Evolutionary Strategies lead to Catastrophic Forgetting in LLMs
Abstract: One of the biggest missing capabilities in current AI systems is the ability to learn continuously after deployment. Implementing such continually learning systems have several challenges, one of which is the large memory requirement of gradient-based algorithms that are used to train state-of-the-art LLMs. Evolutionary Strategies (ES) have recently re-emerged as a gradient-free alternative to traditional learning algorithms and have shown encouraging performance on specific tasks in LLMs. In this paper, we perform a comprehensive analysis of ES and specifically evaluate its forgetting curves when training for an increasing number of update steps. We first find that ES is able to reach performance numbers close to GRPO for math and reasoning tasks with a comparable compute budget. However, and most importantly for continual learning, the performance gains in ES is accompanied by significant forgetting of prior abilities, limiting its applicability for training models online. We also explore the reason behind this behavior and show that the updates made using ES are much less sparse and have orders of magnitude larger $\ell_2$ norm compared to corresponding GRPO updates, explaining the contrasting forgetting curves between the two algorithms. With this study, we aim to highlight the issue of forgetting in gradient-free algorithms like ES and hope to inspire future work to mitigate these issues.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: can we train LLMs to keep learning new things after they’ve already been deployed, without using a lot of memory? The authors look at a training method called Evolutionary Strategies (ES), which doesn’t need gradients, and compare it to a popular gradient-based method called GRPO. They find that while ES can reach similar performance on new tasks, it makes the model forget skills it already had—a problem known as “catastrophic forgetting.”
Key Objectives
The paper sets out to:
- See how well ES performs compared to GRPO on math and reasoning tasks.
- Measure how much each method makes the model forget older skills while learning new ones.
- Understand why ES causes more forgetting by looking at the kinds of changes it makes to the model’s “knobs” (its parameters).
Methods and Approach
Think of an LLM like a huge machine with millions of tiny knobs that control how it answers questions. Training is about turning the right knobs to do better on a task.
- GRPO (gradient-based): This method is like rolling a ball down a hill and following the steepest path. The “gradient” tells you which knobs to turn and by how much so the model gets better. It’s targeted and usually changes only the knobs that matter.
