Memory Retention Is Not Enough to Master Memory Tasks in Reinforcement Learning
Abstract: Effective decision-making in the real world depends on memory that is both stable and adaptive: environments change over time, and agents must retain relevant information over long horizons while also updating or overwriting outdated content when circumstances shift. Existing Reinforcement Learning (RL) benchmarks and memory-augmented agents focus primarily on retention, leaving the equally critical ability of memory rewriting largely unexplored. To address this gap, we introduce a benchmark that explicitly tests continual memory updating under partial observability, i.e. the natural setting where an agent must rely on memory rather than current observations, and use it to compare recurrent, transformer-based, and structured memory architectures. Our experiments reveal that classic recurrent models, despite their simplicity, demonstrate greater flexibility and robustness in memory rewriting tasks than modern structured memories, which succeed only under narrow conditions, and transformer-based agents, which often fail beyond trivial retention cases. These findings expose a fundamental limitation of current approaches and emphasize the necessity of memory mechanisms that balance stable retention with adaptive updating. Our work highlights this overlooked challenge, introduces benchmarks to evaluate it, and offers insights for designing future RL agents with explicit and trainable forgetting mechanisms. Code: https://quartz-admirer.github.io/Memory-Rewriting/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: Is being good at remembering enough for an AI to make smart decisions in changing situations? The authors argue no. Real life changes. So an AI needs memory that can not only keep things for a long time (retention) but also replace old facts with new ones when they stop being true (rewriting). The paper introduces new test worlds that specifically check whether AI agents can update and overwrite their memories, then compares several popular AI memory systems to see which ones handle this best.
What questions did the researchers ask?
The authors translated their idea into four easy-to-understand questions:
- If a task only needs remembering (no updates), which AI memory works well?
- When the task requires updating memory over and over, which systems can actually rewrite their memory correctly?
- Can these systems generalize — that is, still work well when the task gets longer or slightly different than what they were trained on?
- When lots of updates pile up, can the system keep the most important, up-to-date information and ignore what’s outdated?
How did they test it?
To keep things fair and focused, the team built simple but powerful test environments and tried several types of AI memory models.
Two test worlds
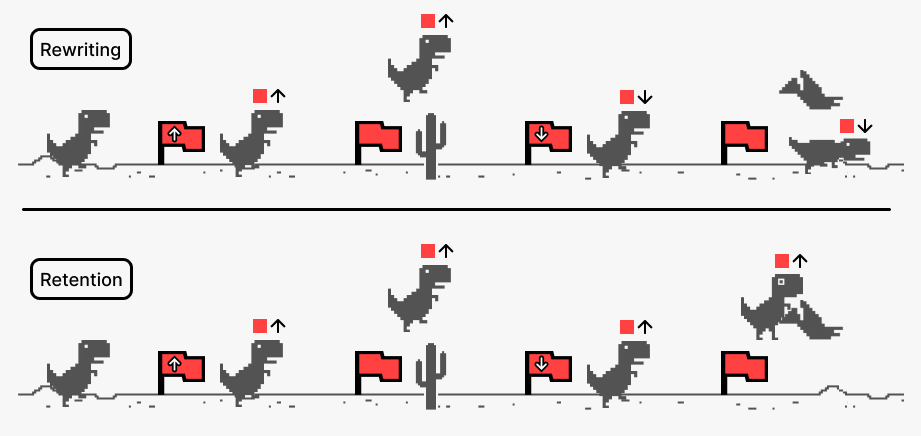
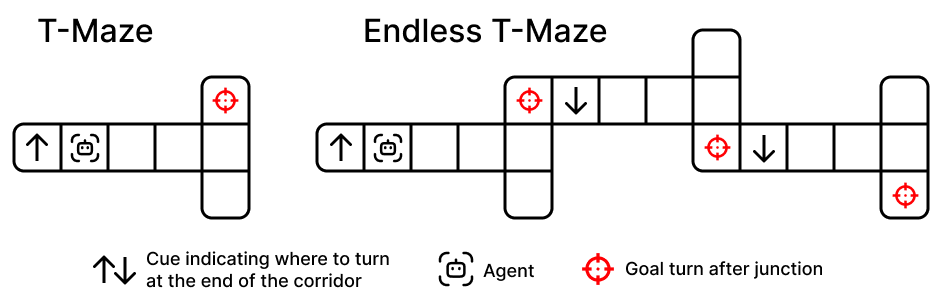
- Endless T‑Maze: Imagine walking down a hallway. At the start, you see a sign telling you to turn left or right at the end. After you turn, a new hallway starts with a new sign — which replaces the old instruction. This repeats again and again. The agent must always follow the latest sign, not any of the old ones. This directly tests memory rewriting.
