How AI Impacts Skill Formation
Abstract: AI assistance produces significant productivity gains across professional domains, particularly for novice workers. Yet how this assistance affects the development of skills required to effectively supervise AI remains unclear. Novice workers who rely heavily on AI to complete unfamiliar tasks may compromise their own skill acquisition in the process. We conduct randomized experiments to study how developers gained mastery of a new asynchronous programming library with and without the assistance of AI. We find that AI use impairs conceptual understanding, code reading, and debugging abilities, without delivering significant efficiency gains on average. Participants who fully delegated coding tasks showed some productivity improvements, but at the cost of learning the library. We identify six distinct AI interaction patterns, three of which involve cognitive engagement and preserve learning outcomes even when participants receive AI assistance. Our findings suggest that AI-enhanced productivity is not a shortcut to competence and AI assistance should be carefully adopted into workflows to preserve skill formation -- particularly in safety-critical domains.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “How AI Impacts Skill Formation”
Overview: What is this paper about?
This paper looks at how using AI tools to help with coding affects how people learn important skills. The authors wanted to know if getting quick help from AI makes you faster, and also whether it helps or hurts your understanding of the code—especially the kind of understanding you need to check, fix, and safely use code written by AI.
Key questions the researchers asked
- Does using an AI assistant make people complete new coding tasks faster?
- Does using AI while learning a new coding tool hurt people’s understanding of that tool and their ability to read and debug code?
How the study worked (in everyday terms)
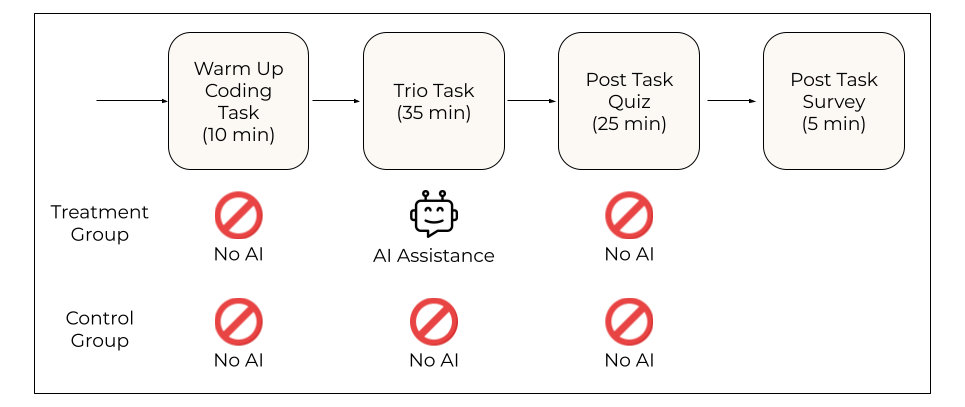
The researchers ran a randomized experiment with 52 people who already knew Python but had never used a specific library called “Trio.” Trio helps you do “asynchronous” programming—think of it like cooking dinner while your laundry runs and your message downloads, all at the same time, without getting tangled up.
Here’s what participants did:
- First, everyone completed a short warm-up Python task without any AI.
- Then, they did two small coding tasks using the new Trio library. Half were allowed to use an AI chat assistant (powered by GPT-4o) and half were not.
- After the tasks, everyone took a quiz (no AI allowed) to test three things: conceptual understanding (big ideas), code reading (what the code does), and debugging (finding and fixing errors). The quiz did not test basic syntax memorization.
To keep things fair, participants were similar in experience, and the AI assistant could give correct code if asked. The team also watched screen recordings to see how people interacted with the AI and how much time they spent typing questions or reading answers.
