Memorization Dynamics in Knowledge Distillation for Language Models
Abstract: Knowledge Distillation (KD) is increasingly adopted to transfer capabilities from LLMs to smaller ones, offering significant improvements in efficiency and utility while often surpassing standard fine-tuning. Beyond performance, KD is also explored as a privacy-preserving mechanism to mitigate the risk of training data leakage. While training data memorization has been extensively studied in standard pre-training and fine-tuning settings, its dynamics in a knowledge distillation setup remain poorly understood. In this work, we study memorization across the KD pipeline using three LLM families (Pythia, OLMo-2, Qwen-3) and three datasets (FineWeb, Wikitext, Nemotron-CC-v2). We find: (1) distilled models memorize significantly less training data than standard fine-tuning (reducing memorization by more than 50%); (2) some examples are inherently easier to memorize and account for a large fraction of memorization during distillation (over ~95%); (3) student memorization is predictable prior to distillation using features based on zlib entropy, KL divergence, and perplexity; and (4) while soft and hard distillation have similar overall memorization rates, hard distillation poses a greater risk: it inherits $2.7\times$ more teacher-specific examples than soft distillation. Overall, we demonstrate that distillation can provide both improved generalization and reduced memorization risks compared to standard fine-tuning.
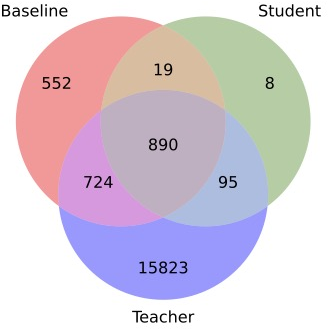
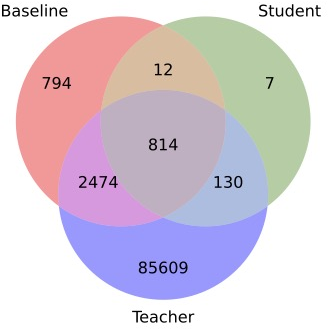
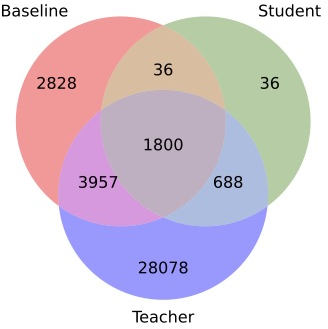

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how “knowledge distillation” affects what LLMs remember from their training data. Knowledge distillation is a way to train a smaller “student” model to learn from a bigger “teacher” model. The authors wanted to know: do student models trained this way memorize less of their training text, and can we predict and prevent that memorization?
What questions did the researchers ask?
- Does a distilled student memorize less training data than a similar model trained the usual way?
- Which kinds of examples are most likely to be memorized?
- Can we predict which training examples the student would memorize before we even start distillation?
- What’s the difference between two styles of distillation (“soft” vs. “hard”) in terms of memorization?
How did they study it?
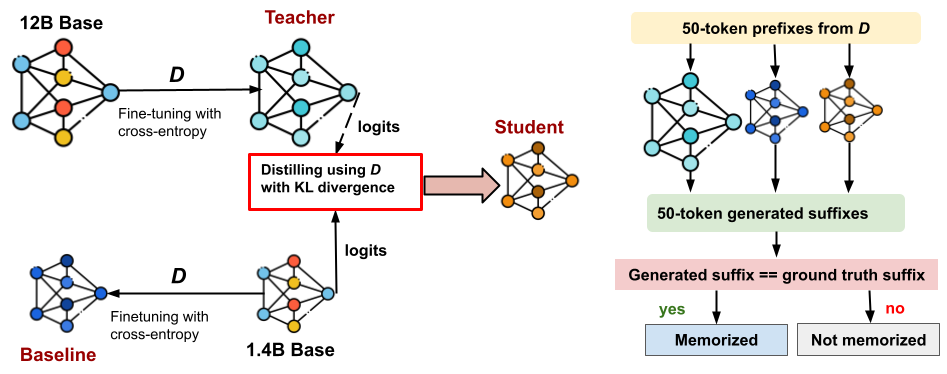
They compared three kinds of models that were all trained on the same dataset:
- Teacher: a large model (for example, Pythia 12B) fine-tuned in the standard way.
- Baseline: a smaller model (for example, Pythia 1.4B) fine-tuned in the standard way, without a teacher.
- Student: the same smaller model trained by distillation from the teacher.
Here’s what those terms mean in everyday language:
- Fine-tuning with cross-entropy: Think of grading the model strictly on whether it picks the exact correct next word. If it’s wrong, it’s penalized a lot; if it’s right, it’s rewarded. This can pressure smaller models to “force” the right answer even when they’re unsure.
- Distillation with KL divergence (“soft” distillation): Instead of grading only right vs. wrong, the teacher shares how confident it is across all possible next words. The student learns to match that pattern of confidence. This acts more like learning a teacher’s “style” rather than copying exact answers.
- Logits: The model’s raw scores about which word comes next, before turning those scores into probabilities.
- Temperature: A knob that makes the teacher’s confidence “softer” or “sharper.” Higher temperature softens the confidence, like blurring a picture.
- Tokens: Small chunks of text (a word or part of a word).
- Perplexity: A measure of how “confused” a model is; lower perplexity means the model is more certain.
