Kimi K2.5: Visual Agentic Intelligence
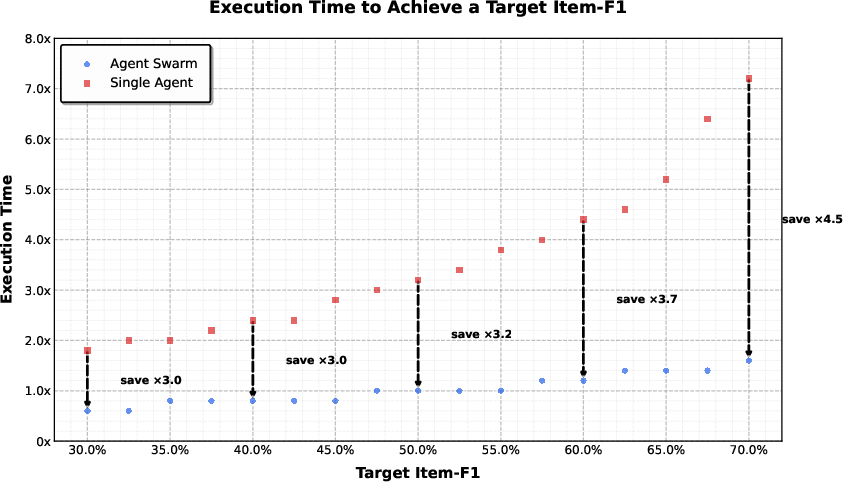
Abstract: We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Kimi K2.5, a smart AI system that can understand both text and visuals (like images and videos) and act like an “agent” that uses tools and plans steps to solve complex tasks. It focuses on two big ideas:
- Training the model to read and see at the same time so these skills strengthen each other.
- Creating an “Agent Swarm,” where one main agent can spin up many helper agents to work in parallel, making hard tasks faster and more reliable.
What questions did the researchers ask?
- How can we train an AI on text and visuals together so one skill doesn’t weaken the other?
- Can we activate good visual reasoning without feeding the model lots of hand-made image examples?
- Does training on visual tasks help or harm the model’s text abilities?
- How can we build many agents that work in parallel—safely and efficiently—so big jobs don’t take forever?
- Can we reduce the number of tokens (the “words” a model outputs) while keeping strong performance?
How did they do it? (Methods and ideas)
Training the model to read and see together
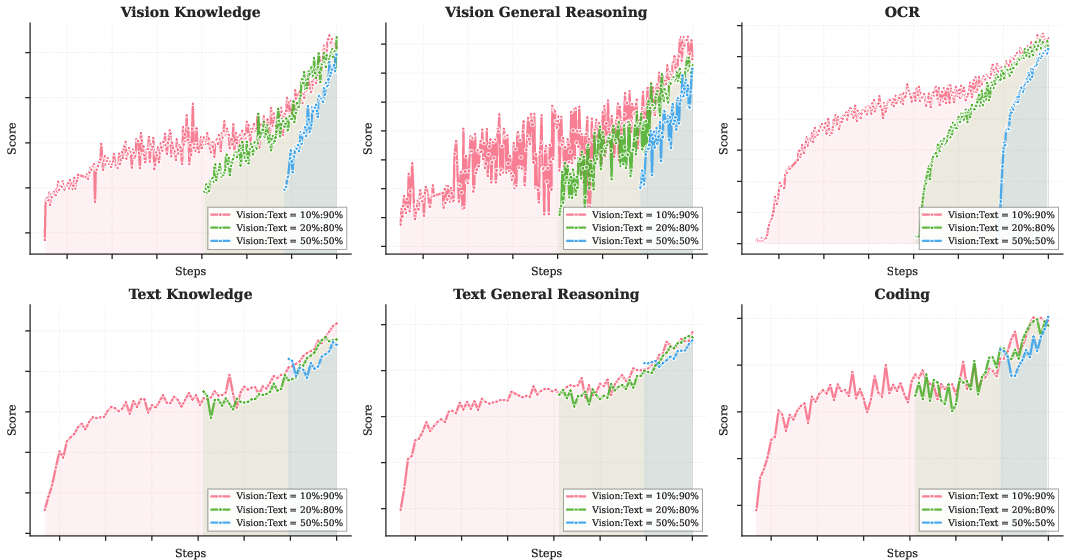
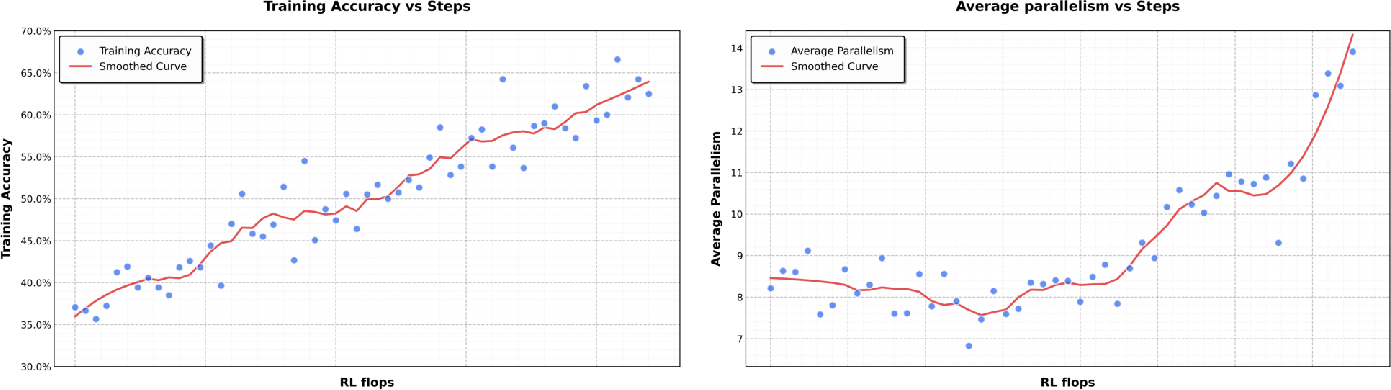
Think of learning to read and learning to recognize objects. If you learn both from the start, each helps the other. Kimi K2.5 uses “joint pre-training” where it mixes text and visual data early and steadily, instead of adding vision late. The key insight: early and moderate mixing works better than late and heavy mixing.
For visuals, K2.5 uses a vision encoder called MoonViT-3D:
- It handles images at their original resolution by chopping them into patches (like cutting a big picture into tiles) and packing them efficiently, inspired by a strategy called NaViT.
- For video, it groups every four frames together—like flipping four pages of a flipbook at once—and averages information over time, so it can process videos up to about four times longer within the same memory limits.