What they found and why it matters
The main results:
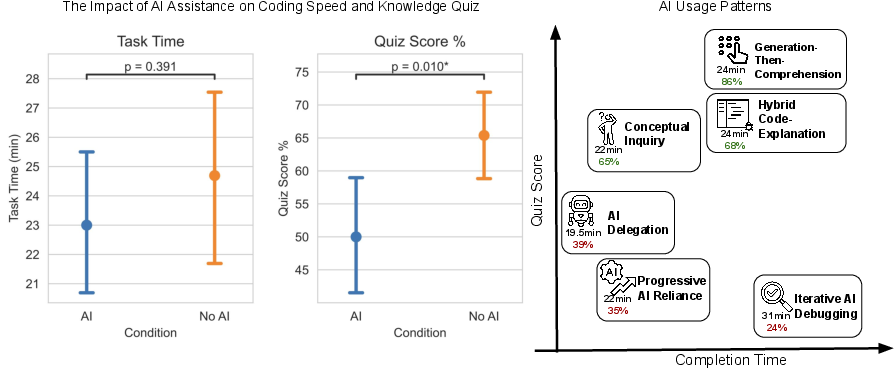
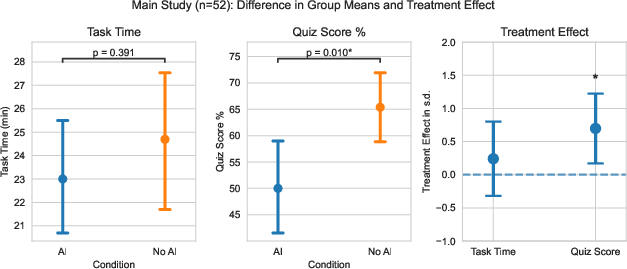
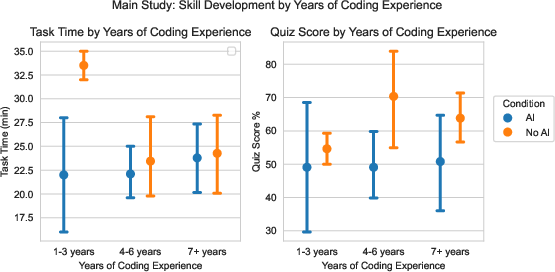
- People who used AI did not finish the tasks significantly faster on average.
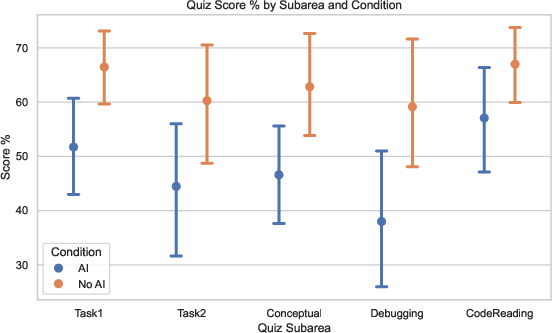
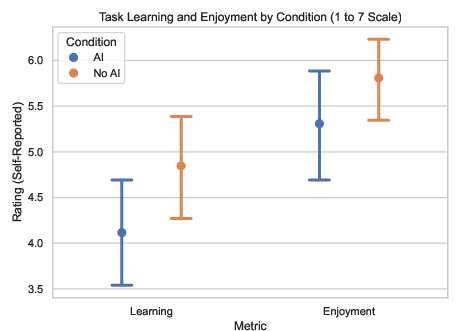
- People who used AI scored lower on the quiz by about 17% (roughly two grade steps), especially on understanding concepts and debugging skills.
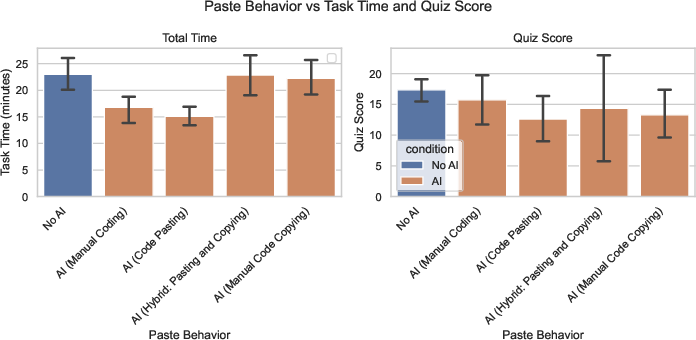
- A few people who fully delegated the coding to the AI were faster, but they learned much less about the library.