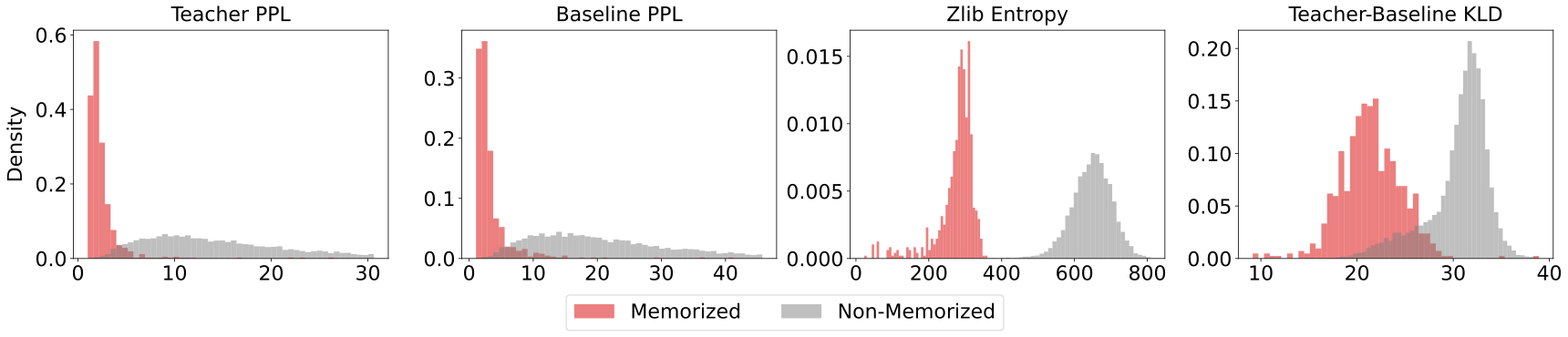
- Entropy (and zlib entropy): A measure of how predictable text is. Low entropy means the text has repeating patterns or is easy to compress—like “ha ha ha ha”—which models find easier to memorize.
- Memorization test: They showed each model the first 50 tokens from a training example and checked if the model’s next 50 tokens matched exactly what was in the training data. If it matched perfectly, that example was considered memorized.
They ran these tests across different model families (Pythia, OLMo-2, Qwen-3) and different datasets (FineWeb, WikiText, and a synthetic dataset), and repeated training with different random seeds to check consistency.
What did they find and why does it matter?
Here are the main takeaways:
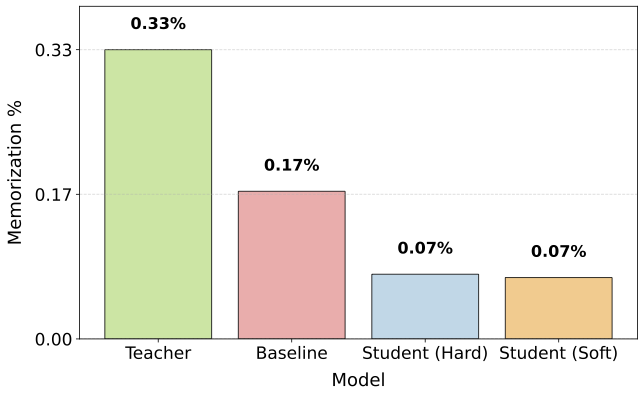
- Distillation reduces memorization a lot, while improving quality. The distilled student memorized over 50% less than the baseline trained the usual way, and still performed better on validation metrics. In short: smaller, better, and less likely to repeat training text.
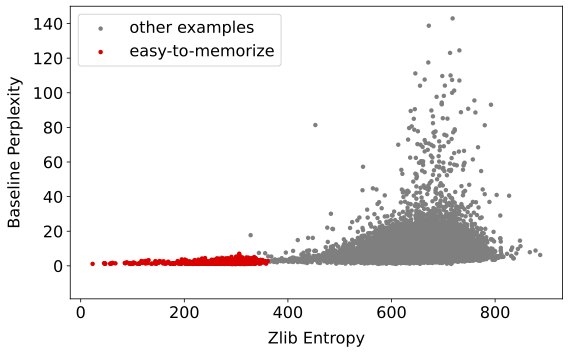
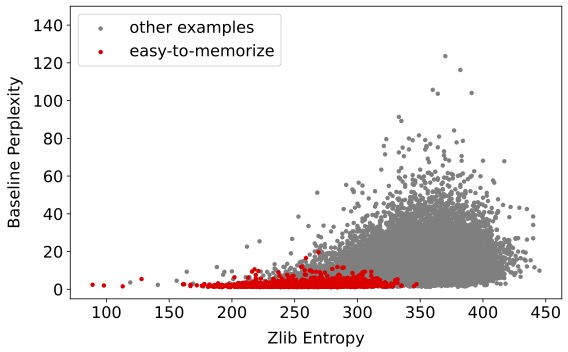
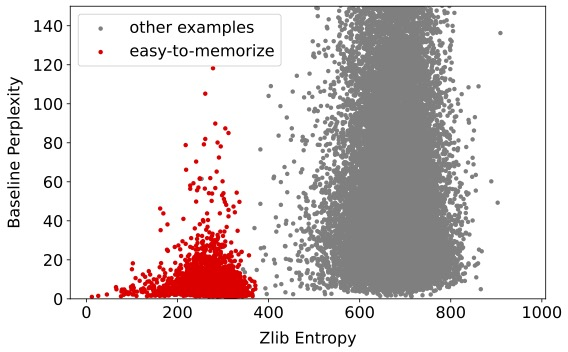
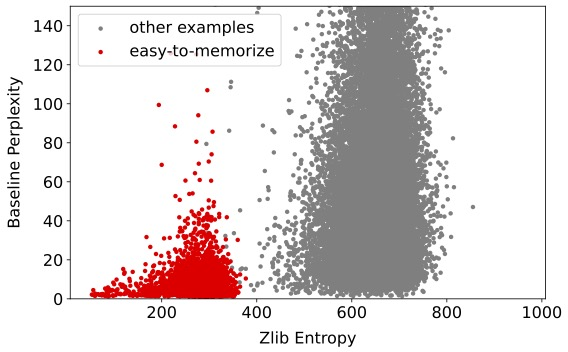
- Most memorization comes from “easy-to-memorize” examples. These are texts with low entropy (they’re highly predictable or compressible). Students mostly memorize this small set of easy examples, and avoid memorizing harder, more unique texts.
