TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
Abstract: Standard Vision-Language-Action (VLA) models typically fine-tune a monolithic Vision-LLM (VLM) backbone explicitly for robotic control. However, this approach creates a critical tension between maintaining high-level general semantic understanding and learning low-level, fine-grained sensorimotor skills, often leading to "catastrophic forgetting" of the model's open-world capabilities. To resolve this conflict, we introduce TwinBrainVLA, a novel architecture that coordinates a generalist VLM retaining universal semantic understanding and a specialist VLM dedicated to embodied proprioception for joint robotic control. TwinBrainVLA synergizes a frozen "Left Brain", which retains robust general visual reasoning, with a trainable "Right Brain", specialized for embodied perception, via a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. This design allows the Right Brain to dynamically query semantic knowledge from the frozen Left Brain and fuse it with proprioceptive states, providing rich conditioning for a Flow-Matching Action Expert to generate precise continuous controls. Extensive experiments on SimplerEnv and RoboCasa benchmarks demonstrate that TwinBrainVLA achieves superior manipulation performance compared to state-of-the-art baselines while explicitly preserving the comprehensive visual understanding capabilities of the pre-trained VLM, offering a promising direction for building general-purpose robots that simultaneously achieve high-level semantic understanding and low-level physical dexterity.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
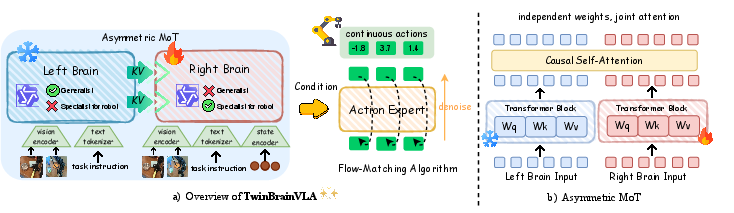
This paper introduces a new “robot brain” called TwinBrainVLA. It helps robots both understand the world (from pictures and words) and move their bodies precisely (like picking up objects), without forgetting what they already know. The key idea is to split the robot’s thinking into two parts—one that keeps general knowledge safe, and another that learns how to control the robot’s body.
Goals: What the researchers wanted to figure out
The paper aims to answer three simple questions:
- Can we stop robots from “forgetting” their general knowledge when we train them to do hands-on tasks?
- If we split the robot’s brain into a “knowledge side” and a “control side,” will it perform better at real tasks?
- Can this setup work well on many different robot tasks and still understand instructions and scenes?
Methods: How the system works (with simple explanations)
Think of a robot’s mind as two teammates working together:
- The Left Brain: This part is like a big encyclopedia. It’s already very good at understanding images and instructions (for example: “Put the mug on the coaster”). It is “frozen,” which means we don’t change it during training, so it won’t forget what it knows.
- The Right Brain: This part is the athlete. It learns how to move the robot’s arm and fingers. It also reads the robot’s “body sense” (called proprioception), which tells it where the robot’s joints and gripper are right now—like how you can touch your nose with your eyes closed because you can feel where your arm is.
How they talk to each other:
- Asymmetric Mixture-of-Transformers (AsyMoT): Imagine the Right Brain can “peek” at the Left Brain’s notes during a test. It can use the Left Brain’s knowledge to make better decisions, but it doesn’t change those notes. This keeps the Left Brain’s general knowledge safe from being overwritten.
How the robot learns to move smoothly:
- Flow-Matching Action Expert: Think of making a blurry sketch clearer step by step until it looks right. The robot starts with a “noisy” guess of an action and gradually makes it more accurate, guided by what the Right Brain understands about the task and the scene. This uses a model called a Diffusion Transformer (DiT), which is good at turning rough guesses into precise actions.
Training strategy:
- Only the Right Brain and the action model are trained on robot data.
- The Left Brain stays frozen, so it doesn’t suffer “catastrophic forgetting” (which is like practicing only soccer until you forget your math and vocabulary).
Findings: What they discovered and why it matters
The researchers tested TwinBrainVLA in two robot simulation worlds with many object-moving tasks.
