- The paper presents a novel tracking adaptation method that leverages COLMAP-derived 3D tracks to supervise SuperPoint features for endoscopic data.
- It employs a multi-image batch triplet loss to enhance descriptor discriminability and achieve a precision of 63.2%, outperforming traditional methods.
- The approach demonstrates strong domain generalization and nearly doubles frame reconstruction coverage in colonoscopy videos, supporting clinical navigation.
Motivation and Problem Setting
Robust 3D reconstruction in endoscopic imagery presents unique challenges for traditional Structure-from-Motion (SfM) and SLAM pipelines. Endoscopic scenes are typically characterized by low texture, frequent illumination fluctuations due to direct light source attachment, and prevalent specular reflections, all of which degrade the repeatability and discriminability of conventional local features. Hand-crafted methods such as SIFT and ORB yield sub-optimal results in these conditions, motivating the need for domain-adapted, learned feature detectors and descriptors. The SuperPoint framework provides a viable foundation for deep feature extraction, but its self-supervised training is agnostic to the idiosyncrasies of endoscopic data.
Tracking Adaptation: Training with Reliable 3D Tracks
The central contribution of "SuperPoint-E: local features for 3D reconstruction via tracking adaptation in endoscopy" (2602.04108) is a novel supervision mechanism—Tracking Adaptation—specifically designed to adapt SuperPoint features to the endoscopic domain. Instead of synthetic homographies or pairwise correspondence heuristics, the scheme leverages reliable multi-frame keypoint tracks derived from successful COLMAP 3D reconstructions on endoscopic sequences.
The method involves the following pipeline: (1) Run COLMAP to reconstruct short, high-quality sub-sequences, reprojecting recovered 3D points back into individual frames; (2) Identify reliable tracks—spatio-temporal chains of the same 3D point observed across multiple images (Figure 1). These tracks, post-processed to mark the intervals of successful detection and observation, serve as precise ground-truth correspondences spanning the training batch.
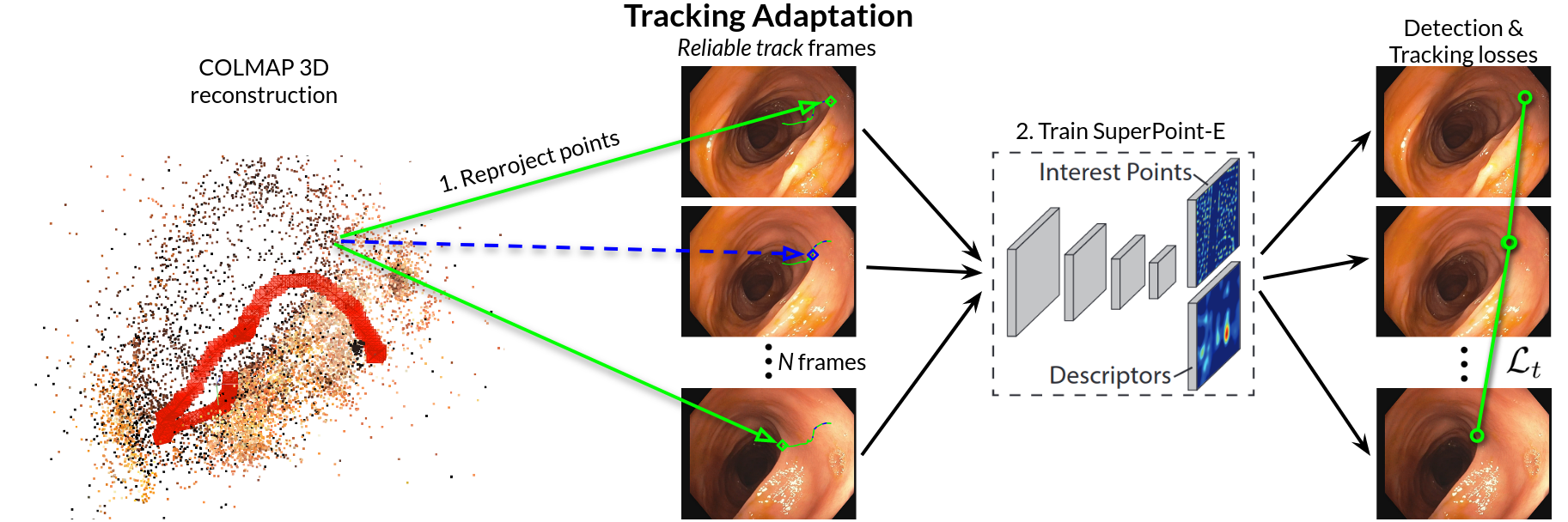
Figure 1: A schematic overview of Tracking Adaptation supervision using COLMAP-generated 3D tracks reprojected into training frames for SuperPoint-E.