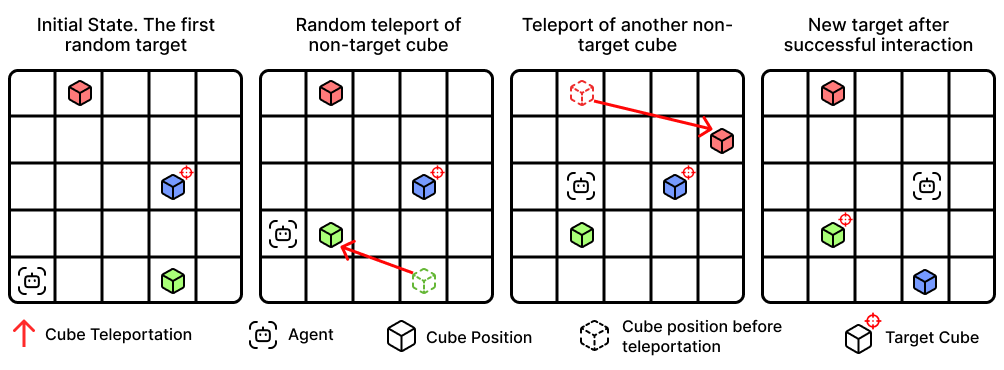
- Color‑Cubes: The agent moves on a grid to find and interact with a cube of a specific color. But here’s the twist: while the agent is moving, other cubes can “teleport” to new locations. Depending on the difficulty:
- Trivial: Only one cube and one target — basically just remember once.
- Medium: Several cubes can move, and the agent sees both new positions and colors when teleports happen.
- Extreme: Several cubes can move, but only positions are revealed after teleports — colors are hidden, so the agent has to infer which cube moved and update its internal map. This tests both rewriting and reasoning under uncertainty.
In both worlds, the agent can’t see everything it needs in the moment (this is called partial observability), so it must rely on its memory — and update it correctly when the world changes.
Types of AI memories compared
The authors compared three main families of memory mechanisms, plus a simple baseline:
- Recurrent networks (like LSTM and GRU): These have “gates,” which are like tiny valves that control what to keep, what to forget, and what to add to memory at each step. LSTM includes a special “forget gate” that can actively drop outdated information.
- Transformers (GTrXL): These use attention and a cache of past information. They’re great at looking back over long histories but don’t have a built-in, explicit “forget this now” control.
- Structured external memories (FFM, SHM):
- FFM (Fast and Forgetful Memory) uses traces that naturally fade over time — like ink that slowly fades unless refreshed.