Teaching visual skills without pictures at first
“Zero-vision SFT” means during supervised fine-tuning, they only used text-based training—not lots of hand-labeled visual examples. They simulated “visual tool use” with code (like using Python to reason about pixel operations). Because the model had already learned to connect text and vision during pre-training, this text-only fine-tuning surprisingly woke up its visual reasoning without needing a ton of custom image data.
Reinforcement learning that helps both vision and text
Reinforcement learning (RL) is like letting the model try things and rewarding it when it does well. They used “outcome-based visual RL” on tasks that require looking (like counting objects, reading charts/documents, and solving math/science problems that depend on an image).
Important discovery: visual RL didn’t hurt text performance—it improved it. After visual RL, the model scored higher on tough text benchmarks (like MMLU-Pro and GPQA-Diamond). In simple terms, learning to extract structured info from visuals made the model better at similar tasks in text.
They then did “joint multimodal RL” where training wasn’t split by input type (text vs. image) but by abilities (like knowledge, reasoning, coding, agentic skills). This encourages skills learned from text to transfer to vision and vice versa.
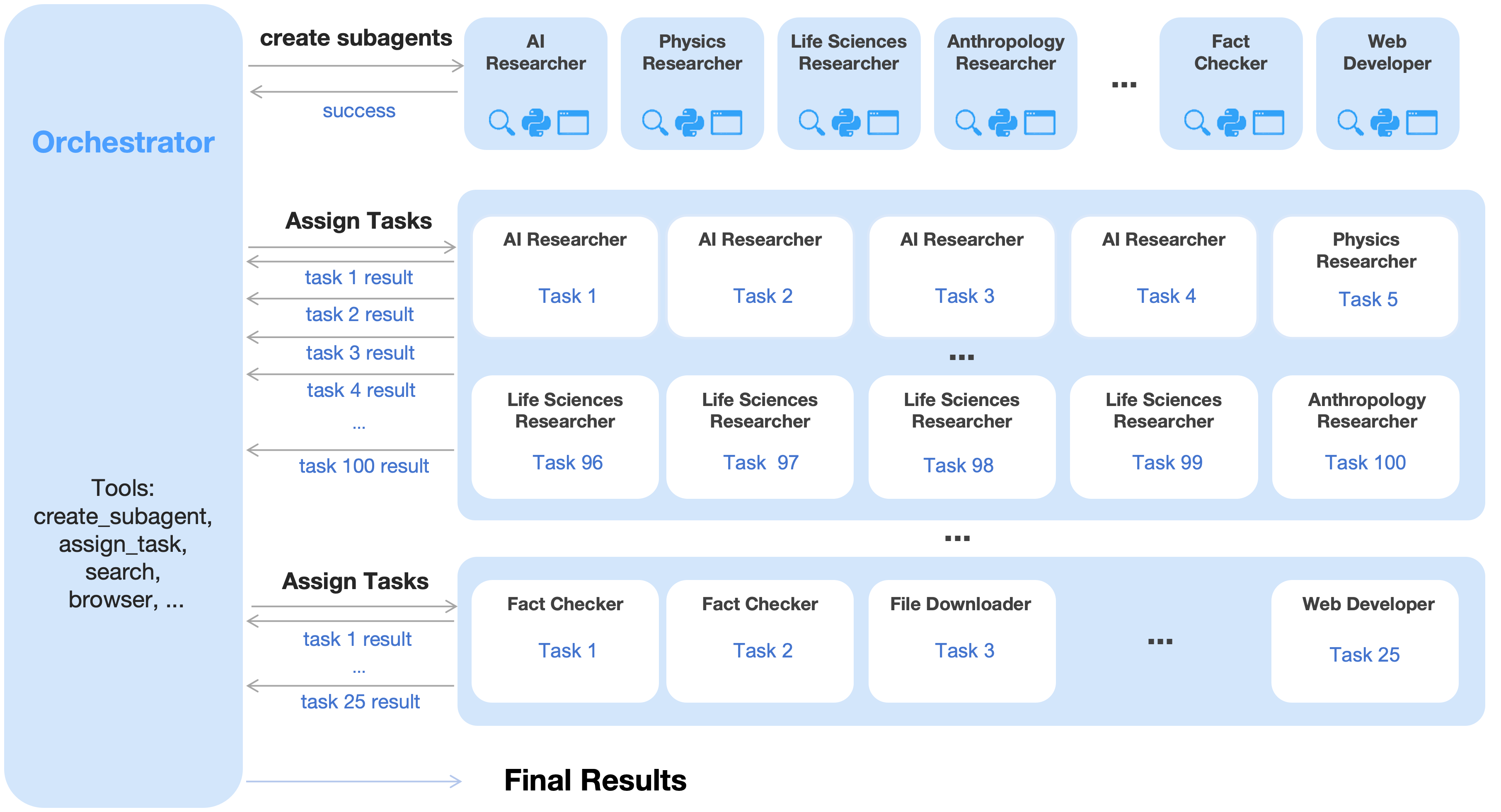
Agent Swarm: many helpers working in parallel
Most AI agents do tasks step-by-step. That’s slow for big jobs. K2.5 introduces “Agent Swarm,” where a trainable orchestrator (like a team lead) can:
- Break a big task into sub-tasks,
- Create specialized sub-agents (frozen helpers with fixed skills),
- Run those sub-agents at the same time (in parallel),
- Combine their results for a final answer.
They trained the orchestrator with “Parallel-Agent Reinforcement Learning (PARL).” Instead of training all agents together (which can be unstable and confusing), only the orchestrator learns; the sub-agents stay fixed. This avoids problems like not knowing which agent deserves credit for success or blame for failure.
They designed a reward that balances:
- Performance (did we solve the task?),
- Sensible parallelization (don’t spawn lots of useless helpers),
- Finishing sub-tasks properly (complete what you started).
They also measured “critical steps” (like timing the longest checkout line per stage) to reflect real waiting time in parallel work—pushing the orchestrator to reduce end-to-end latency.
Making training efficient
- DEP (Decoupled Encoder Process): They separated how the vision part runs during training to keep GPUs balanced and reuse efficient text-only strategies. Think of it like doing the image calculations first, saving the results, and then finishing the rest with stable, well-optimized steps.