- SimplerEnv (tasks like “put spoon on towel” or “stack blocks”): TwinBrainVLA reached around 62% average success with one setup, beating strong baselines like Isaac-GROOT N1.6 (~57%).
- RoboCasa (24 different tabletop tasks like placing items in drawers, microwaves, and cabinets): TwinBrainVLA achieved about 54.6% average success, outperforming other well-known systems by 6–11 percentage points.
Why this matters:
- Better performance: The robot completes more tasks correctly.
- No forgetting: It keeps its general understanding of images and language while learning precise control.
- More general purpose: It’s a step toward robots that can understand many kinds of instructions and also act with careful, human-like control.
Impact: What this could mean for the future
TwinBrainVLA shows that splitting knowledge and control into two coordinated “brains” can make robots smarter and more reliable. This design could lead to:
- Home or factory robots that can follow flexible instructions (“clean the counter, then put cups in the cabinet”) and actually do the steps safely and accurately.
- Easier training on new tasks without wiping out what the robot already knows.
- A foundation to combine bigger “knowledge brains” with faster “control brains” for even better performance.
The authors note future improvements, like mixing different types of brain models, training on larger datasets, and testing more in the real world. Overall, this is a promising blueprint for building robots that both understand and act well.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces TwinBrainVLA and demonstrates gains on two simulated benchmarks. The following concrete gaps and unresolved questions remain for future work:
- Preservation of general VLM abilities: No quantitative evaluation of open-world visual-language skills (e.g., VQA, captioning, instruction following) before vs. after VLA training to substantiate the “no catastrophic forgetting” claim at the system level.
- Reliance on Left Brain semantics: No analyses (e.g., attention maps, feature ablations) verifying that the Right Brain truly uses Left Brain KV features during control rather than ignoring them.
- AsyMoT ablations: Missing controlled comparisons to alternative fusion strategies (e.g., cross-attention without KV concatenation, gated fusion, adapters, FiLM, learnable projections) and to symmetric variants (training both brains, training only one brain, freezing different subsets).
- Stop-gradient design: No study of how stop-gradient placement (KV-only vs. broader) affects stability, learning dynamics, or performance; unclear whether partial unfreezing of the Left Brain might yield better trade-offs.
- Architectural coupling: Current need for identical architectures limits flexibility; concrete procedures for heterogeneous pairings (e.g., large generalist Left Brain + compact control-oriented Right Brain) and their performance/efficiency trade-offs remain unexplored.
- Computational overhead: No profiling of latency, memory, and throughput for dual VLM inference plus DiT policy; unclear feasibility for real-time control on embedded or resource-constrained robots.
- Scaling laws: Absent analysis of how performance scales with model size (Left/Right Brain), action-expert capacity, and token lengths; no guidance on optimal size ratios between the two brains.
- Data scale sensitivity: Only subsets of OXE were used; missing curves showing data-efficiency, saturation points, and the marginal utility of additional demonstrations for each component (Left/Right/DiT).
- OOD generalization: No tests under distribution shift (novel objects, unseen tasks, different language phrasings, lighting/camera changes, embodiment changes) to validate robustness claims.
- Cross-embodiment transfer: While two robots (WidowX, GR1) are used in simulation, there is no systematic study of cross-embodiment generalization or adaptation cost when transferring policies to new morphologies.
- Real-robot deployment: No hardware experiments, sim-to-real adaptation strategy, or analysis of latency, safety, and robustness in the presence of sensing/actuation noise and delays.
- Temporal perception: Visual processing appears single-frame/static; no evaluation of video encoders, temporal memory, or recurrent context for long-horizon, multi-step tasks requiring temporal reasoning.
- Multimodal sensing: Proprioception is included via an MLP, but tactile/force/torque/depth/multi-view inputs and their fusion with Left/Right Brain streams are not investigated.
- State encoder design: No ablation on the proprioceptive tokenization (which signals to include, embedding size, injection layer, early vs. late fusion) and its impact on closed-loop performance.
- Action expert choices: Flow-matching DiT is adopted without comparisons to alternative continuous-control formulations (e.g., diffusion vs. normalizing flows vs. tokenized actions) or solver choices (Euler vs. higher-order ODE solvers) under real-time constraints.