- ES (gradient-free): This method is more like trying lots of small random tweaks to the knobs and keeping the ones that improve performance. You don’t compute gradients; you just test variations and pick the best. This can save memory because you don’t have to store extra training information.
What the authors did:
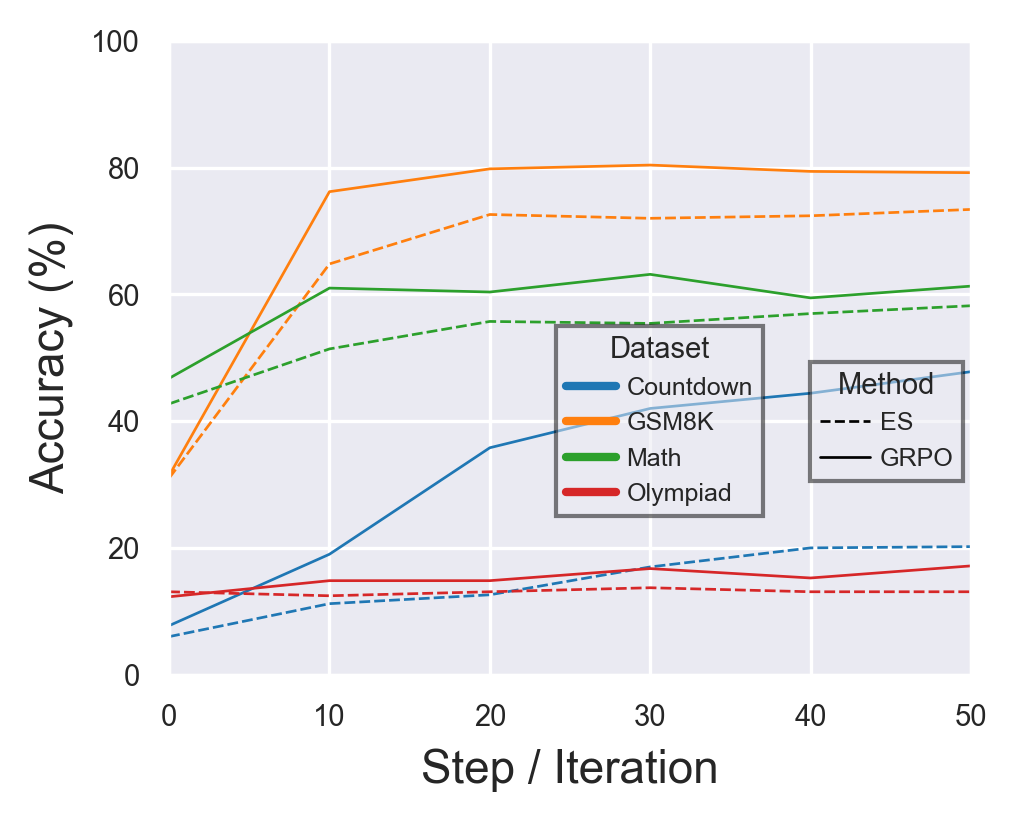
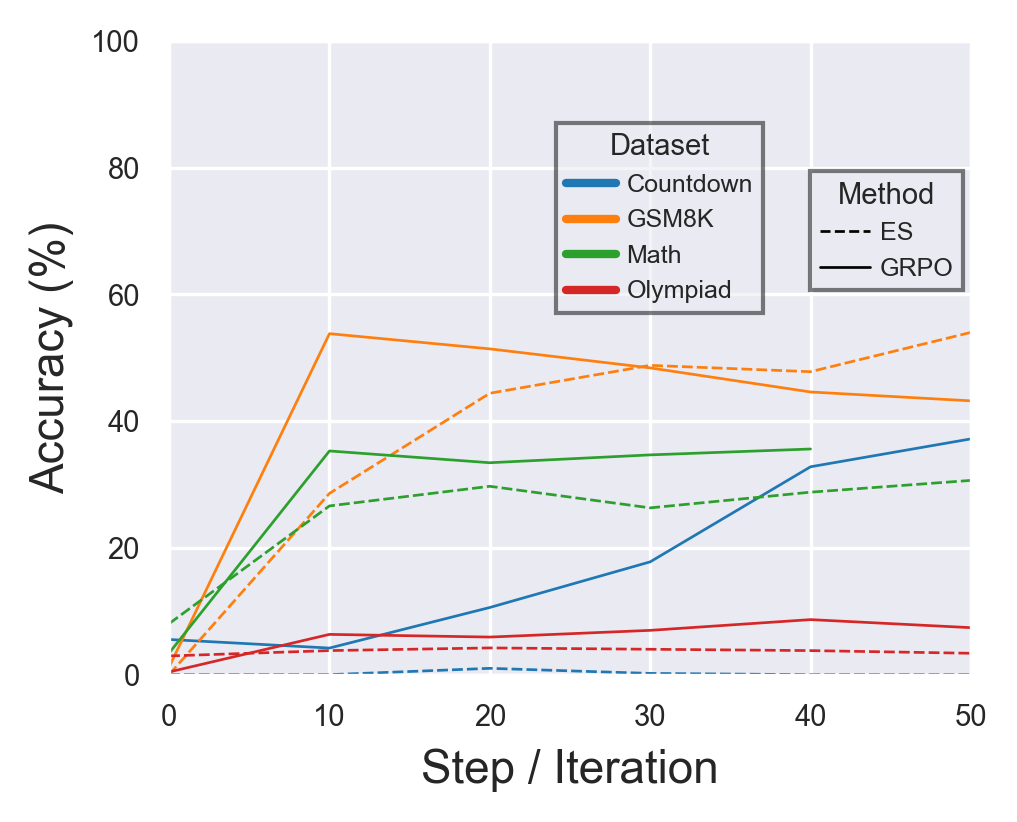
- They trained two small instruction-tuned LLMs (Qwen2.5-1.5B and Llama-3.2-1B) on math and reasoning tasks: GSM8K, MATH, OlympiadBench, and Countdown.
- They measured accuracy on these tasks while training with ES and GRPO using similar compute.
- To check for forgetting, they used a general understanding benchmark called HellaSwag (a test of common sense and sentence completion) to see if the model’s earlier abilities stayed intact.
- They tracked performance over many training steps (iterations) and also analyzed how much the model’s parameters moved:
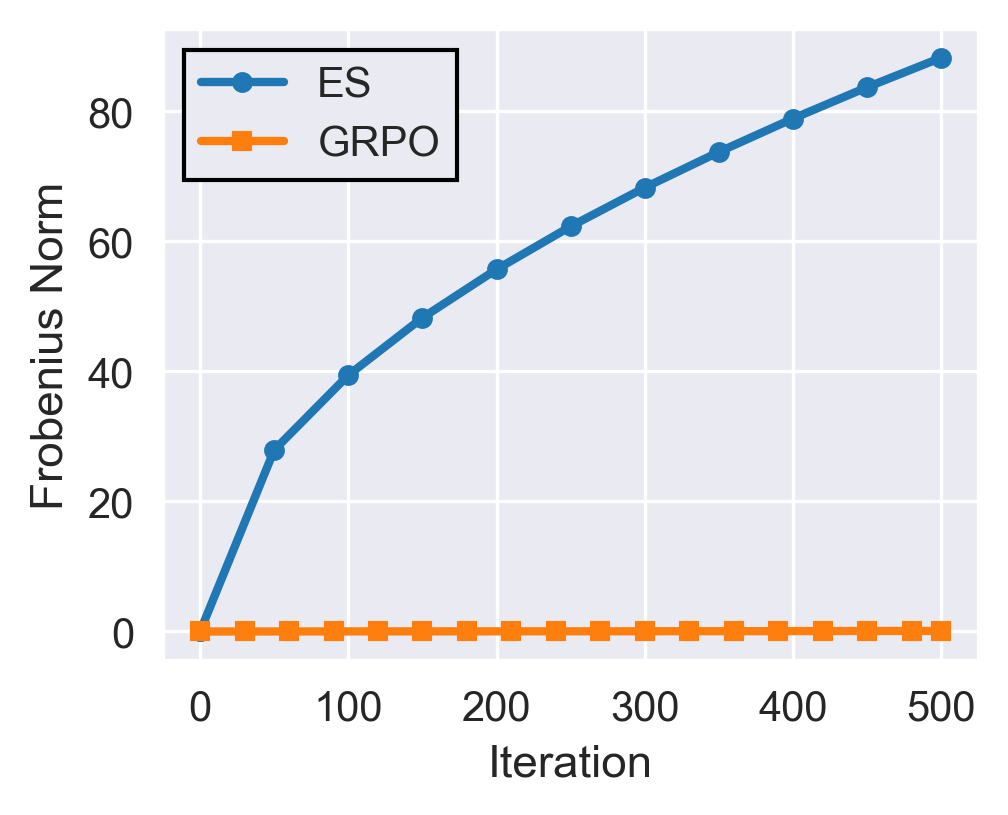
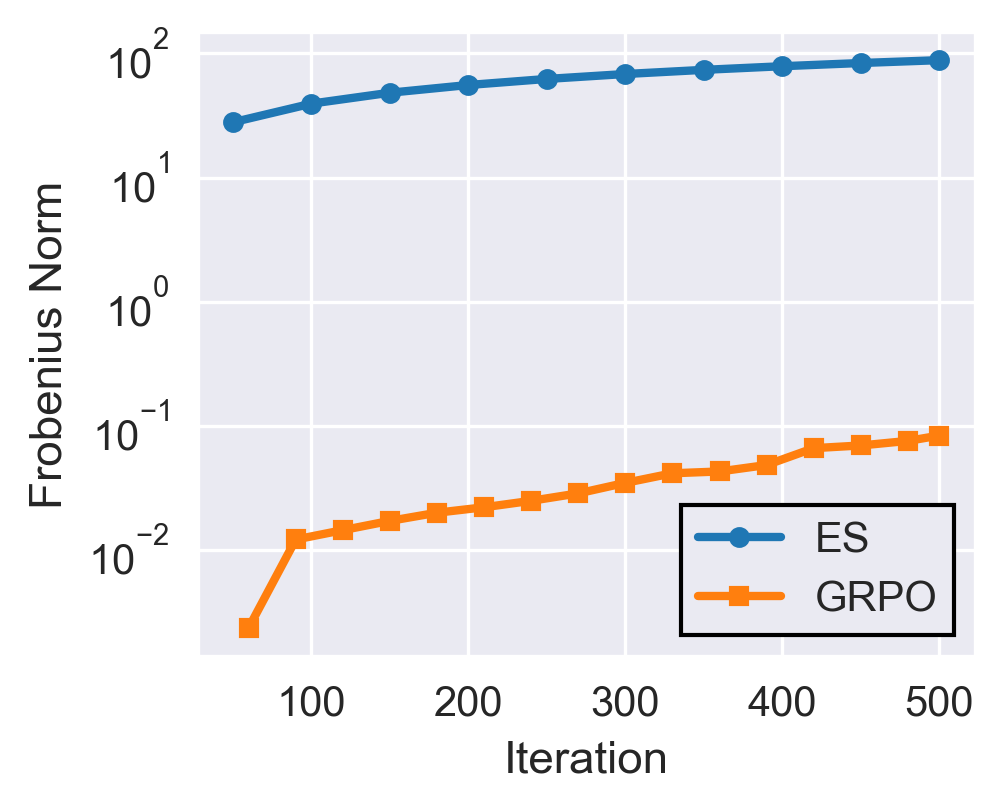
- “How far did the knobs move?” measured by the overall size of changes (the Frobenius or norm—think “distance traveled”).
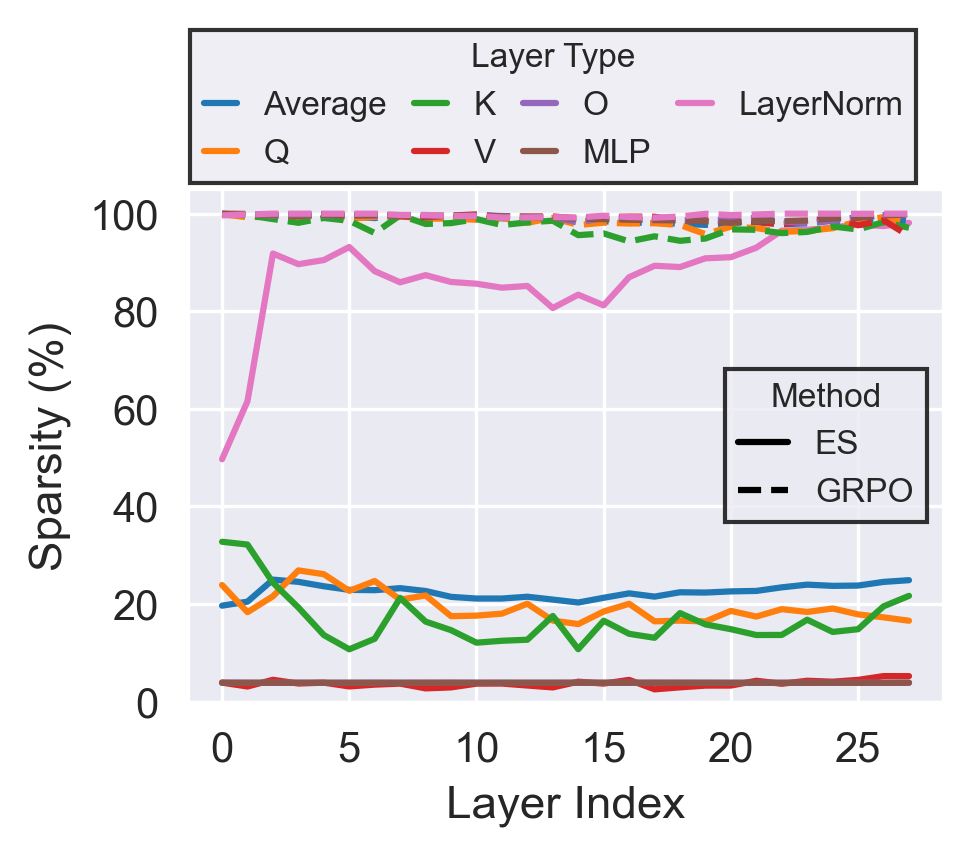
- “How many knobs changed?” measured by sparsity—are changes focused on a few knobs or spread across many?
Main Findings
- ES can be competitive on new tasks:
- ES reached performance close to GRPO on math and reasoning benchmarks, often within a few percentage points, and with similar compute.
