MindCine: Multimodal EEG-to-Video Reconstruction with Large-Scale Pretrained Models
Abstract: Reconstructing human dynamic visual perception from electroencephalography (EEG) signals is of great research significance since EEG's non-invasiveness and high temporal resolution. However, EEG-to-video reconstruction remains challenging due to: 1) Single Modality: existing studies solely align EEG signals with the text modality, which ignores other modalities and are prone to suffer from overfitting problems; 2) Data Scarcity: current methods often have difficulty training to converge with limited EEG-video data. To solve the above problems, we propose a novel framework MindCine to achieve high-fidelity video reconstructions on limited data. We employ a multimodal joint learning strategy to incorporate beyond-text modalities in the training stage and leverage a pre-trained large EEG model to relieve the data scarcity issue for decoding semantic information, while a Seq2Seq model with causal attention is specifically designed for decoding perceptual information. Extensive experiments demonstrate that our model outperforms state-of-the-art methods both qualitatively and quantitatively. Additionally, the results underscore the effectiveness of the complementary strengths of different modalities and demonstrate that leveraging a large-scale EEG model can further enhance reconstruction performance by alleviating the challenges associated with limited data.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MindCine: An easy-to-understand summary
What this paper is about
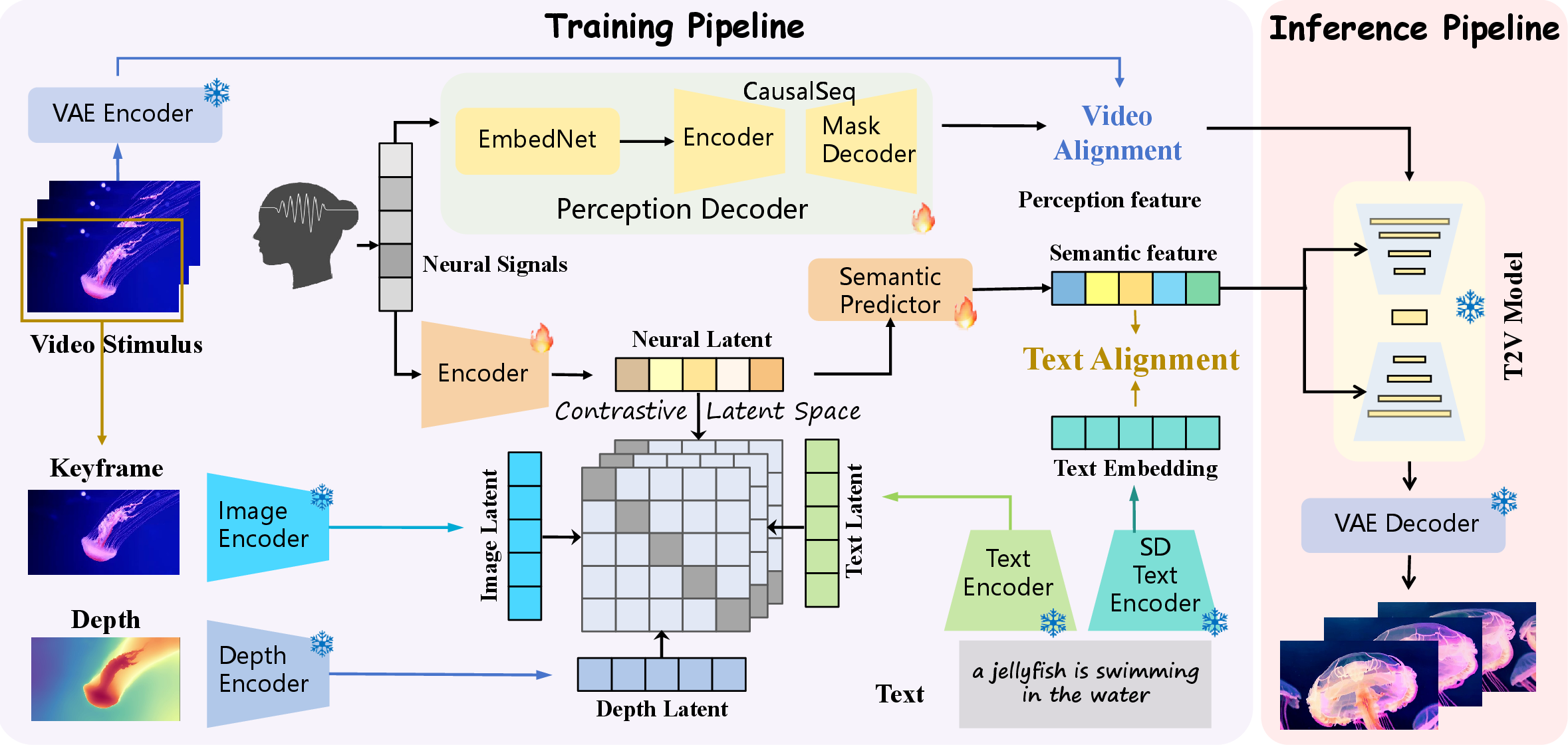
This paper shows a new way to turn brain signals into short videos. The brain signals come from EEG, which is a safe method that records tiny electrical signals from your scalp. The system, called MindCine, tries to rebuild what a person was watching by using these EEG signals, creating videos that look and move like the originals.
What questions the researchers asked
The authors focused on two big questions:
- How can we use more than just text to understand what EEG signals mean? (Most past work only matched EEG with text descriptions, which can miss important visual details.)
- How can we build good models even though there isn’t much EEG+video data available? (EEG data is hard to collect, so datasets are small.)
How the method works (in everyday language)
Think of MindCine as a two-part translator that turns brain signals into a video:
- First, a quick primer on terms:
- EEG: a “microphone” for your brain’s electrical activity, recording thousands of tiny “blips” per second.
- Embedding: a compressed summary of information, like turning a long story into a short keyword list.
