TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
Abstract: The Muon optimizer has demonstrated strong empirical performance in pre-training LLMs by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Teon, a new way to train LLMs faster and more reliably. It builds on a recent optimizer called Muon. While Muon improves learning by fixing problems inside each layer of a neural network separately, Teon looks across several layers at the same time. By doing this, Teon can spot and use helpful patterns shared across layers, leading to better training.
What questions does the paper ask?
- Can we make Muon better by letting it “see” connections across multiple layers instead of treating each layer alone?
- Will this cross-layer view make training faster or more stable in theory?
- Does it actually help in practice on real LLMs (like GPT- and LLaMA-style models)?
- What’s the best way to group layers and apply Teon to get the most benefit?
How does the method work? (Everyday explanation)
First, a few simple ideas:
- A gradient is like a piece of advice telling the model how to change its numbers (weights) to make fewer mistakes.
- Orthogonalization means adjusting directions so they don’t overlap—like making sure you move north/south and east/west separately, not diagonally in a messy way. This can make learning more stable.
- A tensor is a multi-dimensional grid of numbers. Think of a stack of sheets of paper: each sheet is a matrix (a table of numbers), and stacking them makes a 3D block (a tensor).
What Muon does:
- Muon takes the gradient “table” for each layer and “orthogonalizes” it (makes the main directions independent), one layer at a time. This helps prevent the gradient from collapsing into just a few directions, which can slow learning.
What Teon does differently:
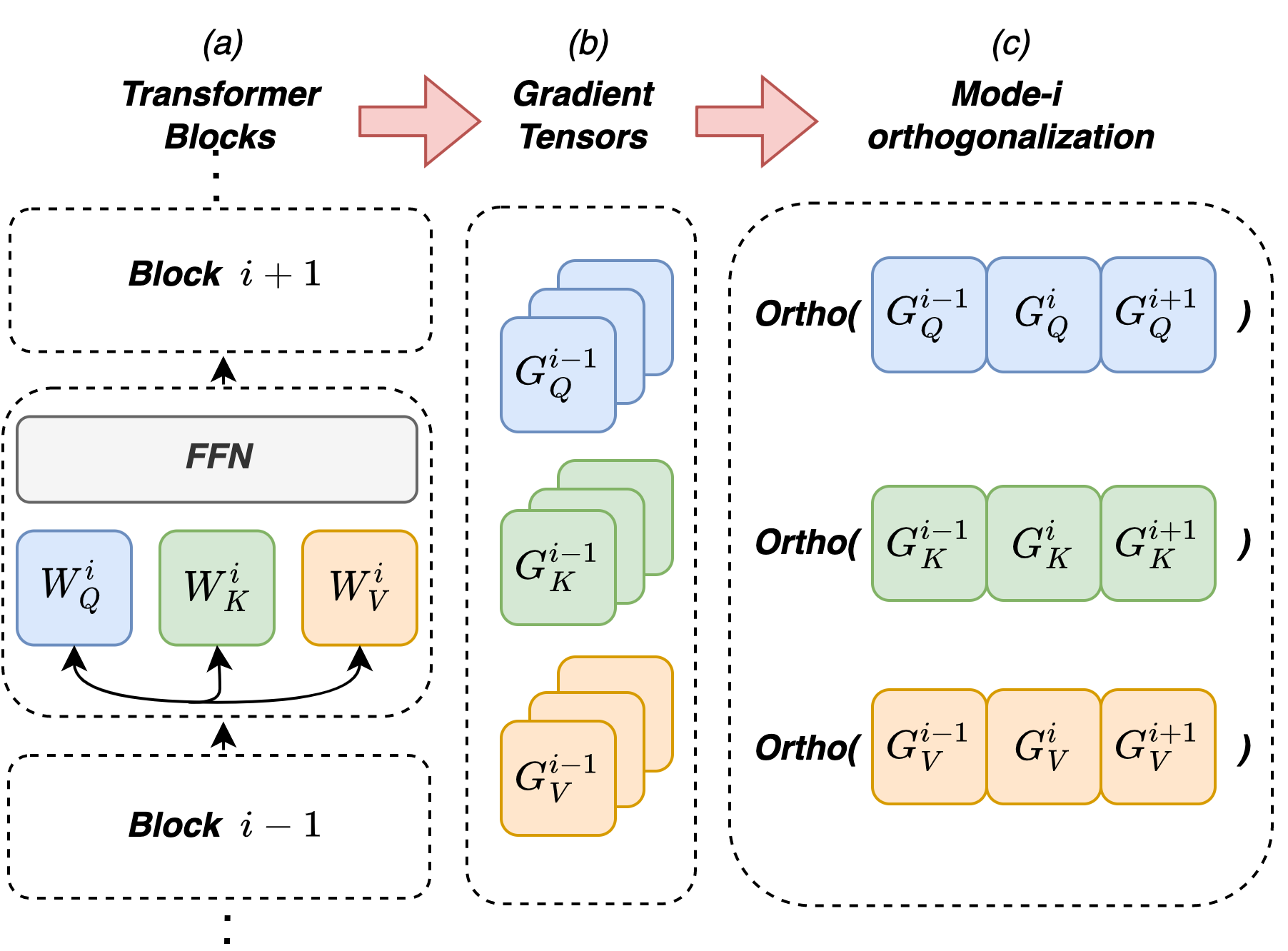
- Teon stacks the gradients from several related layers into a 3D block (a tensor)—like stacking pages into a book—so it can learn from patterns across layers.
