- The paper introduces iterative plan generation with self-correction to enhance long-horizon task planning in multi-agent scenarios.
- It presents a modular, closed-loop architecture that enables explicit agent selection and action sequencing in simulated environments.
- Evaluation shows that Mixture-of-Experts and decentralized policies face scalability challenges as action combinatorics increase.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Introduction
The MARS Challenge represents a comprehensive benchmark for assessing embodied AI progress in multi-agent robotic collaboration. It is explicitly designed to interrogate the scalability, coordination, and semantic reasoning capabilities of state-of-the-art vision-language-action models (VLAMs) and multimodal LLMs in scenarios that require both high-level planning and low-level policy execution across heterogeneous robot teams. The challenge divides evaluation into planning and control tracks, enabling rigorous dissection of challenges and innovations in both hierarchical embodied reasoning and continuous coordination under partial observability.
Design and Methodology of the MARS Challenge
The challenge structure targets two primary axes: multi-agent planning and collaborative control. The Planning Track requires participants to solve real-world inspired, hierarchically compositional tasks in simulated domestic environments. Systems must receive natural language instructions and multimodal observations, then select a subset of candidate robots and generate parallelizable action plans. The evaluation protocol explicitly rewards prefix planning precision, semantic correctness, parallelism, and optimality in resource utilization, making naive or "lazy" overgeneralization strategies suboptimal. The action output structure is rigorously formalized, and tasks are derived from the RoboCasa suite, covering variations in scene topology, agent configuration, and instruction ambiguity.
The Control Track isolates policy learning challenges in collaborative multi-arm tasks, necessitating synchronized decision making over high-dimensional continuous spaces. Environmental stochasticity, unseen evaluation seeds, and partial state observation further stress-test robustness and transferability of policy architectures. The requirement of a unified model family across multiple collaborative manipulation tasks enforces a degree of architectural generality, deterring per-task overfitting.
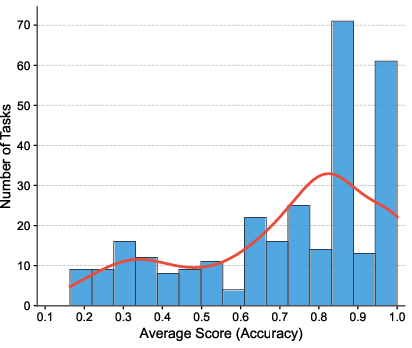
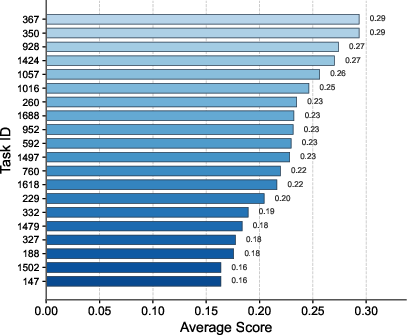
Figure 1: Left—Leaderboard for the top ten planning track participants; middle—distribution of task accuracy; right—20 most challenging tasks emphasizing long-horizon, parallel-agent coordination requirements.
Analysis of Planning and Control Approaches
Planning Track: Iterative Self-Correction and Modular Reasoning
The highest-performing planning systems adopt either iterative refinement (self-correction) or modular role decomposition. The self-correction framework utilizes stochastic plan generation through VLMs, followed by plan evaluation and selection via an independent VLM "judge." This additional consensus step—implemented via resampling and voting across semantically diverse planning candidates—directly mitigates compounding long-horizon errors and reduces model bias toward suboptimal, single-pass generations. Supervised fine-tuning on self-generated, iteratively improved data further allows the system to bootstrap data efficiency and broaden coverage without extensive manual annotation.