- Multimodal: using several types of information together (like text, images, and depth).
- Transformer with causal attention: a model that reads a sequence step-by-step, only looking at what came before, like writing a sentence one word at a time without peeking ahead.
- Diffusion model: a video generator that starts from noisy visuals and gradually cleans them up to form a realistic video, guided by hints.
- The system has three main parts:
- Goal: capture high-level meaning (what objects/scenes are present).
- How: The EEG signals are first processed by a powerful EEG encoder. Instead of only matching EEG with text, MindCine aligns EEG with three kinds of information from the original videos:
- Text captions (what the scene is about in words)
- Image features (visual details)
- Depth maps (the 3D shape/structure of the scene)
- Analogy: It teaches the EEG to “speak the same language” as a well-known vision-LLM (like CLIP), so EEG can better express what the person saw.
- To deal with small datasets, they start from “large EEG models” that were pre-trained on lots of EEG data. This is like learning general grammar before writing a specific essay—much easier than starting from scratch.
2) Perceptual Decoding (the “how it moves/looks over time”) - Goal: capture low-level, frame-by-frame details such as motion and texture. - How: They cut the EEG into many tiny overlapping slices that line up with video frames. A small network (EmbedNet) turns each slice into an embedding. Then a Transformer with “causal attention” reads those embeddings in order, like predicting the next word in a sentence, and produces a sequence of video “codes” (compact frame representations). - Analogy: It treats a video like a sentence of frames, and EEG like a sentence of brain “words,” learning to translate one into the other, step-by-step without cheating by looking ahead.
3) Video Generation (the final “video maker”) - They use a pretrained text-to-video diffusion model as the “artist.” It’s guided by: - Semantic hints (what to show) - Perceptual hints (how frames evolve over time) - The model is also guided by “positive” and “negative” conditions, like telling the artist what to include and what to avoid, to better match the original clip.
What they found and why it matters
- Better reconstructions: MindCine beat previous methods (like EEG2Video) on many measures, including:
- Semantic recognition (how often a classifier picks the right category)
- Visual similarity (how close the frames look to the originals, measured by clarity, structure, and color similarity)
- Multimodal learning helps: Using text + images + depth together produced more accurate and detailed videos than using text alone.
