- The paper introduces PITQS that frames neural quantum states as latent imaginary-time evolution to target ground states using a weight-shared effective Hamiltonian.
- It employs advanced Trotter–Suzuki decompositions to reduce parameter count and improve energy convergence in benchmark models like the J1-J2 Heisenberg system.
- Results demonstrate enhanced parameter efficiency, scalable performance, and potential adaptation for fermionic systems through tokenized antisymmetry in wavefunction decoding.
Introduction and Motivation
Neural quantum states (NQS), particularly those grounded in modern deep learning architectures, have facilitated high-precision variational approximate solutions to challenging quantum many-body problems. Transformer-based quantum states (TQS) constitute the current benchmark in several strongly correlated systems such as the frustrated J1-J2 Heisenberg model, but the physical interpretation of their architecture remains opaque. The dominant approach is "black box": generic transformer stacks are typically overparameterized, and there is little control or understanding regarding why particular design choices impact variational performance. This lack of physical transparency impedes systematic architectural progress and undermines the interpretability of variational Monte Carlo (VMC) results.
The present work introduces a physically motivated architecture, physics-inspired transformer quantum states (PITQS), in which the NQS is interpreted as a neural surrogate for imaginary-time evolution (ITE) in a learned latent space. The PITQS architecture formalizes the deep neural network as "latent imaginary-time evolution" (LITE), driven by a static (i.e., weight-shared) effective Hamiltonian. Furthermore, the architecture harnesses higher-order Trotter–Suzuki decompositions to enhance propagation accuracy, breaking the necessity for overparameterization without sacrificing performance. This construction produces NQS with both systematic physical grounding and strong numerical results.
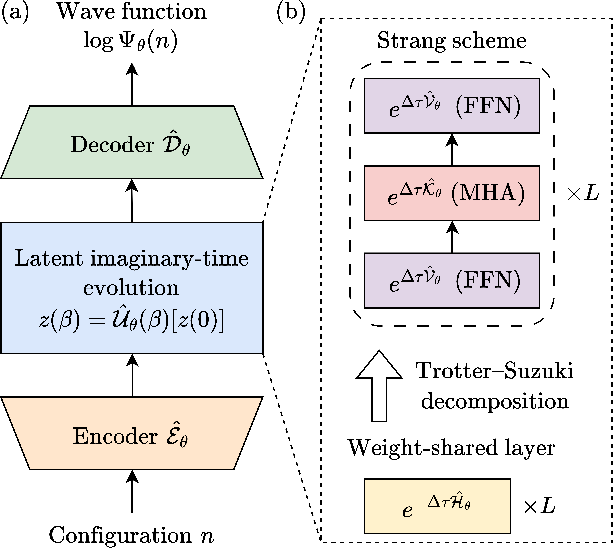
Figure 1: Schematic of the PITQS architecture: spin configuration n is encoded, evolved in latent space via repeated application of a static effective Hamiltonian (using Trotter–Suzuki splitting), and decoded to the log-amplitude of the many-body wavefunction.
The PITQS ansatz for the wavefunction amplitude Ψθ(n) is decomposed explicitly into three logical operations:
- Latent Encoder: E^θ embeds the physical configuration n into a latent variable z(0) (a set of "tokens").
- Latent Imaginary-Time Evolution Operator: U^θ(β) propagates the latent variable z(0) to z(β) under a static, learned effective Hamiltonian for fictitious or "imaginary time" β.
- Wavefunction Decoder: D^θ maps the cooled latent variables to the log-amplitude representation of the wavefunction.
This realizes
logΨθ(n)=D^θ(U^θ(β)E^θ[n])
where U^θ(β)≡e−βH^θ constitutes evolution by a static Hamiltonian in latent space.
Standard TQS architectures are revealed to implement a depth-unrolled evolution with distinct, layer-dependent effective Hamiltonians. This corresponds to a latent-space "cooling" process with effective Hamiltonian H^θ(ℓ) at each layer, i.e.,
U^θ(β)≈Tτℓ=1∏Le−ΔτH^θ(ℓ)
This construction lacks physical motivation, as ITE aims to target the ground state of a single Hamiltonian, and the per-layer variation constitutes an overparameterized, redundant ansatz.