- Many AI users spent a lot of time crafting questions and reading answers—which partly explains why they weren’t much faster.
- The biggest skill gap was in debugging. People without AI bumped into more errors themselves and learned how to fix them, which improved their debugging ability.
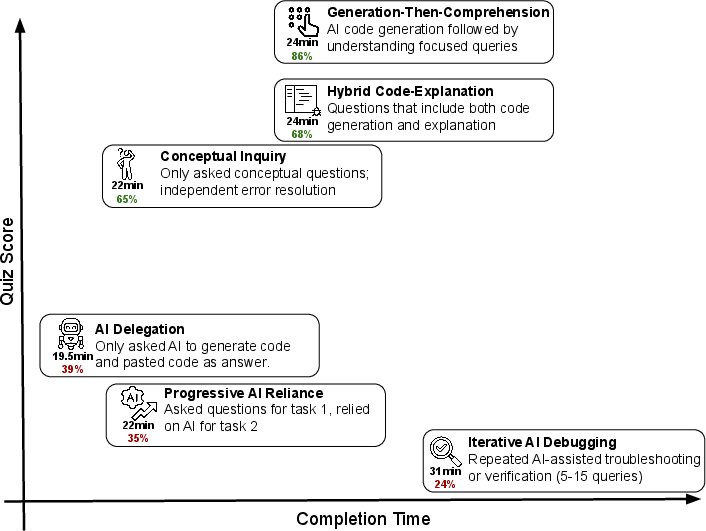
The researchers also identified six common AI “interaction patterns.” Three of these patterns helped people learn better because they kept them mentally engaged:
- Generation-then-comprehension: Ask AI for code, then ask follow-up questions to understand it.
- Hybrid code-explanation: Request code plus a clear explanation of how it works.
- Conceptual inquiry: Ask AI only conceptual questions (no code generation), then write and debug your own code.
The other three patterns led to worse learning because people relied too much on AI:
- Full delegation: Let AI write almost everything.
- Progressive reliance: Start independent, then drift into letting AI do most of the work.
- Iterative AI debugging: Keep asking AI to fix things without deeply understanding the fixes.
What this means in simple terms
Using AI can feel like a shortcut, but it isn’t a shortcut to true competence. If you depend on AI to do the hard thinking, you might finish the task—but you won’t build the deeper skills needed to check AI’s work, spot mistakes, and make safe decisions. That’s especially risky in areas where code quality really matters (like healthcare, finance, or safety-critical systems).
Practical takeaways and potential impact
- AI is useful, but how you use it matters. If you stay engaged—ask for explanations, probe concepts, and write or debug code yourself—you can get help from AI without sacrificing learning.
- Workplaces and schools should be careful about when and how AI is used during learning. Encouraging “explain-then-code” or “concept-first” interactions can protect skill development.
- For safety-critical jobs, humans must maintain strong understanding and debugging skills to supervise AI and catch mistakes.
- Bottom line: AI can boost productivity, but it doesn’t automatically build competence. To grow real skills, use AI as a coach, not a crutch.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide actionable follow-up research.
- External validity across domains: Do these learning effects generalize beyond Python async (Trio) to other programming topics (e.g., data engineering, systems design), non-programming tasks (writing, analytics), and safety-critical domains (medical diagnostics, finance, aviation)?
- Longitudinal retention: How do AI-assisted vs. unassisted learners retain concepts and debugging ability over time (e.g., 1–4 weeks, 3 months)? Do initial deficits persist, widen, or close with continued practice?
- Transfer of learning: Does AI-assisted learning impair transfer to conceptually related libraries (e.g., asyncio, anyio) or different concurrency models (threads, processes, reactive frameworks)?