- You can predict memorization before training. By looking at simple features—like zlib entropy (how compressible the text is), the teacher’s and baseline’s perplexity (how confused they are), and how different the teacher and baseline are (KL divergence)—they built a simple classifier that almost perfectly predicted which examples the student would memorize. When they removed those risky examples before distillation, memorization dropped by about 99.8%.
- Why distillation helps: It acts like a regularizer. Standard fine-tuning pushes a small model to be very confident on examples even when it’s unsure, which can “force” memorization. Distillation lets the student keep some uncertainty on hard examples, so it doesn’t overfit and repeat them.
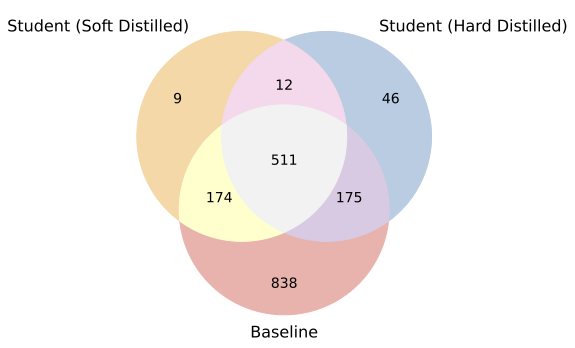
- Soft vs. hard distillation: Both have similarly low overall memorization, and they memorize many of the same examples. But “hard” distillation (training on the teacher’s generated text) inherited about 2.7 times more teacher-specific memorized examples than “soft” distillation. So hard distillation carries a slightly higher privacy risk.
Why does distillation reduce memorization?
Think of standard fine-tuning as telling a small model, “Always pick the exact right next word,” even when the model doesn’t really understand. That pressure can make the model just memorize and repeat pieces of the training data.
Distillation is more like the teacher saying, “Here’s how confident I am about each possible next word.” The student learns this smoother, realistic confidence pattern. On hard, uncertain examples, the student isn’t forced to pretend it’s sure. That lowers overfitting and memorization.
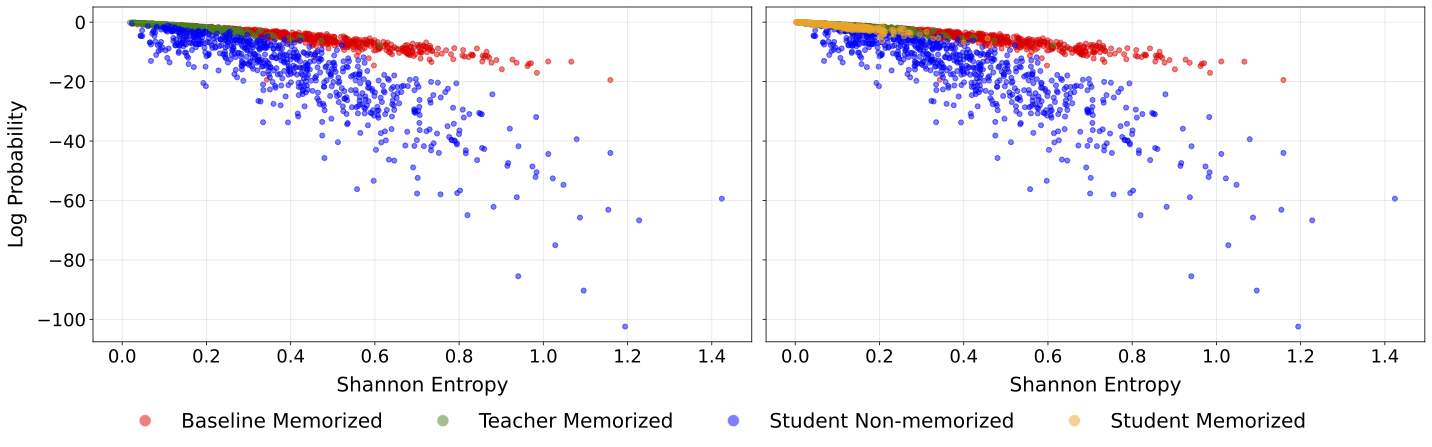
The paper shows this by plotting, for many examples, how confident each model is and how uncertain the text is:
- Teacher: high confidence on low-entropy (easy) examples.
- Baseline: high confidence even on higher-entropy (hard) examples—classic overfitting.
- Student: lower confidence on hard examples—avoids memorization—and high confidence only on truly easy examples.
What does this mean?