- Big EEG models help with small data: Starting from large, pretrained EEG encoders improved the “meaning” decoding, especially when training data was limited.
- Both modules are necessary: When they removed either the semantic or the perceptual module, performance dropped. This shows the two parts work together and complement each other.
Why this research is important
This work pushes brain-to-video technology closer to reality by:
- Showing that combining multiple types of information (text, images, depth) helps the brain signals tell a richer story.
- Proving that large pretrained EEG models can make up for limited data—very practical in brain research.
- Producing clearer, more accurate videos that better reflect what people saw.
Possible future impacts include better brain-computer interfaces, tools to study how we perceive the world moment-to-moment, and new ways for people who can’t speak or move to share what they see or imagine. At the same time, this area raises privacy and ethics questions, so careful and responsible use is essential.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of knowledge gaps and limitations that remain unaddressed and could guide future research:
- Dataset and ecological validity
- Generalization beyond SEED-DV (20 subjects, 40 concepts, 2 s clips) is untested; cross-dataset transfer (e.g., to Gifford et al., CineBrain) and performance on long-form, naturalistic videos remain unknown.
- Zero-shot/open-vocabulary reconstruction for unseen categories or out-of-distribution scenes is not evaluated.
- Cross-subject generalization
- It is unclear whether models are trained per-subject or shared across subjects; subject-independent training and adaptation to new users (few-shot/zero-shot) are not assessed.
- No analysis of inter-subject variability or functional alignment techniques to mitigate individual differences.
- Temporal modeling and alignment
- The choice of sliding-window size, overlap, and frame-rate alignment (EEG sampling vs video fps) is fixed and not justified; sensitivity to these choices and temporal lags in visual processing (e.g., ~100 ms latency) is unexamined.
- The value of strictly causal decoding vs bidirectional context is not compared; effects on temporal coherence and motion fidelity remain unknown.
- Perceptual supervision mismatch
- The perceptual decoder is trained on VQ-VAE latents, while the T2V diffusion backbone may operate in a different latent space; potential incompatibilities and their impact on reconstruction quality are not analyzed.
- Only L2 loss on latents is used; benefits of perceptual, adversarial, or motion-aware losses (e.g., LPIPS, temporal consistency metrics) are not explored.
- Diffusion backbone and conditioning interface
- The specific T2V model, conditioning interfaces, and integration of semantic and perceptual cues are under-specified; effects of backbone choice and conditioning strategies are not benchmarked.
- The adversarial guidance setup (construction of positive/negative conditions from EEG, selection of negative prompts, and sensitivity to guidance scale s) lacks description and ablation.
- Multimodal joint learning scope
- “Beyond-text” modalities are limited to CLIP image embeddings and monocular depth; omission of audio, optical flow, or video-language (temporal) embeddings may constrain semantic/motion decoding.
- Dependence on pseudo-labels from BLIP2 (captions) and DepthAnything (depth) introduces unknown noise/bias; the effect of caption/depth quality and alternative annotators is not quantified.
- Use of large EEG models
- Large EEG models are only used in the semantic pathway; whether they also improve perceptual decoding is untested.
- No scaling-law or data-efficiency analysis (performance vs amount of paired EEG-video data, pretraining corpus size/domain, or regularization strategies).
- Robustness and real-world use
- Robustness to EEG artifacts (EOG/EMG), nonstationarity, electrode dropout, different montages/hardware, and sampling rates is not evaluated.
- Real-time feasibility (end-to-end latency, compute footprint) and energy efficiency are not reported.
- Evaluation methodology
- Heavy reliance on classifier-based N-way top-1 accuracy and SSIM/PSNR/hue metrics; lack of perceptual user studies and modern video metrics (e.g., FVD, LPIPS, temporal consistency, motion smoothness).