- SHM (Stable Hadamard Memory) tries to keep updates stable using a learned matrix that tunes what gets boosted or suppressed, but it doesn’t have an explicit, learnable forget gate.
- Simple MLP (no memory): Used as a control to show what happens with no memory system under partial observability.
How they measured success
They trained agents on certain settings (for example, a hallway length and number of turns in Endless T‑Maze), then tested them on matching and different settings to see:
- Can they solve the task?
- Can they handle shorter/longer horizons and more/fewer rewrites than they trained on (interpolation and extrapolation)?
- Are they stable across random seeds and small changes?
The main score was the success rate — how often an agent completed tasks correctly.
What did they find?
Here are the key takeaways, in plain language:
- Rewriting beats retention: Many current AI memory systems are good at holding onto information (retention), but stumble when they must throw out old info and replace it with new info multiple times (rewriting). The paper shows this is a major gap in existing methods and benchmarks.
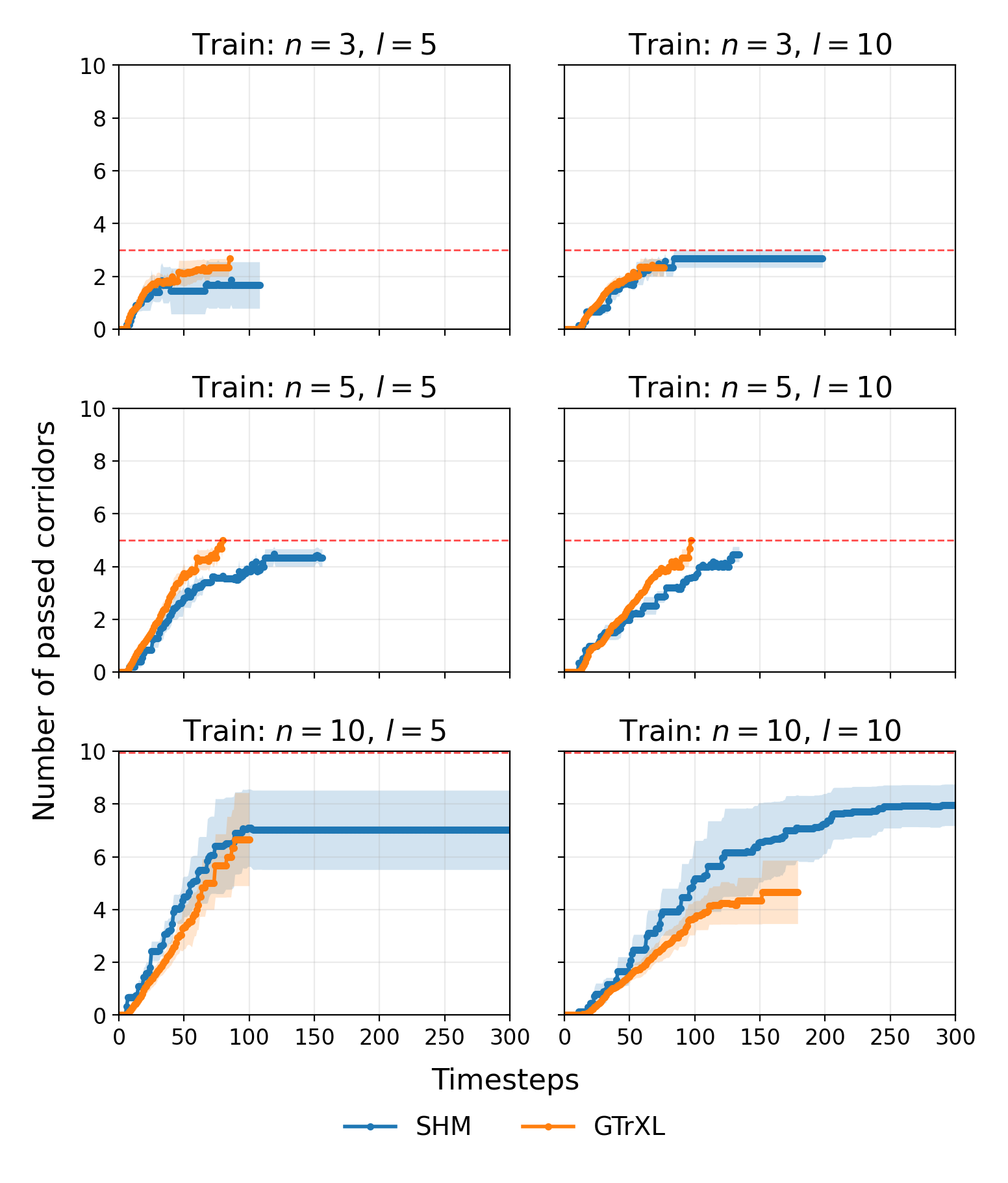
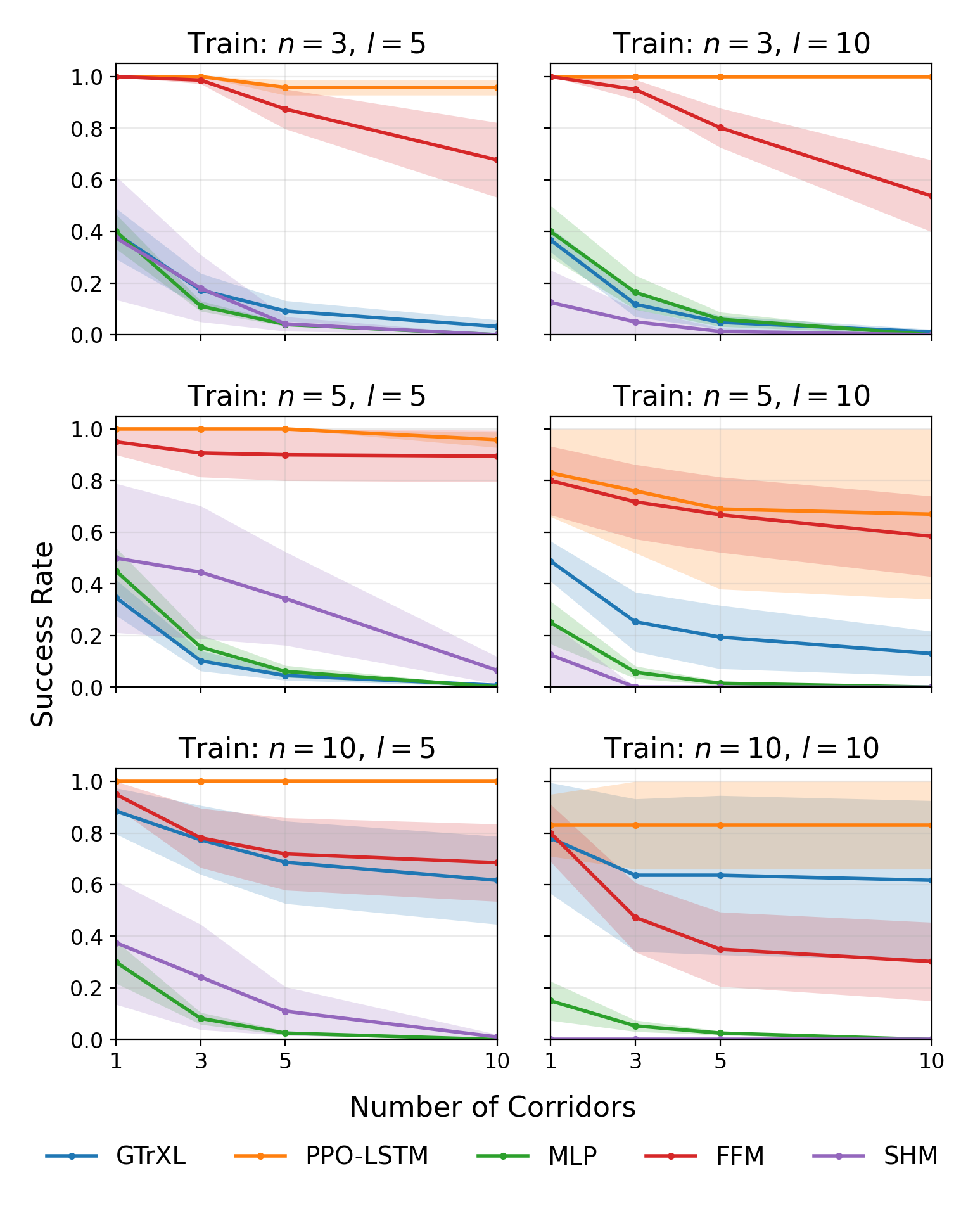
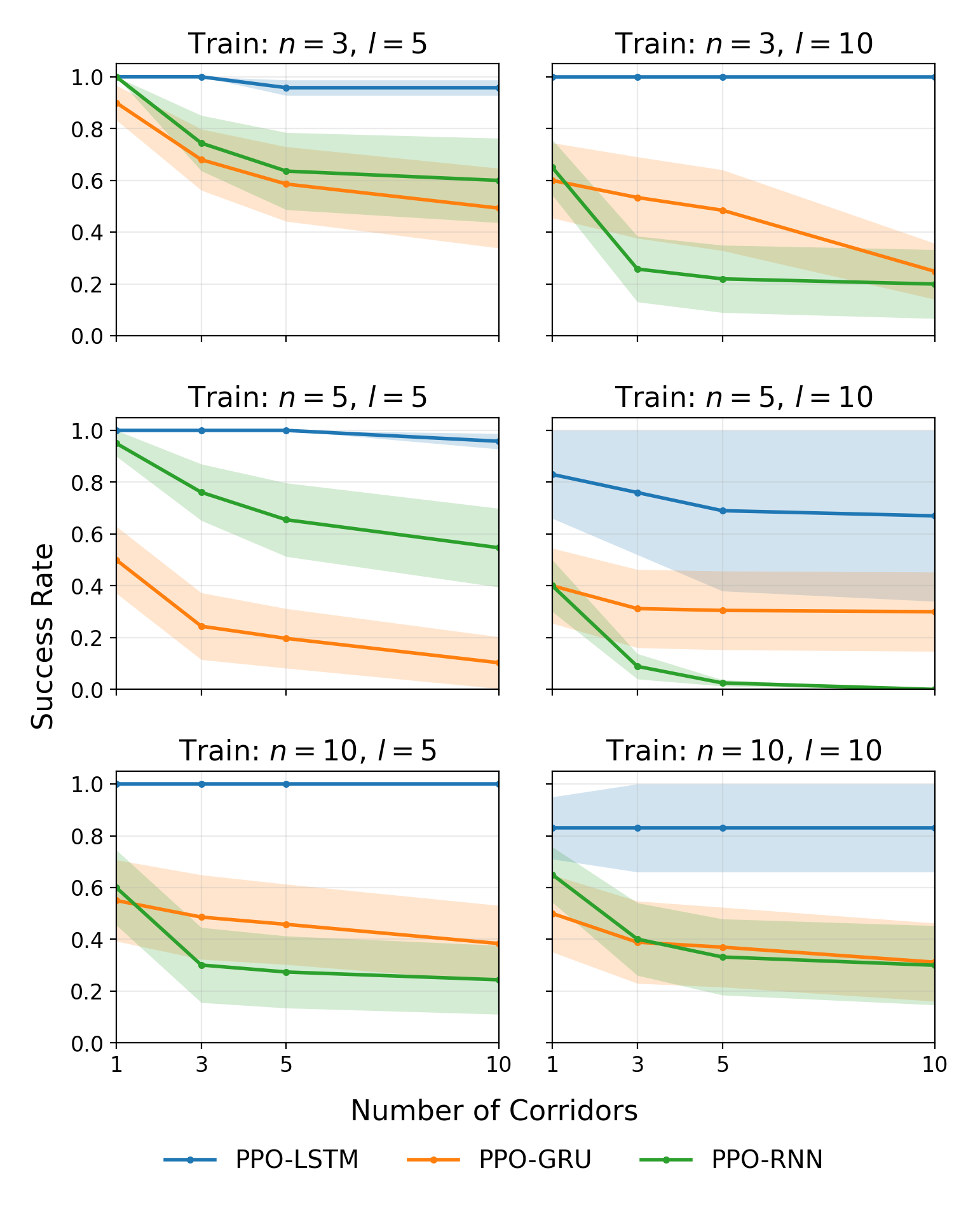
- LSTM is best at rewriting: Agents using LSTM (with learnable forget gates) consistently handled the Endless T‑Maze well, including when the number of rewrites increased and when corridor lengths varied. LSTM also generalized better to new task settings.
- Structured memories work only in predictable conditions: FFM and SHM did okay when things were stable and predictable (like fixed corridor lengths), but performance dropped sharply when timing or lengths varied (uniform/random settings). In short, they can forget in a “preset” way but struggle to adaptively forget when the pattern changes.