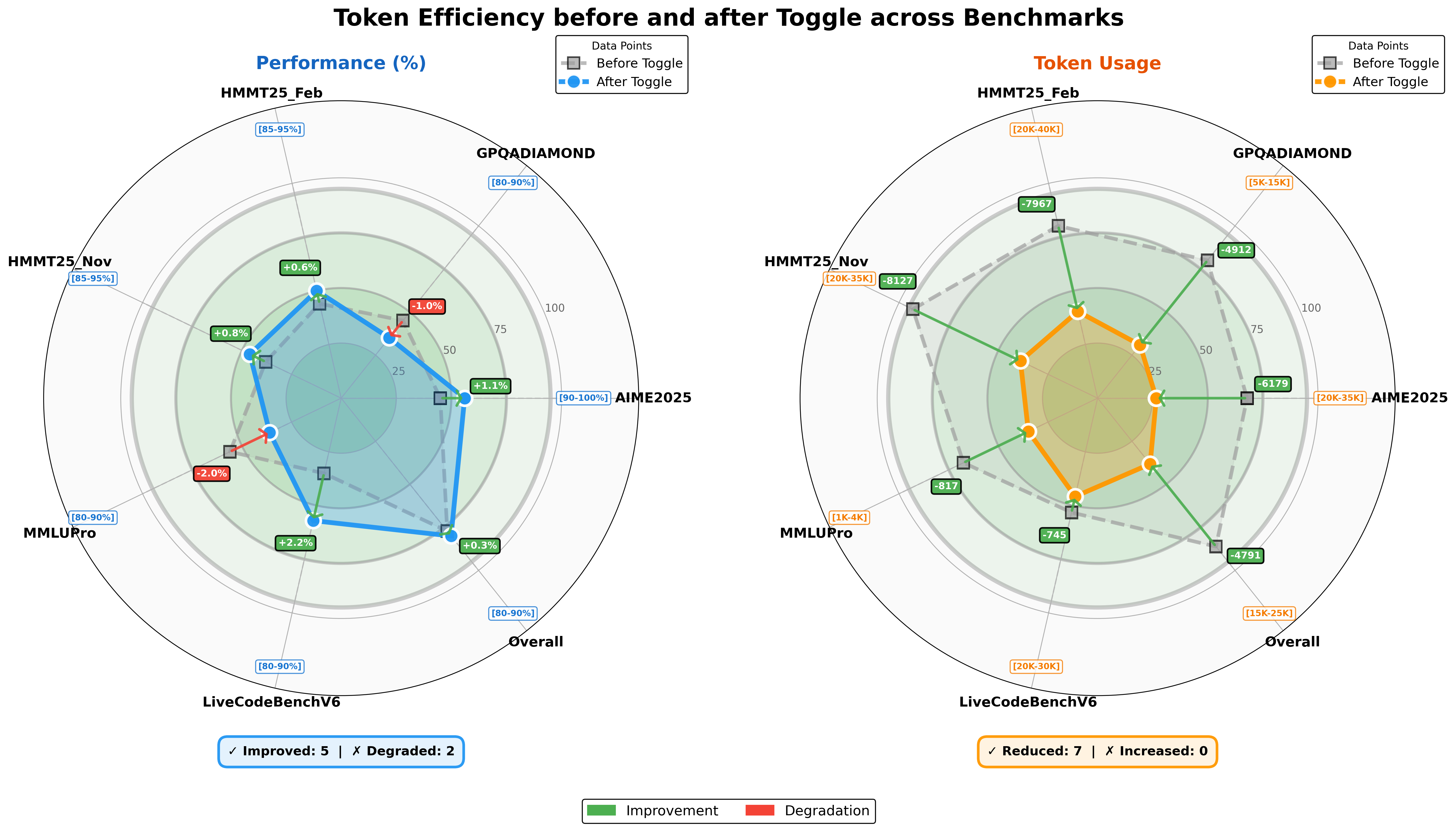
- Token-efficient RL (Toggle): Sometimes the model trains with a token budget (limit the length), and sometimes it trains without limits (to learn deeper thinking). Alternating between these two phases reduces needless long outputs but keeps the ability to think more when needed.
What did they find? Why it matters
- Early, steady mixing of text and vision during training works best. Late heavy vision injection isn’t necessary and can be worse.
- Zero-vision SFT (text-only fine-tuning) was enough to kickstart visual reasoning, thanks to earlier joint pre-training.
- Visual RL improved text performance (e.g., higher scores on MMLU-Pro and GPQA-Diamond), showing strong cross-modal transfer.
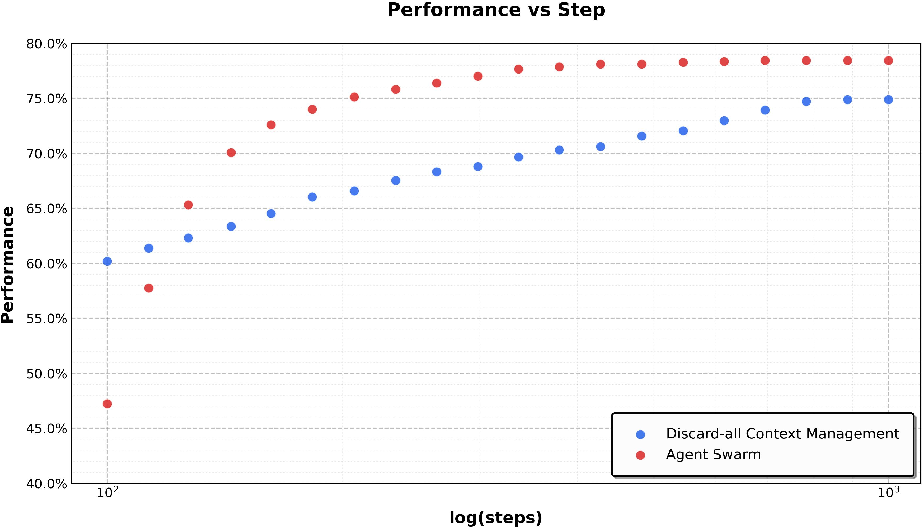
- Agent Swarm cut latency by up to around 4.5× compared to a single agent and improved accuracy in wide-search tasks (item-level F1 rose from about 72.8% to 79.0%).