- No per-class breakdown, confidence/uncertainty estimates, or statistical significance tests; reproducibility across multiple random seeds/samples is not reported.
- Interpretability and neurophysiological grounding
- No analysis of which channels, cortical regions, or frequency bands contribute to semantic vs perceptual decoding; absence of attribution/ablation to support the “two-pathway” assumption.
- Lack of alignment to known visual processing timelines (e.g., ERP components) or source-space analyses.
- Hyperparameter sensitivity and training details
- Fixed loss weights (α1–α3, λ, μ) and architectural choices (e.g., CausalSeq depth/heads) lack sensitivity studies; stability under different settings is unknown.
- Key implementation details (training schedules, learning rates, seeds) and their effect on outcomes are missing, hindering reproducibility.
- Controllability and compositionality
- Fine-grained control over attributes (color, shape, viewpoint, motion style) via EEG-derived conditions is not characterized.
- Failure modes (fast motion, occlusions, crowded scenes) and controllability limits are not analyzed.
- Ethical and privacy considerations
- Potential privacy risks of reconstructing perceived content from EEG, consent frameworks, and safeguards are not discussed.
Glossary
- Adversarial guidance: A guidance technique that steers diffusion sampling using positive and negative conditions to better match targets. "we introduce adversarial guidance to control the T2V model 'what to generate' and 'what not to generate' to better reconstruct the original video stimuli"
- Attention logits: The raw, pre-softmax scores computed by attention mechanisms. "we add layer normalization to the queries and keys before the dot-product attention mechanism to avoid over-large values in attention logits"
- BIOT: A pretrained biosignal Transformer model used for cross-data EEG learning. "These large EEG models all follow the masked then reconstruction pretraining paradigm, like BIOT \cite{yang2023biot} and CBraMod \cite{wang2024cbramod}."
- BLIP2: A vision-LLM used to generate image captions that align text with visuals. "we use BLIP2 \cite{li2023blip} for textual descriptions of the images"
- CBraMod: A criss-cross brain foundation model for EEG decoding. "These large EEG models all follow the masked then reconstruction pretraining paradigm, like BIOT \cite{yang2023biot} and CBraMod \cite{wang2024cbramod}."
- Causal Mask: An attention mask that prevents tokens from attending to future positions. "the attention layer incorporates a specially designed Causal Mask to ensure that each token cannot access information from subsequent tokens."
- CausalSeq model: A Transformer-based, causally masked sequence model to decode temporally continuous low-level information from EEG. "we introduce the Transformer-based CausalSeq model to decode continuous, dynamic low-level visual information from high temporal resolution EEG signals."
- CLIP: A contrastive language–image pretraining model whose latent space encodes rich semantics. "Considering the robust semantic information embedded in the latent space of CLIP \cite{lu2024animate, gao2020sketchycoco}"
- Contrastive loss: A representation-learning loss that brings paired samples closer and pushes non-pairs apart. "EEGPT \cite{yue2024eegpt} uses an additional contrastive loss to align masked EEG data and complete EEG data"
- DepthAnything v2: A pretrained model for monocular depth estimation used to provide depth modality. "DepthAnything v2\cite{depth_anything_v2} for depth estimation"
- EEG: Electroencephalography; noninvasive brain signals with high temporal resolution. "EEG signal can capture high dynamic changes due to its high temporal resolution (200 Hz)."
- EEG encoder: A neural network that maps EEG signals into latent representations for downstream alignment and decoding. "The EEG signals are first fed into an EEG encoder to obtain neural latents for subsequent multimodal joint learning."
- EEG2Video: A prior method that reconstructs video directly from EEG signals. "EEG2Video \cite{liu2024eeg2video} has been proposed to reconstruct video from EEG signals"
- EEGPT: A large EEG foundation model pretrained with autoregressive or contrastive objectives. "EEGPT \cite{yue2024eegpt} uses an additional contrastive loss"
- Encoder-Decoder architecture: A neural design with an encoder that processes inputs and a decoder that generates outputs conditioned on encoded states. "The proposed CausalSeq model is based on the Encoder-Decoder architecture."