- Better privacy: Distilled students repeat less of their training data, which reduces the risk of sensitive information leaking.
- Better performance with smaller models: You can get high-quality models that are faster and cheaper to run, without increasing memorization.
- Practical safety step: Teams can scan and remove “high-risk” training examples before distillation. This saves compute and drastically lowers memorization.
- Caution with hard distillation: If you only have access to the teacher’s outputs (not its full confidence scores), hard distillation still works well, but it may inherit more of the teacher’s specific memorized items. Soft distillation is safer when possible.
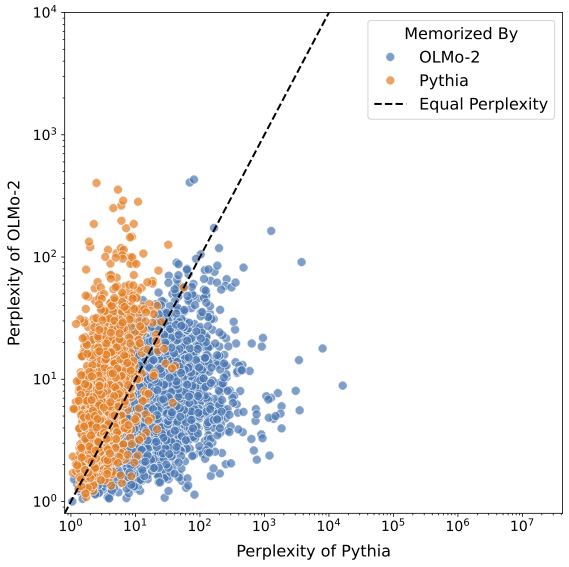
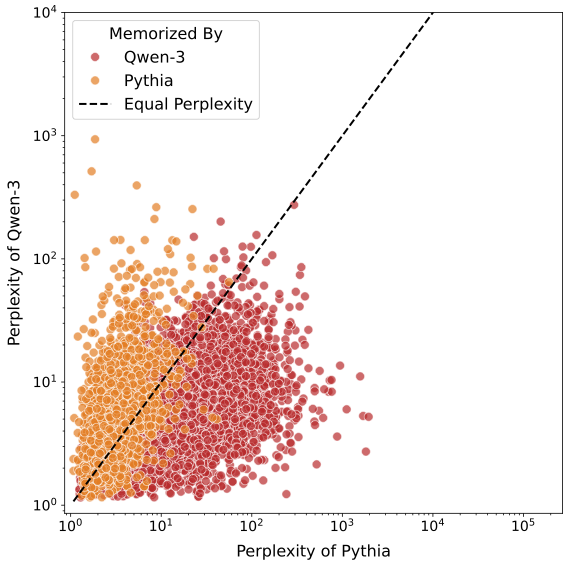
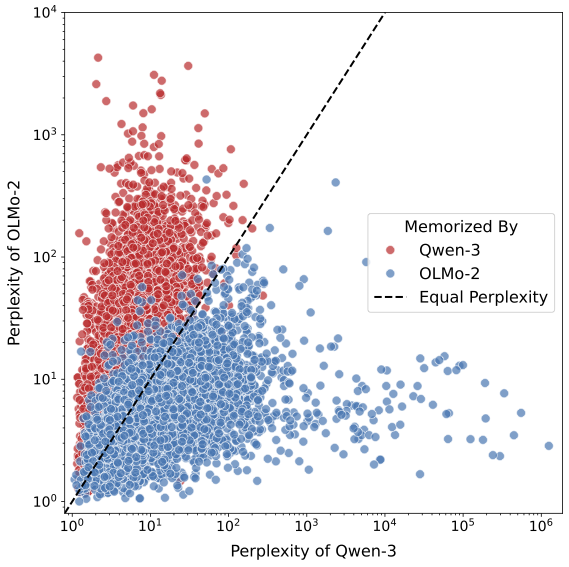
- Architecture matters: Different model families tend to memorize different easy examples because of their design choices. So audits should be done per model family, not assumed to transfer across families.
Overall, the paper shows that knowledge distillation can make LLMs both more useful and more careful, learning general patterns from the teacher while avoiding simply memorizing and repeating the training data.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item is framed to be actionable for future research.
- Memorization metric scope: The study uses “discoverable memorization” defined as exact 50-token suffix match under greedy decoding. It does not evaluate near-verbatim regurgitation, paraphrased recall, longer or shorter suffixes, variable prefix lengths, beam search or sampling-based decoding, nor probabilistic extraction metrics (e.g., probabilistic extraction rates or edit distance thresholds).
- Attack evaluations: No empirical membership inference, exposure or data extraction attacks are run on distilled vs. baseline students. It remains unknown whether distillation reduces (or shifts) vulnerability under standard black-box and white-box attack frameworks.
- Privacy content analysis: The paper does not characterize the semantic nature of memorized content (e.g., personal data, copyrighted text, sensitive domains). It is unclear if distillation preferentially suppresses PII/copyright content or merely lower-entropy segments without privacy significance.
