The unreasonable effectiveness of pattern matching
Abstract: We report on an astonishing ability of LLMs to make sense of "Jabberwocky" language in which most or all content words have been randomly replaced by nonsense strings, e.g., translating "He dwushed a ghanc zawk" to "He dragged a spare chair". This result addresses ongoing controversies regarding how to best think of what LLMs are doing: are they a language mimic, a database, a blurry version of the Web? The ability of LLMs to recover meaning from structural patterns speaks to the unreasonable effectiveness of pattern-matching. Pattern-matching is not an alternative to "real" intelligence, but rather a key ingredient.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
The unreasonable effectiveness of pattern matching — explained simply
What is this paper about?
This paper shows that LLMs like ChatGPT and Gemini can figure out the meaning of sentences even when most of the real words are replaced with made‑up nonsense words. The authors use this to argue that “pattern matching” isn’t a cheap trick—it’s a powerful part of how both AIs and humans make sense of language and the world.
What questions are the authors asking?
- Are LLMs just parrots that repeat text they’ve seen, or do they actually understand patterns well enough to make sense of brand‑new situations?
- If you scramble or hide most of the important words in a text, can an LLM still guess what it means?
- How far can pattern matching go? Is it just about language, or is it part of human thinking in general?
How did they test this? (Methods in everyday terms)
The authors ran a set of simple but clever experiments:
- Jabberwockifying texts: They took normal English texts (news articles, Reddit posts, school essays) and randomly replaced most content words (nouns, verbs, adjectives) with nonsense words, while keeping the grammar and word order. For example, “He dragged a second chair” might become “He dwushed a ghanc zawk.” The “skeleton” of the sentence stays; the “meat” (content words) is swapped out.
- Extreme masking: In some tests they replaced every content word with the word “BLANK,” like “In the BLANK BLANK, BLANK BLANK has BLANK…,” and asked the LLM to recover the original meaning.
- The Gostak game: They let an LLM briefly play an old text‑adventure game written entirely in a fake language (“Gostakian”), then asked it what some of the made‑up words probably meant. The model used game feedback and context to infer meanings.
- Unseen, recent texts: They tested brand‑new posts (like an ESPN update and a Reddit question) that the models couldn’t have seen during training. The LLMs still produced reasonable translations from the nonsense versions.
Think of this like hearing someone whistle “Happy Birthday” very off‑key: even if many notes are wrong, the pattern still gives it away. Or like reading scrambled text (“if yuo cna raed tihs…”): your brain fills in the gaps because the pattern of letters and grammar helps you guess the intended words.
A few terms in simple language:
- Pattern matching: Noticing familiar structures or “shapes” in information, and using them to fill in missing details.
- Grammar/syntax: The rules for how words are arranged in sentences (who does what to whom, when, where).
- Context: The surrounding clues that narrow down the best meaning (football numbers suggest a sports story; “Netherlands” suggests Dutch foods).
What did they find, and why is it surprising?
- LLMs can often “translate” nonsense‑heavy text back into understandable English, sometimes very accurately.
- Example: A football sentence like “he dwoiseed 88 plonges for 884 spelchs” was translated as “he had 88 receptions for 884 yards,” because those numbers and the sentence shape strongly fit football talk.
- Example: A Reddit post about a Dutch food term became clear after swapping just one hint (“in the Splud” → “in the Netherlands”). That one clue steered the model toward Dutch supermarket foods and improved the whole translation.
- Even when nearly all content words were replaced with “BLANK,” the model still reconstructed the main ideas (such as “federal law preempts state law”) just from the sentence structure and tiny words like “in,” “the,” “of,” “when.”
- After a bit of unsupervised play, the LLM started figuring out the meanings of fake words in The Gostak game by noticing how they behaved in sentences and the game’s responses.
- These results were not just copy‑and‑paste. The models handled brand‑new, unseen posts and often filled in plausible details, sometimes getting specifics wrong but the big picture right.
Why it’s important:
- This goes way beyond “mimicking” or “database lookups.” You can’t look up “He dwushed a ghanc zawk” in Wikipedia. The model uses learned patterns of language to infer meaning from structure.