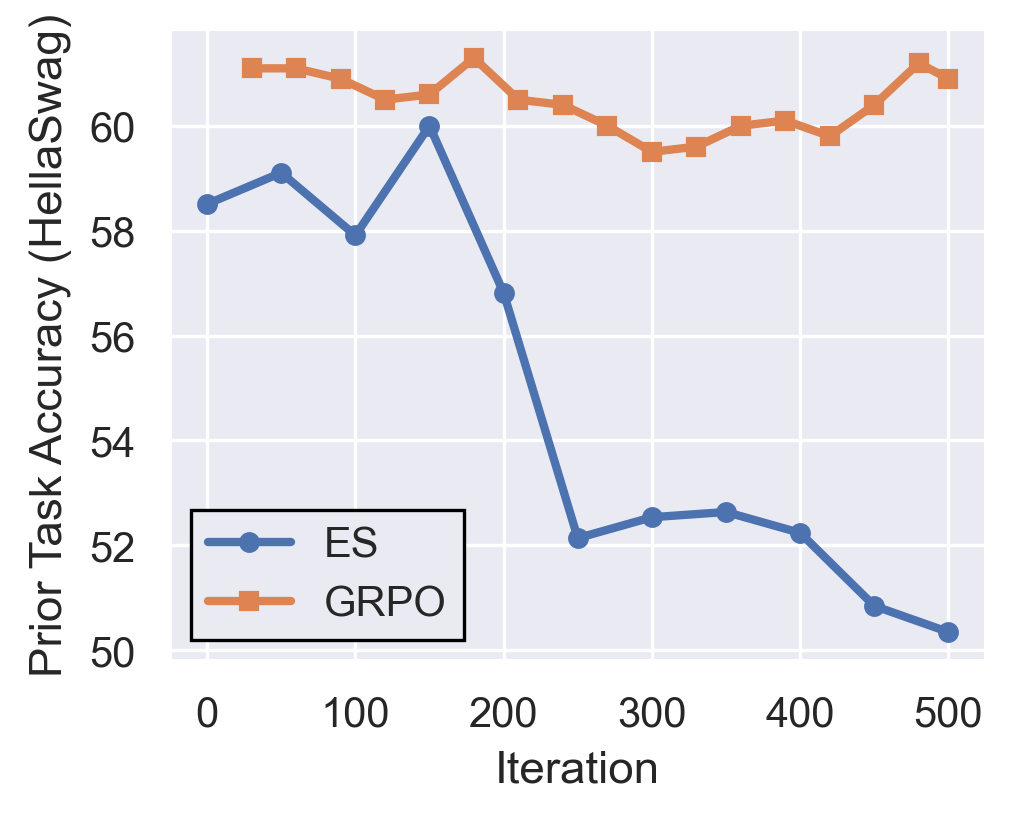
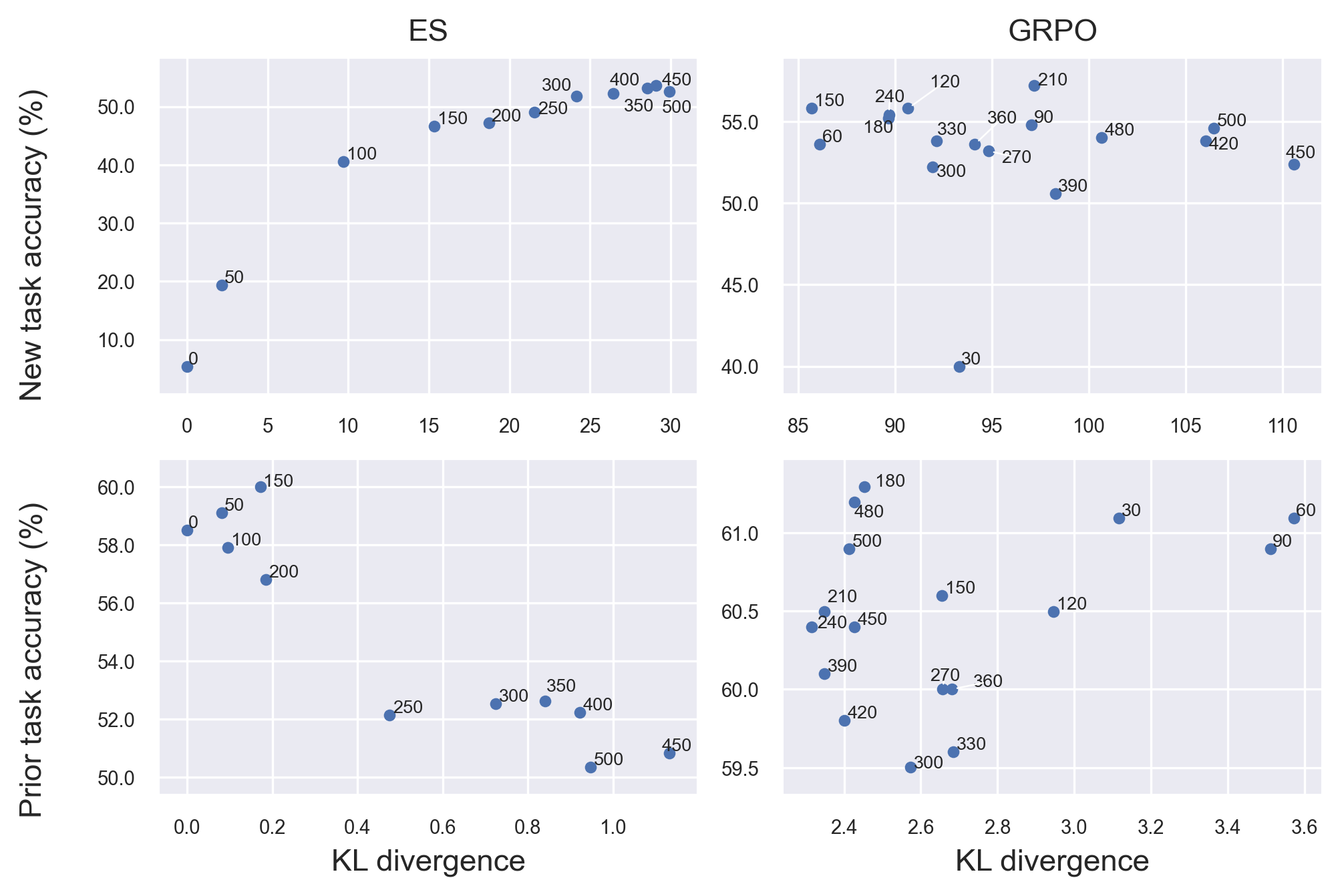
- ES causes significant forgetting of old skills:
- As ES keeps training, the model does better on the new task but steadily gets worse on prior abilities (like HellaSwag).
- Even after the new task performance stops improving, ES keeps pushing changes that further harm old skills.
- GRPO, in contrast, maintains stable performance on old tasks while improving on new ones.
- Why ES forgets more:
- ES updates are large and spread out:
- The total “distance” the model moves (update norm) under ES is orders of magnitude bigger than under GRPO after the same number of steps.