Under the PITQS design, the LITE operator is implemented by weight-sharing the effective Hamiltonian across all layers and by utilizing higher-order Trotter–Suzuki splitting for the noncommuting local (on-site) and non-local (off-site) latent operators. This systematic design reduces parameter count by a factor of the depth L compared to standard TQS.
Trotter–Suzuki Decomposition and Enhanced Physical Inductive Bias
The propagation in latent space is governed by an effective Hamiltonian of the structure
H^θ=−(V^θ+K^θ)
where V^θ corresponds to local token updates (feed-forward networks), and K^θ to nonlocal token–token interactions (self-attention). To accurately approximate the continuous evolution operator e−βH^θ, the architecture enforces a fixed, weight-shared effective Hamiltonian (θ identical for all L layers) and approximates the exponential via
- First-order Lie–Trotter decomposition (standard in TQS)
- Second- or higher-order Trotter–Suzuki schemes (Strang, Suzuki, Blanes–Moan decompositions)
Higher-order decompositions create a more accurate approximation to imaginary-time propagation at fixed network depth, reducing Trotter errors without introducing extra learnable parameters.
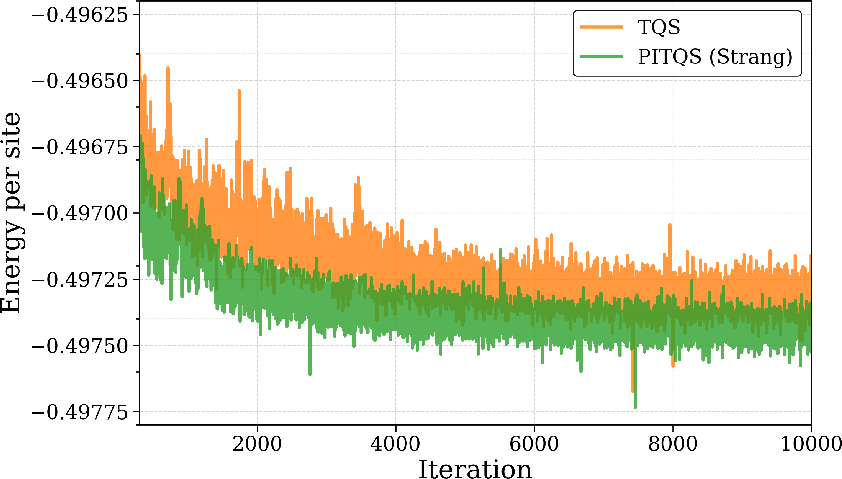
Figure 2: Optimization trajectories of energy per site for PITQS (Strang) and a standard TQS, demonstrating accelerated and lower-energy convergence for PITQS using fewer parameters.
Numerical Results: J1-J2 Heisenberg Benchmarks
Benchmarking was performed on the prototypical frustrated J1–J2 Heisenberg model on a 10×10 square lattice at J2/J1=0.5. Several key findings emerge:
- Parameter Efficiency: At fixed architecture (encoder-decoder), the PITQS ansatz matches or exceeds the variational energy accuracy of standard TQS while utilizing 3–7× fewer variational parameters. Conventional TQS performance saturates and does not improve monotonically with parameter count, reflecting redundancy in per-layer Hamiltonian freedom.
- Trotter Order and Accuracy: Increasing the Trotter–Suzuki order systematically reduces energy, with the fourth-order Suzuki and Blanes–Moan decompositions yielding the best energies in moderate-β regimes.
- Scalability: Larger PITQS instances (Strang, Np=143010) outperform TQS models of comparable parameter count and match the best energies in the literature, despite a much smaller parameter budget.
- Cooling Effect: The LITE block acts as a monotonic cooling mechanism for the variational energy as β increases, directly tracking the expected imaginary-time evolution.