- Then Teon “unfolds” this block along one side to turn it into a big table (this step is called “matricization,” like unrolling a poster). After that, it applies the same kind of orthogonalization Muon uses, and then folds it back into the block shape.
- In practice, Teon: 1) Groups K similar layers (often 2 layers works best), 2) Stacks their gradients into a tensor, 3) Unfolds along a chosen “mode” (usually mode-1 works best), 4) Orthogonalizes, 5) Updates all grouped layers together using this improved direction.
Helpful analogy:
- Imagine you’re learning to draw faces. If you only correct each drawing alone, you miss patterns that repeat across drawings (like eye placement). Teon compares several drawings at once, finds shared patterns, and corrects them together—so you improve faster.
A note on “fast math tricks”:
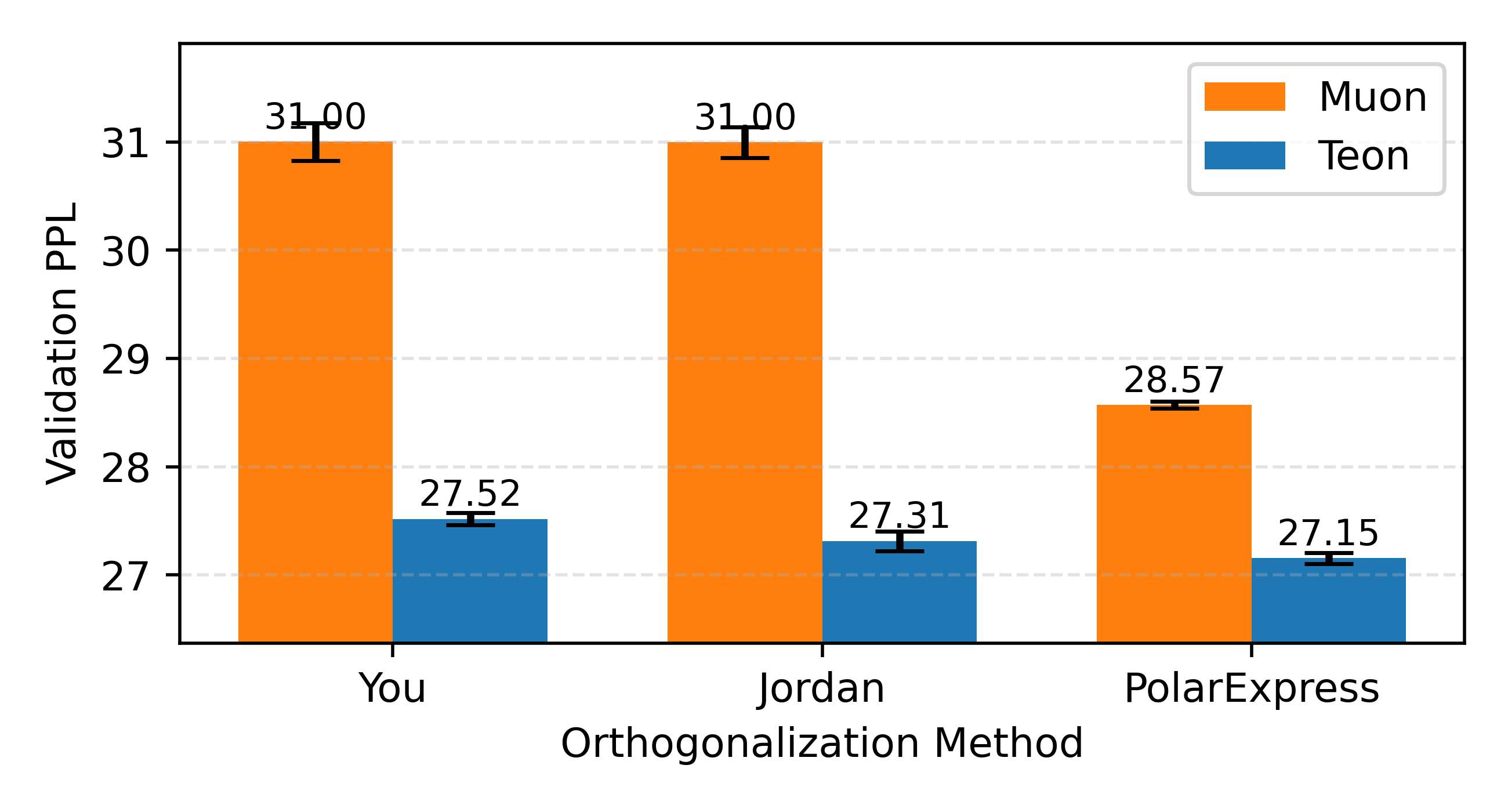
- Orthogonalization often uses a math tool (SVD) that can be costly. The paper tries different fast approximations (“Newton–Schulz,” “PolarExpress,” etc.). You can think of them as shortcuts to find the main directions quickly.