- Transformers struggled beyond trivial retention: GTrXL often failed when meaningful rewriting was needed, especially with sparse rewards (few signals telling the agent if it’s doing well). It did fine in easy retention cases but lacked an explicit mechanism for selective forgetting.
- Color‑Cubes exposed a harder challenge: In the Medium and Extreme versions — where multiple updates happen and the agent must keep an accurate, current map — all agents failed. This shows that simply being able to forget is not enough; agents also need to re‑rank and manage many pieces of changing information and sometimes infer hidden changes.
- Gates matter: An ablation study showed that:
- Plain RNNs (no gates) performed poorly.
- GRU (some gates) did better.
- LSTM (with a dedicated forget gate) did best.
- This strongly suggests that explicit, trainable forgetting is crucial for successful memory rewriting.
Why it matters: In the real world, acting on outdated information can cause mistakes — like following yesterday’s directions after the route changed. The best systems need to know what to keep, what to update, and when to drop old info.
Why does this matter?
- For AI to be reliable in changing environments (robots in warehouses, navigation with detours, games with shifting rules, assistive devices that adapt to people), it must not only remember but also rewrite memory smoothly and correctly.
- Many popular methods are designed and tested mostly for retention. This paper shows that approach is incomplete and can fail in realistic, dynamic settings.