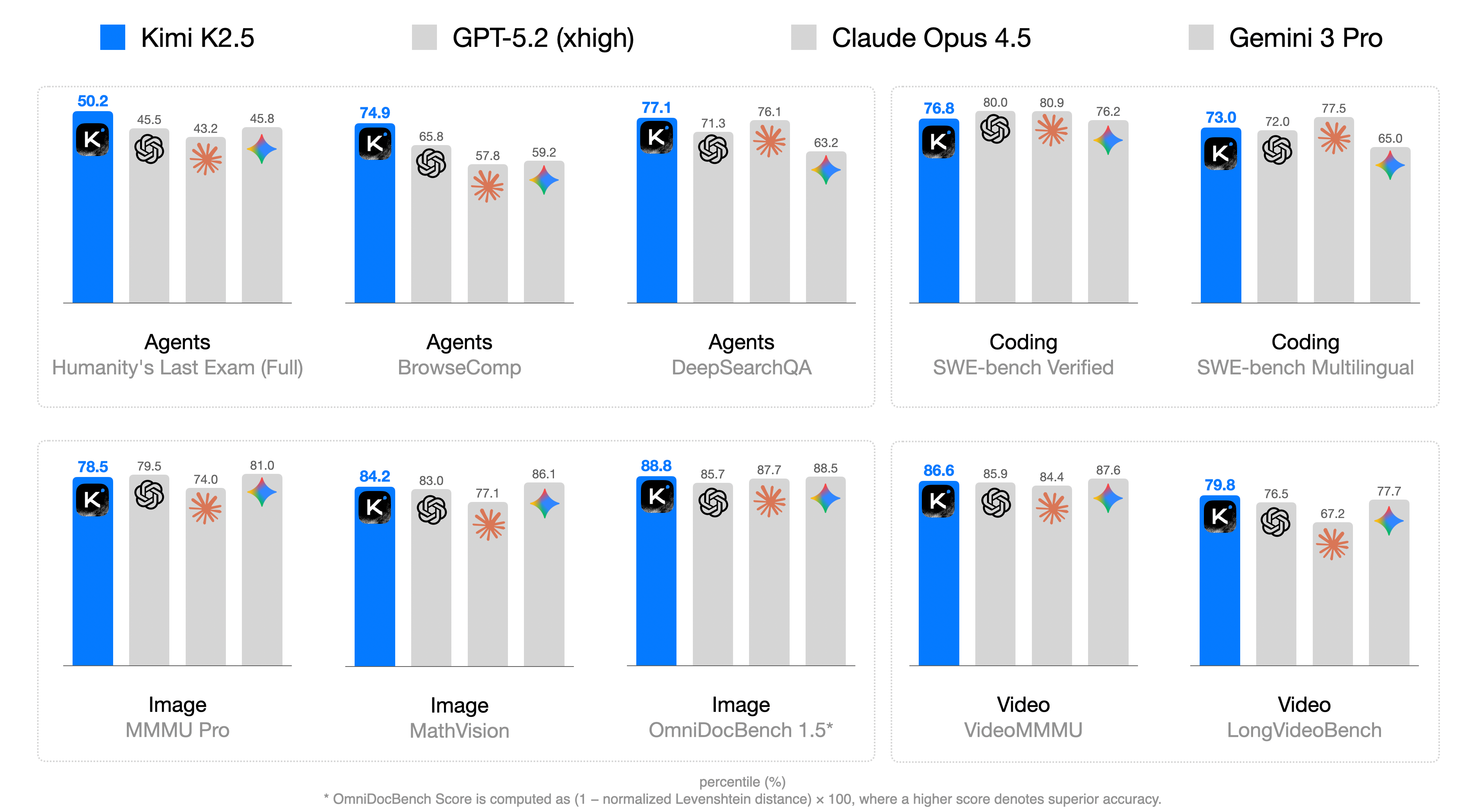
- K2.5 reached state-of-the-art or highly competitive scores across many areas: coding (like LiveCodeBench and SWE-Bench variants), visual understanding (images and videos), reasoning (AIME and HMMT math competitions), and agentic tasks (web browsing, search).
- Toggle reduced output length by around 25–30% on average with little performance loss, making the model more efficient.
In short, K2.5 shows that:
- Training vision and language together from the start pays off.
- Parallel agents can make complex tasks both faster and better.
- Learning visual skills can strengthen text skills too.
What could this mean for the future?
- Faster, smarter assistants: Agent Swarm makes big, multi-part jobs—like researching across many sources, analyzing long documents, or building software—much quicker and more reliable.
- Stronger multimodal intelligence: Joint training and cross-modal RL point toward AI that naturally blends reading, seeing, and acting, which is key for real-world tasks.
- Better efficiency: Token-efficient strategies and DEP-like training make advanced models more practical to run.
- Open research: The team released a post-trained checkpoint, inviting developers and scientists to build on top of K2.5—accelerating progress toward “General Agentic Intelligence,” where AI can plan, coordinate, and execute complex goals in varied environments.
Overall, Kimi K2.5 brings together strong vision-language understanding and a powerful parallel agent framework, pushing AI toward being faster, more capable, and more useful in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Based on the paper, the following unresolved issues remain for future researchers to investigate and address:
Data, contamination, and pre-training schedule
- No contamination audit: the paper does not report procedures or results for benchmark leakage checks across 15T tokens (especially for 2024–2026 benchmarks like AIME 2025, HLE, VideoMMMU), leaving uncertainty in SOTA claims.
- Unreported data composition: precise distributions, sources, licenses, and filtering for the 15T joint pre-training and 500B→200B mid-training tokens are not disclosed, hindering reproducibility and bias analysis.
- Early-vision “lower ratio” claim underexplored: the ablation in Table 1 covers only a few points; a fuller sweep over ratios, schedules (cyclical, curriculum, stochastic interleaving), and budget regimes is missing to validate generality.
- No analysis of domain balance: the effect of increased coding weight and “max epochs per source” on non-coding capabilities (e.g., long-context reasoning, factuality, safety) is not isolated or quantified.
- Missing contrastive vs. generative pre-training comparison: MoonViT-3D uses captioning-only loss; the trade-offs vs. contrastive (e.g., CLIP/SigLIP) for retrieval, calibration, and grounding are not evaluated.
Architecture and modality coverage
- Video compression trade-offs unquantified: grouping frames in fours and temporal pooling (4× compression) may impair fast-motion and fine-grained temporal reasoning; no ablations on chunk size, pooling method, or per-domain effects.
- Limits of native-resolution packing: NaViT-style packing for high-res images/videos could induce position/scale biases; no stress tests on extreme aspect ratios, dense text (documents), or small-objects detection sensitivity.
- Lack of audio/multisensory support: despite video capability, the model excludes audio; impact on video QA that relies on speech/sound cues remains unexplored.
- Capacity and scaling limits: how MoonViT-3D scales (parameter count, memory, latency) and whether DEP remains efficient with larger encoders or higher-resolution videos is not examined.
Zero-vision SFT and cross-modal generalization
- Mechanism of “zero-vision activation” is hypothesized but unverified: no controlled comparisons with matched-quality multimodal SFT, few-shot vision SFT, or synthetic high-quality visual trajectories to establish causal factors.
- Generalization boundaries unclear: robustness to real-world visual tool-use beyond IPython proxies (e.g., imperfect cropping/OCR, noisy images) is not tested.
- Failure mode quantification missing: the paper notes prior “image ignoring” issues but does not report rates of modality neglect before/after zero-vision SFT or RL.
- Compositionality and transfer: no evaluations on systematic visual-text compositional generalization (e.g., compositional VQA, unseen symbol-operator combinations) to support cross-modal transfer claims.
Multimodal RL, objectives, and theory
- Visual RL improving text: improvements could be confounded by additional RL compute or data; need controlled compute-matched baselines and negative-transfer audits across more text tasks (reasoning, factuality, safety).