What did the researchers find?
Theory (what the math says):
- Teon can have stronger convergence guarantees than Muon. In simple terms, it can reach good performance in fewer steps or with more stability.
- In the best case, when the grouped layers share similar “main directions,” Teon can be up to about √K times better than Muon (K is the number of layers stacked together). For example, if you stack 4 layers (K=4), the best-case speedup factor is about 2.
Practice (what the experiments show):
- On GPT-style models (from ~130M to ~774M parameters) and LLaMA-style models (from ~60M to ~1B), Teon consistently achieved lower validation perplexity than Muon. Perplexity is a measure of how well the model predicts text—lower is better.
- The gains held across different ways of approximating the math for orthogonalization, making Teon fairly robust.
- Teon’s per-step runtime and memory use were almost the same as Muon, so the improvements come “for free” in terms of cost per step.
What settings worked best:
- Which layers to group: Stacking the attention projection matrices (Q, K, V) from nearby layers worked best. These have similar “output-side” patterns, so Teon’s cross-layer view really helps.
- How many layers to stack (K): K=2 gave the best, most reliable gains. Stacking too many layers can mix in layers that don’t match well, weakening the benefit.
- Which way to unfold (mode): Mode-1 (think “unroll along rows”) usually worked best, matching the observed pattern similarities.
Why is this important?
- Better training efficiency: If your optimizer (the training “coach”) extracts more value from each step, you can train large models faster or to a better final quality with the same compute.
- Scales to big models: The tests on common LLM families (GPT and LLaMA) show the idea works beyond toy cases.
- Robust and practical: Teon improves results even with fast approximation tricks and without extra per-step cost, making it practical for large-scale use.
What could this change in the future?
- Cheaper and greener training: If models learn faster, we can save energy and money, which matters as AI models keep growing.
- General tool for optimizers: Teon shows that looking across layers (not just within a single layer) can unlock extra performance. This cross-layer idea could inspire new optimizers or be combined with other training tricks.
- Guidance for practitioners: If you use Teon, start by stacking Q/K/V from two neighboring layers and use mode-1 unfolding. This setup is a good balance of gains and stability.
In short, Teon teaches big models by comparing and correcting several layers at once, not just one-by-one. That cross-layer perspective helps models learn more effectively—with strong theory behind it and solid results in practice.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Scalability to frontier-scale LLMs: Results top out at ~1B parameters and ≤10–13B tokens. It is unknown whether Teon’s gains persist for 10B–100B+ models, longer contexts, and multi-hundred-billion-token pretraining.
- Downstream utility: Evaluation focuses on validation perplexity. Effects on zero-/few-shot tasks, instruction-tuning, RLHF, multilingual/multimodal benchmarks, and robustness tasks remain untested.
- Runtime and memory profiling: The paper asserts Teon and Muon have “almost identical per-step cost” without measurements. End-to-end throughput, wall-clock time, GPU memory usage, kernel efficiency, and scaling under data/model/pipeline parallelism are not reported.
- Distributed systems implications: Teon stacks gradients across layers; the communication and scheduling impact under pipeline parallelism (when stacked layers span pipeline stages) and gradient accumulation schemes is not analyzed.
- Generality across architectures: Applicability to encoder–decoder Transformers, MoE, ViTs/CNNs, RNNs, and non-Transformer blocks is untested. Behavior for convolutional kernels and attention variants (e.g., multi-query, grouped-query) is unclear.
- Coverage of parameter types: Embeddings, unembeddings, norms, and positional encodings are excluded (kept on AdamW). Whether and how Teon can safely/beneficially handle these parameter classes is not explored.
- Grouping policy design: Teon stacks consecutive, same-type layers (Q/K/V) with fixed K=2. It is unknown whether non-consecutive groupings, depth-varying K, cross-attention groupings (in enc–dec), or learned/automatic group discovery (e.g., by maximizing singular-vector alignment) improve results.