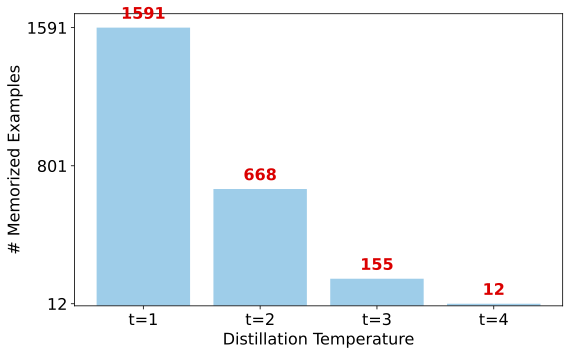
- Utility–privacy trade-offs for temperature: While increasing KL temperature reduces memorization, the utility trade-off (across diverse benchmarks and tasks) and optimal temperature scheduling are not mapped. Robustness of the temperature–memorization relationship across architectures and datasets remains unexplored.
- Distillation objective variants: Only forward KL is studied. The impact of reverse KL, Jensen–Shannon, temperature annealing schedules, on-policy distillation, and other objectives (e.g., MiniLLM, GKD) on memorization and utility is not evaluated.
- Regularization baselines: The paper attributes “forced memorization” to cross-entropy vs. KD soft targets but does not compare against standard regularizers (label smoothing, mixup, confidence penalties, entropy regularization) under the same compute to isolate KD’s unique effect.
- Hard distillation design choices: Hard distillation uses teacher greedy outputs. The effects of sampling (top-k/p), higher teacher temperatures, diversity-promoting decoding, and sequence filtering on memorization inheritance are not studied.
- Mitigations for hard distillation: Beyond noting increased inheritance of teacher-specific “difficult” examples, the paper does not test mitigation strategies for hard distillation (e.g., confidence thresholds, entropy-aware filtering, de-duplication of teacher outputs, sequence rejection policies).
- Scaling laws: Memorization dynamics are assessed at a few fixed sizes. How memorization reduction scales with student size, teacher–student gap, and compute budget is not characterized via scaling law experiments.
- Compute and training-time confounds: Baseline and student are trained to different stopping criteria (student trained until outperforming baseline) and the teacher is trained for fewer epochs. A controlled study with matched epochs, matched validation loss targets, and fixed compute would clarify whether differences stem from objective vs. training duration.
- Dataset breadth: Results focus on three datasets (two natural, one synthetic). Generalization to code, conversational data, multilingual corpora, higher-noise web scrapes, and domain-specific datasets (medical, legal) is not tested.
- Duplication analysis: FineWeb is claimed to lack sequence-level duplicates, but near-duplicates, substring duplication, and cross-document overlaps are not quantified. The interaction between various duplication types and KD memorization is unknown.
- Tokenization dependence: zlib entropy is computed on detokenized text but remains tokenizer-dependent. The robustness of entropy-based predictions when teacher and student use different tokenizers (and vocabularies) needs systematic assessment.
- Cross-architecture “easy examples”: The paper observes zero overlap of memorized examples across families despite similar entropy profiles, attributing it to inductive biases. There is no causal analysis isolating tokenizer, attention patterns, pretraining data differences, or positional encodings to explain the selection mechanism.
- Classifier practicality: The memorization classifier uses teacher/baseline perplexities and KL between them. Many real-world settings lack baseline access or teacher logits. Variants that work with only teacher black-box APIs (no logits), only student-inference features, or purely data-intrinsic features are not explored.
- Classifier training dependency: The classifier is trained using student labels (post hoc). It is unclear whether a classifier trained on one teacher–student pair generalizes to new pairs/datasets without first training a student to obtain labels.
- Pre-removal utility impact: Removing predicted-to-be-memorized examples reduces memorization drastically but the paper does not report the impact on downstream task performance, calibration, or generalization. The robustness of utility under aggressive data filtering needs measurement.
- Memorization content shifts after filtering: Removing high-risk examples led to four new memorized examples. There is no analysis of what characteristics these “replacement” memorized samples have, whether they become more privacy-sensitive, and how to prevent shift-induced new memorization.
- Long-context behavior: Experiments use sequences of length 256 with 50-token suffix evaluation. Memorization dynamics for longer contexts, varying prefix/suffix lengths, and document-level continuation remain untested.
- Seed variability and statistical confidence: Results aggregate unions across three seeds. Confidence intervals, per-seed variability, and statistical significance for key findings (e.g., 2.7x teacher-specific inheritance under hard KD) are not reported.
- Benchmark breadth: Utility comparisons rely on validation loss/perplexity and two benchmarks (LAMBADA, Winogrande). A broader suite (reasoning, factuality, long-context QA, code) is needed to assess whether KD’s memorization reduction affects performance across task types.
- Teacher memorization heterogeneity: Teacher memorization rates vary widely across families (e.g., OLMo-2 teacher higher than Pythia teacher). Causes (architecture, tokenizer, pretrain corpora, finetune dynamics) are not analyzed.
- Robustness to instruction tuning/RLHF: Distillation is studied in supervised fine-tuning; its interaction with post-training methods (instruction tuning, RLHF, DPO) on memorization and privacy is unknown.
- Content-type stratification: The study does not stratify memorization by genre, domain, or content type (lists, code snippets, poetry), leaving unclear which types are preferentially memorized under KD vs. cross-entropy.
- Safety and fairness impacts: Filtering “easy-to-memorize” low-entropy data could skew distributions. Effects on bias, representativeness, and safety (e.g., toxicity or misinformation) are not evaluated.
- Black-box KD privacy: While hard KD is considered for black-box teachers, there is no assessment of privacy leakage under realistic API constraints (limited outputs, rate limits, prompt restrictions) or model extraction risks when only sequences are available.
- Pretraining distillation: The paper mentions similar findings in pretraining KD (Appendix A.6), but does not present details. A full pretraining-scale study with open logs would validate whether results extend beyond fine-tuning regimes.