- Realistic oversight tasks: How does AI use affect the ability to audit, test, and correct flawed AI-generated code under realistic conditions (e.g., seeded subtle bugs, race conditions, incomplete specs)?
- Variation in AI modalities: How do outcomes differ for chat assistants vs. autocomplete (Copilot-style), inline “fix” tools, retrieval-augmented docs, and agentic tools that run/edit code? Compare head-to-head under identical tasks.
- AI reliability and hallucination: What is the causal impact of systematically varying AI error rates or uncertainty displays on overreliance, learning, and oversight skill?
- Dose–response of assistance: How does the amount and timing of assistance (e.g., query limits, delayed access until after an attempt, escalating hints) modulate productivity–learning trade-offs?
- Causal tests of “good” interaction patterns: The identified high-learning personas are correlational. Do instructed protocols (e.g., “conceptual inquiry only,” “generate-then-explain,” “explain-before-code”) causally improve learning and at what productivity cost?
- Scaffolding interventions: Which instructional scaffolds mitigate learning loss? Examples to test: mandatory self-explanations, test-first or doc-first requirements, reflection prompts after AI outputs, adversarial spot checks, explanation-quality grading.
- Mechanism identification (error exposure): Is the learning benefit in the control driven by error encounter/resolution? Randomize error exposure (e.g., inject controlled errors into both conditions or suppress errors for some controls) to isolate mechanisms.
- Measurement breadth: The quiz excluded code writing. Do results hold when adding code-writing, test design, system design, and mental-model probes (concept inventories)?
- Cognitive load and attention: Objectively measure cognitive effort (e.g., NASA-TLX, secondary-task probing, eye-tracking, telemetry) to test whether AI reduces desirable difficulty essential for learning.
- Larger and stratified samples: Increase power to detect subgroup effects (e.g., novices vs. experts, prior asyncio users, education levels). Multi-site replications to assess robustness.
- Naturalistic settings: Allow normal developer behaviors (web search, documentation, Stack Overflow) and full IDE/tooling (linters, tests, CI) to evaluate ecological validity.
- Team and workflow contexts: How do effects manifest in pair programming, code review, and multi-developer projects where oversight is distributed and social processes matter?
- Task scale and duration: Do results change for multi-hour/multi-day projects with architecture decisions, refactoring, and sustained debugging vs. brief tasks?
- Incentives and goals: The study emphasized speed. How do different incentives (quality bonuses, learning objectives, minimal-bug targets) shift the productivity–learning frontier under AI assistance?
- Assistant integration and context: Does deeper repository context, codebase-level awareness, or workspace tools (e.g., running tests, tracing) change learning impacts relative to a chat-only interface?
- Model heterogeneity and updates: Replicate with different models (e.g., code-specialized vs. general, smaller vs. larger) and across model updates to assess stability of effects.
- Reliability of qualitative clusters: The persona clusters are small (n per cluster). Validate clustering with larger samples and pre-registered criteria; assess reproducibility across tasks and models.
- Bias and heterogeneity: Test whether impacts vary by demographics (e.g., gender, native language), cognitive styles, or prior AI familiarity; assess equity implications.
- Compliance and contamination in the wild: In settings where AI use cannot be restricted, instrument actual usage to gauge real-world effects and policy-relevant guardrails.
- Policy and pedagogy trade-offs: Quantify the net value of short-term productivity vs. long-term skill formation for organizations; model when to permit, gate, or structure AI use during training and onboarding.
- Safety-focused benchmarks: Create standardized benchmarks for oversight skills (bug finding, risk assessment, test adequacy) under AI assistance, especially for concurrency and other error-prone areas.
- Replication with alternative evaluations: Re-run with different validated assessments (e.g., open-ended explanations scored with rubrics, code reviews of flawed PRs) to test measurement sensitivity.
Practical Applications
Immediate Applications
The paper’s findings can be operationalized now in multiple sectors by adjusting workflows, product defaults, and training to preserve skill formation while using AI.