- Mode selection: Only mode-1 is used in practice; mode-2 is briefly tested, mode-3 is dismissed due to imbalance. There is no systematic policy for adaptive mode selection based on measured left/right singular-vector alignment during training.
- Tensor-orthogonalization variants: The paper uses matricization + matrix orthogonalization. Alternative tensor formulations (e.g., HOSVD/Tucker/CP, TT, block-orthogonalization, Kronecker factorizations) and their trade-offs are unexamined.
- Approximate orthogonalization error: Theoretical bounds do not incorporate approximation error of Ortho(·) (Newton–Schulz, PolarExpress, etc.). How such errors propagate, how many iterations are needed for stability, and how to couple step sizes/momentum to these errors remain open.
- Numerical stability on ill-conditioned shapes: Teon’s gains degrade with highly rectangular matrices (e.g., MLP layers) under approximate SVD. Mitigations (preconditioning, normalization, shape-aware conditioning, mixed-precision strategies) are not proposed or evaluated.
- Dynamic alignment characterization: While empirical plots show top singular-vector alignment for Q/K/V, a quantitative, time-resolved characterization of alignment across depth and training (and its link to gains vs. K) is missing.
- Adaptive K and stacking windows: Fixed K=2 is chosen via ablation; no adaptive mechanism adjusts K based on observed alignment, training phase, layer depth, or approximation quality.
- Interaction with other optimizers/preconditioners: How Teon composes with AdamW for excluded parameters, or with second-order/adaptive methods (Shampoo, Sophia, Lion, K-FAC, Gauss-Newton) is unexplored.
- Hyperparameter sensitivity: Systematic studies of learning rate, momentum, weight decay, orthogonalization frequency, and iteration counts for Ortho(·) (including schedules or per-layer tuning) are not provided.
- Training stability and safety: Effects on gradient norm distributions, exploding/vanishing gradients, catastrophic rank collapse (beyond Muon baselines), and sensitivity to bf16/fp16/fp8 are not analyzed.
- Theoretical assumptions vs. practice: Convergence analysis relies on smoothness, norm–Frobenius equivalence, and simplified settings (e.g., σ=0, μ=0 for key bound expression) and does not quantify L_teon vs. L_muon in real models or non-convex regimes.
- Estimating smoothness constants: There is no practical method to estimate or bound L_teon and L_muon during training, making it difficult to operationalize the theoretical guidance.
- Beyond adjacent-layer correlations: Only short-range, consecutive-layer stacking is tested. Whether long-range correlations (e.g., between early and late layers or across attention heads) can be exploited remains open.
- Token/data domain generality: Results are on FineWeb only. Robustness across corpora (The Pile, SlimPajama, code-heavy datasets), multilingual corpora, and different tokenizers is not evaluated.
- Longer-horizon training: Improvements are measured at limited token budgets. Whether gains persist or change near convergence or under compute-optimal scaling curves is uncertain.
- Implementation artifacts: The dimensional prefactor √(m/n) is adopted without ablation. Its interaction with different matrix shapes, layer norms (LayerNorm/RMSNorm), and architectures is not studied.
- Reproducibility and release: It is not stated whether code, trained checkpoints, or scripts will be released to facilitate independent verification and broader testing.
Practical Applications
Overview
The paper introduces Teon, a tensorized generalization of the Muon optimizer that performs cross-layer gradient orthogonalization by stacking layer gradients (e.g., Q, K, V) into a 3D tensor and applying Muon-style orthogonalization after mode-1 matricization. Teon provides up to a √K theoretical convergence advantage over layer-wise Muon, and empirically improves pre-training perplexity and convergence speed across GPT- and LLaMA-style models with similar per-step cost to Muon. Practical guidance includes mode-1 orthogonalization, stacking K=2 consecutive layers, and focusing on QKV matrices due to strong alignment of top right singular vectors.
Below are practical, real-world applications distilled from the paper’s findings, methods, and innovations.
Immediate Applications
These can be deployed now with minimal additional research.
- Drop-in optimizer upgrade for LLM pre-training
- Sector: software/AI, cloud compute, energy
- What: Replace Muon or AdamW with Teon in Transformer pre-training (GPT-/LLaMA-style), using the recommended defaults—mode-1 orthogonalization, K=2, stacking QKV of consecutive layers, and a robust SVD approximation (e.g., PolarExpress).
- Benefits: Lower validation perplexity at fixed tokens; faster early-stage convergence; potential reduction in total tokens/compute to reach a target PPL, translating to energy and cost savings.
- Tools/workflows: Integrate Teon into Megatron-LM/DeepSpeed/MosaicML Composer/Hugging Face Trainer; use existing Newton–Schulz or Polar decomposition routines; monitor learning rates with the √(m/n) scaling.