- ES changes a lot of knobs across many layers (low sparsity), which can disrupt previously learned skills.
- GRPO updates are smaller and more targeted:
- Most changes are concentrated in a small subset of parameters (high sparsity), so older skills are less disturbed.
- ES updates are large and spread out:
In simple terms: ES feels like turning lots of knobs all over the machine at once, which can mess up settings that were already working. GRPO is more like carefully adjusting only the few knobs that matter for the new task, leaving the rest alone.
Why This Is Important
If we want AI systems that keep learning after they’re deployed—say, to adapt to new user preferences or new kinds of questions—we need training methods that don’t make them forget what they already know. ES looks attractive because it’s memory-friendly and parallelizable, but this study shows a big caveat: it can cause “catastrophic forgetting,” making the AI less reliable over time.
Implications and Potential Impact
- For continual learning: ES, in its current form, may not be a good choice for training models online (during deployment) because it harms older abilities. GRPO is more stable and preserves prior skills better.
- For future research: The paper highlights the need to fix ES’s forgetting—perhaps by making its updates smaller, more targeted (sparser), or adding regularization to limit how far the model drifts from its base settings.
- For practitioners: If you need an LLM to keep learning safely, prefer gradient-based methods like GRPO or combine ES with safeguards to reduce forgetting.
Overall, the paper’s message is: ES can match GRPO on performance for new tasks with similar compute, but it currently trades that off with losing old knowledge. Solving this trade-off is key to building AIs that learn continuously without forgetting.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research:
- External validity across scales: results are limited to 1–1.5B-parameter models; it is unknown whether ES forgetting persists, worsens, or improves at 7B–70B scales and beyond.
- Task diversity: conclusions stem from math/reasoning and a single prior-task probe (HellaSwag); effects on broader capabilities (e.g., MMLU, BBH, ARC-C, commonsense, safety/alignment, multilingual) remain untested.
- Single prior-task proxy: using HellaSwag alone may not capture multifaceted retention; a standardized multi-benchmark retention suite is needed to quantify general ability drift.
- Sequential continual-learning regimes: forgetting is assessed within one run; performance across realistic sequences (A→B→C) and interleaved or curriculum schedules is unexplored.
- Mitigation strategies for ES: no evaluation of mechanisms that might reduce forgetting (e.g., KL/trust-region constraints to a reference model, weight decay/L2, orthogonal updates, selective layer freezing, replay/interleaving, elastic weight consolidation-like penalties).
- ES design space: only one ES variant is studied; the impact of CMA-ES, NES, mirrored sampling, antithetic sampling, rank-based utilities, gradient surrogates, or hybrid ES+gradient methods on forgetting is unknown.
- Population and noise ablations: catastrophic forgetting is attributed to high-variance/global updates, but systematic ablations over population size, perturbation variance σ, annealing schedules, and utility normalization are missing.
- Parameter-efficient ES: the paper does not test LoRA/adapters/prefix-tuning within ES; whether PEFT reduces update norms/density and mitigates forgetting is open.
- Layerwise/structured perturbations: whether constraining ES to specific modules (e.g., attention vs MLP, upper vs lower layers) can localize updates and preserve prior skills is untested.
- Compute–memory trade-offs: claims of ES memory efficiency are not quantified; there is no head-to-head comparison of peak memory, wall-clock, throughput, and energy vs GRPO/PEFT on identical hardware.
- Hyperparameter fairness and tuning: ES and GRPO use fixed hyperparameters “across tasks”; task-specific tuning, budgets, and fairness protocols (including reward scaling and KL coefficients) are not explored and may affect conclusions.
- Statistical robustness: results lack multiple seeds, confidence intervals, and variance reports—especially important given ES stochasticity—limiting reliability claims.
- Early stopping and over-optimization: ES degrades after new-task convergence; principled stopping criteria or adaptive regularization to prevent post-convergence drift are not investigated.
- Objective-level constraints: GRPO commonly uses KL penalties/trust regions; ES is evaluated without analogous constraints. Whether ES with explicit KL-to-reference (or trust-region ES) prevents large-norm drifts is unknown.
- Reward model/prompting confounds: differences in sampling, decoding parameters, reward shaping, and prompt formats across methods are not fully controlled or ablated.
- Data regime constraints: fine-tuning uses only 200 training examples per task; the interaction between data scale and ES forgetting (few-shot vs large-scale) is uncharacterized.
- Generalization vs memorization: no analysis of whether ES gains come from shallow memorization of small datasets vs genuine reasoning improvements that transfer across benchmarks.
- Update-norm and sparsity methodology: Frobenius norm and a fixed |ΔW|<1e−6 sparsity threshold can bias comparisons across parameter groups; sensitivity analyses (relative thresholds, per-tensor normalization, top-k sparsity, per-layer scaling) are missing.
- Representation-level drift: only weight-space metrics are analyzed; activation/representation similarity (e.g., CKA/CCA), Fisher overlap, or logit lens diagnostics to link drift to forgetting are absent.
- Per-layer dynamics: while layerwise sparsity is reported, the causal role of specific layers (e.g., lower vs higher, attention vs MLP) in driving forgetting is not dissected via targeted interventions.
- Interaction with decoding-time controls: how decoding temperature, nucleus sampling, or routing mechanisms interact with ES-induced drift and measured accuracy is not studied.
- Safety and calibration: effects of ES on toxicity, hallucination rates, calibration, and robustness (adversarial prompts, distribution shift) are not evaluated.
- Energy efficiency and cost: claimed practicality for deployment-time learning lacks energy and monetary cost analyses compared to strong PEFT/RL baselines.
- Theoretical grounding: the observed link between high-norm, dense ES updates and forgetting is correlational; a formal analysis (e.g., interference in parameter subspaces, stability bounds) is missing.
- Hybrid or alternating training schedules: whether alternating ES with small gradient steps (or projecting ES updates into GRPO-identified subspaces) maintains performance while preserving prior skills remains unexplored.