This approach eschews pairwise-only supervision in favor of higher-order consistency, enforcing that the learned representation maps different 2D manifestations of the same 3D feature across the sequence to close, discriminative descriptors.
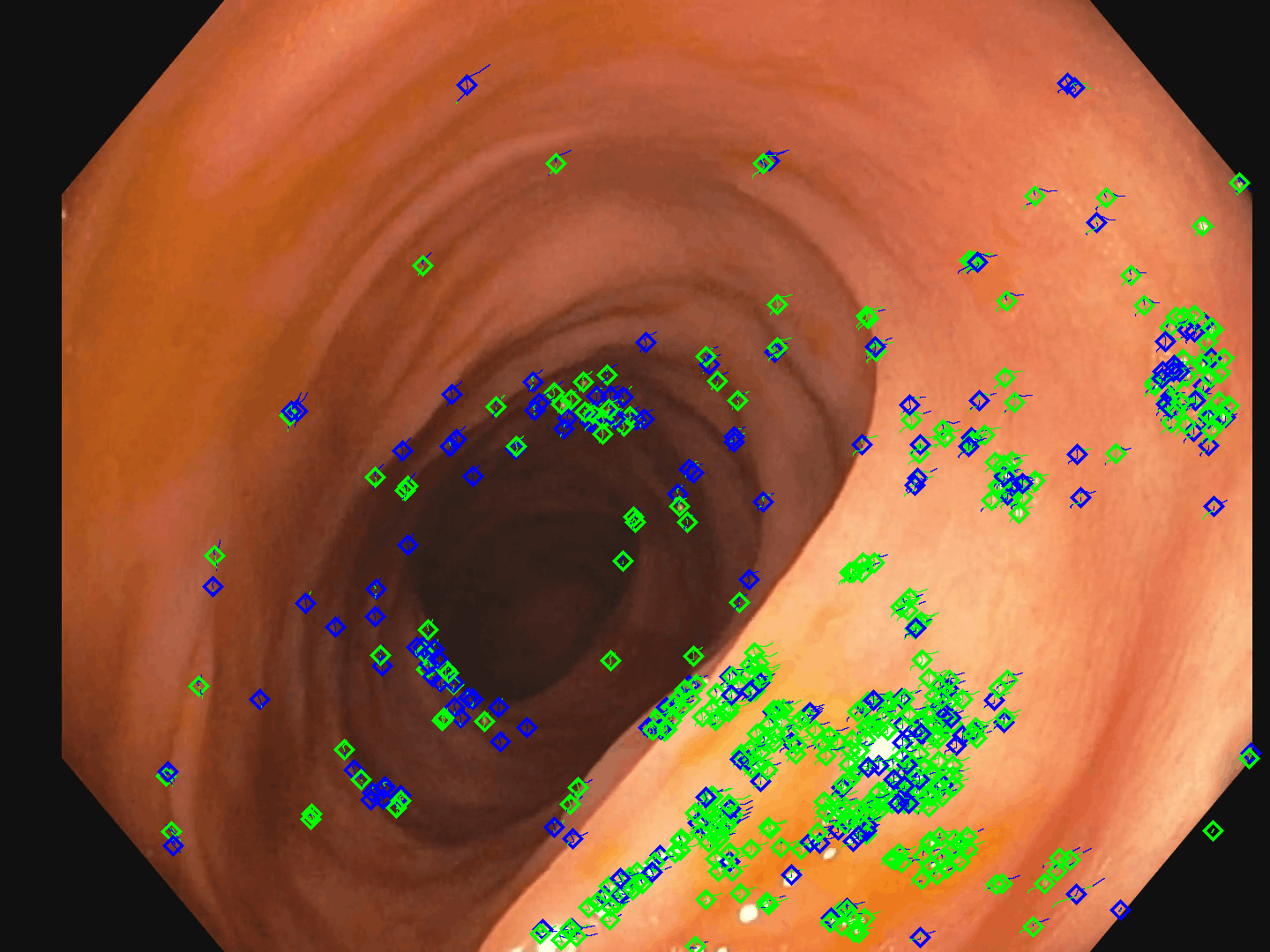
Figure 2: Illustration of reliable point tracks used for supervision—green denotes successful detection, blue denotes track continuation without current detection.
