- The paper introduces a unified RL framework achieving zero-shot transfer of dynamic, athletic skills through minimal observations and principled actuation modeling.
- It employs an adaptive sampling curriculum and assistive wrench mechanism to enhance convergence and performance in contact-rich, multi-modal behaviors.
- Empirical evaluations on platforms like Atlas, Unitree G1, and Spot demonstrate significant sim-to-real improvements and versatile skill deployment.
ZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Context and Motivation
Progress toward robust, general-purpose physical intelligence in legged robots—particularly humanoids—has been constrained by the need for per-task controller tuning, extensive modeling, and reward shaping. Prevailing methods rely on either model-based controllers tracking pre-computed trajectories or reinforcement learning (RL) from scratch with heavy reward engineering. These approaches face limitations regarding adaptability to contact-rich, multi-modal behaviors, scalability across robots and environments, and deployment under sim-to-real discrepancies.
The "ZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control" paper (2602.00401) presents a scalable, unified RL-based framework capable of transferring a large repertoire of complex, dynamic whole-body skills—learned exclusively in simulation from heterogeneous data sources—directly to real robots with zero-shot deployment. ZEST eschews hand-designed contact schedules, state estimators, observation histories, and multi-stage pipelines, instead leveraging an adaptive RL pipeline with robust domain randomization and principled actuation modeling.
ZEST is structured as a goal-conditioned MDP for high-DoF robots, with policies conditioned on instantaneous reference states derived from MoCap, single-camera video reconstructions (ViCap), or hand-designed animation, retargeted to the robot via spacetime optimization. The actor receives minimal observations: proprioception and next-step reference only, augmented by previous action. Policy outputs are residual joint targets, forming a correction on top of the reference before feeding into joint-level PD controllers.
Learning is stabilized and scaled using two key innovations:
- Adaptive Sampling Curriculum: Reference motions are segmented; trajectories and temporal bins (phases) exhibiting higher failure are resampled more frequently, addressing catastrophic forgetting and improving convergence on long-horizon or multifaceted behaviors.
- Model-based Assistive Wrench: For challenging motions (e.g., acrobatics), a virtual base wrench—scaled by per-bin failure EMA—facilitates initial exploration and decays as performance improves, yielding a self-curriculum without hand-coded schedules.
All training is performed in Isaac Lab with domain randomization over friction, mass, observation noise, and external disturbances, supporting robust deployment.

Figure 2: Overview of the ZEST framework, depicting policy training—using diverse motion sources, adaptive curricula, and minimalistic observation/action structure—and zero-shot hardware deployment.
Actuator Modeling and Controller Synthesis
Robust sim-to-real transfer necessitates high-fidelity actuation modeling. Many humanoid robots, such as Atlas and Unitree G1, exploit Parallel-Linkage Actuators (PLA) in legs and waists. Accurately simulating closed-chain PLA kinematics imposes computational overhead; ZEST introduces a progression of analytical PLA models:
- Locally Projected Model: Assumes massless support links, yielding configuration-dependent armature models.
- Dynamic Armature (Jacobi) Model: Uses a diagonal approximation, with off-diagonal couplings handled as fictitious torques.
- Nominal Armature Model: Armatures are fixed at a nominal configuration, drastically reducing computation with negligible error, and providing a basis for robust PD-gain tuning.
This progression enables efficient, scalable RL training, and the Nominal Armature Model improves sim-to-real transfer—when omitted, policies fail on hardware for the same training performance in sim.
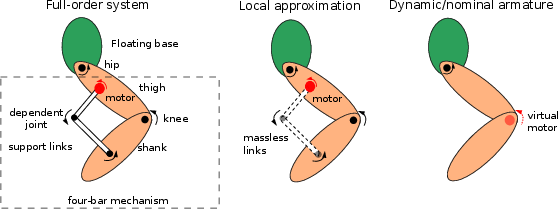
Figure 1: Progressive simplification of PLA modeling for humanoid leg actuation, demonstrating model reduction strategies while maintaining dynamical accuracy for RL training.
ZEST is validated on Boston Dynamics Atlas, Unitree G1, and Spot platforms. Skills include:
- MoCap-derived: Walking, jogging, forward roll, army crawl, cartwheel, breakdance.
- ViCap-derived: Soccer-kick, complex dance sequences, scene interaction—e.g., jumping on, climbing up/down boxes.
- Animation: Handstands and continuous backflips on quadrupeds, leveraging degrees of freedom inaccessible to human demonstration.
Strong numerical results are reported for all behaviors, notably mean absolute joint errors MAE(q) < 0.055 rad for foot-only gaits; challenging, multi-contact athletic skills achieve MAD(R) < 0.15 rad even in the presence of contact artifacts and dynamic transitions.