- Feed-forward network (FFN): The position-wise MLP sublayer used in Transformers after attention. "Each encoder and decoder layer contains a multi-head attention (MHA) and feed-forward network (FFN)."
- fMRI: Functional Magnetic Resonance Imaging; brain imaging with high spatial but low temporal resolution. "functional Magnetic Resonance Imaging (fMRI) \cite{chen2023cinematic, gong2024neuroclips, lu2024animate}."
- Gram: A large-scale general EEG model evaluated as an encoder in this work. "It can be observed that the largest model Gram (6.0M) outperforms other models in most metrics."
- Guidance scale: A scalar controlling the strength of conditional guidance in diffusion sampling. "s is the guidance scale"
- Hue-based Pearson correlation coefficient (Hue-pcc): A pixel-level evaluation metric computing Pearson correlation on hue channels. "hue-based Pearson correlation coefficient \cite{swain1991color} (Hue-pcc)"
- ImageNet classifier: A pretrained image classifier (on ImageNet) used to evaluate frame-level semantics. "For frame-based metric (2-way-I, 40-way-I), the classifier is an ImageNet classifier \cite{radford2021learning}."
- Kinetics-400 dataset: A large-scale action recognition dataset used to train video classifiers. "the classifier is a VideoMAE-based \cite{tong2022videomae} video classifier trained on Kinetics-400 dataset \cite{kay2017kinetics}."
- LaBraM: A large brain model trained on tremendous EEG data to learn generic representations. "LaBraM \cite{jiang2024large} and Gram \cite{li2025gram} apply neural quantization to learn a neural codebook"
- Layer normalization: A normalization applied to stabilize and scale attention computations. "we add layer normalization to the queries and keys before the dot-product attention mechanism"
- Large EEG models: Foundation models pretrained on large EEG corpora to produce robust EEG representations. "we exploit cutting-edge large EEG models trained based on their large-scale pretrained weights"
- Masked then reconstruction pretraining paradigm: A self-supervised scheme masking inputs and training models to reconstruct them. "These large EEG models all follow the masked then reconstruction pretraining paradigm"
- Masked-predict pretraining: A pretraining stage where the model predicts masked tokens or patches. "for next-stage masked-predict pretraining."
- Multi-head attention (MHA): The Transformer attention mechanism that uses multiple heads to capture diverse relations. "Each encoder and decoder layer contains a multi-head attention (MHA) and feed-forward network (FFN)."
- Multimodal joint learning: Training strategy that aligns or combines multiple modalities to enrich learned semantics. "We employ a multimodal joint learning strategy to incorporate beyond-text modalities in the training stage"
- N-way-top-K metric: An evaluation protocol that counts success if the ground-truth class ranks in the top-K among N candidates. "we use the N-way-top-K metric and set K to 1 for measuring semantic-level decoding performance."
- Neural codebook: A learned discrete set of vectors (codes) representing neural features for quantized modeling. "apply neural quantization to learn a neural codebook"
- Neural quantization: Discretizing continuous neural features into a finite set of codes for modeling. "LaBraM \cite{jiang2024large} and Gram \cite{li2025gram} apply neural quantization"
- Overlapping sliding window algorithm: A method to segment signals into overlapping chunks for finer temporal processing. "we apply the overlapping sliding window algorithm to slice one EEG segment into t shorter EEG segments"
- Positional embeddings (PE): Learned or fixed vectors encoding token positions for sequence models. "the EEG embeddings and positional embeddings (PE) are jointly input into the encoder layers."
- Score estimator: The neural network in diffusion models that predicts noise (score) during denoising. " is the score estimator."
- SEED-DV dataset: A synchronized EEG–video dataset used for EEG-to-video reconstruction. "our experiments are conducted on the SEED-DV dataset \cite{liu2024eeg2video}"
- Seq2Seq model: A sequence-to-sequence architecture that maps input sequences to output sequences, often with causal attention. "a Seq2Seq model with causal attention is specifically designed for decoding perceptual information."