- Reward function clarity: the PARL reward and key RL objective equations are partially garbled in the text; exact mathematical forms and implementation details (e.g., units, normalization) are missing.
- Hyperparameter sensitivity unreported: no ablations on token-level clipping bounds (
alpha,beta,tau), GRM weights, or PARL coefficients (lambda_1,lambda_2) and their annealing schedules. - Exploration vs. stability: the impact of the token-level clipping scheme on exploration, mode collapse, and long-horizon credit assignment is not analyzed theoretically or empirically.
- GRM reliability and bias: training data, rubric variants, inter-rater agreement with humans, and robustness to reward hacking/adversarial prompts are not reported, especially for multimodal outputs.
Agent Swarm (PARL) orchestration and scalability
- Optimality gap from frozen subagents: decoupled training avoids instability but may cap performance; no comparison with partially co-optimized or periodically refreshed subagents.
- Real-world generalization: training includes synthetic prompts; transfer to messy, dynamic, and dependency-heavy tasks (e.g., incremental requirements changes, flaky tools, rate limits) is not evaluated.
- Scheduling and straggler handling: beyond “critical steps,” wall-clock latency under heterogeneous I/O-bound subtasks, variance, and straggler mitigation (e.g., speculative execution) are not analyzed.
- Communication and context management: policies for sharing intermediate results, preventing redundant work, and managing context budgets across many subagents are unspecified and unevaluated.
- Safety in parallel execution: safeguards for parallel browsing, large-scale downloads, code execution, and tool-use (sandboxing, permissions, auditing) are not detailed; failure cascades and rollback strategies are unclear.
- Non-stationarity and lifecycle: how the orchestrator adapts as subagents are upgraded/replaced (distribution shift) is not addressed; policies for continual learning or orchestration distillation remain open.
Evaluation methodology and reproducibility
- Reproducibility gaps: many scores are from internal re-evaluations (*) or custom settings (e.g., “with context manage”); full evaluation harnesses, seeds, n-samples, retries, and tool configurations are not released.
- Fairness of comparisons: differences in tool access, context length (256k), temperature/top-p, and thinking modes across models may bias comparisons; ablation on decoding settings is missing.
- Error analysis absent: limited or no qualitative analysis of common failure cases (e.g., ZeroBench low scores), brittleness to prompt phrasing, or out-of-distribution stress tests.
- Long-context reliability: while context is extended to 256k, retrieval accuracy, position-bias, and truncation-related errors over long sessions are not quantified; no analysis of memory strategies or attention drift.
- Multilingual coverage: aside from SWE-Bench Multilingual, broader non-English performance for text, vision, OCR, and video is not reported.
Efficiency, cost, and infrastructure
- Compute and energy costs unreported: pre-training, mid-training, and RL FLOPs, GPU-hours, and energy/carbon estimates are absent, hindering cost-effectiveness assessment.
- DEP trade-offs: DEP recomputes the vision forward pass; the overhead vs. memory savings across batch sizes, resolutions, and cluster topologies is not quantified; failure modes under network contention are unknown.
- Inference cost and throughput: MoE activation (32B active) with multimodal encoders may be expensive; per-query latency and cost breakdowns (encoder vs. decoder vs. tool calls) are not provided.
- Token-efficient RL (Toggle) generality: sensitivity to
lambda,m,rhoand long-horizon tasks is unreported; risk of under-explaining or brittle short CoT on problems requiring extended reasoning remains unquantified.
Safety, ethics, and governance
- Data privacy and licensing: image/video/tool-use datasets’ license status, PII filtering, and opt-out compliance are not described.
- Hallucination and calibration: no systematic hallucination/groundedness evaluation for multimodal outputs (e.g., visual hallucinations, OCR confidence, citation grounding).
- Bias and fairness: vision/text biases (gender, race, geography), document OCR bias across scripts/fonts, and accessibility impacts are not assessed.
- Autonomy controls: policies for user consent, tool permissioning, rate limiting, and cross-domain data isolation in multi-agent execution are not specified.
- Misuse risks: no red-teaming results for agentic misuse (e.g., automated data exfiltration, cyber tasks) or mitigations beyond unspecified GRMs.
Open technical questions
- Can end-to-end differentiable co-optimization of orchestrator and subagents be stabilized to surpass the decoupled PARL approach?
- What is the principled schedule for vision-text mixing that optimizes sample efficiency across diverse tasks and compute budgets?
- How do generative-only visual pre-training objectives compare to hybrid (contrastive + generative) objectives for grounding, calibration, and compositional generalization?
- Under what conditions does visual RL reliably transfer to text (and vice versa), and when does negative transfer occur?
- What are the theoretical properties of token-level log-ratio clipping for large-scale, off-policy, multi-step RL (e.g., bias/variance trade-offs, convergence guarantees)?
Practical Applications
Overview
Based on the paper’s findings and innovations (joint text–vision optimization, zero‑vision SFT, outcome‑based and joint multimodal RL, Agent Swarm with PARL, MoonViT‑3D for native-resolution image/video, token‑efficient RL via Toggle, Generative Reward Models, and training infra like DEP), the following are practical, real‑world applications and workflows, grouped by deployment horizon.
Immediate Applications
- Software engineering copilots and automation (software)
- Visual-to-code and UI-to-frontend: generate code from UI mockups, screenshots, or videos; convert design/video demos into working components; assist with image/video-to-code prototyping.
- Repo triage and bug fixing: parallel static analysis, test generation, and patch proposals on large repos using Agent Swarm to reduce latency; CI/CD bots that open PRs with tests.
- IDE assistants: inline code repair from error screenshots, log parsing, and stacktrace+screen analysis.
- Potential tools/products: VS Code/JetBrains plugins; CI “PR bots”; repository-wide parallel analyzers.
- Assumptions/Dependencies: secure repo access and test suites; integration with SCM/CI; policy/compliance controls for code changes.
- Parallel knowledge search and evidence synthesis (academia, finance, policy, enterprise research)
- Orchestrated web research: Agent Swarm spins up sub‑agents to browse diverse sources in parallel, extract, deduplicate, and synthesize findings (BrowseComp/WideSearch-like).
- Long‑context digesting: summarize/compare 100–256k‑token corpora (reports, filings) with citation tracking.
- Potential tools/products: “Research Swarm” browser agent; literature/filing digester with confidence and provenance.
- Assumptions/Dependencies: robust browser automation and anti‑scraping compliance, source attribution, legal/ethical data use.
- Document understanding and OCR pipelines (finance, legal, healthcare administration, insurance)
- High‑accuracy OCR and layout parsing: extract structured data from invoices, receipts, contracts, forms; table/figure/chart understanding.
- Workflow acceleration: parallel page‑level extraction with aggregation agents; line‑item reconciliation and anomaly flags.
- Potential tools/products: invoice/receipt extractors; contract clause miners; claims pre‑processing.