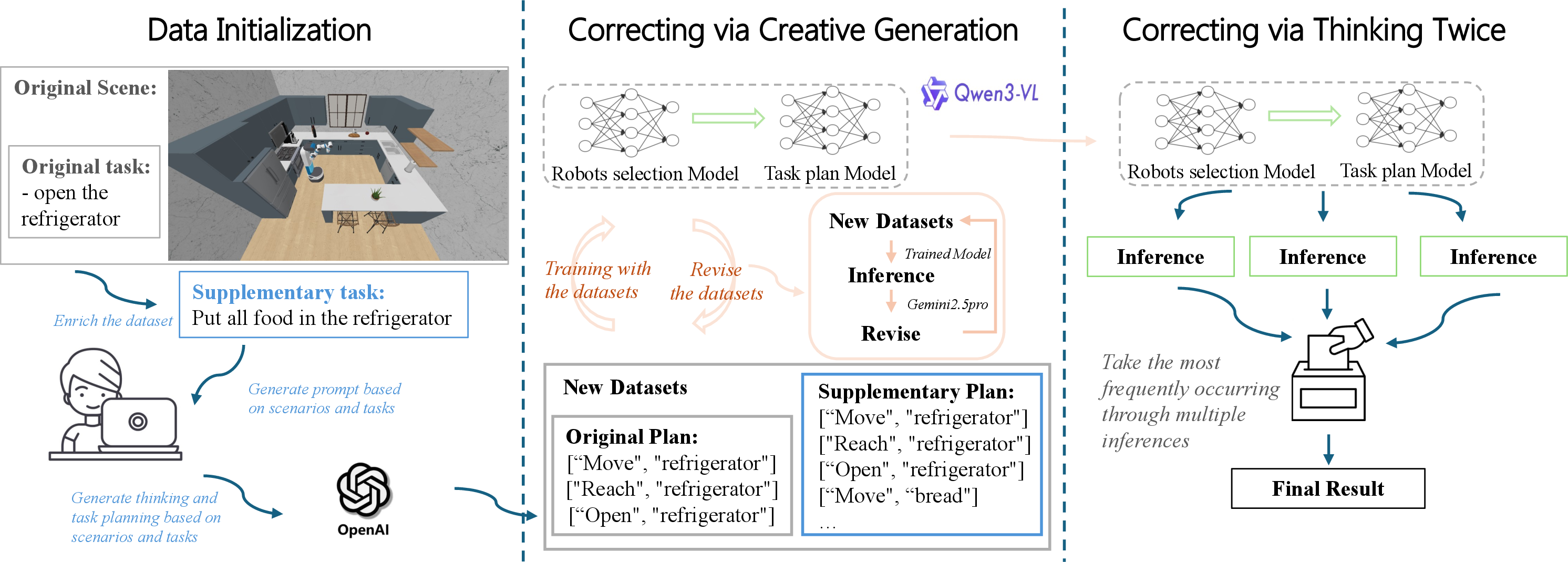
Figure 2: Pipeline of the champion self-correction framework with multi-stage VLM plan generation, judging, selection, and fine-tuning loop for iterative performance enhancement.
In contrast, another prominent approach introduces a modular, closed-loop architecture where submodules address agent selection, action planning, and plan verification independently. Embodied priors and capability grounding are explicitly injected in the agent activation and action sequencing phases, while a final monitor module acts as a formal validator, enforcing compositional constraints and logical coherency.

Figure 3: Multi-agent planning as decomposed into activated agent selection, explicit stepwise plan generation, and downstream verification modules, promoting interpretability and closed-loop error correction.
Notably, both solution families outperform basic single-pass and monolithic autoregressive planners by a large margin, as demonstrated in both mean task accuracy and robustness to ambiguous instructions and high parallelization demands.
Control Track: Mixture-of-Experts and Decentralized Policies
Collaborative multi-arm control solutions bifurcate into mixture-of-experts (MoE) and decentralized policy paradigms. The MoE approach factorizes the action space across all nonempty arm subsets, creating specialized experts for both singleton and combinatorial arm configurations. A learned router dynamically selects or aggregates specific experts contingent on the evolving requirements of each manipulation step. The integration of pre-trained VLMs ensures consistent spatial grounding, while the MoE head allows the system to adaptively balance independent and tightly coordinated actions.