- Control quality metrics: Success rate is the only metric; smoothness, safety constraint violations, energy usage, and latency-sensitive tracking accuracy are not reported.
- Instruction adherence: No measurement of instruction grounding fidelity (e.g., success conditioned on paraphrases, compositional language, or ambiguous/underspecified instructions).
- Multilingual and multimodal language: Generalization to multilingual instructions and speech/audio interaction remains untested.
- Curriculum and multi-task training: The impact of mixing action loss with language modeling (NTP) or general VL data during training (curricula, loss weighting, staged unfreezing) is not explored.
- Continual learning: While freezing prevents forgetting in the Left Brain, the Right Brain and Action Expert may still forget when learning new tasks; mechanisms for continual adaptation without skill loss are absent.
- Interpretability and attribution: No tools or experiments (e.g., token/feature attribution) to disentangle when semantics vs. proprioception dominate decisions, or to diagnose failure modes.
- Safety and reliability: No discussion of safety guarantees, failure detection, or fallback behaviors for high-risk states and actuator saturation.
- Failure case analysis: Missing qualitative analysis of common failure patterns (e.g., mis-grasps, occlusions, articulated-object errors) to guide targeted improvements.
- Fairness of comparisons: Limited transparency on compute budgets, training durations, and data usage matching across baselines; unclear whether performance gains stem from architecture vs. training scale.
- Benchmark breadth: Only SimplerEnv and RoboCasa are used; evaluation on diverse, long-horizon, articulated, and deformable-object benchmarks (and real households/labs) would better validate generality.
- Knowledge alignment drift: As the Right Brain changes while the Left Brain is frozen, whether representational drift causes semantic-control misalignment (and how to re-align) is unaddressed.
- Distillation and compression: No strategies for distilling the dual-brain system into a single compact controller for deployment, or for pruning/quantization to reduce runtime costs.
- Robustness to noise: Sensitivity to sensor noise, calibration errors, time delays, and partial observability is untested; no robustness training (e.g., domain randomization) reported.
- Task compositionality: No experiments on multi-subgoal, compositional instructions or hierarchical task decomposition to assess whether the architecture scales to complex procedures.
Practical Applications
Practical Applications of TwinBrainVLA (AsyMoT dual-VLM + flow-matching control)
Below are applications derived from the paper’s dual-stream “Left/Right Brain” VLM design, the Asymmetric Mixture-of-Transformers (AsyMoT) fusion, and the flow-matching action expert. Each item notes sectors, potential tools/workflows, and feasibility assumptions.
Immediate Applications
- Dual-brain fine-tuning to prevent catastrophic forgetting in VLA training (Sectors: robotics, software, academia)
- Use TwinBrainVLA as a drop-in training recipe in existing VLA stacks (e.g., starVLA-based pipelines): freeze a generalist VLM as the “Left Brain”, clone it as a trainable “Right Brain” with proprioceptive tokens, and fuse via AsyMoT; train the policy with action-only flow-matching loss.
- Tools/workflows: a “freeze-left-brain” trainer, AsyMoT module, state-token encoder, CI tests that track pre/post fine-tune VLM capabilities.
- Dependencies/assumptions: identical VLM architectures for both brains (current limitation), access to demonstration datasets (e.g., OXE subsets), multi-GPU training; licensing for the chosen VLM (e.g., Qwen).
- Rapid benchmarking and model selection for tabletop manipulation (Sectors: robotics R&D, evaluation services)
- Apply the architecture to SimplerEnv/RoboCasa-style tasks to compare policies without degrading general visual-language skills; use simulated success rates as a proxy for policy quality.
- Tools/workflows: automated benchmark harness that logs both manipulation success and retained semantic/VQA performance.
- Dependencies/assumptions: sim-to-real gap awareness; standardized evaluation scripts; stable sim sensors and timing.
- Retrofitting existing VLA models to preserve open-world understanding (Sectors: robotics, enterprise integration)
- Migrate monolithic VLAs by freezing their pre-trained VLM as Left Brain, adding a trainable Right Brain + AsyMoT, and re-training only the Right Brain and action expert to recover performance without losing language/instruction-following.