Contrary to conventional wisdom, longer reference or observation windows—ubiquitous in other RL pipelines—degrade performance in ZEST, as established via targeted ablations. Adding sequence-based features confounds credit assignment and slows convergence, contradicting the prevalent model in recent LLM-style architectures. Performance with minimal observations suggests possibility for on-robot, estimator-free deployment.
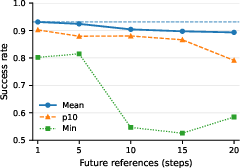
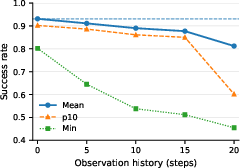
Figure 5: Effect of future references—multi-step reference windows degrade policy success, with maximal performance achieved with "next reference" only.
Robustness, Ablations, and Comparison
A comprehensive set of ablation studies is performed in simulation. Key findings:
- Removal of adaptive sampling or assistive wrenches slows convergence and degrades lower-tail performance, impacting the most challenging segments/skills.
- RL policies configured as in ZEST outperform model-based MPC controllers on dynamic, contact-rich behaviors (cartwheel, jog, roll on all fours), while maintaining parity on simpler gaits. Model-based controllers are especially limited by the need for explicit contact schedule labeling, which proves error-prone for video- or MoCap-derived sequences and infeasible for multi-contact actions.
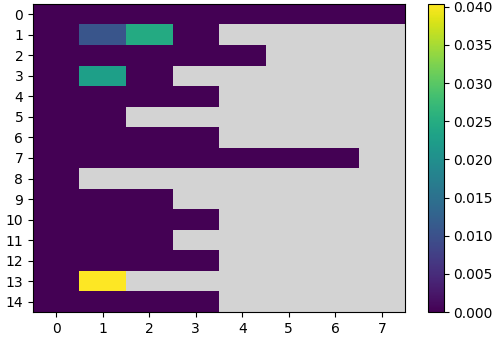
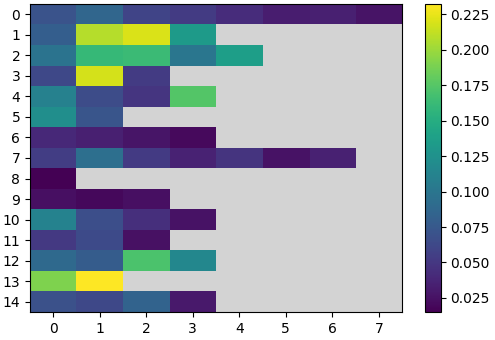
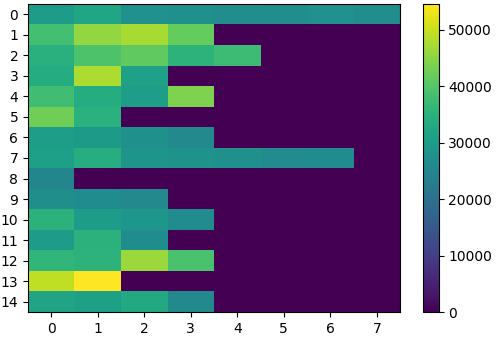

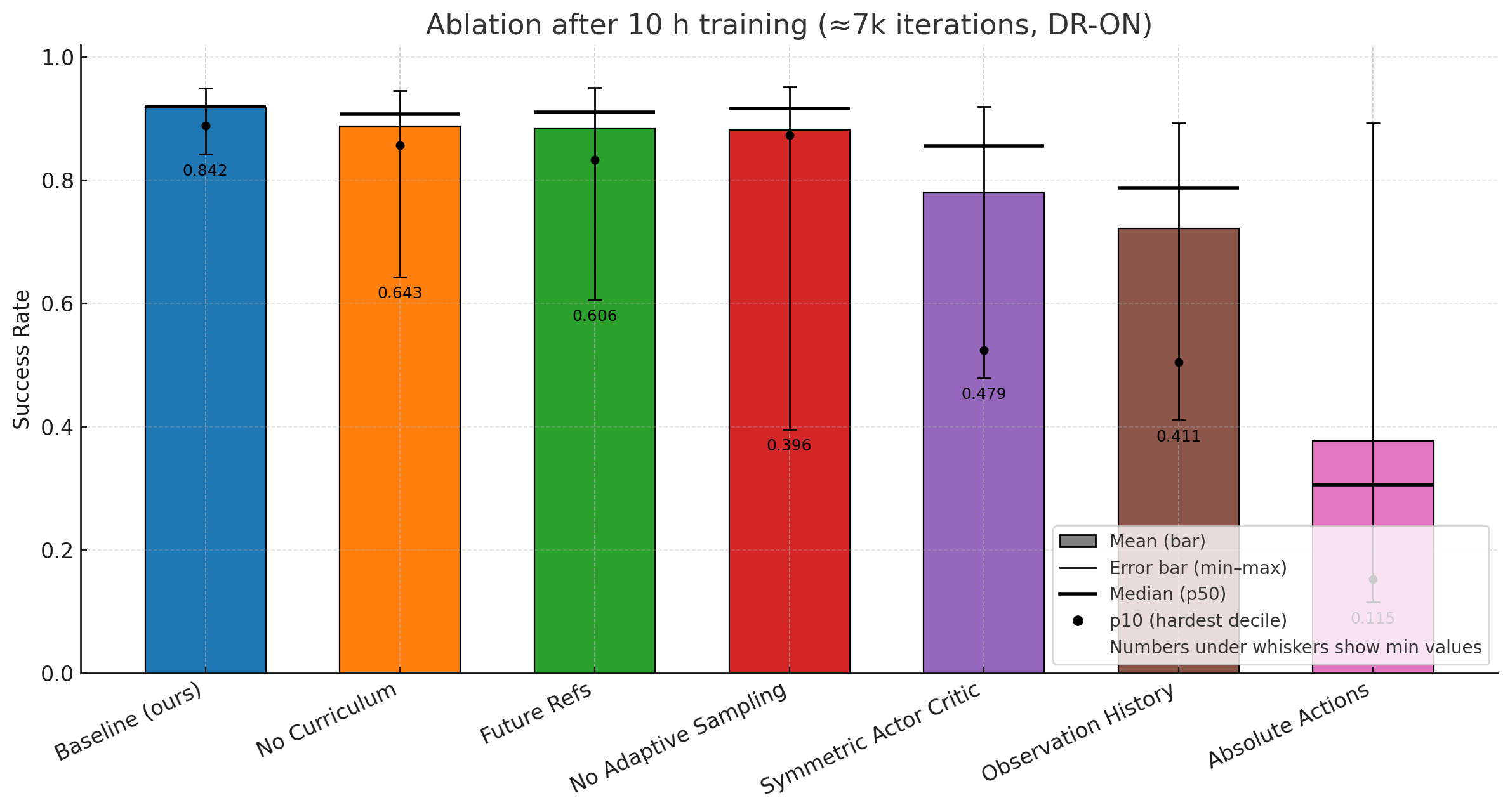
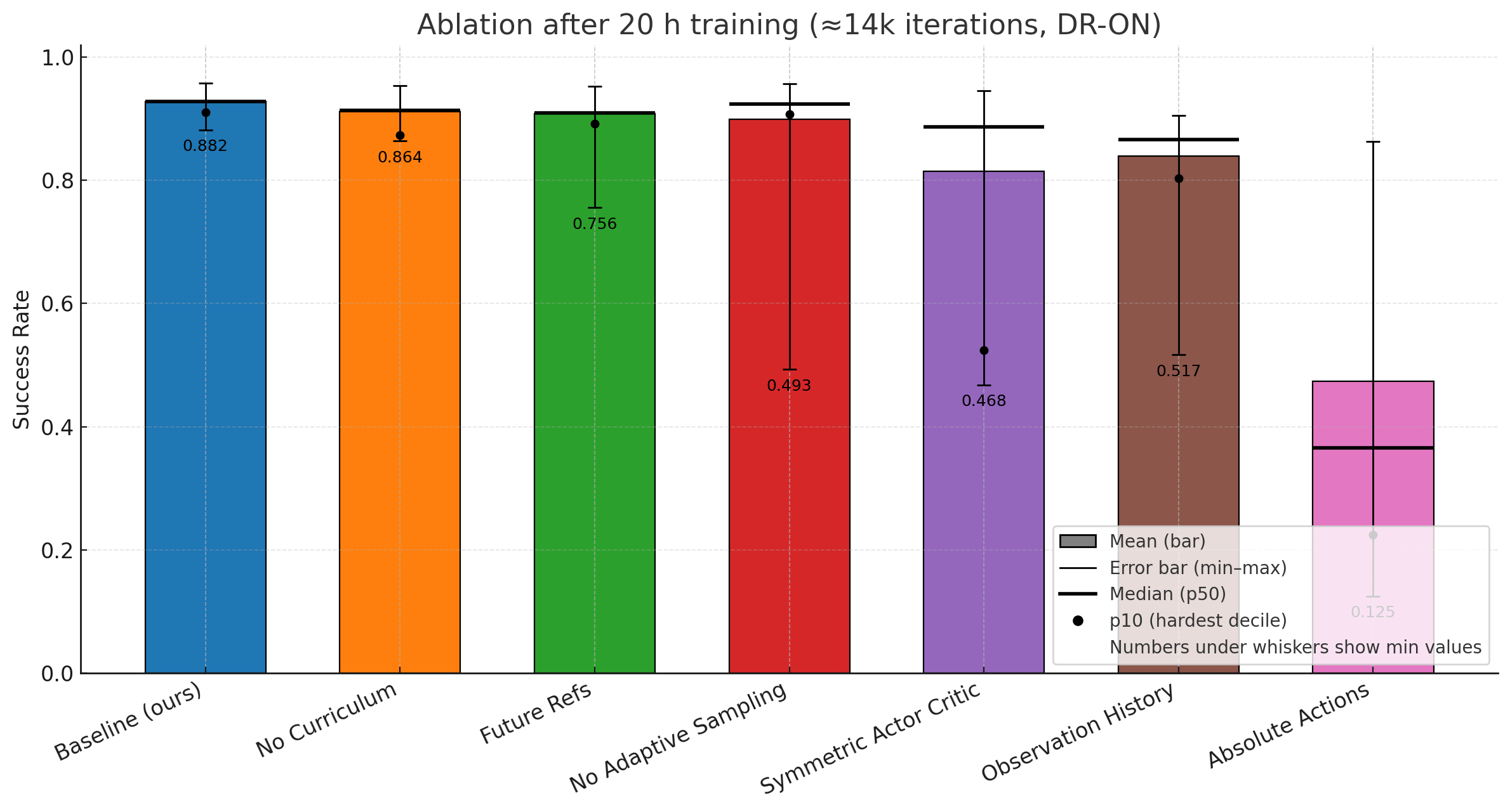