- Software/Tech (Engineering teams): Structured “learning-preserving” AI-use policies
- What: Adopt three proven interaction patterns—Conceptual Inquiry, Hybrid Code-Explanation, and Generation-Then-Comprehension—into team norms and onboarding.
- How (workflow/tools): Provide prompt libraries (“Explain before code,” “Ask why this works,” “Summarize the concept in your own words”); add a “Conceptual mode” toggle in IDE assistants that defaults to explanations before generation; require brief post-AI reflection notes in PRs.
- Assumptions/Dependencies: Managerial buy-in; existing LLM/IDE integration; assumes findings generalize from Trio to other APIs/libraries.
- Software/Tech (L&D/onboarding): Two-stage tasks with AI-free checks
- What: Use AI-assisted task completion followed by a timed, no-AI quiz emphasizing conceptual understanding, code reading, and debugging.
- How (workflow/tools): Integrate short quizzes into onboarding modules; use code reading/debugging-focused rubrics; LMS/autograder setups.
- Assumptions/Dependencies: Ability to proctor no-AI assessments; short-form assessments reflect job-relevant skills.
- Software/Tech (Code review): Guardrails for novices to prevent full delegation
- What: Require “no-assist” diffs for critical components and debugging ownership for junior developers.
- How (workflow/tools): PR templates with sections completed without AI; test failures deliberately left for the author to diagnose; reviewer checklists highlighting conceptual/library-specific risks.
- Assumptions/Dependencies: Cultural support; minor productivity trade-offs accepted for learning.
- Software/Tech (Hiring/assessment): Emphasize code reading and debugging
- What: Shift technical screens toward reading, explaining, and debugging tasks rather than greenfield coding.
- How (workflow/tools): Interview banks with short conceptual and debugging problems; post-interview AI-free take-home quizzes.
- Assumptions/Dependencies: Interviewer training; candidate fairness considerations.
- AI Vendors/DevTools: “Explain-with-code” defaults and “Socratic” nudges
- What: Make code generation ship with inline explanations by default; nudge users toward high-skill patterns when delegation-only behavior is detected.
- How (product features): “Explain-and-generate” toggle on by default; “Ask me why” one-click prompts; lightweight telemetry to classify interaction patterns and surface tips.
- Assumptions/Dependencies: User consent for telemetry; minimal UI/latency overhead; privacy compliance.
- AI Vendors/DevTools: Reflection gates for paste/apply actions
- What: Prompt users to paraphrase a concept or describe expected behavior before inserting AI-generated code into the buffer.
- How (product features): IDE plugin that requires a short typed rationale or a selection of the correct conceptual tag before paste/apply.
- Assumptions/Dependencies: Friction acceptable for learning contexts; configurable per user/seniority.
- Academia (CS and beyond): Structured AI-use policies in courses
- What: Allow AI for exploration but require AI-free comprehension checks; rebalance grading toward code reading/debugging and conceptual questions.
- How (workflow/tools): Two-stage assignments (AI-allowed build, AI-free quiz); LMS templates; exam variants that prevent local item dependence.
- Assumptions/Dependencies: Proctoring and clear policies; faculty time to redesign assessments.
- Academia (Instruction): Instructor guidance for preventing overreliance
- What: Train TAs/instructors to coach students into high-skill patterns (ask conceptual questions first, then code).
- How (workflow/tools): TA checklists; short “prompt hygiene” guides; template feedback comments.
- Assumptions/Dependencies: TA training bandwidth; faculty alignment.
- Safety-critical orgs (Healthcare, Finance, Energy, Robotics): Internal governance limiting full delegation for trainees
- What: Set staged privileges—novices use conceptual/explanation modes; full code generation only after passing competency checks.
- How (policy/workflows): Competency gates; documented “AI-free” practice blocks; periodic debugging drills on synthetic failures.
- Assumptions/Dependencies: Compliance frameworks; supervisory bandwidth; risk appetite.