- The new benchmarks (Endless T‑Maze and Color‑Cubes) give the community tools to test and develop “adaptive memory” — especially explicit, learnable forgetting mechanisms — which are essential for real-world decision-making.
Takeaway
Memory that only keeps things isn’t enough. To succeed in the real world, AI needs memory that can also update and overwrite what no longer applies — and do so repeatedly. In these tests, LSTM‑based agents, which include an explicit, learnable forget gate, handled this best. Structured memories worked in simple, predictable cases, and transformers often struggled when rewriting was key. The benchmarks and results point toward a clear design lesson: future RL agents should include explicit, trainable forgetting and be evaluated on tasks that truly require continual memory rewriting, not just long-term retention.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or left unexplored in the paper, aimed at guiding future research.
- Benchmark modality scope is narrow: rewriting is only tested with compact vector observations; it is unknown whether the conclusions hold for high-dimensional sensory inputs (pixels, audio), 3D embodied settings, or real robots where perception and occlusions are more complex.
- Color-Cubes Medium/Extreme tasks yielded zero success across all baselines; the paper does not analyze whether this reflects agent limitations, task formulation issues (e.g., excessive difficulty), insufficient training, or missing inductive biases. A systematic failure-mode analysis and difficulty scaling/curriculum are needed.
- Rewriting is conceptually defined but not operationalized with dedicated metrics. There is no quantitative measurement of “rewrite events,” update latency, correctness of updated content, or gate activation dynamics relative to cue changes.
- Limited algorithmic breadth: only PPO-based on-policy agents and a single transformer variant (GTrXL) were evaluated. Generality across off-policy (e.g., R2D2, IMPALA), model-based (e.g., Dreamer, PlaNet), sequence models (S4/RSSM/RNN-T), decision transformers, or episodic memory modules (DNC, kNN memory) remains untested.
- Transformer fairness and configuration are underexplored: context length, cache management, auxiliary losses for stabilization (e.g., predictive/self-supervised heads), reward shaping, and actor-critic design choices that mitigate sparse-reward instability were not systematically varied.
- Structured memories (FFM/SHM) may be misaligned with Uniform regimes; it is unclear whether adaptive decay schedules, observation-conditioned forgetting, or explicit learnable forget gates would restore performance. Hyperparameter sensitivity to stochastic horizons was not investigated.
- Horizon scaling is limited: Endless T-Maze corridor lengths only up to 10. How performance scales with much longer horizons, higher rewrite frequencies, and compounding updates is unknown.
- Environment generalization is only partially probed: Endless T-Maze tests interpolation/extrapolation over n and l, but Color-Cubes is fixed to one Medium/Extreme parameterization. Effects of varying grid size, number of cubes/phases, teleport probability, and train–test distribution shifts remain unexplored.
- Partial observability realism is limited in Color-Cubes: agents receive global initialization of positions/colors. Rewriting under local field-of-view, occlusions, and noisy sensing (more typical POMDPs) is not evaluated.
- No comparison to belief-state filtering baselines (e.g., particle filters, learned Bayesian filters): whether explicit filtering provides stronger rewriting than neural memory mechanisms is unanswered.
- Mechanistic interpretability is missing: LSTM/GRU gate activations are not analyzed around cue-change events; causal interventions (e.g., gate bias manipulation, clamping) were not used to validate the hypothesized role of adaptive forgetting.
- Training budget, sample efficiency, and stability are not reported in detail (e.g., steps to convergence, compute, sensitivity to seeds), making it hard to separate architectural limitations from optimization constraints.
- Trade-off between memory stability and plasticity is not quantified: there is no principled measure or regularization to tune retention vs. rewriting (e.g., gating priors, neuromodulatory signals, meta-learned decay).
- Multi-agent and interactive non-stationary settings are absent: rewriting in the presence of other agents, adversarial changes, or strategic deception is not studied.
- Continual learning across episodes/tasks is unaddressed: how agents rewrite memory without catastrophic forgetting at task boundaries (lifelong learning) remains open.
- Robustness to noisy or incorrect updates is unassessed: agents’ ability to recover from erroneous rewrites, filter spurious cues, and maintain reliability under noise is unknown.
- Evaluation metrics are narrow (success rate only): learning speed, sample efficiency, asymptotic vs. transient performance, and calibration of confidence in memory updates are not reported.
- Auxiliary objectives to facilitate rewriting were not explored: predictive reconstruction of cues, contrastive memory alignment, change-point detection, or supervised memory-update targets may improve performance but were not tested.
- Real-world applicability is speculative: no demonstrations on robotic or autonomous systems where rewriting is critical (e.g., dynamic mapping, task switching) to validate external validity.
- Benchmark standardization lacks difficulty indices: the environments do not expose standardized measures of rewrite frequency, temporal uncertainty, or interference to enable consistent cross-study comparisons.
- Unexpected PPO-LSTM underperformance on Trivial Color-Cubes (0.52±0.10 vs. 1.00 for others) is not investigated; potential implementation or representational mismatches should be diagnosed.
- Uniform regime confounds are not disentangled: the effect of variable horizon length vs. variable rewrite timing is not isolated; variants that independently control rewrite frequency and horizon could clarify failure causes.
- Alternative memory mechanisms with explicit forgetting are untested: learnable decay kernels, attention-with-decay, neuromodulation, or hybrid internal–external memory architectures could directly embody the proposed design principles.