- Assumptions/Dependencies: privacy/security controls (PII/PHI); domain templates or schema mapping; QA loops.
- Long video and meeting summarization (media, enterprise, education)
- MoonViT‑3D enables efficient variable-resolution ingestion and temporal compression for longer videos in the same context window.
- Use cases: meeting/minute generation from recordings; lecture/course summarization; editorial rough cuts; sports highlight extraction; training content indexing.
- Potential tools/products: “Video Summarizer Pro”; LMS integrations; media asset indexers.
- Assumptions/Dependencies: GPU budget for long contexts; storage/I/O throughput; consent for recordings.
- Computer use automation and RPA (enterprise IT, customer support)
- OS/Web task execution: automate multi‑step tasks (file operations, app/data ingestion, web portals) with improved success on OSWorld/WebArena‑style tasks.
- Parallel task orchestration: download/report generation across many sources in parallel; SLA‑oriented batch jobs.
- Potential tools/products: desktop/web RPA agents with parallel subtask scheduling; helpdesk automators.
- Assumptions/Dependencies: robust UI selectors, permissioning/credential vaults, audit trails, rollback plans.
- Customer support triage with screenshots and logs (software, consumer electronics)
- Troubleshoot user issues from screenshots, UI videos, and logs; map to known issues; propose guided steps.
- Potential tools/products: support ticket enrichers; self‑serve assistants with step‑by‑step guidance.
- Assumptions/Dependencies: integration with ticketing/KB; guardrails for device‑specific actions.
- STEM education and tutoring with diagrams/figures (education)
- Step‑by‑step solutions to math/physics problems involving charts/diagrams; problem generation and grading with rubric‑based feedback.
- Potential tools/products: multimodal tutors; teacher‑assist tools for grading and feedback.
- Assumptions/Dependencies: anti‑cheating guardrails; curriculum alignment; explanation quality controls.
- Cybersecurity assistance (security operations, DevSecOps)
- Multi‑agent analysis of logs/artifacts; code audit for vulnerabilities; lab exercises (CyberGym‑like) for training.
- Potential tools/products: SOC assistant for triage and playbook suggestions; secure coding reviewers.
- Assumptions/Dependencies: isolated sandboxes; strict access control and tampering safeguards; human‑in‑the‑loop.
- Robotics/industrial vision perception modules (manufacturing, logistics, retail)
- Visual grounding and counting for QC/stock counting; OCR for labels; simple visual QA tasks where action is separate.
- Potential tools/products: inspection dashboards; inventory counters; shelf analytics.
- Assumptions/Dependencies: calibrated cameras; lighting variability; integration to control systems if used for actuation (HITL advisable).
- Platform cost control via token‑efficient reasoning (AI infrastructure)
- Apply Toggle‑style training/serving policies to reduce average output tokens 25–30% with minimal accuracy loss; expose budget knobs to customers.
- Potential tools/products: “Cost‑Aware Reasoning Mode” in AI platforms; autoscaling policies for max tokens.
- Assumptions/Dependencies: RL pipeline or serving‑time heuristics; monitoring for quality regressions.
- Model training and evaluation infrastructure (AI R&D)
- Zero‑vision SFT to activate visual reasoning without heavy visual SFT; DEP for efficient multimodal training with balanced loads; GRMs for multimodal preference optimization.
- Potential tools/products: training cookbook; GRM‑based QA for content moderation, doc/video outputs.
- Assumptions/Dependencies: compute availability; high‑quality text SFT; sound reward rubrics; vigilance for reward hacking.
- Daily life assistants (consumer)
- Personal organizer: extract data from bills/receipts; build budgets; calendar from PDFs; parallel travel search (flights/hotels/visas).
- Home troubleshooting: analyze appliance screenshots/videos, suggest steps or schedule service.
- Assumptions/Dependencies: permissioned account connections; clear data retention policies; error‑handling UX.
Long‑Term Applications
- Autonomous multi‑agent project copilots (software, product development, enterprise PMO)
- Agent Swarm manages end‑to‑end project workflows: requirements research, design alternatives, implementation, testing, documentation—delegating to specialized sub‑agents and coordinating parallel workstreams.
- Potential tools/products: “Agent Swarm Studio” with orchestrator controls, critical‑steps KPIs, cluster schedulers.
- Assumptions/Dependencies: mature safety/oversight, robust sub‑agent pools, enterprise change‑management; more RL on real workflows.
- Clinical and biomedical AI copilots (healthcare)
- Multimodal chart/document extraction + imaging/video understanding for triage, reporting, and procedure summarization; integrate literature/clinical guidelines in parallel.
- Potential tools/products: radiology/echo report assistants; clinical documentation QA.
- Assumptions/Dependencies: regulatory clearance, validated datasets, bias/safety audits, EHR integration; strong HITL, privacy compliance (HIPAA/GDPR).
- Real‑time video analytics and edge deployments (retail, smart cities, transportation)
- Continuous monitoring with MoonViT‑3D on edge devices for event detection, queue length counting, shelf restocking alerts, traffic incident detection, and pipeline parallel analysis.
- Potential tools/products: edge video agents; store/traffic control dashboards.
- Assumptions/Dependencies: model compression/quantization, edge accelerators, privacy‑by‑design, false positive mitigation.
- Domestic/industrial robots with multimodal agent brains (robotics)
- Combine visual grounding, counting, document/label understanding with planning; parallel modules for perception, planning, and task execution coordinated by an orchestrator.
- Potential tools/products: robot middleware plugins; vision‑language controllers for multi‑task robots.
- Assumptions/Dependencies: tight integration with control stacks; sim‑to‑real transfer; safety and reliability guarantees; extensive RL with real‑world feedback.
- Autonomous scientific assistants (academia, pharma, materials)
- Large‑scale parallel literature sweeps, plot/figure data extraction (chart/document vision), code generation for replication, and result synthesis.
- Potential tools/products: “Auto‑Meta‑Analysis” suites; lab‑notebook agents.
- Assumptions/Dependencies: licensing for paywalled content; provenance tracking; domain validation with SMEs.
- Government and policy evidence synthesis (public sector, NGOs)
- Rapid, parallel evidence gathering across multilingual sources; extraction from long documents; synthesis into policy briefs with uncertainty characterization.
- Potential tools/products: policy brief generators; crisis response intel hubs.
- Assumptions/Dependencies: misinformation detection; secure data pipelines; auditability and public record compliance.
- Financial research and compliance copilots (finance)
- Autonomous analyst swarms scanning filings, earnings calls, news, and alternative data in parallel; compliance monitoring across websites/docs and internal comms.
- Potential tools/products: “Analyst Swarm”; RegTech compliance watchers.
- Assumptions/Dependencies: strict risk controls, adversarial testing, model governance; access to market data; latency‑aware orchestration.