- Individual professionals/daily life: Personal AI-use protocol to learn new tools
- What: Prefer Conceptual Inquiry and Generation-Then-Comprehension; insert “AI-free practice windows.”
- How (workflow/tools): Save reusable prompts (“Explain concept X before code”); block time for unaided practice; self-quizzes after tasks.
- Assumptions/Dependencies: Personal discipline; access to good prompts or checklists.
Long-Term Applications
Longer-horizon innovations can embed “learning preservation” into AI systems, standards, and training ecosystems, requiring research, scaling, or product development.
- AI Vendors/DevTools: Skill-aware copilots that adapt to user proficiency
- What: Dynamic scaffolding that modulates assistance—more explanations and conceptual prompts for novices; relaxed constraints for experts.
- How (product features): User modeling; classification of interaction patterns; personalized “assist profiles.”
- Assumptions/Dependencies: Reliable skill estimation; privacy-preserving telemetry; UX acceptance.
- AI Vendors/DevTools: Pedagogical agents for developers
- What: Agents that intentionally create teachable moments (e.g., surface controlled failures to debug) before providing full solutions.
- How (product features): Curriculum graphs per library/API; “debug-first” workflows; formative assessment built into IDEs.
- Assumptions/Dependencies: Accurate error injection and test harnesses; buy-in despite initial time costs.
- Cross-sector Training (Healthcare, Finance, Operations): “Reliance drills” and skill-retention programs
- What: Simulate scenarios with plausible AI errors; trainees must detect and correct without AI help.
- How (programs/tools): Scenario platforms; structured debriefs; recurrent certifications focusing on oversight skills.
- Assumptions/Dependencies: Domain-specific scenario design; regulator or insurer endorsement.
- Standards/Policy: Learning-preserving AI standards and audits
- What: Industry standards requiring vendors and orgs to document how AI tools impact skill formation and oversight capacity.
- How (policy/tools): “Learning impact statements” in procurement; external audits; benchmarks for code reading/debugging retention.
- Assumptions/Dependencies: Standards bodies’ engagement; measurable, agreed-upon metrics.
- Regulation (Safety-critical domains): Competency verification for AI supervisors
- What: Mandate periodic, AI-free skill checks for roles responsible for supervising automated systems.
- How (policy/workflows): Regulator-defined exams; continuing education credits tied to oversight competencies.
- Assumptions/Dependencies: Evidence base across domains; harmonization across jurisdictions.
- Academia (Curriculum): Longitudinal programs integrating AI with proven learning patterns
- What: Degree/certificate pathways where AI is used in structured, scaffolded ways and retention is measured across semesters.
- How (programs/tools): Capstone “AI-free” validations; portfolios documenting conceptual mastery; analytics linking AI-use patterns to outcomes.
- Assumptions/Dependencies: Multi-term coordination; longitudinal data infra; IRB-compliant analytics.
- Measurement & Research Infrastructure: Open tools for learning-impact telemetry
- What: Pipelines that capture interaction patterns, active coding time, and post-task comprehension at scale.
- How (tools): Open-source IDE plugins; quiz banks emphasizing code reading/debugging; shared datasets for replication.
- Assumptions/Dependencies: Data privacy; consent frameworks; cross-institution collaboration.
- Sector extensions: Generalize beyond software into text, data, and decision-heavy domains
- What: Test and adapt high-skill interaction patterns for law (issue spotting), medicine (diagnostic reasoning), and operations (root-cause analysis).
- How (research/tools): Domain-specific tasks and no-AI evaluations; explain-first assistants tuned to each field.
- Assumptions/Dependencies: Domain expertise; task realism; varied AI error profiles.
- Organizational Analytics: Skill-formation dashboards
- What: Link AI-use patterns with performance and learning metrics for teams.
- How (tools): HR/L&D integrations; alerts when teams drift to delegation-heavy patterns; cohort comparisons.
- Assumptions/Dependencies: Secure telemetry; cultural acceptance; clear KPIs beyond velocity.