- Granular mechanisms: The entropy–log-probability analysis suggests KD avoids “forced memorization,” but lacks ablations proving causality (e.g., swapping losses mid-training, matching confidence profiles via temperature schedules) and does not model gradient dynamics responsible for overfitting.
- Policy guidance: The work stops short of operational guidelines (e.g., how to set KD temperature and filtering thresholds per dataset to meet specific privacy budgets) and does not present a recipe for deployment with privacy guarantees or monitoring protocols.
Practical Applications
Immediate Applications
The paper’s findings enable several deployable practices and tools for safer, more efficient LLM distillation. The following items summarize specific use cases, mapped to sectors, with concrete workflows and feasibility notes.
- Privacy-aware distillation pipelines for LLM deployment
- Sectors: software/AI, cloud platforms, edge/IoT, consumer apps
- What to do: Prefer soft (logit-level) KD with elevated temperature (e.g., T≈2) to reduce memorization while improving generalization versus same-size fine-tuning; add post-training “discoverable memorization” audits.
- Tools/workflows:
- KD training with KL divergence, temperature scheduling, and validation loss/perplexity gates.
- Memorization audit harness using 50-token prefix → 50-token suffix exact-match checks (discoverable memorization).
- Dependencies/assumptions: Access to teacher logits for soft KD; the discoverable memorization metric captures only exact regurgitation under greedy decoding; tuning temperature may require small utility–privacy trade-off experiments.
- Pre-distillation data risk scoring and filtering
- Sectors: healthcare, finance, legal services, enterprise AI (compliance-heavy contexts)
- What to do: Score each training sequence before KD using zlib entropy, teacher/baseline perplexity, and teacher–baseline KL; filter or downweight “easy-to-memorize” low-entropy sequences predicted to be memorized by the student. The paper’s logistic regression achieves near-perfect AUC-ROC and reduces memorized examples by ≈99.8% when filtered.
- Tools/products:
- “MemRisk” CLI/service to compute features (zlib entropy, PPLs, KL) and predict memorization risk.
- “EntropyGate” dataset filter to remove/weight down high-risk spans before KD.
- Dependencies/assumptions: Availability of a large teacher and a same-size baseline trained on similar data to compute features; zlib entropy is tokenizer-dependent; some quality impact is possible and should be measured.
- Safer on-device and edge model releases via distillation
- Sectors: mobile keyboards/assistants, automotive, robotics, wearables
- What to do: Distill large server models into <2B parameter students for edge inference; use soft KD and pre-distillation filtering to reduce regurgitation of sensitive or copyrighted text in consumer devices.
- Tools/workflows: KD training recipes for edge targets; continuous field audits for memorization on-device.
- Dependencies/assumptions: Compute/logit access during training; edge hardware constraints; licensing for teacher models.
- Black-box teacher mitigation when only hard distillation is possible
- Sectors: cloud/API users, integration partners
- What to do: If logits are unavailable and you must use sequence-level (hard) KD, implement guardrails because hard KD inherits ≈2.7× more teacher-specific memorization than soft KD.
- Tools/workflows:
- Prefer non-greedy sampling (temperature/top-k) for teacher outputs to avoid exact teacher-specific regurgitation in the synthetic dataset.
- Add stronger pre-filtering, label smoothing, or entropy-based weighting during training; run stricter post-hoc audits.
- Dependencies/assumptions: Utility may vary with sampling; requires careful benchmarking (e.g., LAMBADA, Winogrande) to preserve downstream performance.
- Sector-specific privacy hardening with KD
- Healthcare (HIPAA), Finance (GLBA), Legal (attorney–client privilege), Education (student data)
- What to do: Combine domain-specific PHI/PII scrubbing with entropy/perplexity-based pre-filtering and soft KD; monitor memorization via periodic audits.
- Tools/workflows: Plug “MemRisk” into PHI/PII redaction pipelines; maintain risk budgets (max allowed discoverable memorization rate).
- Dependencies/assumptions: Domain annotation/redaction quality; alignment between legal requirements and audit metrics.
- Copyright and brand-protection in content-facing products
- Sectors: search, creative tooling, content platforms, marketing
- What to do: Use KD plus low-entropy sequence filtering to cut verbatim regurgitation risks; track residual exact-match rates on internal content and licensed corpora.
- Tools/workflows: Continuous similarity checks (n-gram/fuzzy); risk dashboards for legal teams.
- Dependencies/assumptions: Data licensing terms; deduplication still helps even if the studied dataset had no duplicates.
- Model governance and compliance checklists for distillation
- Sectors: enterprise MLOps, risk/compliance teams, policymakers (internal audits)
- What to do: Adopt a distillation SOP: soft KD by default; higher temperature; pre-distillation risk filtering; post-distillation discoverable memorization audits; keep logs of entropy and log-prob distributions to detect forced memorization.
- Tools/workflows: “DistillSafe” governance templates, CI/CD hooks to fail builds that exceed memorization thresholds.
- Dependencies/assumptions: Organizational buy-in; compute for audits; acceptance of proxy metrics.
- Academic reproducibility and benchmarking
- Sectors: academia, research labs, evaluation orgs
- What to do: Reuse the paper’s setup to study KD memorization across new datasets/objectives; release “easy-to-memorize” benchmark subsets and report overlap across families.