- Tools/workflows: migration scripts that clone and rewire checkpoints; KV-extraction from frozen Left Brain for AsyMoT.
- Dependencies/assumptions: access to original weights and training data; runtime memory for dual models; no real-robot claims until validated.
- Action-only training pipelines with simpler data mixing (Sectors: robotics, MLOps)
- Adopt action-only flow-matching objectives (no mixed NTP/chat losses) without sacrificing general semantics, reducing dataset curation complexity during control fine-tuning.
- Tools/workflows: streamlined data loaders (RGB, instruction, proprioception), DiT-based policy trainer, ODE-based inference node.
- Dependencies/assumptions: frozen Left Brain reliably supplies semantic priors; sufficient action demos for target tasks.
- Multi-embodiment reuse of a shared Left Brain across robot platforms (Sectors: robotics fleets, OEMs)
- Standardize on a single frozen generalist Left Brain for a fleet, while training per-robot Right Brains specialized to embodiment/proprioception.
- Tools/workflows: fleet model registry with shared Left Brain image; per-embodiment Right Brain checkpoints; deployment templates.
- Dependencies/assumptions: consistent vision-language tokenization across platforms; calibrated proprioception encoders; version control for Left Brain.
- Safety and instruction-compliance gating via the frozen Left Brain (Sectors: robotics safety, policy, compliance)
- Use the unmodified Left Brain’s instruction-following to validate, sanitize, or reinterpret user commands before they condition the control policy, reducing drift from unsafe prompt tuning during control training.
- Tools/workflows: a “semantic gate” node that checks goals, unsafe objects/verbs, or domain constraints pre-action.
- Dependencies/assumptions: robust safety prompts/criteria; auditable logs; careful latency budget to keep closed-loop control responsive.
- Teaching and research modules on catastrophic forgetting and modular embodied AI (Sectors: academia, education)
- Classroom labs demonstrating monolithic vs dual-brain training and measuring semantic retention vs control accuracy.
- Tools/workflows: teaching notebooks, visualization of AsyMoT attention, ablations on freezing strategies.
- Dependencies/assumptions: access to compute and simulators; curated small-scale datasets for coursework.
- Plugin components for existing VLA codebases (Sectors: software tooling)
- Package AsyMoT, proprioception tokenizers, and DiT-conditioning bridges as reusable libraries for PyTorch/JAX stacks.
- Tools/workflows: pip-installable “TwinBrain” module; starVLA integration examples; inference graphs.
- Dependencies/assumptions: community adoption; stable APIs of underlying VLMs; clear licenses.
Long-Term Applications
- General-purpose home assistants with robust instruction following and dexterous manipulation (Sectors: consumer robotics, smart home)
- Robots that can parse open-ended language and perform fine-grained tasks (cleaning, tidying, cooking prep) without losing conversational competence during continual skill learning.
- Tools/products: “TwinBrain-enabled” household robots; app interfaces for multi-step instructions; cloud-updated Left Brain, on-device Right Brain updates.
- Dependencies/assumptions: real-robot validation beyond simulation; reliable perception in clutter; safety certification; on-device acceleration for dual models plus DiT.
- Retaskable cobots in manufacturing with natural-language programming (Sectors: manufacturing, Industry 4.0)
- Floor operators describe tasks in natural language; the frozen semantic Left Brain interprets specs while Right Brain policies are adapted to new fixtures/tools without revalidating the generalist core.
- Tools/products: line-changeover wizards; task libraries tied to semantic templates; per-station Right Brain fine-tunes.
- Dependencies/assumptions: precise calibration, safety cages, cycle-time constraints, quality assurance pipelines, regulatory acceptance of modular re-certification.
- Assistive robots for healthcare and eldercare (Sectors: healthcare, assistive tech)
- Systems that maintain robust language understanding (medication reminders, dialogue) while continuously improving physical assistance (fetch, open containers, device operation) through Right Brain updates.
- Tools/products: hospital logistics carts, bedside assistants; clinician-friendly task authoring via dialogue; safety gating via Left Brain.