- Continual evaluation protocols: a standardized forgetting curve protocol—with checkpoints, mixed-task validation, and retention metrics (e.g., backward/forward transfer)—is not established for gradient-free LLM fine-tuning.
Glossary
- Attention output projection (W_O): The linear transformation that maps concatenated multi-head attention outputs back to the model’s hidden dimension. "the attention output projection , MLP layers and LayerNorms."
- Attention projections (Q, K, V): The query, key, and value linear projections used to compute attention weights and values in transformer attention. "including attention projections , the attention output projection , MLP layers and LayerNorms."
- Catastrophic forgetting: A phenomenon where learning new tasks degrades performance on previously learned skills. "it is also accompanied by ``catastrophic'' forgetting \cite{kirkpatrick2017overcoming, gupta2024model} of prior abilities of the model."
- CMA-ES: Covariance Matrix Adaptation Evolution Strategy; an ES variant that adapts the covariance of the mutation distribution for efficient black-box optimization. "implementations such as CMA-ES \cite{hansen2001completelyderandomizedselfadaptationinevolutionstrategies} and natural ES \cite{wierstra2011naturalevolutionstrategies, sun2012efficientnaturalevolutionstrategies} demonstrated success"
- Countdown: A benchmark/task used for evaluating arithmetic/reasoning in LLMs in this study. "in addition to the Countdown dataset which was extensively studied in prior work \cite{qiuEvolutionStrategiesScale2025}."
- DPO: Direct Preference Optimization; a preference-based post-training method that optimizes models directly from pairwise preferences without a learned reward model. "DPO \cite{rafailov2024directpreferenceoptimizationlanguage}"
- ES (Evolutionary Strategies): A family of gradient-free optimization algorithms that estimate updates via randomized parameter perturbations over a population. "Evolutionary Strategies (ES) have recently re-emerged as a gradient-free alternative for optimizing LLMs."
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, used here to quantify the magnitude of parameter changes between checkpoints. "We measure the Frobenius norm between model checkpoints within a training run."
- GRPO: A reinforcement-learning-based fine-tuning algorithm that optimizes policies using group-relative preferences. "We first find that ES is able to reach performance numbers close to GRPO for math and reasoning tasks with a comparable compute budget."
- GSM8K: A benchmark of grade-school math word problems used to evaluate reasoning in LLMs. "GSM8K \citep{cobbe2021trainingverifierssolvemath}"
- HellaSwag: A commonsense inference benchmark for sentence completion used here to assess retention of prior capabilities. "HellaSwag \citep{zellers2019hellaswagmachinereallyfinish} was used to evaluate LLMs on their prior capabilities."
- In-context learning: Conditioning a model on examples or instructions in the prompt to adapt behavior without updating weights. "and use in-context learning \cite{brown2020language} to incorporate this information"
- KL regularization: Regularization that penalizes the Kullback–Leibler divergence from a reference model/policy to constrain updates and prevent drift. "When combined with KL regularization, these mechanisms provide a natural safeguard against large-scale parameter drift and, consequently, catastrophic forgetting."
- L2 norm: The Euclidean norm of a parameter update vector; used to quantify update magnitude. "orders of magnitude larger norm compared to corresponding GRPO updates"
- LayerNorms: Normalization layers applied per feature across tokens to stabilize and accelerate training. "including attention projections , the attention output projection , MLP layers and LayerNorms."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects trainable low-rank matrices into weight matrices. "can be modified with LoRA adaptions \cite{jin2024derivativefreeoptimizationlowrankadaptation, korotyshova2025essaevolutionarystrategiesscalable, sarkar2025evolutionstrategieshyperscale}"
- MATH: A benchmark of competition-style mathematical problems used to measure mathematical problem-solving in LLMs. "MATH \citep{hendrycks2021measuringmathematicalproblemsolving}"
- Natural ES: Natural Evolution Strategies; ES methods that estimate and follow the natural gradient in parameter space for black-box optimization. "natural ES \cite{wierstra2011naturalevolutionstrategies, sun2012efficientnaturalevolutionstrategies} demonstrated success"
- OlympiadBench: A benchmark of olympiad-level scientific problems designed to stress-test advanced reasoning. "OlympiadBench \citep{he2024olympiadbenchchallengingbenchmarkpromoting}"
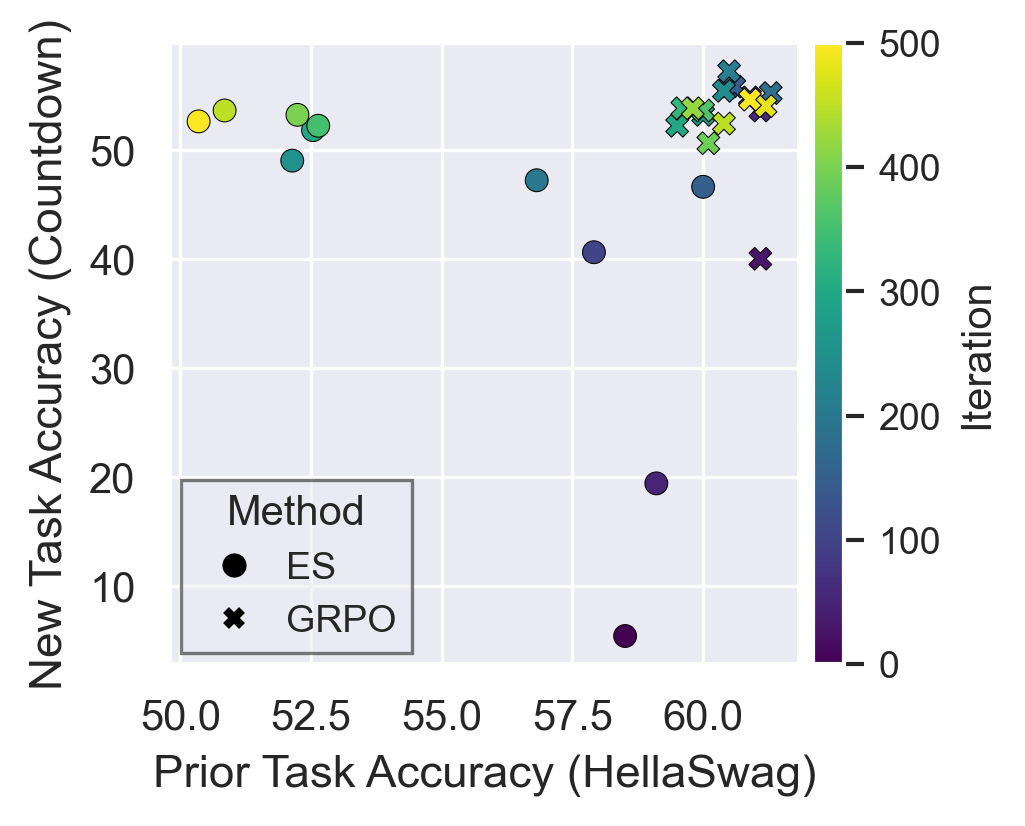
- Pareto front: The set of trade-off optimal points balancing multiple objectives; here, new-task vs prior-task performance. "Pareto front between new task (Countdown) and old task (HellaSwag) performance across fine-tuning with ES and GRPO."