- It shows language is not just words; it’s patterns all the way down. Because grammar and context create a “fingerprint,” even nonsense words can be mapped back to real meanings.
How does this connect to how humans think?
The paper argues that people also rely heavily on pattern matching:
- We can read blurred or scrambled text because the pattern is familiar.
- Our everyday reasoning is often guided by context and patterns, not strict, step‑by‑step logic. We’re great at using hints, examples, and structures to fill gaps.
- Linguists describe language as “constructions” (patterns ranging from fixed phrases like “kick the bucket” to abstract sentence frames like “Subject–Verb–Object”). LLMs seem to learn and use these construction patterns at huge scale.
The twist: While strict logic is crucial for things like building circuits or doing proofs, human day‑to‑day thinking is messy, context‑sensitive, and pattern‑based. LLMs succeed by doing that kind of large‑scale pattern matching extremely well.
The authors also offer a helpful picture: LLMs are like powerful “deblurrers.” They’ve learned a compressed representation of language and knowledge. Given a blurry, incomplete input, they can often reconstruct a sharp, meaningful version. This reframes the “blurry JPEG of the web” insult: the “blurriness” is exactly what lets them fill in missing details when the input is incomplete.
What does this mean for the future? (Implications)
- Rethinking AI: Calling LLMs “stochastic parrots” misses the point. Pattern matching, done well, is a big part of real intelligence—human and machine.
- Better tools and prompts: Small, well‑chosen hints (like specifying a country) can strongly improve results. Knowing the model’s strength—using structure and context—helps us ask better questions.
- Understanding minds: These findings support the idea that human cognition is largely pattern‑based. Our “cognitive prostheses” (language, diagrams, math notation) extend and sharpen those patterns so we can think more abstractly.
- Limits and care: Models can still be wrong about details. They are powerful guessers using patterns, not perfect truth machines. That means we should use them thoughtfully, check facts, and give good context.
Bottom line
The paper shows that when LLMs make sense of “nonsense,” they aren’t just faking it—they’re using the hidden structure of language to rebuild meaning. Pattern matching isn’t a shortcut around intelligence. It’s a core ingredient of it.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
The paper presents striking qualitative demonstrations but leaves several empirical, methodological, and theoretical issues open. Future work could address the following gaps:
- Quantitative evaluation is missing: establish standardized metrics for “translation” quality (human-annotated semantic fidelity, factual accuracy, and calibration), report accuracy distributions, and test statistical significance across large, diverse corpora.
- Baselines and ablations are absent: compare LLMs to simpler models (n-gram, HMM, POS-only models, syntax-only parsers), retrieval-based systems, and rule-based paraphrasers; perform ablations removing numbers, named entities, and function words to isolate which cues drive success.
- Contamination and retrieval vs reconstruction remain unresolved: use strict out-of-distribution protocols (freshly authored texts, synthetic datasets never on the web), disable web/tools, apply membership inference tests, and measure verbatim overlap to distinguish reconstruction from memorization.
- “Structural fingerprint” uniqueness is untested: quantify collision rates (how often different texts share the same function-word/grammar template), assess false matches, and measure how often LLMs reconstruct incorrect plausible sources given the same skeleton.
- Jabberwockification parameters provide cues: systematically vary orthotactic constraints, preserve vs scramble morphological affixes, swap word order, and introduce adversarial noise to test robustness and identify minimal structural cues required for recovery.
- Role of numeric anchors and domain priors is unclear: remove or perturb numbers, units, and conventional domain markers (e.g., sports stats), and assess the drop in accuracy to separate genuine structural inference from template-driven filling.
- Cross-linguistic generality is not demonstrated: replicate in typologically diverse languages (free word order, rich morphology, non-segmented scripts), test cross-lingual Jabberwocky (e.g., nonsense tokens in Mandarin, Turkish, Finnish), and compare performance across languages.
- Mechanistic explanation is lacking: use interpretability methods (causal tracing, activation patching, probing, representational similarity analyses) to identify which layers and features support structural matching and semantic resolution.
- Human–LLM comparative performance is speculative: run controlled psycholinguistic studies comparing humans and LLMs on Jabberwockified comprehension, measuring accuracy, latency, cognitive load, and how performance scales with context length and cue availability.