- Assumptions/dependencies: Transformer architectures with repeated layers and clear QKV; stable SVD approximation kernels (prefer PolarExpress); bfloat16 with FP32 accumulators; effectiveness tied to observed cross-layer singular vector alignment.
- Cost and energy footprint reduction for AI labs and cloud providers
- Sector: energy, finance, sustainability reporting
- What: Use Teon to achieve target quality with fewer training tokens or epochs; embed into internal carbon accounting and cost models.
- Benefits: Reduced GPU-hours; improved energy efficiency metrics (e.g., kWh per unit perplexity).
- Tools/workflows: Update training budgets/schedules and carbon dashboards; run A/B comparisons at fixed token budgets.
- Assumptions/dependencies: Per-step runtime parity with Muon holds; token savings convert linearly into cost/energy savings; quality parity assessed on downstream tasks as needed.
- Faster prototyping and iteration for small/mid-scale models
- Sector: startups, academia/education
- What: Employ Teon in small-to-medium LMs (60M–1B) to accelerate research and reduce iteration cycles.
- Benefits: Shorter time-to-signal; fewer tokens required to validate ideas.
- Tools/workflows: Hugging Face Transformers + Accelerate; open-source Teon optimizer module for torch.optim; default K=2, mode-1, QKV stacking.
- Assumptions/dependencies: Gains carry over to small batch sizes and shorter training runs; alignment patterns resemble those observed in the paper.
- Extending to fine-tuning and post-training (SFT, DPO/RLHF) with caution
- Sector: industry/AI product teams
- What: Try Teon for supervised fine-tuning or preference optimization on Transformer-based models to reduce step counts or improve stability.
- Benefits: Potentially faster convergence at similar quality; improved stability when gradients are low-rank and structured.
- Tools/workflows: Swap optimizer in existing SFT pipelines; keep K=2/QKV/mode-1; monitor small-batch stability and learning rate schedules.
- Assumptions/dependencies: Not directly evaluated in the paper; small-batch and high-variance regimes may change optimal K or mode; assess alignment metrics before adoption.
- Applying Teon to attention-heavy architectures beyond LLMs
- Sector: healthcare (medical vision transformers), robotics (perception), multimodal AI (vision-language), content generation
- What: Use Teon in ViTs, multimodal Transformers, and diffusion models with attention blocks by stacking QKV gradients in consecutive layers.
- Benefits: Potential data-efficiency gains in pre-training (self-supervised vision, multimodal corpora).
- Tools/workflows: Integrate Teon into training code for ViTs and multimodal transformers; run alignment diagnostics on top singular vectors to decide mode/K.
- Assumptions/dependencies: Presence of strongly aligned top right singular vectors across consecutive QKV layers; SVD approximations remain stable for local shapes.
- MLOps diagnostics: alignment-aware training monitors
- Sector: software/ML infrastructure
- What: Add low-frequency probes to compute similarities of top singular vectors across stacked layers’ momenta to inform K and mode selection (and alert when benefits may diminish).
- Benefits: Data-driven optimizer configuration; early detection of regimes where stacking ceases to help.
- Tools/workflows: Periodic SVD on momentum with downsampled frequency; dashboards showing alignment trends (right vs. left singular vectors).
- Assumptions/dependencies: Overhead remains acceptable; singular vectors are computed on representative batches; suitable batching to stabilize estimates.
- Packaging and standardization of Teon
- Sector: open-source tooling, software/AI
- What: Provide a polished Teon package with backends for Ortho (Newton–Schulz, PolarExpress), auto-configuration (K=2, QKV-only), and hooks for Megatron-LM, DeepSpeed, and Composer.
- Benefits: Lower integration friction; consistent, reproducible gains.
- Tools/workflows: pip-installable optimizer; CI against public training stacks; example configs and ablation scripts.
- Assumptions/dependencies: Maintenance of SVD/Polar kernels on common accelerators; clear licensing and version support.
- Teaching and research reproducibility
- Sector: academia/education
- What: Use Teon as a teaching artifact for tensorized optimization and non-Euclidean trust region methods; reproduce reported curves and ablations.
- Benefits: Clearer pedagogical link between theory (dual norms, smoothness constants) and practice; student projects on cross-layer modeling.
- Tools/workflows: Jupyter tutorials, lab assignments, and reproducible training scripts.
- Assumptions/dependencies: Access to moderate GPU resources; availability of public datasets (e.g., FineWeb).
Long-Term Applications
These require further research, scaling, or development.
- Adaptive cross-layer optimizers (AutoTeon)
- Sector: software/AI research
- What: Dynamically choose K, stacking sets (beyond consecutive layers), and matricization mode by monitoring singular-vector alignment and validation signals during training.
- Benefits: Consistently approach the theoretical √K advantage where structure exists; avoid degradation when alignment weakens.
