- The paper systematically critiques IoT device identification methods, highlighting pitfalls such as data leakage, mislabeling, and overfitting risks.
- It emphasizes rigorous feature engineering and careful model selection, advocating classical methods over deep learning for better interpretability.
- Practical guidelines, including robust evaluation metrics like per-class recall and macro-averaged F1-Score, are recommended for reliable IoT fingerprinting.
Critical Analysis of IoT Device Identification with Machine Learning: Pitfalls and Best Practices
Introduction
The identification of IoT devices through network traffic is foundational for constructing effective network security policies in heterogeneous environments. The paper "IoT Device Identification with Machine Learning: Common Pitfalls and Best Practices" (2601.20548) provides a systematic critique of existing methodologies, highlighting commonly overlooked errors that undermine the reproducibility, scalability, and overall robustness of IoT device fingerprinting pipelines. The authors advocate for a precise alignment between methodological choices at each pipeline stage—scope definition, data preparation, feature extraction, model selection, and evaluation—with the inherent constraints and use cases of IoT deployments.
Device Identification Methods: Taxonomy and Consequences
A critical contribution is the dissection of identification taxonomies—Unique, Type, and Class identification. The paper demonstrates that the approach selected fundamentally influences downstream decisions in feature engineering and model architecture. Unique device identification treats each physical unit as a class, necessitating high-entropy flow-based features and exacerbating overfitting risks. In contrast, class-based identification aggregates devices by function, favoring generalizability but requiring domain knowledge for coherent class definitions.
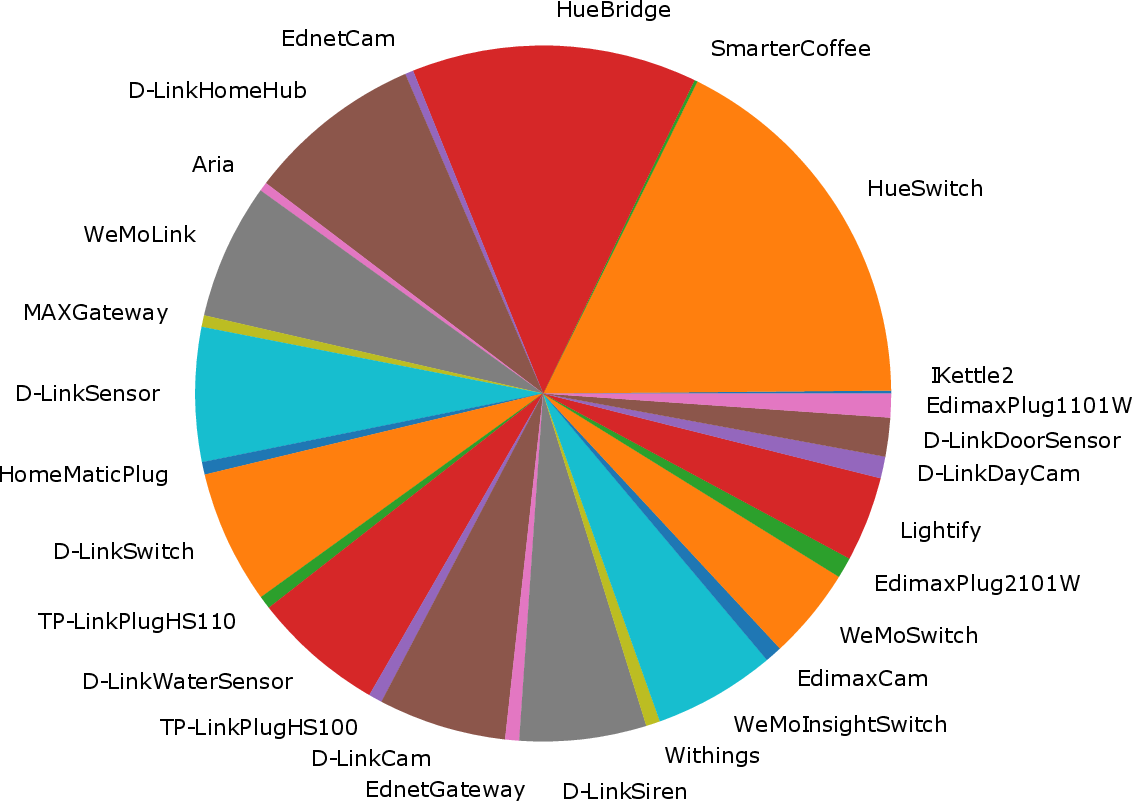
The Aalto University dataset is used as an exemplar, showing dramatically different class counts depending on the granularity of labeling, thus directly affecting the complexity of the classification task.

Figure 1: The Aalto dataset relabeled under three identification approaches, illustrating the impact on class count and heterogeneity.
For each identification goal, the choice and engineering of features (packet-based vs. flow-based) must be rigorously matched. An incongruous selection results in underperformance or brittle models that do not transfer outside the original context.
Data Integrity: Acquisition, Labeling, and Leakage
The paper identifies the prevalence of improper data handling as a major threat to model validity. Three data-related pitfalls are explicitly addressed:
Feature Extraction and Overfitting Risks
Feature engineering is underlined as both an opportunity for model improvement and a major source of overfitting. The inclusion of explicit identifiers (MAC, IP addresses), session-specific values, and derived fields (e.g., checksums encoding sensitive fields) can result in shortcut learning, where the model merely memorizes static patterns.