- Sparse-reward sensitivity in transformers is asserted but not systematically studied: controlled manipulations of reward density, advantage estimation, or bootstrapping strategies are needed to validate and mitigate this failure mode.
- Credit assignment over long-range rewrites is not examined: whether agents can assign credit to earlier rewrites for later success (and techniques to improve it) remains an open question.
Practical Applications
Overview
This paper introduces two diagnostic benchmarks—Endless T-Maze and Color-Cubes—to explicitly evaluate “memory rewriting” (adaptive forgetting and updating) in reinforcement learning (RL) under partial observability. Empirically, recurrent models with explicit learnable forget gates (e.g., LSTM) outperform transformer-based and structured-memory agents on rewriting tasks, especially in stochastic regimes. Structured memories (FFM, SHM) succeed mainly in predictable settings; transformers struggle with sparse rewards and lack explicit forgetting. The ablations highlight the centrality of gating and adaptive forgetting.
Below are actionable applications that leverage these findings, methods, and innovations. Each item names likely sectors, suggests tools/workflows, and notes assumptions that affect feasibility.
Immediate Applications
These can be deployed now with available methods (e.g., LSTM-based policies, provided benchmark code, standard RL stacks).
- Robotics and autonomy (industry)
- Adaptive navigation and manipulation in dynamic spaces (e.g., warehouses, hospitals, retail): deploy LSTM-based RL policies with forget gates to update internal maps when objects, signage, or human flows change.
- Tools/workflows: integrate Endless T-Maze and Color-Cubes into robot QA; add “rewrite frequency curricula” to training; incorporate dense reward shaping to stabilize learning where needed.
- Assumptions/dependencies: reliable simulation-to-real transfer; access to partial observability simulators; safety envelopes for online adaptation.
- Field robots and drones (agriculture, inspection): use gate-based recurrent policies to handle occlusions, moving obstacles, and intermittent sensing.
- Tools/workflows: POMDP training with stochastic event injection (teleports/relocations → moving assets); CI tests for “rewrite competence.”
- Assumptions/dependencies: onboard compute budgets for RNN policies; sensor noise models.
- Software and ML engineering (software/AI tooling)
- Benchmarking and CI for “memory rewriting readiness”: adopt the provided benchmark suite as a standard test in RL model validation pipelines.
- Tools/products: “Memory Rewriting Score” dashboard; Gymnasium-compatible environments; trainer plugins that vary rewrite frequency and horizon.
- Assumptions/dependencies: consistent seeding and logging; support in existing training frameworks (PPO-LSTM, PPO-GRU available in most libs).
- Architecture selection guidelines: prefer LSTM/GRU over cache-only transformers for dynamic POMDPs; require explicit forgetting mechanisms in design docs.
- Tools/workflows: decision checklists; ablation templates (RNN vs. GRU vs. LSTM) per task.
- Finance (trading, risk)
- Regime-shift–aware agents: apply explicit forgetting (LSTM gates) in sequential decision systems to de-emphasize stale signals during market regime changes.
- Tools/workflows: “rewrite pressure” hyperparameters controlling how quickly to downweight old features; backtests where synthetic regime shifts emulate Color-Cubes teleports.
- Assumptions/dependencies: careful validation to avoid overfitting; guardrails for catastrophic forgetting of slow-moving fundamentals.
- Healthcare operations and monitoring
- Alerting and triage models that update beliefs as new measurements arrive (e.g., vitals, labs): adopt gated recurrence to prevent acting on outdated states.
- Tools/workflows: temporal QA suites with synthetic “state-change” events; gated memory ablations in MIMIC-style datasets.
- Assumptions/dependencies: clinical validation; explainability requirements; integration with existing EHR pipelines.
- Education technology
- Student modeling and adaptive practice: use LSTM-style memory to rewrite prior estimates of mastery as new evidence arrives, avoiding stale recommendations.
- Tools/workflows: curriculum with stochastic concept drift; “rewrite audit” to verify responsiveness to recent performance.
- Assumptions/dependencies: privacy-preserving deployment; alignment with pedagogy and fairness constraints.
- Smart homes and consumer assistants (daily life)
- Task-following that adapts to changing instructions or environments (e.g., rearranged furniture, updated routines): prioritize LSTM policies in embodied assistants.
- Tools/workflows: home-simulation tests with frequent layout changes; metrics for response latency to instruction updates.
- Assumptions/dependencies: safe fallback behaviors; minimal compute footprint.
- MLOps and AI governance (cross-sector)
- Model validation for partial observability: add rewriting benchmarks to release gates for RL agents deployed in dynamic settings (e.g., robotics, online control).
- Tools/workflows: “Rewrite-Stability Score” across fixed vs. stochastic regimes; drift monitoring tied to agent memory states.
- Assumptions/dependencies: observability of internal memory (logging hooks); reproducible evaluation harnesses.
Long-Term Applications
These require further research, scaling, or development (e.g., new architectures with trainable forgetting, standardization, real-world certification).
- Next-generation memory architectures (academia, software, robotics)
- Transformers with explicit, trainable forgetting: develop attention mechanisms that incorporate learnable gating or decay for cached states.
- Potential products: “ForgetFormer” layers; hybrid LSTM–Transformer controllers; structured memory with adaptive prioritization.
- Dependencies: algorithmic advances for stability under sparse rewards; efficient memory introspection tools.
- Structured memory with prioritization and reinstatement: extend FFM/SHM to support selective overwriting, re-ranking, and recovery of previously irrelevant information (toward solving Color-Cubes Extreme).