- Tools/workflows: Evaluation harnesses (e.g., lm-eval), memorization audit suites, entropy/log-prob analytics.
- Dependencies/assumptions: Access to model families and datasets; careful control of tokenizers and seeds.
Long-Term Applications
These opportunities likely require additional research, scaling, or standardization before widespread adoption.
- Standardized privacy certifications for distilled models
- Sectors: policymakers, standards bodies, cloud providers, enterprises
- What it could become: A certification regime specifying KD best practices (soft KD, temperature bounds, risk filtering) and reporting of discoverable memorization rates; integrated into procurement and AI assurance.
- Dependencies/assumptions: Consensus on metrics (discoverable memorization vs. broader leakage); third-party auditors; sector-specific thresholds.
- Adaptive KD objectives explicitly minimizing “forced memorization”
- Sectors: AI model vendors, research
- What it could become: New loss functions that penalize high log-prob with high entropy (uncertainty) during KD, preventing small students from overfitting uncertain tokens; dynamic temperature schedules guided by entropy.
- Dependencies/assumptions: Robust utility–privacy trade-offs; generalization across architectures and tasks.
- Cross-architecture distillation to decorrelate memorization
- Sectors: AI labs, privacy-first vendors
- What it could become: Teacher–student pairings with different tokenizers/inductive biases to exploit the paper’s finding that “easy-to-memorize” examples differ by architecture, further reducing overlap and inheritance.
- Dependencies/assumptions: Stable transfer of capabilities across architectures; careful evaluation to avoid utility degradation.
- Memorization-aware data marketplaces and corpus risk scoring
- Sectors: data brokers, publishers, enterprise data teams
- What it could become: Dataset “memorization risk reports” (entropy distributions, PPL histograms, predicted KD memorization rates) attached to licenses; dynamic pricing for low-risk corpora.
- Dependencies/assumptions: Seller willingness to share stats; standard feature computation across tokenizers; buyer trust.
- Unlearning and right-to-be-forgotten via distillation
- Sectors: policy, legal compliance, enterprise AI
- What it could become: KD-based pipelines that replace portions of model knowledge while minimizing re-memorization, leveraging KD’s regularizing effect and pre-filtering to enforce deletions.
- Dependencies/assumptions: Verified unlearning guarantees; alignment with evolving legal standards; monitoring for reintroduction via new data.
- Copyright-safe creative assistants
- Sectors: media, publishing, education
- What it could become: Distilled assistants tuned to avoid low-entropy, highly compressible passages (e.g., poetry, lyrics) from regurgitation, with real-time entropy gating during generation.
- Dependencies/assumptions: Reliable runtime entropy proxies; acceptance by rights holders and regulators.
- Red-team and blue-team automation for extraction risk
- Sectors: security, trust & safety
- What it could become: Automated extraction probes tied to KD training loops that target predicted high-risk sequences and adapt training to reduce their memorization.
- Dependencies/assumptions: Coverage of probes; integration with training schedulers.
- Privacy-preserving KD for domain-sensitive verticals
- Sectors: healthcare diagnostics, financial advice, legal draft assistants
- What it could become: Vertical KD stacks combining domain redaction, entropy filtering, soft KD, and post-hoc audits, with documented risk SLAs for clients and regulators.
- Dependencies/assumptions: Domain-specific redaction quality; regulatory acceptance; evidence linking lower discoverable memorization to lower real-world leakage.
- Curriculum and data weighting strategies informed by entropy/perplexity
- Sectors: model training platforms
- What it could become: KD curricula that stage or downweight low-entropy sequences most likely to be memorized, while preserving capability gains.
- Dependencies/assumptions: Automated selection that doesn’t harm learning of rare but important patterns; reproducible gains across tasks.
Notes on overarching assumptions
- The paper’s memorization metric focuses on exact 50-token continuation under greedy decoding; broader privacy leakage (e.g., paraphrased regurgitation, membership inference) requires additional checks.
- Reported gains and risks were validated on Pythia, OLMo-2, and Qwen-3 families and specific datasets; results should be re-validated for other architectures/tasks.
- Soft KD assumes teacher logit access; where unavailable, hard KD requires compensating mitigations and tighter audits.
Glossary
- AUC-ROC: Area under the receiver operating characteristic curve; a threshold-independent metric for binary classification performance. "with an AUC-ROC of 0.9997 ± 0.0005."
- Baseline model (Mbaseline): A same-sized model trained independently without distillation, typically using cross-entropy, serving as a comparison point. "Baseline model (Mbaseline): a model of the same size as the distilled student, but fine-tuned independently using standard cross-entropy loss"
- Chain-of-Thought rationales: Intermediate reasoning steps generated by a model that can be distilled to transfer reasoning ability. "distilling Chain-of-Thought rationales alongside final labels."
- Cosine decay: A learning rate schedule that follows a cosine curve to gradually reduce the learning rate during training. "All models are trained with a learning rate of 5 x 10-5 and cosine decay."
- Cross-entropy loss: A loss function that compares the predicted probability distribution to a one-hot target, commonly used for supervised training. "fine-tune on Dhard using cross-entropy loss:"
- Data extraction attacks: Attacks that aim to recover pieces of the training data from a trained model. "One such class of attacks is data extraction attacks, where an attacker can extract some portions of the training data from LLMs"
- Discoverable memorization: A measurable form of memorization where exact training suffixes can be recovered by prompting with prefixes. "We adopt the definition of discoverable memorization from Nasr et al. (2023)."