- Population-level perturbations: Parameter noise injected across a population of model copies to estimate gradients or search directions without backprop. "By estimating updates through population-level perturbations rather than backpropagation, ES avoids explicit gradient storage"
- RLHF: Reinforcement Learning from Human Feedback; training that optimizes a model using human preference signals. "RLHF \citep{ouyangTrainingLanguageModels2022}"
- SFT: Supervised Fine-Tuning; post-training using labeled examples to align model outputs. "SFT \cite{wei2022finetunedlanguagemodelszeroshot}"
- Sparsity: The proportion of near-zero entries in a vector/tensor; here, measuring how concentrated parameter updates are. "we define sparsity as the percentage of elements whose absolute magnitude is below a fixed threshold ()."
Practical Applications
Practical Applications Derived from the Paper
Below are actionable applications that translate the paper’s findings into real-world impact. Items are grouped by deployment horizon and, where relevant, tagged with sectors and potential tools/workflows. Each item concludes with assumptions or dependencies that may affect feasibility.
Immediate Applications
- Prefer GRPO over ES for any continual-learning or safety-critical fine-tuning
- Sectors: healthcare, finance, education, enterprise software, robotics
- What to do: For any system that must retain prior capabilities while learning a new task (e.g., a clinical summarizer that must not lose general comprehension), use GRPO (or similar gradient-based methods with KL control) rather than ES.
- Tools/workflows: Add “retention gates” in training pipelines that block deployment if prior-task metrics drop beyond a threshold.
- Assumptions/dependencies: Findings measured on 1B–1.5B models and specific tasks; generalization to much larger models is likely but not yet proven.
- Use ES for single-task, memory-constrained fine-tuning where retention is not required
- Sectors: on-device assistants, embedded/edge AI, robotics prototypes, A/B test sandboxes
- What to do: If you only need to add a narrow capability (e.g., a better math solver on an edge device) and do not care about prior-skill preservation, ES is a low-memory, highly parallelizable option.
- Tools/workflows: Short ES runs with strict early stopping at peak validation performance; keep base model snapshots for rollback.
- Assumptions/dependencies: Forgetting is expected; do not deploy for multi-skill systems without additional safeguards.
- Add prior-capability monitors to all fine-tuning jobs (retention-aware evaluation)
- Sectors: MLOps across industries
- What to do: Track at least one broad prior benchmark (e.g., HellaSwag or domain-specific regressions) during training, not just the new task.
- Tools/workflows: “Forgetting dashboard” that plots new-task vs prior-task accuracy over iterations (Pareto front), and triggers early stop/rollback.
- Assumptions/dependencies: Requires curated, stable prior-task test sets; compute overhead for continuous evaluation.
- Enforce update-norm budgets and sparsity checks during training
- Sectors: enterprise software, safety-critical AI, LLM platforms
- What to do: Compute ΔW Frobenius norm and layer-wise update sparsity each checkpoint; halt or regularize when drift exceeds a budget.
- Tools/workflows: MLOps plugin that computes ΔW norms and sparsity histograms; policy: “no-deploy if ΔW > X or sparsity < Y%.”
- Assumptions/dependencies: Access to model parameters (or adapter weights) is required; may need parameter-efficient fine-tuning to make ΔW tracking practical.
- Default to parameter-efficient adapters when experimenting with ES
- Sectors: software, edge AI, robotics
- What to do: If using ES at all, confine it to LoRA/adapters to localize change and simplify rollback.
- Tools/workflows: “ES-on-adapters” recipe with tight early stopping and frequent checkpointing.
- Assumptions/dependencies: While the paper cites LoRA compatibility, it does not quantify forgetting under LoRA with ES; risk remains.
- Production safety guardrails for self-updating models
- Sectors: healthcare, finance, legal, customer support
- What to do: Disallow “always-on” ES updates in production. If post-deployment learning is needed, run updates offline, validate retention, then ship.
- Tools/workflows: Shadow-model training + canary tests; immutable baseline + differential audits (ΔW and metric deltas).
- Assumptions/dependencies: Requires CI/CD for models and rigorous offline evaluation loops.
- Replace weight-updating “personalization” with retrieval or memory for consumer apps
- Sectors: daily-life assistants, education apps
- What to do: Use user memory (structured notes) and retrieval augmentation instead of ES-based on-device learning to avoid degrading general abilities.
- Tools/workflows: RAG pipelines and per-user context stores; user controls to edit/forget memories.
- Assumptions/dependencies: UX and data infra for memory/RAG; may trade off latency for stability.
- Internal benchmarking updates: include forgetting curves when evaluating new optimizers
- Sectors: academia, labs, platform vendors
- What to do: Always report new-task performance together with retention dynamics (prior-task curves).
- Tools/workflows: Standardized protocol: new-task metric, prior-task metric(s), ΔW norm trajectory, sparsity profile per layer.