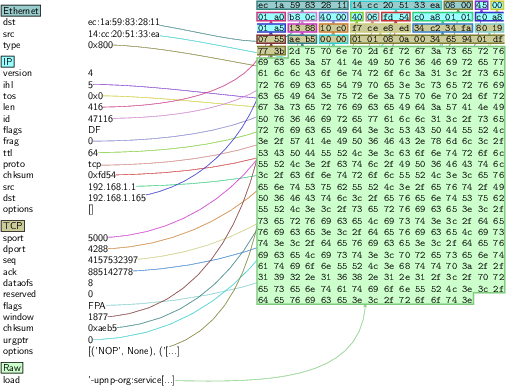
Figure 3: Network packet byte fields, highlighting potential identifier leakage through raw data inputs.
The authors argue for robust sanitation routines, especially for raw-byte feature sets—masking or removing fields that leak device-specific information. They also recommend toolchains that scale on large PCAP collections, endorsing efficient C-based tools over Python-based platforms for initial data handling and filtration.
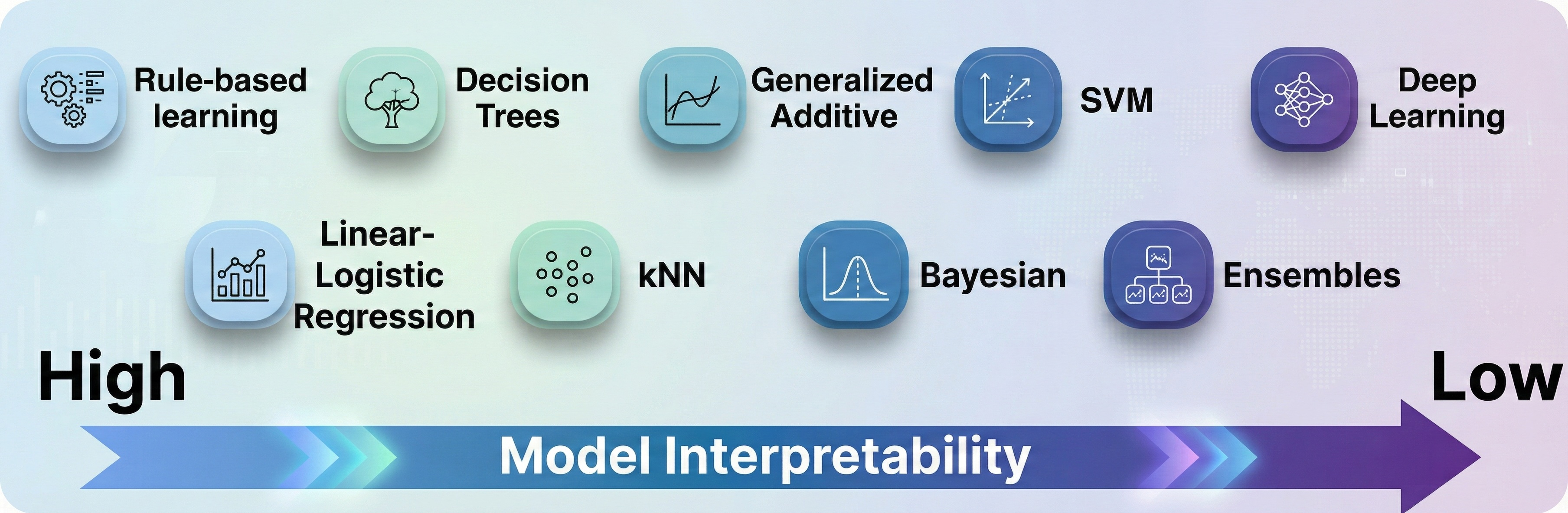
Model Selection: Scalability, Efficiency, and Interpretability
The survey dispels the notion that deep learning is universally optimal, echoing the "No Free Lunch" theorem. For tabular, non-sequential IoT traffic features, classical methods (e.g., Decision Trees) often yield superior accuracy, interpretability, and lower inference latency. The authors emphasize:
Evaluation Metrics and Practical Validity
Reliance on accuracy as the primary reporting metric is forcefully criticized due to its insensitivity to class imbalance. The authors instead promote per-class Recall and macro-averaged F1-Score as diagnostics that correctly reflect minority class performance. They further encourage the use of confusion matrices for error pattern analysis, which supports practical deployment diagnostics by identifying problematic device pairs.
Practical and Theoretical Implications
From a practical perspective, these guidelines will enhance the reproducibility and scalability of IoT device identification systems. The prescriptive alignment between methodology and feature engineering, ethical handling of data sources, and robust statistical evaluation metrics collectively enable more trustworthy ML-based security architectures. Theoretically, the discussion deepens understanding of distribution shift, data leakage, and shortcut learning in the IoT fingerprinting domain, providing a template for transferable methodology across network forensics applications.
Future Directions
The paper’s recommendations foresee an increased emphasis on explainable ML, privacy-preserving analytics, and continual learning systems that can incorporate new device types incrementally with minimal disruption. Further investigation is warranted into synthetic data generation that matches real-world heterogeneity while maintaining train/test set isolation, and into more generalizable feature sets resilient to protocol translation within IoT gateways.
Conclusion
This paper offers a comprehensive and rigorous framework for the design, implementation, and evaluation of ML-based IoT device fingerprinting systems. By exposing systemic pitfalls—data leakage, identifier-based overfitting, inappropriate metric selection—it sets forth concrete best practices that researchers and practitioners can adopt to ensure the real-world reliability and scalability of their solutions. The outlined methodology not only improves empirical reproducibility but also advances the theoretical discourse on secure, interpretable machine learning pipelines for IoT security.