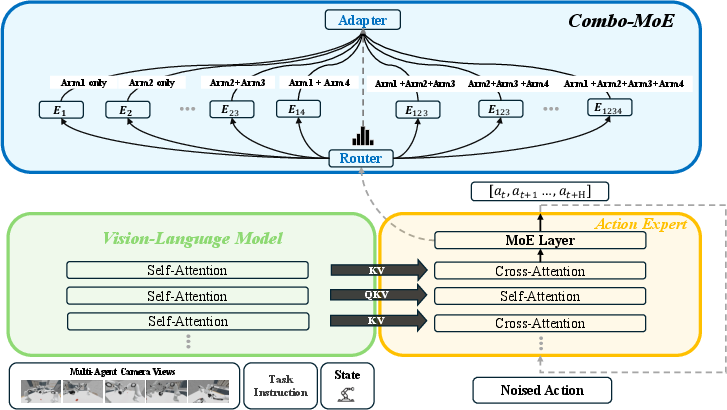
Figure 4: Combo-MoE pipeline showcasing task instruction and multimodal observation encoding via VLM; MoE action head enables dynamic selection and aggregation among specialized single-arm and combinatorial experts.
Decentralized frameworks such as CoVLA eschew a centralized controller, instead deploying per-arm policies with implicit spatial communication mediated via a shared workspace. Each policy has access only to local RGB observations, and coordination is emergent, learned via environmental reward shaping and demonstration data partitioned according to subtask specialization. This paradigm embodies the principle of spatially grounded, perception-driven collaboration—a critical attribute for fault tolerance and scalability under agent heterogeneity and dynamic addition/removal.

Figure 5: CoVLA policy decomposition—one vision-language-action policy per robot, each acting on its own input while coordination is realized implicitly from shared workspace observation.
While MoE demonstrates the highest ceiling in two-arm tasks, all explored methods observe catastrophic degradation once action combinatorics and observation fragmentation scale with agent number, underscoring the open nature of robust coordination at scale.
Empirical Outcomes and Limitations
The evaluation metrics expose order-of-magnitude gaps between top leaderboard participants and the theoretical upper bound of the challenge protocol. With the highest planning track score remaining below 0.9, and average task accuracy clustered between 0.4 and 0.6, the results point to persistent difficulty in robust, efficient collaborative execution under semantic and stochastic ambiguity.
Within the control track, even state-of-the-art policies collapse on three- and four-arm collaborative tasks, with success rates rapidly falling to zero as agent numbers increase, despite high-frequency demonstration regimes and architectural innovations. The exponential scaling of the action space, compounded by the need for mutual state prediction, presents a bottleneck not overcome by current policy architectures.
Implications, Theory, and Prospects
This work substantiates several formal mechanisms crucial for embodied multi-agent intelligence:
- Iterative plan generation and judgment robustly transform irrecoverable planning failures into locally correctable missteps in long-horizon tasks.
- Explicit capability grounding and modular coordination architectures are necessary to avoid domain shift-induced hallucinations and semantic errors in parallel plans.
- Mixture-of-experts action heads enable a scalable decomposition but cannot, alone, address action space explosion under combinatorial collaboration. Hybrid decentralized strategies and shared spatial grounding are required for next-level robustness.
The fundamental limitation remains the transfer from simulation to real-world platforms, where sensor noise, actuation error, and unmodeled human-agent interaction threaten the brittle compositional policies learned in controlled simulators. Future development hinges on the extension of this framework to hardware-in-the-loop, domain-randomized environments, online adaptation, and large-scale data-driven transfer learning for collaborative skill synthesis.
Conclusion
The MARS Challenge establishes a demanding and wide-coverage evaluation protocol for multi-agent embodied AI, revealing the potential and limitations of current VLM-based planning and policy systems under compositional collaboration. Iterative, self-corrective frameworks, modular policy architectures, and environment-mediated, decentralized coordination emerge as leading paradigms. There remains significant headroom—both practical and theoretical—in efficiently scaling such systems to robust real-world operation and to tasks exhibiting open-ended heterogeneity (2601.18733).