Figure 6: Visualization of per-bin assistive wrench scaling, adaptive bin visitation, and the effect of curricula on multi-skill policy success during training.
Physical Deployment and Reproducibility
All policies are evaluated in hardware with an automated, reproducible deployment pipeline, ensuring the exact policy, network, and gains used for sim matches hardware. Generalization across robot morphologies (Atlas, G1, Spot) and data sources (MoCap, ViCap, animation) is achieved via the same policy and training recipe, without hand-tuning.
For physically interactive tasks (box climbing), minimal observation is used (no perception of box position). Instead, randomized training ensures robust deployment even with variable initial relative poses and mass.
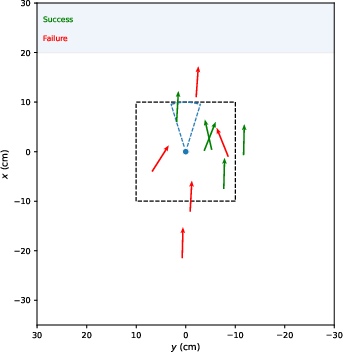
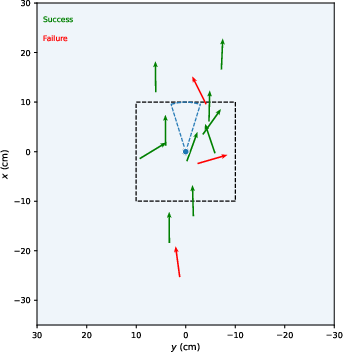
Figure 3: Hardware execution of the box climb up skill on Unitree G1, demonstrating multi-contact robustness on scene-interactive tasks using ViCap-derived references and proprioceptive-only policy.
Implications and Future Directions
The ZEST pipeline demonstrates that:
1. RL policies conditioned only on next-step reference states and proprioception, trained in simulation via minimalistic, automated curricula, can robustly execute a wide array of athletic, multi-contact, dynamic skills in the physical world, without auxiliary estimators, history, or contact annotation.
2. A streamlined actuator modeling and PD-gain synthesis pipeline—leveraging physically grounded armature modeling—can substantially reduce the sim-to-real gap.