- Dependencies/assumptions: clinical validation, HIPAA/data privacy, stringent safety and fail-safe behaviors, human-in-the-loop oversight.
- Warehouse/logistics manipulation with instruction-conditioned generalization (Sectors: logistics, e-commerce)
- Handling previously unseen SKUs or packaging with language-specified goals while refining grasp/placement skills per site via Right Brain specialization.
- Tools/products: SKU-agnostic pick-and-place; voice/text tasking; fleet-scale shared Left Brain service.
- Dependencies/assumptions: robust perception under varying lighting/occlusion; integration with WMS; latency constraints.
- Heterogeneous “brains”: large reasoning Left Brain + lightweight real-time Right Brain (Sectors: edge AI, embedded systems)
- Decouple a big cloud-scale Left Brain (rich reasoning/world knowledge) from a compact, high-frequency Right Brain on edge hardware; AsyMoT-like bridges generalized with adapters/projections.
- Tools/products: hybrid cloud-edge inference; low-latency KV streaming; adaptive compression of Left Brain features.
- Dependencies/assumptions: new fusion layers for heterogeneous backbones (not yet supported), bandwidth budgeting, feature privacy/security.
- Continual learning and certification-friendly updates (Sectors: safety, policy, standards)
- Maintain a certified Left Brain; iterate Right Brain and action expert for new skills/datasets with limited re-certification scope; log semantic invariance tests to satisfy auditors.
- Tools/workflows: change-control pipelines with semantic-regression suites; formally defined “semantic anchor” contracts.
- Dependencies/assumptions: standardized test suites for semantic retention; regulatory frameworks that recognize modular updates.
- Cross-embodiment transfer and fleet personalization (Sectors: robotics platforms, OEMs)
- Share the same Left Brain across arms, mobile manipulators, or humanoids; only adapt Right Brain per embodiment and environment, accelerating deployment and personalization.
- Tools/workflows: embodiment descriptors feeding proprioception encoders; policy distillation to new platforms; centralized knowledge management.
- Dependencies/assumptions: consistent sensor interfaces; reliable state-tokenization; scalable MLOps for many Right Brain variants.
- Extension to other embodied domains (drones, autonomous driving, AR/VR agents) (Sectors: mobility, aerospace, XR)
- Keep a frozen semantic world model (maps, traffic rules, task language), specialize Right Brain for platform-specific dynamics and sensorimotor loops.
- Tools/products: modular autonomy stacks; instruction-conditioned inspectors (drones), valet robots.
- Dependencies/assumptions: domain-specific datasets, real-time constraints, safety-critical redundancy and verification.
- TwinBrain SDK and service offerings (Sectors: software, cloud robotics)
- Commercial SDK that bundles AsyMoT, state encoders, DiT policies, evaluation harnesses; cloud service for “Left Brain as a Service” with on-prem Right Brain training.
- Tools/products: hosted KV feature APIs, fleet dashboards, semantic-retention scorecards.
- Dependencies/assumptions: secure multi-tenant hosting; IP/licensing for backbone VLMs; cost-effective inference.
- Data-efficient learning with targeted Right Brain updates (Sectors: R&D, cost optimization)
- Hypothesized reduction in data needs for new skills by leveraging the stable semantic anchor; prioritize collecting proprioceptive/action-rich demos.
- Tools/workflows: active learning to select demos that stress embodiment-specific gaps; uncertainty-aware retraining loops.
- Dependencies/assumptions: empirical validation of data efficiency at scale; robust active-learning heuristics.
Notes on feasibility across applications:
- Current evidence is simulation-based; real-robot trials, robustness, latency, and safety remain to be demonstrated.
- Present AsyMoT requires identical backbones; heterogeneous pairing needs further research (projection/adapters).
- Compute and memory overhead of dual models + DiT must be engineered for edge deployment.
- Legal and licensing considerations for commercial use of chosen VLM backbones apply.