- Tools/workflows: Controllers that adjust grouping per layer and over training phases; periodic low-overhead alignment estimates.
- Assumptions/dependencies: Robust, low-cost alignment measurements; stability of dynamic reconfiguration; scheduler-policy design.
- Hardware-aware kernels and accelerator support for orthogonalization
- Sector: semiconductors, systems software
- What: Fused and low-precision kernels for Newton–Schulz/Polar decomposition; hardware primitives for semi-orthogonal projections (U Vᵀ) on tall-skinny matrices.
- Benefits: Reduced latency/overhead; enabling Teon at very large scales (tens/hundreds of billions of parameters).
- Tools/workflows: CUDA/HIP/TPU-XLA kernels; BF16/FP8 variants with error-compensation; vendor libraries.
- Assumptions/dependencies: Numerical stability at low precision; memory bandwidth and register pressure management.
- Hybrid second-order methods (Teon + Shampoo/K-FAC/Gauss–Newton)
- Sector: AI research, high-performance training
- What: Combine cross-layer orthogonalization with curvature-aware preconditioning to approximate denser Fisher structure without prohibitive cost.
- Benefits: Further improvements in convergence and stability; potential reduction in training tokens and wall-clock time.
- Tools/workflows: Blockwise curvature estimates alongside Teon steps; schedule that alternates or composes updates.
- Assumptions/dependencies: Extra compute and memory overheads; stability in mixed-precision; careful tuning of step composition.
- Distributed and pipeline-parallel co-optimization
- Sector: cloud infrastructure
- What: Jointly orthogonalize gradients across pipeline stages or tensor-parallel shards where cross-stage correlations are strong.
- Benefits: Better global update directions; possible reductions in gradient communication by exploiting shared structure.
- Tools/workflows: Communication-efficient sharing of summary statistics (e.g., sketches for top singular vectors); block-periodic orthogonalization schedules.
- Assumptions/dependencies: Network overhead vs. gain trade-offs; consistency under asynchronous pipelines.
- Federated and multi-task learning via tensorized stacking
- Sector: healthcare, finance, IoT/edge
- What: Stack gradients across clients/tasks when singular-vector alignment indicates shared structure; apply Teon to exploit commonalities.
- Benefits: Improved sample efficiency and convergence in heterogeneous settings; potential for better personalization with fewer rounds.
- Tools/workflows: Secure aggregation of low-rank summaries; client-side alignment checks; privacy-preserving SVD approximations.
- Assumptions/dependencies: Sufficient cross-client/task alignment; privacy and regulatory constraints; robustness to non-i.i.d. data.
- Quantization-aware and low-resource training
- Sector: mobile/edge, consumer devices
- What: Low-precision (8-bit/FP8) Teon variants with error-feedback to enable training on commodity hardware or on-device continual learning.
- Benefits: Broader accessibility of training; reduced power draw.
- Tools/workflows: Quantization-aware orthogonalization kernels; calibration of √(m/n) scaling under low precision.
- Assumptions/dependencies: Numerical stability and convergence guarantees in low precision; compatibility with 8-bit optimizers.
- Architecture and NAS informed by alignment metrics
- Sector: AI research, AutoML
- What: Use cross-layer singular-vector alignment as a signal in architecture search or layer design (e.g., tie projections to increase beneficial alignment).
- Benefits: Architectures that are inherently more amenable to tensorized optimization; improved training efficiency by design.
- Tools/workflows: NAS loops with periodic alignment scoring; inductive biases that promote right-vector alignment in attention blocks.
- Assumptions/dependencies: Alignment correlates with generalization and downstream task performance; search overheads remain tractable.
- Training efficiency benchmarks and sustainability policy
- Sector: policy, standards, sustainability
- What: Incorporate optimizer choice (e.g., Teon) into standardized reporting: energy per token to target PPL, energy per task score; encourage adoption via procurement/grant guidelines.
- Benefits: Incentivizes use of efficiency-improving optimizers; better transparency in model training energy use.
- Tools/workflows: Benchmark suites that record optimizer, tokens, PPL curves; carbon reporting frameworks.
- Assumptions/dependencies: Community consensus on metrics; reproducibility across hardware and datasets.
- Cross-domain extensions beyond Transformers
- Sector: scientific computing, recommendation systems, time-series, speech
- What: Explore tensorized orthogonalization in architectures with repeated or modular blocks (e.g., SSMs, GNN layers, recommender towers).
- Benefits: Potential convergence and stability gains where cross-block gradient alignment exists.
- Tools/workflows: Alignment studies per domain; custom stacking strategies (e.g., across residual blocks).
- Assumptions/dependencies: Sufficient cross-block alignment; matrix aspect ratios compatible with stable SVD approximations.
