- The paper presents TTARAG, a test-time adaptation framework that dynamically adjusts LLM parameters using self-supervised signals at inference.
- It employs a prefix-suffix segmentation strategy to process retrieved passages, enhancing the model’s understanding of domain-specific semantics.
- Empirical evaluations reveal significant accuracy gains across domains, notably improving biomedical QA performance compared to standard RAG.
Test-Time Adaptation for Retrieval-Augmented Generation: Predict-the-Retrieval
Introduction
Retrieval-Augmented Generation (RAG) has established itself as a robust strategy for incorporating external knowledge into LLMs, thereby mitigating information deficits and reducing hallucination. RAG’s principal limitation, however, is its generalization performance under domain shift: when deployed in specialized domains distinct from pretraining or fine-tuning distributions, parametric knowledge from LLMs inadequately adapts to new data dependencies, resulting in degraded downstream performance. The work “Predict the Retrieval! Test time adaptation for Retrieval Augmented Generation” (2601.11443) addresses this limitation by proposing a test-time adaptation (TTA) framework, TTARAG, which dynamically updates LLM parameters using self-supervised signals at inference, without requiring labeled data or access to the original training distribution.
Methodology and System Design
Self-Supervised Test-Time Adaptation for RAG
The core contribution is a self-supervised adaptation objective instantiated at inference. For each retrieved passage pi given a query q, passages are split into linguistically-informed prefix-suffix pairs, and LLMs are trained to predict each suffix conditioned on the prefix and the original query. The optimization target is:
Ladapt=−i=1∑klogP(pisuffix∣piprefix,q;θ)
where θ are the model parameters. This objective impels the LLM to internalize the structural semantics and domain-specific idioms present in the retrieval corpus, enhancing its response quality for the target domain.
Passage Preprocessing and Adaptation Loop
Passage segmentation uses a two-stage heuristic: prioritizing splits at punctuation for natural linguistic boundaries, falling back to midpoint splits when necessary. Extremely short passages are filtered. For each test query, adaptation proceeds in batches: suffixed tokens are masked, loss is computed on predicting suffix from given prefix and query, gradients are accumulated/clipped, and AdamW optimizer performs parameter updates. Critically, the LLM is reset to pretrained weights after each query’s adaptation to avoid catastrophic interference across queries.
System Comparison
TTARAG differs fundamentally from standard RAG systems: rather than statically leveraging retrieved content during generation, it introduces a transient adaptation phase where the LLM is tuned on-the-fly using the structure of retrieved knowledge, resulting in an “adapted” model tailored to the specific test-time context.
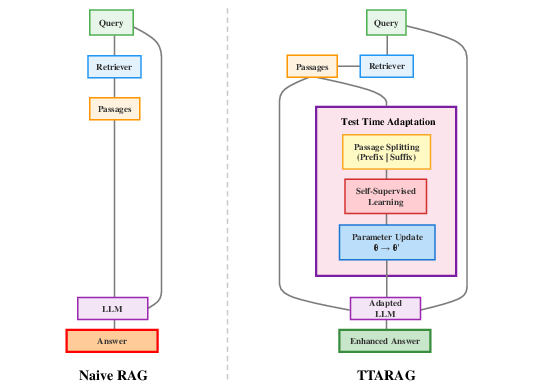
Figure 1: Comparison between Standard RAG and TTARAG systems.
Empirical Evaluation
Experimental Setup
TTARAG is evaluated on the CRAG benchmark (finance, sports, music, movie, open), as well as in-domain biomedical QA (BioASQ, PubMedQA). Models under scrutiny include Llama-3.1-8b-it, Llama-2-7b-chat, and ChatGLM-3-6b. Retrieved passages for CRAG use web-retrieved HTML sentences reranked by MiniLM, while BM25 provides evidence from PubMed or biomedical corpora for medical tasks. Model performance is measured using an LLM-judge framework (Qwen2.5-72B-Instruct) to assess semantic answer equivalence, as opposed to exact match.
TTARAG delivers consistent accuracy improvements across domains and model architectures relative to several baselines, including naive RAG, Chain-of-Thought (CoT), In-Context Learning (ICL), and multiple pretrained RAG variants (Ret-Robust, RAAT, Self-RAG):
- Llama-3.1-8b-it: TTARAG outperforms naive-RAG by +2.7% (finance), +2.8% (music), +3.3% (movie), and yields large gains on medical QA (+19.4% BioASQ, +10.8% PubMedQA).
- Llama-2-7b-chat: TTARAG achieves +1.7 to +4.2 percentage-point gains (general domains), +17.7% and +6.4% improvement for biomedical tasks.
- ChatGLM-3-6b: TTARAG produces +7.0% (BioASQ) and +25.0% (PubMedQA), as well as consistent improvements across non-medical domains.
Notably, standard RAG pretraining approaches (e.g., Ret-Robust, Self-RAG) exhibit inferior generalization to downstream domains even relative to naive RAG with smaller base models, highlighting the brittleness of existing RAG pre-training when confronted with significant semantic shift. TTARAG’s test-time adaptation consistently surpasses all other approaches regardless of base LLM.
Ablation: Segmentation Strategy
Segment-based adaptation (prefix-suffix splitting) is shown to provide +0.4% to +1.1% improvement across models over token-level next-word prediction, reinforcing the claim that structured, cognitively-motivated splitting aligns better with language understanding and model adaptation.
Hyperparameter Sensitivity
TTARAG’s effectiveness is robust to the number of adaptation pairs (optimal at 3–5) and learning rates (best in the range 1e−6 to 1e−5), as demonstrated by analysis of accuracy vs. these two hyperparameters.