- SoftCLIP loss: A softened variant of CLIP’s contrastive loss that aligns embeddings across modalities. "we adopt the SoftCLIP loss \cite{gao2024softclip} (with bidirectional component omitted for brevity) to align EEG embeddings with the latent space of CLIP"
- SSIM: Structural Similarity Index Measure; a perceptual metric for image/video quality. "we employ the structural similarity index measure (SSIM)"
- Stable Diffusion (SD): A latent diffusion model framework used here for text conditioning. "the text condition $\mathbf{e_{t}$ of Stable Diffusion (SD)"
- Temporal-Spatial convolution architecture: A CNN design that captures temporal and spatial patterns in EEG. "The EmbedNet is based on the Temporal-Spatial convolution architecture."
- Text-to-Video (T2V) diffusion model: A diffusion-based generative model that synthesizes video from text (and other) conditions. "we leverage a pre-trained, off-the-shelf Text-to-Video (T2V) diffusion model"
- VideoMAE-based video classifier: A classifier built on VideoMAE pretraining for video understanding tasks. "the classifier is a VideoMAE-based \cite{tong2022videomae} video classifier"
- VQ-VAE encoder: The encoder of a Vector-Quantized Variational Autoencoder that maps inputs to quantized latent codes. "the Ground Truth (GT) video latent variables are extracted by feeding video frames into the VQ-VAE encoder."
Practical Applications
Immediate Applications
Below are applications that can be piloted or deployed now using the MindCine framework and its components, primarily in controlled settings with research-grade EEG, aligned audiovisual stimuli, and GPU inference.
- Neuroscience research workflows (academia)
- Use case: Quantitatively study dynamic visual encoding/decoding by reconstructing short video clips from EEG during naturalistic viewing; compare semantic- vs pixel-level fidelity across subjects, tasks, and cortical montages.
- Sectors: Healthcare research, cognitive neuroscience, neuroinformatics.
- Tools/products/workflows: MindCine codebase; large EEG encoders (e.g., Gram, CBraMod); multimodal alignment via SoftCLIP to CLIP image/text/depth latents; CausalSeq for perceptual decoding; T2V diffusion backbones; BLIP2 and DepthAnything v2 for dataset augmentation.
- Assumptions/dependencies: High-quality, synchronized EEG–video pairs (e.g., SEED-DV); subject-specific fine-tuning; controlled lab conditions to reduce artifacts; substantial GPU for diffusion inference; ethical approval and informed consent.
- Benchmarking and model selection for EEG foundation models (academia/industry)
- Use case: Evaluate which large EEG model best transfers to visual semantic decoding; perform ablations on modality combinations (text-only vs text+image+depth) and module contributions (semantic vs perceptual).
- Sectors: Software/AI, brain–computer interface (BCI) research.
- Tools/products/workflows: Standardized N-way-top-K and pixel-level (SSIM/PSNR/Hue-PCC) evaluation suite; reproducible pipelines using masked-reconstruction pretraining encoders; code to plug-and-play BIOT, LaBraM, EEGPT, CBraMod, Gram.
- Assumptions/dependencies: Availability of pretrained EEG foundation models; labeled and multimodally aligned datasets; consistent preprocessing/normalization across studies.
- Data-efficient EEG feature extraction for scarce paired datasets (academia/industry)
- Use case: Reduce sample requirements for small labs by fine-tuning large EEG encoders and leveraging multimodal joint learning to stabilize convergence and improve semantic fidelity.
- Sectors: Software/AI tooling, neurotech startups.
- Tools/products/workflows: Pretrained EEG encoders + SoftCLIP-based joint training; projection/alignment losses; minimal paired data with synthetic multimodal descriptors via BLIP2.
- Assumptions/dependencies: Transferability of pretrained representations from source corpora to target tasks; maintenance of encoder licensing and model weights; careful hyperparameter tuning.