- Forward KL divergence: The KL divergence measured as KL(teacher || student), encouraging the student to match the teacher’s distribution. "using the teacher's guidance via forward KL divergence loss"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without exploration. "and generate 206 tokens using greedy decoding,"
- Hard distillation: Sequence-level distillation where the student is trained on teacher-generated sequences with cross-entropy rather than matching full distributions. "Sequence-level knowledge distillation (Kim and Rush, 2016) (or hard distillation) is an alternative approach"
- Inductive biases: Model- or architecture-specific preferences that influence which patterns are learned or memorized. "driven by their inherent inductive biases."
- Knowledge Distillation (KD): Training a smaller student model to mimic a larger teacher model’s behavior to improve efficiency and utility. "Knowledge Distillation (KD) is increasingly adopted to transfer capabilities from LLMs to smaller ones,"
- Kullback-Leibler (KL) divergence: A measure of how one probability distribution diverges from another; used to align student predictions with teacher outputs. "the student is trained to mimic the teacher's distribution using the Kullback-Leibler (KL) divergence loss"
- LAMBADA: A reading comprehension benchmark used to evaluate LLMs on long-range context prediction. "an accuracy of 51.85% on LAMBADA,"
- Log-probability: The logarithm of the probability assigned to a sequence or token, used to quantify model confidence. "the sequence log-probability (confidence),"
- Logit: The pre-softmax score output by a model for each token, representing unnormalized log-probabilities. "to match the Teacher's logit distribution by minimizing KL divergence."
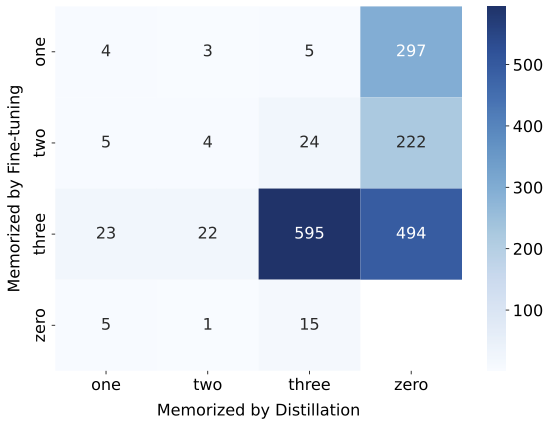
- Logit-level (soft) distillation: Distillation that matches the teacher’s full probability distribution (logits) via KL divergence rather than teacher-generated hard labels. "Logit-level (soft) and sequence-level (hard) distillation show significant memorization overlap,"
- Membership inference attacks: Attacks that attempt to determine whether a specific example was part of the training data. "lower temperatures are less vulnerable to membership inference attacks (Carlini et al., 2022a)."
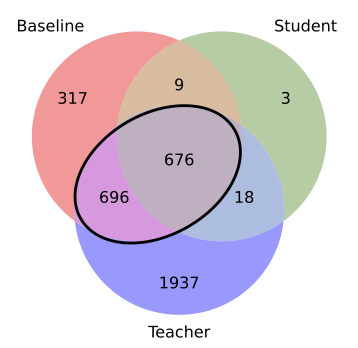
- Memorization inheritance: The subset of memorized examples that the student shares with the teacher but not the baseline. "We define memorization inheritance as examples that are memorized by the teacher and the student, but not by the baseline."
- On-policy distillation: A distillation approach where the student learns from data generated by its own policy to reduce distribution shift. "Generalized Knowledge Distillation (GKD) (Agarwal et al., 2024) explores on-policy distillation to mitigate the distribution shift between teacher and student."
- Perplexity: An exponentiated average negative log-likelihood metric for LLMs; lower values indicate better predictive performance. "Validation loss and perplexity on the FineWeb dataset."
- Reverse KL divergence: The KL divergence measured as KL(student || teacher), often encouraging the student to avoid overconfident mismatches. "MiniLLM (Gu et al., 2025) utilizes reverse KL divergence to prevent the student from over-approximating the teacher's complex distribution,"
- Sequence-level knowledge distillation: Distillation using teacher-generated sequences as targets via cross-entropy, rather than matching distributions. "Sequence-level knowledge distillation (Kim and Rush, 2016) (or hard distillation) is an alternative approach"
- Shannon entropy: A measure of uncertainty in a probability distribution; higher values indicate greater uncertainty. "the average Shannon entropy (intrinsic uncertainty)"
- Soft distillation: Distillation that aligns the student with the teacher’s soft output probabilities (logits) rather than hard labels. "Soft-distilled and Hard- distilled students memorize a lot of similar examples with a 70% overlap."
- Student model (Mstudent): The smaller model trained to mimic the teacher via distillation. "Student model (Mstudent): the smaller model trained to mimic the teacher;"
- Teacher model (Mteacher): The larger model that guides training of the student by providing targets or distributions. "Teacher model (Mteacher): the larger model that serves as a guide for training the smaller model;"
- Temperature (distillation): A scaling of logits before softmax to soften probability distributions during distillation. "We find that increasing the temperature during distillation reduces memorization in the Student model."
- Winogrande: A commonsense reasoning benchmark derived from Winograd-style schemas. "and an accuracy of 55.72% on Winogrande."
- zlib entropy: A proxy for text compressibility computed via zlib compression length; lower values indicate more regular (easier) text. "We plot zlib entropy versus baseline perplexity"
Collections
Sign up for free to add this paper to one or more collections.