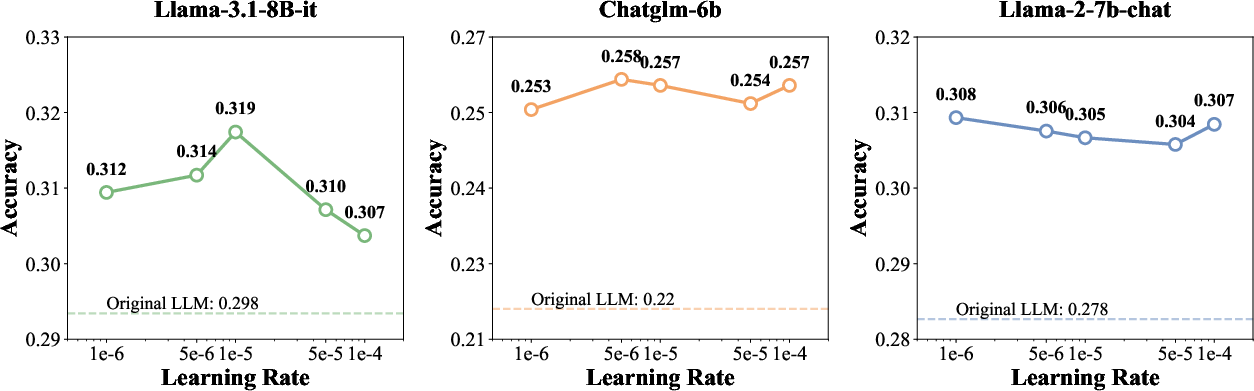
Figure 2: Accuracy vs. learning rate, with optimal performance for moderate rates and robust improvement across settings.
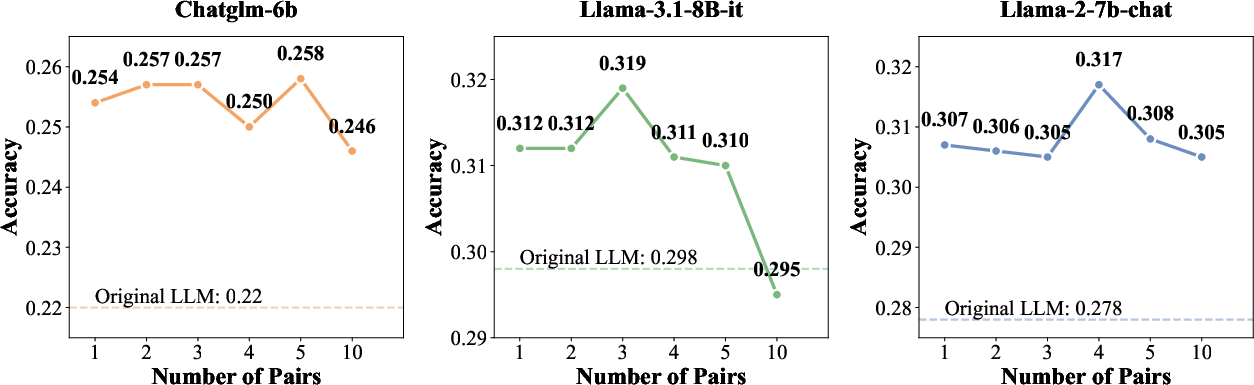
Figure 3: Accuracy vs. number of adaptation pairs, optimal at 3-5 pairs with performance degradation when excessive adaptation induces overfitting.
Computational Efficiency
Despite the introduction of a test-time adaptation phase, TTARAG remains computationally competitive: per-query adaptation latency (1.75–2.60s for 1–5 pairs) is substantially below that of CoT prompting (4.32s), with only moderate overhead relative to naive RAG.
Practical and Theoretical Implications
TTARAG establishes a practical paradigm for domain adaptation in knowledge-intensive NLP. By exploiting naturally occurring structure in the retrieval pipeline, the approach turns test-time context into a source of rich, domain-matched supervision—circumventing the need for labeled adaptation sets or retriever/model retraining. This paradigm offers significant practical implications for robust deployment of LLM-based knowledge assistants, particularly in high-value verticals such as medical QA, legal, and finance.
Theoretically, this work underscores the substantial limitations of static RAG pre-training for cross-domain generalization and suggests that dynamic, locally-adaptive parameter updates—grounded in context-aware self-supervision—can achieve superior flexibility. TTARAG represents a specific instantiation of a broader trend towards meta-learning and on-the-fly amortized inference in large foundational models.
Future Directions
Possible future extensions include: (1) exploring persistent or incremental adaptation to amortize adaptation costs across multiple related queries; (2) extending structured self-supervised adaptation objectives (beyond prefix-suffix prediction); (3) integration of RAG adaptation with retrieval-side TTA for enhanced parameter synergy; (4) application and scaling to significantly larger or smaller models, as well as evaluation under more diverse distribution shifts.
Conclusion
This paper delivers a rigorous account of self-supervised, test-time adaptation for Retrieval-Augmented Generation via prefix-suffix prediction on retrieved evidence. TTARAG demonstrates reliable, generalizable improvements across specialized domains, outperforming both prompting-based and pre-trained RAG baselines in accuracy, efficiency, and cross-domain robustness. The work points to the inadequacy of static RAG pre-training for domain adaptation, positioning dynamic, context-specific adaptation as a necessary mechanism for robust real-world LLM-based QA systems. The implications extend to scalable deployment of knowledge-augmented models, and the methodology presents a promising foundation for future developments in adaptive foundation model architectures.