- Assumptions/dependencies: Agreement on common prior-task suites by domain.
- Procurement and risk assessments for “gradient-free continual learning” claims
- Sectors: policy/governance, enterprise IT
- What to do: Require vendors claiming on-device/gradient-free continual learning to provide forgetting curves and update-norm budgets.
- Tools/workflows: Model change impact assessment (MCIA) checklist; third-party validation of retention.
- Assumptions/dependencies: Organizational policy and governance processes must incorporate technical acceptance criteria.
- Rapid prototyping of reasoning boosts without long-term model drift
- Sectors: education, coding assistants, math tutoring
- What to do: Use ES to quickly explore performance gains on narrow reasoning tasks, then retrain or rebase on GRPO for production.
- Tools/workflows: ES “search sprint” → freeze best checkpoint → reproduce with GRPO (or supervised/RLHF) before shipping.
- Assumptions/dependencies: Extra training cycles to convert ES-found gains into stable, gradient-based updates.
Long-Term Applications
- Retention-aware ES algorithms (multi-objective ES)
- Sectors: software platforms, robotics, edge AI
- What to build: ES variants that jointly optimize new-task reward and retention metrics (e.g., HellaSwag accuracy, KL-to-baseline, ΔW norm penalty).
- Potential products: “Retain-ES” optimizer with trust regions and norm budgets; CMA-ES with retention objectives.
- Assumptions/dependencies: Research needed to balance objectives and avoid mode collapse; scaling studies on larger models.
- Sparse and low-norm ES update techniques
- Sectors: all sectors using continual learning
- What to build: ES with structured perturbations (layer-targeted, low-rank, subnetwork-only), orthogonal noise, or proximal constraints to enforce sparsity/low ΔW.
- Potential products: “SubNet-ES” that perturbs only task-relevant subnetworks; ΔW-regularized ES with automatic budget scheduling.
- Assumptions/dependencies: Methods must maintain ES’s memory/parallelism benefits while preserving retention.
- Hybrid ES + gradient methods with retention control
- Sectors: enterprise AI, research labs
- What to build: ES for exploration to propose candidate directions; gradient-based fine-tuning (GRPO/DPO/SFT) to consolidate changes with KL and sparsity constraints.
- Potential products: “ES-to-GRL” pipeline that converts ES proposals into safe gradient steps; population-informed warm starts for GRPO.
- Assumptions/dependencies: Pipeline engineering and new theory for transfer between zeroth- and first-order updates.
- Governance standards for self-updating models
- Sectors: policy/regulation, safety bodies, certification
- What to build: Standards requiring retention testing, update-norm auditing, and rollback plans for any online-learning model.
- Potential products: Certification labels for “Retention-Safe Continual Learning” with published forgetting curves and ΔW budgets.
- Assumptions/dependencies: Multi-stakeholder consensus and third-party audit ecosystems.
- Continual-learning safety monitors embedded in model servers
- Sectors: platform vendors, cloud providers
- What to build: Real-time monitors that track prior-task probes, ΔW norms, layer-wise sparsity, KL-to-baseline, and trigger throttling/rollback.
- Potential products: “CL Safety Monitor” sidecar for Triton/Inferentia/ONNX runtimes.
- Assumptions/dependencies: Access to model deltas or adapters; efficient telemetry to avoid latency spikes.
- On-device personalization via adapters with retention guarantees
- Sectors: mobile/edge, consumer devices, automotive
- What to build: Adapter-only online updates with strict ΔW budgets, per-user adapter banks, and cloud-verified retention snapshots.
- Potential products: “Personalization Vault” with adapter rotation and automatic rebase to maintain general skills.
- Assumptions/dependencies: Secure storage, privacy controls, and standardized adapter interfaces across devices.
- Robotics policies that avoid skill erosion during lifelong learning
- Sectors: robotics, manufacturing, logistics
- What to build: ES-inspired exploration constrained to specific modules or behaviors, combined with retention penalties for previously mastered skills.
- Potential products: “Skill-Preserving Learner” that uses sub-policy ES plus EWC-like penalties or KL-to-reference controllers.
- Assumptions/dependencies: Task decomposition and robust evaluation suites for previously learned skills.
- Domain-specific retention suites for regulated industries
- Sectors: healthcare, finance, legal
- What to build: Canonical prior-capability testbeds (e.g., medical comprehension, dosage safety, regulatory math) to accompany any new fine-tuning.
- Potential products: Industry “retention packs” (datasets + metrics + acceptance thresholds) integrated with CI/CD.
- Assumptions/dependencies: Data access, governance approvals, and community maintenance.
- Educational tooling for safe model adaptation in classrooms
- Sectors: education/EdTech
- What to build: Teaching modules and labs demonstrating forgetting curves, ΔW norms, and safe adaptation recipes.
- Potential products: “Continual Learning Lab” with interactive dashboards and reproducible notebooks leveraging the authors’ released code/models.
- Assumptions/dependencies: Instructor adoption and simplified compute footprints.
- Organizational playbooks for model change management
- Sectors: enterprise AI operations
- What to build: SOPs that define change budgets (ΔW, KL), retention SLAs, shadow evaluation, and sign-off workflows before and after updates.
- Potential products: “Model Change Impact Assessment” templates and automation that integrate with JIRA/ServiceNow.
- Assumptions/dependencies: Executive sponsorship and integration with existing DevSecOps processes.
Notes on cross-cutting assumptions and dependencies:
- The reported forgetting was demonstrated on small instruction-tuned models (Qwen2.5-1.5B, Llama‑3.2‑1B) and specific math/reasoning datasets; replication at larger scales is advised.
- Population size, noise scales, and ES variants may affect forgetting; stronger regularization and subnetwork targeting are promising but require research.
- Prior-task proxies (e.g., HellaSwag) are informative but should be replaced with domain-appropriate retention suites in applied settings.
- Computing ΔW and sparsity may be easiest when using adapter-based fine-tuning rather than full-model updates.
Collections
Sign up for free to add this paper to one or more collections.