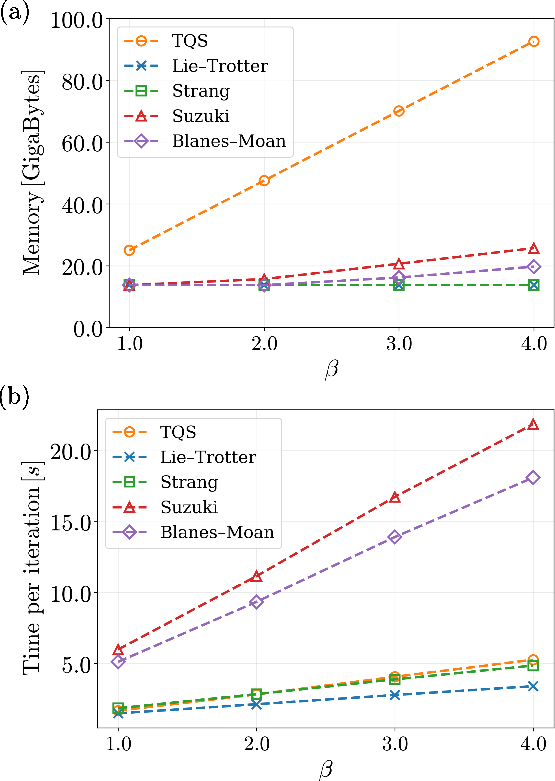
Figure 3: Computational cost of PITQS and standard TQS as a function of imaginary time β; PITQS shows parameter and memory efficiency due to weight sharing.
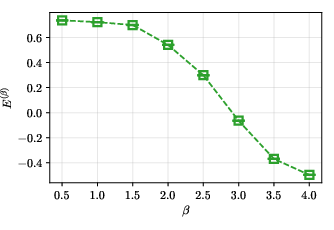
Figure 4: Progression of energy per site E(β) when evaluating the pre-trained PITQS ansatz for increasing latent imaginary-time extent, verifying monotonic cooling toward the ground state.
Computational and Practical Considerations
The PITQS architecture substantially reduces computational resources compared to TQS. Parameter count and peak memory consumption are almost independent of the evolution depth β for PITQS, while they grow linearly for TQS. In practical optimization, low-order decompositions (Lie–Trotter, Strang) yield robust convergence and maintain stability across large β. Higher-order decompositions can yield better energies at moderate β but may introduce sampling/optimization instability at large β.
Extension to Fermionic Systems
The formalism is readily adapted for interacting fermionic systems, as demonstrated on the 4×4 Hubbard model benchmark. With appropriate tokenization and antisymmetry-enforcing decoders, PITQS achieves accuracy matching TQS at less than half the parameter count on this strongly correlated fermion system.
Theoretical and Practical Implications
The central implication is that incorporating an explicit, physically justified inductive bias—wherein the NQS architecture is aligned with the underlying physical process (imaginary-time evolution under a static Hamiltonian)—dramatically increases parameter efficiency without sacrificing expressivity. This finding suggests that much of the empirical performance of generic deep NQS arises from a latent alignment with ITE, and guides future architecture design toward more interpretable and controllable forms.
A practical implication is that parameter-efficient variational optimization becomes feasible for larger problems due to drastically improved memory and compute scaling. Weight sharing and systematic Trotter improvement also facilitate hardware-efficient implementation, with direct analogies to universal transformers and iterative (recurrent) networks in machine learning.
On a theoretical level, PITQS establishes a principled bridge between black-box NQS and systematic, physically motivated variational ansätze. This connection opens further avenues for integrating quantum-inspired splittings, continuous-time flows, and interpretability into neural many-body wavefunction approximation methods.
Conclusion
The physics-inspired transformer quantum states (PITQS) framework introduces a systematic and physically interpretable approach to neural quantum states, leveraging a latent imaginary-time evolution formalism with a static effective Hamiltonian and higher-order Trotter–Suzuki evolution. The architecture achieves state-of-the-art variational energy results at a fraction of the parameter cost of standard TQS, unifying expressivity and physical transparency, and charting a course for future scalable NQS design grounded in physical principles (2602.03031).