- Generalization limits and failure modes are unknown: catalog domains where recovery fails (logic-heavy texts, mathematical derivations, code, poetry with weak syntactic signature), characterize error types (plausible but wrong substitutions), and map boundaries of the approach.
- Confidence calibration is not assessed: require models to produce uncertainty estimates and measure calibration (ECE/Brier scores) against ground truth meanings to ensure reliability under ambiguity.
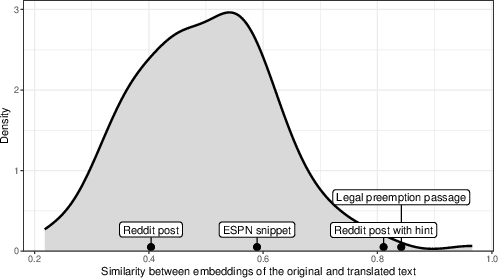
- Evaluation on “totally masked” content words needs rigor: verify with ground-truth mappings (author-preserved original texts), ensure outputs aren’t merely plausible paraphrases, and quantify semantic overlap beyond embedding similarity (which can be misleading).
- The embedding-similarity metric is insufficient: complement with human judgments, entailment tests, semantic frame matching, information-theoretic measures, and task-based utility evaluations (e.g., question answering from recovered text).
- Interactive alignment in The Gostak requires validation: test whether models learn stable lexicons (probe post-game definitions in novel contexts), measure sample efficiency, retention across sessions, and whether improvement stems from in-context learning vs actual updating.
- Effects of model size, training data, and fine-tuning are unknown: run model-scaling studies, compare pretraining corpora (content size/diversity), assess impact of SFT/RLHF, and examine whether smaller models can achieve similar recovery under constrained conditions.
- Distinguish syntax-only from semantics-driven recovery: create stimuli with identical syntactic skeletons but divergent semantics, and test whether models converge on one meaning or maintain uncertainty across viable interpretations.
- Formalization of “pattern matching all the way down” is missing: propose a computational framework (e.g., probabilistic constraint satisfaction over constructions), derive testable predictions, and compare to alternative accounts (symbolic parsing, retrieval-augmented reasoning).
- Benchmarks are needed: release a public “Jabberwocky comprehension” dataset with controlled degradations, ground-truth mappings, adversarial variants, and standardized evaluation scripts to enable reproducible comparison across models.
- Real-time robustness is untested: measure performance under streaming input, partial sentences, and noisy channels; assess whether recovery improves with incremental context and whether early errors propagate.
- Downstream utility is unclear: test whether recovered texts support accurate downstream tasks (summarization, QA, information extraction) and quantify end-to-end performance vs using the original text.
- Effect of prompt design and decoding is unreported: systematically vary prompts (instructions, context framing), temperatures, and sampling strategies to measure sensitivity and reproducibility of recovery.
- Boundary between compression and hallucination is fuzzy: design experiments that quantify how often pattern-based “deblurring” yields factually incorrect yet fluent outputs, and develop methods to constrain recovery to verifiable content.
- Ethical and risk considerations of inferring meaning from ambiguous inputs are not discussed: explore safeguards to prevent confident misinterpretation in high-stakes domains (legal, medical), including mechanisms to flag unresolved ambiguity.
- Data, code, and full experimental details are pending: release the jabberwockification pipeline, datasets, prompts, model settings, and annotation protocols to enable replication and independent validation.
Glossary
- Category error: A logical mistake where something is misclassified as a type of thing it isn’t. "Equating LLMs to technologies like Wikipedia or card catalogs turns any claim that LLMs “think” into a category error because, clearly, Wikipedia cannot think."
- Classical connectionism: A cognitive science approach modeling thought as emergent from networks of simple units performing parallel computations. "The idea of cognition as pattern-based constraint satisfaction has its roots in classical connectionism..."
- Cognitive prostheses: Cultural tools that extend and scaffold human thinking (e.g., numerals, diagrams, language). "our pattern-matching minds are extended by cognitive prostheses which allow us to formulate and manipulate progressively more abstract and larger patterns."
