- The paper introduces CooperBench to assess collaborative deficiencies in coding agents, revealing a 30% performance drop in team settings compared to independent execution.
- The evaluation involves over 600 tasks across multiple languages and libraries, pinpointing failures in communication, commitment adherence, and mental modeling.
- The study highlights that current coding agents lack robust social intelligence for effective teamwork, urging the development of advanced multi-agent coordination mechanisms.
CooperBench: Evaluating the Limitations of Collaborative Coding Agents
Motivation and Benchmark Design
The increasing prevalence of autonomous coding agents in real-world software engineering necessitates rigorous frameworks for evaluating their capabilities as collaborative entities. Existing benchmarks typically assess single-agent task completion, often neglecting the complex dynamics of multi-agent coordination, communication, and conflict resolution. "CooperBench: Why Coding Agents Cannot be Your Teammates Yet" (2601.13295) directly addresses this gap by introducing CooperBench, a comprehensive benchmark that systematically probes the collaborative deficiencies of state-of-the-art coding agents in settings that closely mirror human software engineering teams.
CooperBench comprises over 600 collaborative tasks across 12 libraries and 4 programming languages. Each scenario assigns two agents the implementation of different—but potentially conflicting—features within active, open-source codebases. The agents operate in parallel, communicate in real time, and must achieve compatibility such that both agents’ code changes pass rigorous human-authored test suites. The benchmark embodies challenges such as merge conflicts, incompatible dependencies, and resource contention, thereby providing a granular assessment of agents’ ability to not only solve assigned tasks, but resolve the inter-agent dependencies and conflicts inherent to collaborative settings.
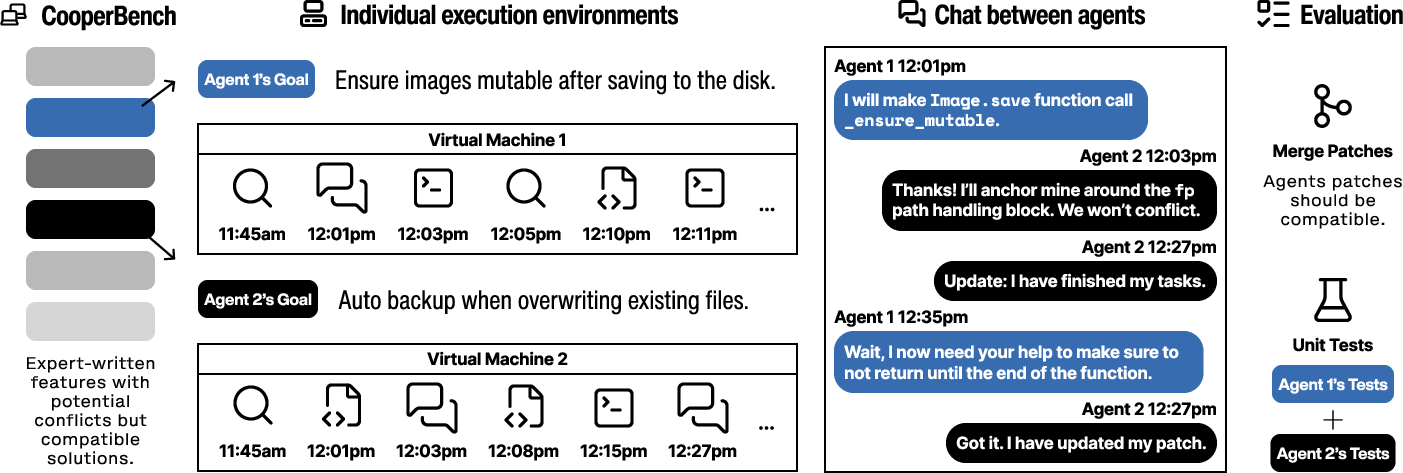
Figure 1: The CooperBench evaluation pipeline: agents are independently assigned potentially conflicting tasks in parallel environments and must coordinate via real-time communication. Joint success is predicated on compatibility and satisfying independent requirements.