Glossary
- Action Expert: A policy module that generates continuous robot actions conditioned on learned representations. "provide conditioning for the Action Expert"
- Asymmetric Dual-Stream Paradigm: A design where a frozen generalist model and a trainable specialist model run in parallel and interact asymmetrically. "an asymmetric dual-stream paradigm"
- Asymmetric Joint Attention: An attention setup where queries come from the specialist while keys/values combine features from both models, with gradients blocked to the frozen side. "employs an Asymmetric Joint Attention mechanism."
- Asymmetric Mixture-of-Transformers (AsyMoT): A fusion mechanism allowing a trainable stream to attend to a frozen stream’s representations without updating it. "Asymmetric Mixture-of-Transformers (AsyMoT) mechanism"
- Causal Self-Attention: Autoregressive attention that prevents positions from attending to future tokens, preserving temporal causality. "Through causal self-attention"
- Catastrophic Forgetting: Degradation of previously learned abilities when fine-tuning on a new task shifts the model’s parameters. "without catastrophic forgetting."
- Closed-Loop Control: Control that continuously uses current sensory/state feedback during execution. "a critical requirement for closed-loop control."
- Conditional Decoder: A generative module that produces outputs (e.g., actions) conditioned on context embeddings. "operates as a conditional decoder"
- Cross-Attention Layers: Transformer layers that condition one sequence on another by attending across streams. "via cross-attention layers."
- Diffusion Transformer (DiT): A transformer architecture used for diffusion/flow-based generative modeling of trajectories. "employs the Diffusion Transformer (DiT) architecture"
- Embodied Perception: Perception grounded in the robot’s own body and sensing context for control. "specialized for embodied perception"
- End-Effector Pose: The position and orientation of a robot arm’s tool/hand in space. "end-effector pose"
- Euler Solver: A simple numerical method for integrating ordinary differential equations step by step. "using an Euler solver"
- Flow Matching: A training objective that learns a vector field transporting noise to data along a continuous path. "via flow matching."
- Gaussian Prior: A normal distribution used as the starting noise distribution in generative sampling. "a standard Gaussian prior"
- Hemispheric Lateralization: The biological principle that different brain hemispheres specialize in different functions; used here as an architectural analogy. "the biological principle of hemispheric lateralization"
- Isomorphic VLM Pathways: Parallel VLM backbones with identical architectures used for generalist and specialist roles. "two isomorphic VLM pathways"
- Key-Value (KV) Pairs: The key and value tensors used in attention mechanisms to compute weighted combinations. "Key-Value (KV) pairs"
- Open-World Generalization: The ability to handle diverse, previously unseen tasks or concepts beyond the training distribution. "open-world generalization capabilities"
- Ordinary Differential Equation (ODE): An equation involving derivatives of a function with respect to one variable; used to generate trajectories from learned vector fields. "Ordinary Differential Equation (ODE)"
- Proprioception: Internal sensing of the robot’s own joint and body states. "embodied proprioception"
- Spatially-Grounded Conditioning: Conditioning signals that preserve spatial relationships needed for precise control. "spatially-grounded conditioning"
- State Encoder: A module (e.g., an MLP) that projects low-level robot states into the model’s embedding space. "a lightweight State Encoder "
- Stop-Gradient Operation: A mechanism that blocks gradient flow to certain tensors to prevent parameter updates. "indicates the stop-gradient operation."
- Tokenization Paradigm: The approach of discretizing continuous signals into tokens for modeling or control. "discrete tokenization paradigm"
- Transfer Learning Paradigm: Adapting a pre-trained model to a new task by fine-tuning on task-specific data. "adopt a transfer learning paradigm."
- Vector Field Regression Loss: A loss that trains a model to predict target velocities (vector fields) along a generative path. "The vector field regresson loss is defined as:"
- Vision-Language-Action (VLA): Models that map visual and linguistic inputs to robot actions for control. "Vision-Language-Action (VLA) models"
- Vision-LLM (VLM): Multimodal models combining vision encoders and LLMs for visual-linguistic understanding. "Vision-LLM (VLM) backbone"
- Zero-Shot Generalization: Performing tasks without task-specific fine-tuning by leveraging learned priors. "zero-shot generalization"
Collections
Sign up for free to add this paper to one or more collections.