Notes on Key Assumptions and Dependencies
- Cross-layer alignment is central: The theoretical and empirical gains hinge on strong alignment of top right singular vectors across stacked layers, especially QKV in Transformers. Gains may diminish if alignment weakens (e.g., MLP layers or very large K).
- Recommended defaults matter: Mode-1 orthogonalization, K=2, QKV stacking, and a robust SVD approximation (PolarExpress) delivered the best results in the paper. Departures (e.g., stacking MLP) can degrade performance due to ill-conditioned SVDs.
- Numerical stability and precision: Use BF16 with FP32 accumulators; ensure SVD/Polar kernels are stable and performant on target hardware. Low-precision variants require further validation.
- Transferability beyond pre-training: While pre-training gains are demonstrated, fine-tuning and other domains need empirical verification; monitor alignment and stability before broad deployment.
- Infrastructure integration: Real-world benefits depend on seamless integration into training stacks, distributed setups, and monitoring, as well as organizational willingness to adapt optimizers and training schedules.
Glossary
- Ablation study: A controlled experimental analysis that isolates and tests the effect of specific components or hyper-parameters. "This section provides a detailed ablation study, which further explains how these choices are made in practice."
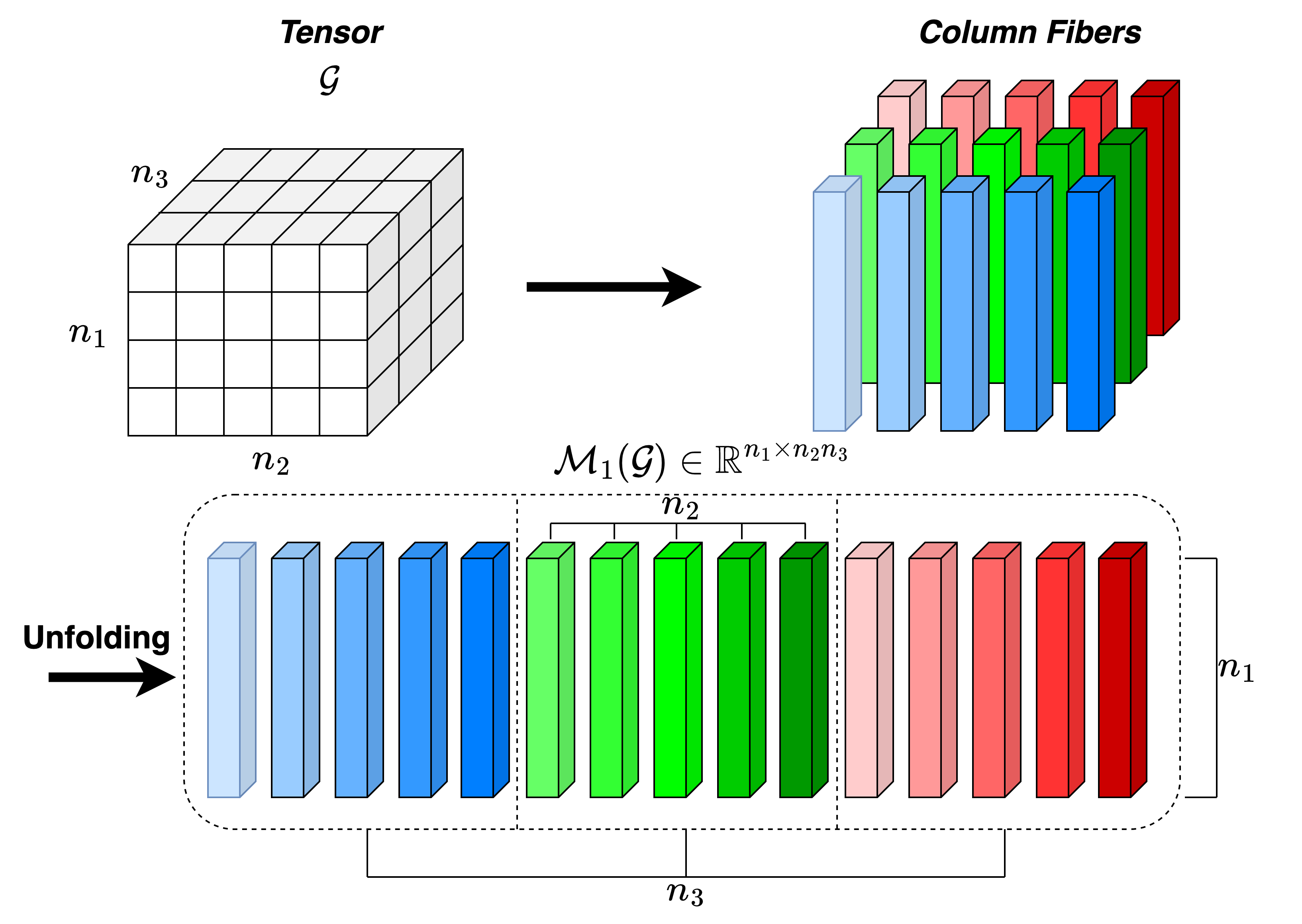
- Column fiber: A tensor fiber obtained by fixing all indices except the first, producing vectors stacked as columns during unfolding. "column fibers, i.e., vectors obtained by fixing all indices except the first, and these fibers are then arranged as columns of a matrix to form the mode-1 unfolding."