- Constraint satisfaction: The process of finding values that jointly meet a set of constraints; used to describe pattern-based reasoning. "the general process of pattern-matching and constraint satisfaction that LLMs are using appears to be a very human one."
- Construction grammar: A linguistic theory that represents language knowledge as learned form–meaning pairings (constructions), not just rules plus words. "Constructions: A construction grammar approach to argument structure"
- Dependent arising: A Buddhist philosophical doctrine that phenomena arise interdependently, not in isolation. "It is also foundational to the Buddhist concept of PratÄ«tyasamutpÄda (dependent arising)."
- Distributional nature of word meanings: The idea that word meaning is defined by usage patterns and co-occurrences in language. "Wittgenstein’s insights into the distributional nature of word meanings"
- Embeddings: Vector representations of text that capture semantic relationships, enabling similarity comparisons. "we computed similarity between the embeddings (OpenAI text-embedding-3-large) of the original text and LLM “translations”"
- Emergent abilities: Capabilities that appear unexpectedly as model scale or training increases. "The list of these so-called “emergent” abilities keeps growing."
- Existential threat: A risk that could cause humanity’s extinction or irreversible collapse. "on the verge of gaining superintelligence and posing an existential threat to humanity"
- Function words: Grammatical words (e.g., articles, prepositions) that provide structural scaffolding rather than content. "The matching would need to be done on the basis of function words alone"
- Generative linguistics: A formal approach that posits innate grammatical structures and rules underlying language. "and which continues to be at the center of generative linguistics"
- Interactive fiction: A text-based game genre where players issue typed commands to affect the narrative and environment. "In conventional interactive fiction games, players navigate text-based world–moving between locations, picking up objects, fighting enemies, and solving puzzles–by issuing commands..."
- Jabberwockified: Describing text where content words are replaced with nonsense strings while preserving structure. "The ability of LLMs to make sense of Jabberwockified English may seem like there is an alien intelligence at work."
- Legal pre-emption: A doctrine where higher-level (e.g., federal) law supersedes conflicting lower-level (e.g., state) law. "The original text, describing legal pre-emption, is included for comparison."
- Morphosyntactic patterns: Combined structural regularities of morphology (word forms) and syntax (sentence structure). "more complex or abstract morphosyntactic patterns."
- Next-token prediction: The training objective of LLMs to predict the next word/token given context. "Exposure to these texts (in the context of next-token prediction) evidently allowed the model to learn patterns..."
- Orthotactics: The rules governing permissible letter sequences in a language’s writing system. "The random strings are restricted to roughly follow English orthotactics..."
- Portmanteau: A blended word formed by merging sounds and meanings of two words. "Slithy, for example, is a portmanteau of “slimy” and “lithe.”"
- Pretraining corpora: Large datasets used to train LLMs prior to any task-specific fine-tuning. "may have been included in the pretraining corpora."
- Subject–Verb–Object1–Object2: A syntactic template for ditransitive constructions involving two objects. "patterns such as Subject–Verb–Object1–Object2."
- Stochastic parrots: A critical label for LLMs as probabilistic mimics without genuine understanding. "Others have derided the idea of anointing what they believe are mere “stochastic parrots” (i.e., mimics) with any type of intelligence at all"
- Symbolic algorithm: A rule-based procedure that manipulates abstract symbols to produce provably correct results. "executing a symbolic algorithm that reliably produces provably correct answers."
Practical Applications
Overview
The paper demonstrates that LLMs can reconstruct meaning from highly degraded text by leveraging structural “fingerprints” (syntax, morphology, numbers, discourse patterns) even when most content words are replaced by nonsense strings or masked. This “unreasonable effectiveness of pattern matching” has immediate implications for products that denoise, normalize, retrieve, and interpret text under uncertainty, and longer-term implications for privacy policy, decipherment, robotics, compression, and education.
Below are actionable applications derived from the paper’s findings, methods (e.g., “Jabberwockification” as a robustness probe), and conceptual innovations (e.g., structural fingerprinting, deblurring-from-patterns), grouped by deployment horizon.