- Product Certification: “Learning-safe” AI labels
- What: Independent certification that assistants support skill formation (e.g., defaults to explanations, scaffolding, AI-free testing modes).
- How (ecosystem): Test suites, benchmarks, and third-party audits; marketplace incentives.
- Assumptions/Dependencies: Market demand; credible certifiers; non-gaming of metrics.
Notes on generalizability and dependencies:
- The study focused on short, time-bounded tasks with a specific Python library (Trio) and a chat-based assistant (GPT-4o). Effects may vary for agentic/autocomplete tools, larger projects, different user profiles, or domains.
- Implementations that add friction (reflection gates, explain-first defaults) may briefly reduce throughput; leadership must value long-run capability.
- Telemetry-based features depend on privacy, consent, and secure storage.
- Safety-critical sectors may require additional validation before policy changes.
Glossary
- Agentic (AI): AI systems capable of autonomously planning and executing multi-step actions without constant human prompting. "an agentic or autocomplete setting where composing queries is not required."
- Asynchronous concurrency: Running multiple tasks in overlapping time without blocking, typically via async primitives rather than threads. "which is designed for asynchronous concurrency and input-output processing (I/O)."
- Asynchronous programming: A programming paradigm using constructs like async/await to handle concurrent operations and I/O without blocking. "a new asynchronous programming library"
- Between-subjects randomized experiment: An experimental design where different participants are randomly assigned to distinct conditions. "We use a between-subjects randomized experiment to test for the effects of using AI in the coding skill formation process."
- Cohen's d: A standardized effect size measuring the difference between two means in standard deviation units. "Cohen d=0.738, p=0.01"
- Confidence interval (CI): A range of values that likely contains a population parameter, expressed with a confidence level (e.g., 95%). "Error bars represent 95% CI."
- Covariate: A control variable included in analysis to account for additional sources of variation. "Controlling for warm-up task time as a covariate, the treatment effect remains significant (Cohenâs d=0.725, p=0.016)."
- Effect size: A quantitative measure of the magnitude of a phenomenon, independent of sample size. "we assumed a conservative effect size of d = 0.85"
- Exploratory data analysis (EDA): Informal, pattern-finding analysis conducted to summarize data and generate hypotheses. "In exploratory data analysis (not pre-registered), the quiz score was decomposed into subareas"
- Hallucinated content: Fabricated but plausible-sounding outputs produced by generative AI. "or hallucinated content"
- Item response theory (IRT): A psychometric framework for modeling the relationship between latent traits and test item responses. "based on item response theory."
- Local item dependence: A violation in test design where responses to certain items are correlated beyond the latent trait being measured. "we observed Local Item Dependence in the quiz"
- Memory channels: Trio primitives for asynchronous message passing between tasks. "memory channels to store results."
- Nursery (Trio): A structured concurrency scope that manages the lifecycle of child tasks in Trio. "nurseries, starting tasks, and running functions concurrently in Trio."
- Overreliance: The tendency for humans to uncritically follow AI outputs even when they are wrong. "are referred to as ``overreliance''"
- Power analysis: A statistical procedure to determine the sample size needed to detect an effect of a given size with desired confidence. "For our complete power analysis and pre-registration of the study,"
- Pre-registration: Publicly specifying hypotheses, design, and analysis plans before data collection to reduce bias. "We submitted the grading rubric for the quiz in our study pre-registration before running the experiment."
- Structured concurrency: A concurrency model that organizes concurrent tasks within well-defined scopes to ensure predictable lifetimes and cleanup. "new concepts (e.g., structured concurrency) beyond just Python fluency."
- Treatment effect: The causal impact of an intervention or condition on an outcome. "Significance values correspond to treatment effect."
- Trio (Python library): An asynchronous Python library emphasizing structured concurrency for I/O and task management. "We designed and tested five tasks that use the Trio library for asynchronous programming"
Collections
Sign up for free to add this paper to one or more collections.