- Multimodal dataset alignment and augmentation utilities (academia/industry)
- Use case: Create multimodally aligned EEG–image–text–depth corpora from existing EEG–video studies to enable richer supervision and analysis.
- Sectors: Software/data engineering, research platforms.
- Tools/products/workflows: Automated captioning (BLIP2) and monocular depth (DepthAnything v2) pipelines; CLIP latent extraction and SoftCLIP training; data versioning and governance.
- Assumptions/dependencies: Quality of generated captions/depth maps; domain match between CLIP/T2V priors and stimuli; reproducible data curation with audit trails.
- Lab-based neuromarketing and UX testing (industry)
- Use case: With participant consent, reconstruct what viewers perceived during short ad or interface exposure to assess semantic alignment and attention; correlate reconstructions with engagement/recall.
- Sectors: Media/advertising, product UX.
- Tools/products/workflows: Controlled stimulus presentation; MindCine reconstruction and automated content classifiers; dashboards showing top-K concept recovery and pixel-level fidelity.
- Assumptions/dependencies: Strict privacy and neurodata protection; limited generalization beyond controlled stimuli; need for per-subject calibration and artifact management.
- Artistic installations and biofeedback visualization (industry/arts)
- Use case: Generate real-time or near-real-time visualizations informed by EEG using MindCine’s semantic/perceptual features, producing stylized videos that reflect brain activity during viewing or meditation.
- Sectors: Entertainment, wellness tech, galleries.
- Tools/products/workflows: EEG capture + lightweight perceptual decoding; T2V guided generation with positive/negative conditions; curation of stimulus sets for robust mapping.
- Assumptions/dependencies: Not exact “mind reading”; visuals are guided by generative priors and may be impressionistic; privacy-aware design for public exhibits.
- Ethics and policy readiness activities (policy)
- Use case: Immediate risk assessment and governance for organizations collecting EEG tied to reconstructive models; develop neurodata consent language, storage, and usage policies.
- Sectors: Policy, compliance, institutional review boards.
- Tools/products/workflows: Neurodata privacy frameworks; data minimization and retention controls; transparency reports on generative reconstruction use.
- Assumptions/dependencies: Jurisdictional compliance (GDPR, evolving “neurorights”); external audits for sensitive research; participant education on capabilities and limits.
Long-Term Applications
These applications require further research on generalization across subjects, robustness in the wild, latency reduction, safety/ethics frameworks, and possibly new hardware and model optimizations.
- Assistive communication and visual reporting for locked-in or non-verbal patients (healthcare)
- Use case: Decode and communicate perceived or imagined visual concepts from EEG to caregivers or clinicians; augment assessments of awareness and perceptual function.
- Sectors: Healthcare, accessibility/assistive tech.
- Tools/products/workflows: Portable, comfortable EEG; cross-subject models (e.g., future “MindCross”-style adaptation); fast video generation (e.g., flow-matching or distillation-based); clinical integration and monitoring.
- Assumptions/dependencies: Strong cross-subject generalization; medically validated endpoints; low-latency inference; rigorous safety/efficacy trials; robust artifact handling.
- Dream, memory, and hallucination visualization for clinical and research use (healthcare/academia)
- Use case: Non-invasively study and potentially visualize internal imagery (sleep, PTSD flashbacks, psychosis) to aid diagnosis, therapy personalization, or basic science.
- Sectors: Mental health, psychiatry, cognitive neuroscience.
- Tools/products/workflows: Specialized decoders for endogenous imagery; longitudinal subject-specific calibration; privacy-preserving pipelines; clinician dashboards with uncertainty quantification.
- Assumptions/dependencies: Ability to decode without synchronized external stimuli; ethical safeguards for highly sensitive content; significant advances in semantic decoding fidelity.
- Real-time AR “visual share” and telepresence (HCI/enterprise)
- Use case: Stream compact reconstructions of what an operator perceives to remote collaborators or robotic agents (e.g., field service, training, mission control).
- Sectors: HCI, robotics, enterprise collaboration.