Immediate Applications
The following can be built or integrated into existing workflows with current LLM capabilities, subject to standard guardrails and validation.
- Noisy text recovery and normalization (software, accessibility, contact centers)
- Use case: Clean up OCR/ASR output, text with heavy typos/scrambling, chat transcripts, and SMS logs by inferring intended words from structural and contextual patterns.
- Tools/products: Context-aware denoising editors; “LLM Spell+Grammar (Structure-Aware)” APIs; ASR post-processors that reconstruct missing tokens.
- Assumptions/dependencies: Domain-tuned prompts; human-in-the-loop for high-stakes use; bias/overcorrection monitoring.
- Redaction and obfuscation risk auditing (legal, compliance, journalism, public sector)
- Use case: Test whether “structure-only” patterns in redacted or obfuscated documents can inadvertently reveal sensitive content (e.g., case facts, parties, protected health data).
- Tools/products: “Redaction Risk Auditor” that Jabberwockifies or masks content and attempts reconstruction to quantify leakage risk; structure-aware anonymization checkers.
- Assumptions/dependencies: Clear policy that the tool is for defensive auditing; logging and access controls; legal/ethical review.
- Coded language, slang, and euphemism interpretation (trust & safety, content moderation)
- Use case: Detect and translate meaning from fast-evolving slang, euphemisms, or code words used to evade moderation by matching relational structure and context.
- Tools/products: “Coded Speech Monitor” dashboards for safety teams; escalation flags when semantic reconstructions reach confidence thresholds.
- Assumptions/dependencies: Human review; fairness audits; jurisdiction-specific policy alignment.
- On-the-fly jargon and glossary induction (enterprise support, education, localization)
- Use case: Rapidly learn and normalize project- or community-specific terminology (internal acronyms, idiolects, classroom invented words) by observing usage patterns.
- Tools/products: “Live Lexicon Builder” that suggests candidate definitions and mappings; chatbot modules that align unfamiliar tokens to known concepts during a session.
- Assumptions/dependencies: Minimal bootstrap context from conversation logs or short exemplars; review-and-accept workflow for teams.
- Clinical text standardization (healthcare)
- Use case: Expand abbreviations, normalize idiosyncratic phrasing, and reconcile partially redacted or noisy clinical notes while preserving clinical meaning.
- Tools/products: “Structure-Based Normalizer” for EHR ingestion; coding support to map noisy notes to SNOMED/ICD using relational cues.
- Assumptions/dependencies: HIPAA compliance; clinical validation; guardrails to avoid hallucinated facts.
- Structure-aware search and summarization (enterprise search, legal, finance)
- Use case: Retrieve and summarize documents that share relational patterns (e.g., “federal preempts state X in domain Y”) even when surface terms differ or are missing.
- Tools/products: “Structural Fingerprint Retrieval” layers on top of vector search; summary engines that reconstruct gist from partial inputs.
- Assumptions/dependencies: High-quality embeddings; evaluation sets; explainability for auditability.
- Semantic code deobfuscation aids (software engineering, cybersecurity)
- Use case: Infer meaningful names/comments for minified or obfuscated variables and functions by leveraging usage structure and call patterns (documentation recovery).
- Tools/products: IDE plugins that propose semantic renamings; reverse-engineering assistants for code comprehension.
- Assumptions/dependencies: IP and license compliance; careful use on proprietary code; human validation.
- Robustness benchmarking via “Jabberwockification” (AI evaluation in industry and academia)
- Use case: Systematically replace content words with pronounceable nonce strings to test LLMs’ reliance on structure vs. surface-form memorization.
- Tools/products: “Jabberwocky Robustness Suite” to create and score masked/obfuscated benchmarks and leaderboards; fine-tuning datasets emphasizing constructional generalization.
- Assumptions/dependencies: Task-specific scoring rubrics; domain-diverse corpora; reproducible evaluation protocols.
Long-Term Applications
These require further research, scaling, safeguards, or cross-disciplinary integration before broad deployment.
- Zero/low-resource language decipherment and revitalization (academia, cultural heritage)
- Use case: Infer semantics and grammar from small corpora or partially-known scripts by aligning structural fingerprints to known linguistic constructions.