3. The use of monocular video and non-physical animation as sources for skill procedures, retargeted through spacetime optimization, broadens the repertoire of transferrable skills far beyond what was previously feasible.
Theoretical implications include the prospect of “generalist” embodied agents, where skilled behaviors can be compiled from diverse, imperfect demonstrations, and deployed with no per-task tuning. Practically, this methodology offers a scalable avenue for populating humanoids and legged robots with motion libraries, without resorting to hand-designed control policies for every new skill.
Future developments may include: (i) tracking previously unseen skills via low-dimensional motion embeddings and few-shot adaptation, (ii) integrating perception for non-flat terrain, and (iii) unifying behavior synthesis and execution via generative models, such as diffusion policies, or natural language interfaces, further bridging the gap between human intent and robotic execution.
Conclusion
ZEST represents a comprehensive framework that demonstrates robust, zero-shot transfer of whole-body motor skills to physical robots from a heterogeneous set of demonstration sources, while employing a principled approach to actuation modeling and sample-efficient RL. The findings suggest that robust, estimator-free policies—with a unified, curriculum-driven learning process—can achieve athletic, expressive control on high-dimensional robots, challenging standard pipeline assumptions in RL for robotics. Directions for further research center on generalization beyond demonstration distributions, high-level generative conditioning, and scalable multi-skill continual learning for embodied agents.