Extension to broader problem formats and languages beyond classical ICPC settings
The paradigm suggests that benchmarks should move beyond monolithic problem-to-code scoring and explicitly measure reasoning and implementation as orthogonal competencies.
Conclusion
Treating editorials as explicit, transferable artifacts enables rigorous separation of algorithmic reasoning from code-level implementation in LLMs for competitive programming. Gold editorials drive large pass rate gains but highlight persistent implementation bottlenecks. Model-generated editorials expose a reasoning bottleneck—many models fail to specify fully correct plans, especially for hard problems. Editorials are not only diagnostic but compositional; reasoning and coding can be modularized across models. This methodology should set the standard for future CP benchmarks and the development of more reliable, interpretable AI assistants in algorithmic contexts.