- Dependencies: differentiable data structures; credit assignment across re-ranking events.
- Safety, testing, and certification standards (policy, industry consortia)
- Rewriting-capability certification for autonomous systems: define standard tests (e.g., Endless T-Maze variants) for public procurement and regulatory approval.
- Tools/products: conformance test suites; sector-specific thresholds (e.g., minimum “rewrite success rate” under stochasticity).
- Dependencies: multi-stakeholder consensus; mapping benchmarks to risk categories.
- Continual and embodied learning at scale (robotics, manufacturing, logistics)
- Lifelong agents that maintain and rewrite world models during deployment, adapting to layout/asset changes without retraining from scratch.
- Workflows: scheduled “re-anchoring” cycles; online RL with safety constraints; sandboxed adaptation phases.
- Dependencies: robust sim-to-real; reliable anomaly detection; safeguards against catastrophic forgetting.
- Healthcare decision support and digital twins
- Patient-level memory rewriting in digital twins, enabling rapid incorporation of new diagnostics and deprecation of outdated hypotheses.
- Products: clinically validated controllers with interpretable memory gates; tools to audit what was “forgotten” and why.
- Dependencies: regulatory approval; interpretability research; clinical trials.
- Intelligent transportation and navigation (mobility, public infrastructure)
- Agents that adapt to temporary detours, signage changes, and sensor occlusions in real time (e.g., autonomous shuttles, last-mile robots).
- Products: city-scale simulators with “rewrite stressors” (dynamic closures); standardized benchmarks for partial observability.
- Dependencies: V2X data sharing; policy frameworks for dynamic routing authority.
- Financial risk and compliance
- Auditable forgetting in algorithmic decision systems: formal frameworks showing how outdated data cease to influence decisions (useful for privacy-by-design and “right to be forgotten” analogs in models).
- Products: memory-state audit logs; compliance reports quantifying decay of historical influence.
- Dependencies: legal alignment; standardized interpretability metrics.
- Education and workforce training
- Tutors that detect concept drift in learners and rewrite mastery models; workforce simulators that adapt to changing procedures and tools.
- Products: adaptive curricula with controlled “drift injections”; dashboards for instructor oversight of model updates.
- Dependencies: longitudinal efficacy studies; fairness and bias monitoring under frequent updates.
- Cross-cutting research infrastructure
- Leaderboards and community challenges on memory rewriting (especially Color-Cubes Extreme–style tasks involving incomplete updates and inference).
- Products: open benchmarks, data generators, and scoring libraries; visualization tools for memory evolution and rewrite events.
- Dependencies: shared evaluation protocols; compute sponsorship for large-scale comparisons.
Key Assumptions and Dependencies (common across applications)
- Explicit forgetting is implementable and tunable: availability of gated recurrent layers or future transformer variants with forgetting.
- Partial observability is a faithful abstraction: tasks can be modeled as POMDPs with realistic stochasticity (analogous to “teleports” as dynamic changes).
- Reward design and stability: sparse-reward fragility (noted for transformers) is mitigated via reward shaping, auxiliary losses, or offline pretraining.
- Safety and interpretability: deployment requires introspection of memory states, audits of what was updated/forgotten, and guardrails against catastrophic forgetting.
- Compute and latency constraints: on-device or real-time settings may favor compact gated recurrent models over heavier attention architectures until efficient forgetting-enabled transformers mature.
By operationalizing these benchmarks and design insights—especially the necessity of explicit, learnable forgetting—teams can immediately improve robustness in dynamic, partially observable domains and chart a research agenda toward general-purpose agents that maintain, rewrite, and prioritize memory reliably.
Glossary
- Adaptive forgetting: A learnable mechanism that enables an agent to selectively discard outdated information based on context. "highlighting the effectiveness of explicit, adaptive forgetting (e.g., learnable forget gates) over cached-state or rigidly structured memories"
- Bayesian filtering: A probabilistic method for updating beliefs about hidden states from observations and actions; often computationally intractable in POMDPs. "Because exact Bayesian filtering~\citep{ahmadi2020control} is typically intractable, agents approximate it using a learned memory state"
- Cached hidden states: Stored transformer activations from prior timesteps used to provide extended temporal context during decision-making. "It preserves long-range temporal context through cached hidden states, enabling policies to leverage information beyond the immediate observation window."
- Color-Cubes: A grid-world benchmark where agents must track and update cube color–position mappings under partial observability with stochastic teleportations. "Color-Cubes (Figure~\ref{fig:color-cube}) is a grid-based environment that evaluates an agent's ability to maintain, detect, and update internal representations under partial observability."
- Correlation horizons: Temporal distances between informative events and dependent decisions that quantify memory demands in partially observable environments. "A partially observable environment can be described by a set of correlation horizons , where each measures the temporal gap between an informative event , which begins at time and lasts for steps, and the later decision made at time that depends on it"
- Discount factor: A scalar that down-weights future rewards to define a preference for immediacy in RL. " the discount factor"
- Discounted return: The expected sum of future rewards weighted by powers of the discount factor. "with the objective of maximizing the expected discounted return ."
- Endless T-Maze: A continual cue-based navigation benchmark where each new corridor cue overrides the previous one, demanding memory rewriting. "Endless T-Maze consists of sequential corridors where each new cue invalidates the previous one, requiring the agent to actively overwrite outdated instructions."