- Compute-optimal token-to-parameter ratios: A heuristic specifying the number of training tokens relative to model parameters to maximize training efficiency under a compute budget. "Following the compute-optimal token-to-parameter ratios~\cite{hoffmann2022training}, we train 60M, 130M, 350M, and 1B parameter models on 1.1B, 2.2B, 6.4B, and 13.1B tokens respectively."
- Dual norm: For a given norm, the associated norm that measures the maximum inner product with unit vectors in the original norm; used to analyze optimization steps. "With a chosen norm and its dual norm "
- Fisher information matrix: A matrix capturing the curvature of a statistical model’s parameter space, underpinning natural gradient methods. "We are inspired by the Fisher information matrix underlying natural gradient methods"
- Fisher metric: The Riemannian metric induced by the Fisher information, defining geometry for natural gradients. "In principle, the optimal natural gradient is defined with respect to the Fisher metric of the {\it entire vectorized model parameters}"
- Frobenius norm: The square root of the sum of squared entries of a tensor or matrix. "The Frobenius norm of a tensor is defined as"
- Gradient orthogonalization: Transforming gradients to orthogonal directions to mitigate degeneracy (e.g., low-rank collapse). "extends gradient orthogonalization beyond individual layers"
- Matricization: Reshaping a tensor into a matrix by unfolding along a selected mode. "A tensor can be unfolded along a selected mode to form a matrix, which is called matricization."
- Matricization-based tensor orthogonalization: Orthogonalizing a tensor by first unfolding it into a matrix and then applying matrix orthogonalization. "we adopt a strategy known as matricization-based tensor orthogonalization"
- Mode-1 matricization: Unfolding a tensor along its first mode to produce a matrix. "Mode-1 Matricization of a given tensor ."
- Mode- orthogonalization: Orthogonalization applied to a tensor after unfolding along mode . "The mode- orthogonalization of tensor is defined as"
- Natural gradient: A gradient defined with respect to the Fisher metric, accounting for the geometry of the parameter space. "natural gradient methods"
- Newton–Schulz iteration: An iterative method used to approximate matrix functions such as the polar decomposition/SVD efficiently. "In practice, the Newton-Schulz iteration process \cite{higham2008functions} is commonly used to approximate the SVD."
- Non-Euclidean norms: Norms other than the standard Euclidean norm, used to define alternative geometries for optimization. "a template for steepest-descent in Non-Euclidean norms."
- Non-Euclidean Trust Region (NTR): An optimization framework performing steepest-descent steps constrained within a trust region under non-Euclidean norms. "We study Teon and muon based on the Non-Euclidean Trust Region (NTR) formulation"
- Perplexity (PPL): A language modeling metric equal to the exponentiated average negative log-likelihood; lower values indicate better performance. "Validation perplexity (PPL) is reported; lower is better."
- Rank collapse: The degeneration of gradient matrices into low-rank forms that can hinder effective optimization. "preventing the rank collapse of the gradient by replacing the singular value matrix with an identity matrix."
- Semi-orthogonal matrix function: The mapping that returns the closest matrix with orthonormal columns or rows to a given matrix. "the semi-orthogonal matrix function closest to the input matrix"
- Singular Value Decomposition (SVD): The factorization of a matrix into , used to analyze and orthogonalize gradients. "If the SVD of the input matrix is \mathrm{Ortho}({M}) := {U} {V}T$."</sup></li> <li><strong>Stochastic gradient</strong>: A random estimate of the true gradient, typically computed on mini-batches and subject to variance. "Stochastic gradients ${G}({W};\xi)$ satisfy"</li> <li><strong>Tensor orthogonalization</strong>: Extending orthogonalization procedures to higher-order tensors to capture cross-layer correlations. "use tensor orthogonalization to constrain the update direction"</li> <li><strong>Tensor unfolding</strong>: Converting a tensor into a matrix by stacking its fibers along a mode. "A tensor can be unfolded along a selected mode to form a matrix"</li> <li><strong>Top singular vectors</strong>: The leading left/right singular vectors ($u_1v_1$) of a matrix that capture its principal directions. "strongly aligned top left (or right) singular vectors"
Collections
Sign up for free to add this paper to one or more collections.