- Multi‑tenant agent orchestration platforms (software/AI infrastructure)
- Cluster‑scale parallel agent orchestration with PARL‑style rewards, dynamic instance ratios, and “critical steps” as a platform KPI to optimize latency under load.
- Potential tools/products: Kubernetes‑native agent schedulers; observability for sub‑agent graphs and rewards.
- Assumptions/Dependencies: advanced resource schedulers; robust failure isolation; reward design to avoid spurious parallelism.
- Standardized GRM‑driven safety/alignment for multimodal outputs (AI safety and tooling)
- GRM‑as‑a‑Service for evaluating helpfulness, instruction adherence, artifacts’ aesthetics/appropriateness across chat, images, and videos; plug‑in evaluators for multi‑agent pipelines.
- Potential tools/products: SaaS evaluators; continuous preference learning loops.
- Assumptions/Dependencies: diverse rubrics, multi‑rater calibration, anti‑reward‑hacking safeguards.
- Privacy‑preserving on‑device multimodal agents (consumer, enterprise)
- Compressed K2.5‑derived models for offline document/video understanding and assistance, reducing data egress risks.
- Potential tools/products: mobile/edge personal assistants for documents/photos/videos.
- Assumptions/Dependencies: efficient distillation/quantization, device‑class accelerators, energy constraints.
- Research on cross‑modal transfer and curricula (academia)
- Use zero‑vision SFT + visual RL to study and formalize when visual training improves text reasoning; develop curricula organized by abilities rather than modalities.
- Potential tools/products: open benchmarks and training recipes; pedagogical agents.
- Assumptions/Dependencies: shared datasets and compute; reproducibility frameworks.
Cross‑cutting Assumptions and Dependencies
- Tooling and integrations: reliable browser/OS/IDE automation, API access, credential management, observability, and rollback.
- Compute and cost: long contexts and video understanding require significant GPU/TPU budgets; Toggle‑style policies and caching mitigate serving cost.
- Data governance: privacy, consent, retention, and regulatory compliance (e.g., HIPAA/GDPR, SOX); provenance and audit trails for all agent actions.
- Reliability and safety: human‑in‑the‑loop for high‑stakes tasks; adversarial robustness; monitoring for reward hacking; clear escalation paths.
- Legal/ethical use: compliant web data acquisition; IP considerations for code/content generation; sector‑specific regulation for deployment.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a short definition and a verbatim usage example.
- Ablation studies: Controlled experiments that vary specific components to assess their impact on performance. "We conducted ablation studies varying the vision ratio and vision injection timing while keeping the total vision and text token budgets fixed."
- Agent Swarm: A framework for dynamically decomposing tasks into parallelizable subtasks executed by specialized agents. "To overcome the latency and scalability limits of sequential agent execution, Kimi K2.5 introduces Agent Swarm, a dynamic framework for parallel agent orchestration."
- Agentic intelligence: The capability of models to plan, act, and use tools autonomously to accomplish complex tasks. "LLMs are rapidly evolving toward agentic intelligence."
- Annealing: Gradually reducing a parameter (e.g., a reward weight) during training to stabilize or shift the objective. "To ensure the final policy optimizes for the primary objective, the hyperparameters and are annealed to zero over the course of training."
- Context window: The maximum token span a model can attend to during inference or training. "process videos up to 4 longer within the same context window while maintaining complete weight sharing between image and video encoders."
- Contrastive loss: A learning objective that brings matched pairs closer and pushes mismatched pairs apart in representation space. "Unlike the implementation in Kimi-VL~\cite{team2025kimivl}, this continual pre-training does not include a contrastive loss, but incorporates solely cross-entropy loss for caption generation conditioned on input images and videos."
- Critical steps: A latency-oriented metric analogous to the critical path, summing main-agent steps and the longest parallel subagent branch per stage. "By constraining training and evaluation using critical steps rather than total steps, the framework explicitly incentivizes effective parallelization."
- Credit assignment ambiguity: Uncertainty about which component’s actions led to success or failure in multi-agent or multi-step settings. "This decoupling circumvents two challenges of end-to-end co-optimization: credit assignment ambiguity and training instability."
- Decoupled Encoder Process (DEP): A training strategy that separates the vision encoder’s computation from the main backbone to balance load and memory. "our training uses Decoupled Encoder Process (DEP), which is composed of three stages in each training step:"
- Early fusion: Introducing multimodal inputs (e.g., vision) early in training with a modest ratio to build balanced representations. "In fact, early fusion with a lower vision ratio yields better results given a fixed total vision-text token budget."
- Embedding space: The vector representation domain in which inputs (images, videos, text) are mapped for model processing. "with a unified architecture, fully shared parameters, and a consistent embedding space."
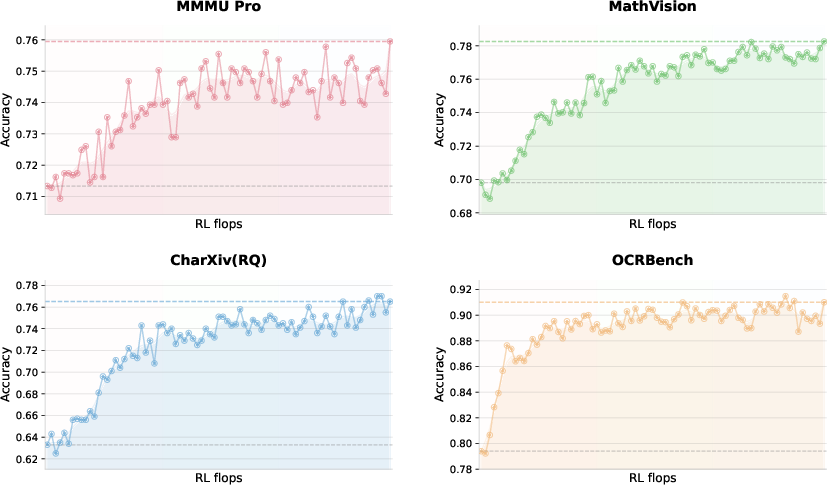
- FLOPs: Floating point operations per second; a measure of computational cost or scaling in training/inference. "By scaling vision RL FLOPs, the performance continues to improve, demonstrating that zero-vision activation paired with long-running RL is sufficient for acquiring robust visual capabilities."
- Generative Reward Models (GRMs): Learned evaluators that provide nuanced, preference-aligned reward signals for open-ended outputs. "For general-purpose tasks, we employ Generative Reward Models (GRMs) that provide granular evaluations aligned with Kimi's internal value criteria."
- Gradient masking: Zeroing out gradients when certain conditions (e.g., log-ratio bounds) are violated to stabilize training. "The mechanism functions as a simple gradient masking scheme: policy gradients are computed normally for tokens with log-ratios within the interval [\alpha, \beta], while gradients for tokens falling outside this range are zeroed out."