- Tools/products/workflows: Streaming CausalSeq + optimized video generation (e.g., pyramidal flow matching, diffusion distillation); edge inference on wearables; enterprise-grade privacy controls.
- Assumptions/dependencies: Millisecond-level latency; comfort and motion robustness of wearable EEG; reliable semantic grounding in diverse environments; strict opt-in.
- Adaptive VR/education systems responding to perceived confusion or attention (education/gaming)
- Use case: Detect perceived content and semantic mismatch to adjust difficulty, pacing, or explanations in real time; generate tailored visual aids based on EEG-derived reconstructions.
- Sectors: Education technology, gaming/edutainment.
- Tools/products/workflows: On-device semantic classifiers built on MindCine outputs; feedback loops for curriculum engines; content generators integrated with T2V.
- Assumptions/dependencies: Robust individual calibration; interpretable measures of attention/comprehension; latency constraints; user consent and fairness considerations.
- In-vehicle cognition and situational awareness monitoring (automotive)
- Use case: Assess whether drivers perceive hazards or signage; provide assistance when perception fails (e.g., fatigue, overload).
- Sectors: Automotive safety, fleet management.
- Tools/products/workflows: Motion artifact–resilient EEG; compressed perceptual decoders; safety-certified decision pipelines.
- Assumptions/dependencies: Practical wearable form factors; high noise tolerance; stringent regulatory validation.
- Scaled neuromarketing and media optimization (media/finance)
- Use case: Large-cohort studies that infer perceived concepts and emotional resonance to optimize media investment; correlate reconstructions with outcomes.
- Sectors: Media, advertising, finance analytics.
- Tools/products/workflows: Cloud services offering MindCine-style reconstruction and concept retrieval; privacy-preserving analytics with aggregation and differential privacy.
- Assumptions/dependencies: Public acceptance; robust cross-subject generalization; compliance with neurodata regulations; avoidance of manipulative practices.
- Robotics and teleoperation with EEG-informed scene understanding (robotics)
- Use case: Provide robots with human-perceived scene summaries to align autonomy with operator intent in cluttered or ambiguous environments.
- Sectors: Robotics, industrial automation.
- Tools/products/workflows: EEG-to-scene-semantic adapters; intent-aware planners consuming reconstructed concepts; latency-optimized models.
- Assumptions/dependencies: Reliable semantic decoding under task stress; integration with safety-critical control stacks; operator training.
- Commercial SDKs and platforms for EEG-to-content generation (software)
- Use case: Offer MindCine-like pipelines as SDKs for research and product prototyping; managed services for dataset alignment and decoding.
- Sectors: Software platforms, cloud AI services.
- Tools/products/workflows: MindCine SDK (encoders, SoftCLIP alignment, CausalSeq, T2V guidance); hardware partner integrations; privacy by design.
- Assumptions/dependencies: Model compression/distillation for real-time; standardized APIs; licensing of pretrained backbones; secure data lifecycle management.
Cross-cutting assumptions and dependencies (affecting feasibility)
- Model generalization and calibration: Current results are per-subject and short (2 s, 40 concepts) with controlled stimuli; scaling to open-world perception needs larger, more diverse EEG–video corpora and cross-subject alignment.
- Hardware and ergonomics: Research-grade EEG quality is needed today; future consumer-grade headsets must improve channel quality, comfort, and motion robustness.
- Compute and latency: Diffusion/T2V models are heavy; real-time applications need distillation, flow matching, or efficient generative backbones.
- Multimodal priors: Reconstructions inherit biases from CLIP/T2V training; domain mismatch can degrade fidelity; careful negative guidance and calibration required.
- Ethics, privacy, and consent: Neurodata is highly sensitive; policies, auditability, and neurorights protections are prerequisites for deployment.
- Safety and evaluation: Clinical/automotive/robotics uses demand rigorous validation, uncertainty reporting, and fail-safes before real-world use.
Collections
Sign up for free to add this paper to one or more collections.