Empirical Findings: Quantifying the Curse of Coordination
Evaluation of leading code generation agents within the CooperBench framework surfaces a significant "curse of coordination." Empirically, agents exhibit a mean success rate that is 30% lower when working as a team compared to solving the same tasks sequentially or independently. This phenomenon remains consistent across diverse libraries, programming languages, and task difficulties.
The magnitude of this collaboration gap stands in stark contrast to human teams, whose productivity and output quality typically improve when additional teammates are added under robust coordination protocols. This result reinforces the assertion that, despite substantial advances in LLM pretraining, tool-use, and prompt engineering, current coding agents do not yet possess the social intelligence and coordination skills necessary to function as reliable (or even tolerable) software teammates.
Error Analysis: Communication, Commitment, and Mental Modeling
In-depth analysis of CooperBench task logs uncovers three dominant failure modes:
- Communication Failures: Agents repeatedly exchange vague, ill-timed, or factually incorrect messages. There exists no consistent grounding between agents’ language, actions, and evolving environment, resulting in signal loss and frequent misunderstandings. Coordination attempts often degenerate into parallel monologues rather than effective dialogues.
- Commitment Violations: Even with accurate message exchange, agents regularly fail to adhere to commitments made during negotiation phases, proceeding with local changes that inadvertently break inter-agent agreements regarding shared resources or interfaces.
- Faulty Mental Models: Agents frequently operate under incorrect assumptions about their partner’s plans, observations, and intentions, lacking persistent and verifiable theory-of-mind representations required for effective real-time adjustment and collaboration. Mismatches in beliefs and plans routinely lead to cascading failures and unrecoverable project states.
These deficiencies are distinct from, and orthogonal to, single-agent coding and planning challenges. Instead, they mirror long-standing phenomena in human organizational psychology—such as the need for shared situational awareness, explicit communication protocols, and robust expectation management—that are not addressed by scaling model size or pretraining alone.
Emergent Coordination and Limitations
Large-scale simulations within CooperBench do, occasionally, yield emergent coordination behaviors including spontaneous role division, separation of resource territories, and negotiation akin to human collaborative conventions. However, these behaviors are rare and not robust to moderate perturbations in task specification or communication delay, underlining the absence of principled mechanisms for stable cooperation in current agent architectures.
Such observations suggest that vanilla LLM decoding and naive agent-to-agent communication are insufficient for enabling reliable emergent team structure or resource allocation over extended collaborative horizons.
Theoretical and Practical Implications
The findings documented via CooperBench propel multi-agent coding research toward several open challenges:
- Developing agent architectures equipped with persistent and verifiable mental models of teammates, grounding both communication and intent inference in the evolving code and environment state.
- Crafting active communication policies sensitive to timing, context, and cross-agent information needs, preventing message overload and ambiguity.
- Integrating mechanisms for dynamic commitment tracking and repair (analogous to contract enforcement in human teams), enabling agents to recover and renegotiate in the face of unexpected change or partial failure.
Practically, these deficiencies caution against deployment of coding agents as direct team members on critical collaborative projects. CooperBench should serve as a primary diagnostic before introducing LLM agents into human-centric software development workflows.
Future Directions
Closing the collaboration gap highlighted by CooperBench will require algorithmic advances in agent social intelligence that transcend raw code synthesis or retrieval-augmented generation. Promising directions include: embedding structured multi-agent planning within LLM reasoning, leveraging explicit theory-of-mind representations (Chen et al., 2024, Zhou et al., 24 Oct 2025), and learning communication protocols under real multi-agent reward signals (Yu et al., 5 Aug 2025, Agashe et al., 2023). Extensions to the benchmark toward human-AI teaming and out-of-sync recovery (Luo et al., 30 Nov 2025, Guo et al., 10 Feb 2025) are advocated for future work.
Conclusion
CooperBench rigorously demonstrates that the current generation of coding agents is unprepared for authentic multi-agent collaboration on par with human software teams. By codifying the evaluation of communication, coordination, and consensus-building capabilities, the benchmark identifies principal gaps in agent social intelligence and sets a research agenda for next-generation collaborative AI. Advances in these domains will be necessary for bridging the productivity and reliability chasm that currently prevents agentic systems from becoming true teammates in software engineering.