- Tools/products: “Structure-First Decipherment Toolkit” for field linguists; museum/research pipelines to hypothesize lexicons and constructions.
- Assumptions/dependencies: Enough parallel or comparable text for constraints; expert oversight; ethical collaboration with communities.
- Structure-aware anonymization and privacy-preserving analytics (policy, healthcare, finance)
- Use case: Develop anonymization standards and tools that consider structure-based leakage; enable analytics on masked corpora while minimizing semantic reconstruction risk.
- Tools/products: “LLM-Resistant Redaction” libraries; adversarial simulators that score re-identification from structure; policy templates for data release.
- Assumptions/dependencies: Regulatory updates (e.g., HIPAA/GDPR interpretations); differential privacy integration; red-team evaluations.
- Household/robot adaptation to invented words and ad hoc commands (robotics, smart home)
- Use case: Let robots/assistants learn user-coined tokens (“grab the floofer”) from local context and generalize via constructional patterns.
- Tools/products: On-device “Idiolect Adapter” modules; teach-by-doing workflows that bind new words to actions/objects.
- Assumptions/dependencies: Grounding to perception/action; safety constraints; continual learning without catastrophic drift.
- Compression and “deblurring” codecs for language and logs (infrastructure, software)
- Use case: Store or transmit structure-dense representations and reconstruct fluent text on demand using learned deblurring patterns.
- Tools/products: “LLM-Assisted Codecs” for long-form text/logs; hybrid symbolic–neural storage systems.
- Assumptions/dependencies: Cost/latency tradeoffs; deterministic reconstructions for compliance contexts.
- Advanced forensic deobfuscation (cybersecurity, law enforcement)
- Use case: Interpret obfuscated communications, malware strings, or steganographic text by extracting relational meaning under heavy noise.
- Tools/products: “Pattern-Match Forensics” platforms; analyst copilots that propose semantic reconstructions with confidence and provenance trails.
- Assumptions/dependencies: Strict legal process; bias and false-positive controls; dual-use risk management.
- Personalized literacy and language remediation (education, accessibility)
- Use case: Tutors that help readers with dyslexia/aphasia by filling gaps from context, teaching constructional cues, and progressively reducing scaffolds.
- Tools/products: “Construction Grammar Tutor”; adaptive reading apps that display graded “Jabberwocky” exercises to strengthen structure-based comprehension.
- Assumptions/dependencies: Clinical trials for efficacy; teacher dashboards; accessibility compliance.
- Structural fingerprinting for copyright and provenance (media, policy)
- Use case: Detect when generated text mimics the structure of protected works or identify lineage via structural signatures beyond surface n-grams.
- Tools/products: “Structure-Based Similarity Scanner” for publishers and platforms; provenance reports combining lexical and constructional features.
- Assumptions/dependencies: Legal standards for substantial similarity; acceptable false positive rates; transparent criteria.
- Scientific/technical knowledge extraction from noisy or partial texts (R&D, pharma, legal)
- Use case: Recover relational claims (A inhibits B, X preempts Y) from scanned, redacted, or poorly formatted documents to populate knowledge graphs.
- Tools/products: “Relation-First Extractors” that operate under masking; litigation/regs copilot for preemption and conflict-of-laws analysis at scale.
- Assumptions/dependencies: Gold-standard evaluation; domain-specific fine-tuning; expert validation loops.
Notes on Cross-Cutting Assumptions and Dependencies
- Model capabilities: Benefits increase with models trained on broad, diverse corpora; small domain-tuned models may suffice for focused tasks.
- Risk management: Because structure can leak meaning, tools must include guardrails, audit trails, and explicit policies against privacy breaches or misuse.
- Human oversight: High-stakes domains (healthcare, legal, cybersecurity) require human review, calibration studies, and conservative deployment.
- Evaluation: New benchmarks based on “Jabberwockification” and total masking (BLANKing) are needed to measure true structure-based generalization vs. memorization.
- Ethics and regulation: Policymakers should assume obfuscation/redaction can be partially reversible and update data-sharing and anonymization standards accordingly.
Collections
Sign up for free to add this paper to one or more collections.