- Extrapolation: Evaluating an agent on longer horizons or more frequent memory updates than seen during training. "and extrapolation (longer corridors or more rewrites)."
- Fast and Forgetful Memory (FFM): A structured memory architecture that uses exponentially decaying traces to gradually forget outdated information. "The Fast and Forgetful Memory (FFM,~\citep{morad2023reinforcementlearningfastforgetful}) models memory as a set of exponentially decaying traces, enabling gradual forgetting of outdated information inspired by computational psychology."
- Gated Recurrent Unit (GRU): A recurrent neural network variant with reset and update gates that control information flow without a separate cell state. "Also PPO-GRU is an intermediate option in which the architecture is simplified compared to LSTM: the cell and hidden states are combined, and the number of gates is reduced from three (forget, input, output) to two (reset and update)."
- Gated Transformer-XL (GTrXL): A transformer architecture adapted for RL that introduces gating and identity-map reordering to improve training stability. "The Gated Transformer-XL (GTrXL)~\citep{parisotto2020stabilizing} extends the Transformer-XL architecture (TrXL)~\citep{dai2019transformerxlattentivelanguagemodels} for RL by introducing identity-map reordering and gating mechanisms that improve training stability."
- Gating mechanisms: Components in recurrent/transformer models that regulate what information is retained, updated, or forgotten at each timestep. "The gating mechanisms of the LSTM regulate what information is preserved or forgotten at each step, providing a learnable and adaptive form of memory that serves as a strong baseline for studying sequential decision-making in RL."
- Identity-map reordering: A transformer modification that reorders residual connections to stabilize training in long-horizon RL. "introducing identity-map reordering and gating mechanisms that improve training stability."
- Initial-state distribution: The probability distribution over starting states in an MDP/POMDP. " the initial-state distribution"
- Latent state: The unobserved, underlying environment state that cannot be directly measured from immediate observations. "and the latent state cannot be inferred from a single frame"
- Learnable forget gates: Trainable gating components (e.g., in LSTMs) that control how much of the past memory is forgotten. "explicit, adaptive forgetting (e.g., learnable forget gates)"
- Long Short-Term Memory (LSTM): A gated recurrent neural network with input, output, and forget gates that enables long-range dependency modeling. "Long Short-Term Memory (LSTM,~\citep{Hochreiter1997LongSM}) units, allowing agents to maintain internal states that summarize recent experience."
- Markov Decision Process (MDP): A formal framework for fully observable decision-making specified by states, actions, transitions, rewards, initial distribution, and discount factor. "A fully observable decision-making problem can be formalized as a Markov Decision Process (MDP), "
- Markov property: The assumption that optimal decisions depend only on the current state, not the full history. "The Markov property implies that the optimal policy depends only on the current state, "
- Memory improvability: The performance gain attributable to adding memory to agents, used to assess memory utility across tasks. "The POBAX benchmark~\citep{tao2025benchmarking} evaluates memory in partially observable settings through memory improvability -- the benefit of adding memory to agents -- across diverse tasks that require recalling information over time."
- Memory rewriting: The selective process of updating, overwriting, or discarding memory contents to keep them decision-relevant as conditions change. "we isolate and systematically investigate memory rewriting in RL through four diagnostic tasks that enforce continual memory updates under partial observability."
- Observation kernel: The conditional distribution that maps hidden states and actions to observable outputs in a POMDP. "and observation kernel , defining the tuple"
- Partially Observable Markov Decision Process (POMDP): An extension of MDPs where the true state is hidden and decisions depend on histories and a learned memory state. "A Partially Observable MDP (POMDP) extends the MDP by introducing an observation space and observation kernel , defining the tuple "
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that uses clipped objectives for stable updates. "Proximal Policy Optimization (PPO,~\citep{schulman2017proximalpolicyoptimizationalgorithms})"
- PPO-LSTM: A PPO-based agent architecture that augments the policy/value networks with LSTM layers to maintain internal memory. "The PPO-LSTM~\citep{schulman2017proximalpolicyoptimizationalgorithms} extends Proximal Policy Optimization (PPO,~\citep{schulman2017proximalpolicyoptimizationalgorithms}) with Long Short-Term Memory (LSTM,~\citep{Hochreiter1997LongSM}) units"
- Stable Hadamard Memory (SHM): A structured memory architecture with a learned calibration matrix that adaptively reinforces or suppresses components during updates. "The Stable Hadamard Memory (SHM,~\citep{le2024stablehadamardmemoryrevitalizing}) extends this idea by learning a dynamic calibration matrix that adaptively regulates which components of memory are reinforced or suppressed, enhancing stability during online updates."
- Structured external memory: Memory systems external to core networks that store and update information in interpretable or engineered formats. "recent work has introduced structured external memory systems."
- Transformer-XL (TrXL): A transformer variant with segment-level recurrence and memories used as context for long-range dependencies. "extends the Transformer-XL architecture (TrXL)~\citep{dai2019transformerxlattentivelanguagemodels}"
- Transition kernel: The conditional distribution over next states given the current state and action in an MDP/POMDP. " is the transition kernel"
- Uniform sampling regime: A configuration where environment parameters (e.g., corridor lengths) are drawn from a uniform distribution to induce variability. "Uniform, where lengths are sampled from a uniform distribution , introducing stochastic variation in cue timing and memory horizon."
Collections
Sign up for free to add this paper to one or more collections.