- Intersection over Union (IoU): A metric for overlap between predicted and ground-truth regions used in detection/segmentation rewards. "grounding tasks derive soft matches from Intersection over Union (IoU) and point tasks derive soft matches from Gaussian-weighted distances under optimal matching."
- Log-ratio: The logarithmic ratio between new and old policy probabilities, used for clipping or stability in RL. "Notably, a key distinction from standard PPO clipping #1{schulman2017proximal} is that our method relies strictly on the log-ratio to explicitly bound off-policy drift, regardless of the sign of the advantages."
- Mixture-of-Experts (MoE): A sparse architecture using multiple expert sub-models, selectively activated per token. "The foundation of Kimi K2.5 is Kimi K2~#1{team2025kimik2}, a trillion-parameter mixture-of-experts (MoE) transformer~#1{transformer} model pre-trained on 15 trillion high-quality text tokens."
- MoonViT-3D: A native-resolution vision encoder with shared parameters for images and videos, enabling unified spatiotemporal processing. "Architecturally, Kimi K2.5 employs MoonViT-3D, a native-resolution vision encoder incorporating the NaViT packing strategy~#1{dehghani2023patchnpacknavit}, enabling variable-resolution image inputs."
- NaViT packing strategy: A method for packing variable-resolution image patches into sequences for efficient transformer processing. "Architecturally, Kimi K2.5 employs MoonViT-3D, a native-resolution vision encoder incorporating the NaViT packing strategy~#1{dehghani2023patchnpacknavit}, enabling variable-resolution image inputs."
- Off-policy divergence: Instability arising when training updates deviate from trajectories generated by the behavior policy. "This loss function departs from the policy optimization algorithm used in K1.5... designed to mitigate the off-policy divergence amplified by discrepancies between training and inference frameworks."
- Orchestrator: The trainable controller that coordinates subagents, parallelization, and task decomposition in PARL. "During training, sub-agents are frozen and their execution trajectories are excluded from the optimization objective; only the orchestrator is updated via reinforcement learning."
- Outcome-based RL: Reinforcement learning that uses verifiable task outcomes to define rewards, especially for vision-required tasks. "We employ outcome-based RL on tasks that explicitly require visual comprehension for correct solutions."
- Parallel-Agent Reinforcement Learning (PARL): An RL paradigm where a central orchestrator learns when and how to parallelize subagents. "We propose a Parallel-Agent Reinforcement Learning (PARL) paradigm that departs from traditional agentic RL~#1{moonshotai2025kimiresearcher}."
- Patch n' pack: Packing 2D patches (and extended to temporal volumes) into a 1D sequence for unified attention. "By generalizing the
patch n' packphilosophy to the temporal dimension, up to four consecutive frames are treated as a spatiotemporal volume..." - Pipeline Parallelism (PP): Splitting model layers across devices to parallelize training, here adapted for multimodal inputs. "In a typical multimodal training paradigm utilizing Pipeline Parallelism (PP), the vision encoder and text embedding are co-located in the first stage of the pipeline (Stage-0)."
- PPO clipping: A stabilization technique from Proximal Policy Optimization that constrains policy updates. "Notably, a key distinction from standard PPO clipping #1{schulman2017proximal} is that our method relies strictly on the log-ratio..."
- QK-Clip: A training stability technique paired with the MuonClip optimizer for large-scale transformers. "Kimi K2 employs the token-efficient MuonClip optimizer~#1{jordan2024muon,liu2025muon} with QK-Clip for training stability."
- Rasterize: Converting vector polygons to pixel masks for computing segmentation-based rewards. "For polygon segmentation tasks, we rasterize the predicted polygon into a binary mask and compute the segmentation IoU against the ground-truth mask to assign the reward."
- Rejection-Sampling Fine-Tuning (RFT): Fine-tuning using selected high-quality trajectories sampled by rejecting lower-quality ones. "Extracting these trajectories for rejection-sampling fine-tuning (RFT) enables a self-improving data pipeline..."
- Reward hacking: Exploiting reward definitions to improve metrics without genuinely solving the task. "The $r_{\text{finish}$ reward focuses on the successful completion of assigned subtasks. It is used to prevent spurious parallelism, a reward-hacking behavior in which the orchestrator increases parallel metrics dramatically by spawning many subagents without meaningful task decomposition."
- SigLIP: A vision-language pretraining approach (here used as initialization) based on sigmoid loss. "Initialized from SigLIP-SO-400M~#1{zhai2023sigmoidlosslanguageimage}, MoonViT incorporates the patch packing strategy from NaViT..."
- Sub-agent: A specialized, frozen agent instantiated and scheduled by the orchestrator for parallel subtasks. "In addition to optimizing tool execution via verifiable rewards, the model is equipped with interfaces for sub-agent creation and task delegation."
- Supervised Fine-Tuning (SFT): Post-training using labeled or curated instruction-following data to refine model behavior. "Following the SFT pipeline established by Kimi K2 #1{team2025kimik2}, we developed K2.5 by synthesizing high-quality candidate responses..."
- Temporal attention: Attention mechanisms extended across time to capture motion or temporal dependencies in videos. "While the extra temporal attention improves understanding on high-speed motions and visual effects, the sharing maximizes knowledge generalization..."
- Temporal compression: Reducing the temporal resolution (e.g., by pooling) to extend the effective video length within constraints. "yielding temporal compression to significantly extend feasible video length."
- Temporal pooling: Aggregating features across frames (time) before projection to reduce sequence length and preserve salient information. "Prior to the MLP projector, lightweight temporal pooling aggregates patches within each temporal chunk..."
- Test-time scaling: Allocating more compute (tokens/steps) at inference to improve reasoning quality. "Token efficiency is central to LLMs with test-time scaling."
- Toggle: A training heuristic alternating between budget-constrained and scaling phases to balance efficiency and capability. "To this end, we propose Toggle, a training heuristic that alternates between {inference-time scaling} and {budget-constrained optimization}:"
- Vision grounding: Linking textual references to specific image regions or objects (localization) as part of vision tasks. "Visual grounding and counting: Accurate localization and enumeration of objects within images;"
- Vision Transformer (ViT): A transformer architecture for vision inputs that operates on patch embeddings. "we introduce a lightweight 3D ViT compression mechanism:"
- Vision-text alignment: The learned correspondence between visual and textual representations enabling cross-modal transfer. "joint pretraining already establishes strong vision-text alignment, enabling capabilities to generalize naturally across modalities."
- YaRN interpolation: A method for extending context length by interpolating positional embeddings. "sequentially extending context length via YaRN~#1{peng2023yarn} interpolation."
Collections
Sign up for free to add this paper to one or more collections.