Network Design and Training
SuperPoint-E inherits the fully convolutional encoder-decoder architecture of SuperPoint, generating both a keypoint heatmap and per-pixel descriptors. The detection head is trained using a standard cross-entropy loss over the reliable 2D keypoint positions indicated by the reprojected 3D tracks. Critically, the descriptor head is supervised via a novel tracking loss formulated as a multi-image batch triplet loss, promoting intra-track descriptor similarity and inter-track separation.
Given a batch of N images with at least one shared reliable track, the objective accumulates detection and tracking loss terms. The positive margin and negative margin hyperparameters are selected to optimize over the distribution of descriptor similarities across the extracted tracks. Ablation studies indicate that modest increases to batch size (N=4) maximize reconstruction density and descriptor discriminability without incurring diminishing returns or computational overhead.
Experiments and Quantitative Analysis
Evaluation is performed on established endoscopic video datasets (EndoMapper, C3VD) under exhaustive and guided matching regimes, benchmarking against SIFT and standard SuperPoint. Metrics encompass reconstructed keypoint precision, coverage, point cloud density, mean reprojection error, feature track length, spatial spread, and sensitivity to specularities.
Feature Matching and Reconstruction
SuperPoint-E achieves a precision of 63.2% for detected features included in the final 3D reconstruction, outperforming both SIFT+GM (46.1%) and SuperPoint+GM (57.7%). The mean number of reconstructed 3D points increases by a factor of >3x over SIFT baselines, and the spatial distribution ("spread") of reconstructed points reaches 86.3%, indicating robust coverage across low-texture organ regions.
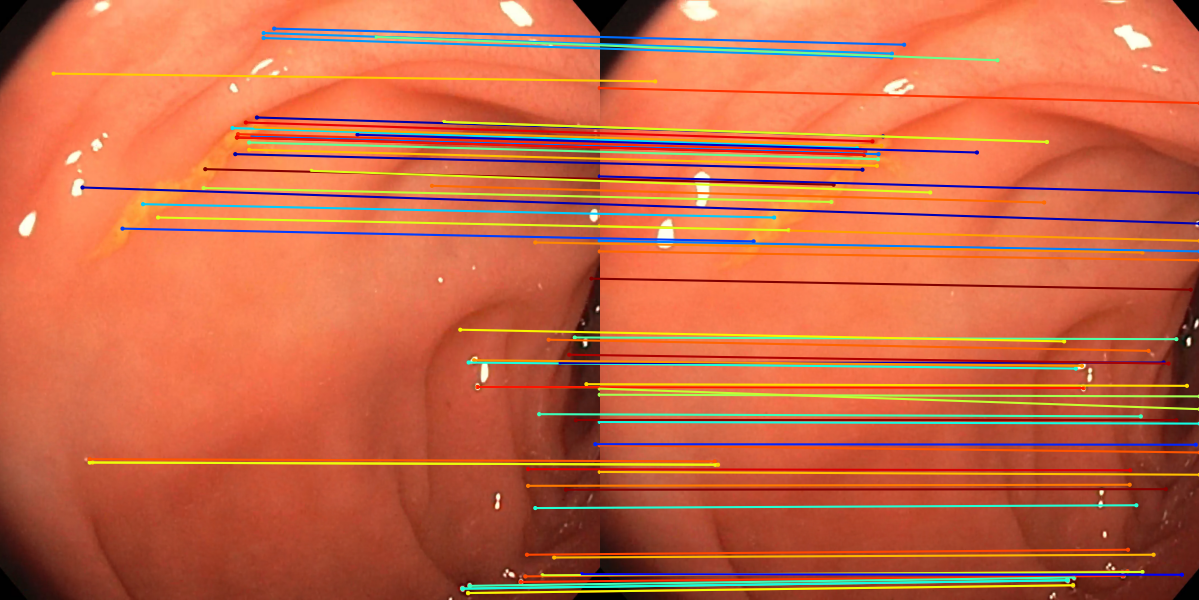


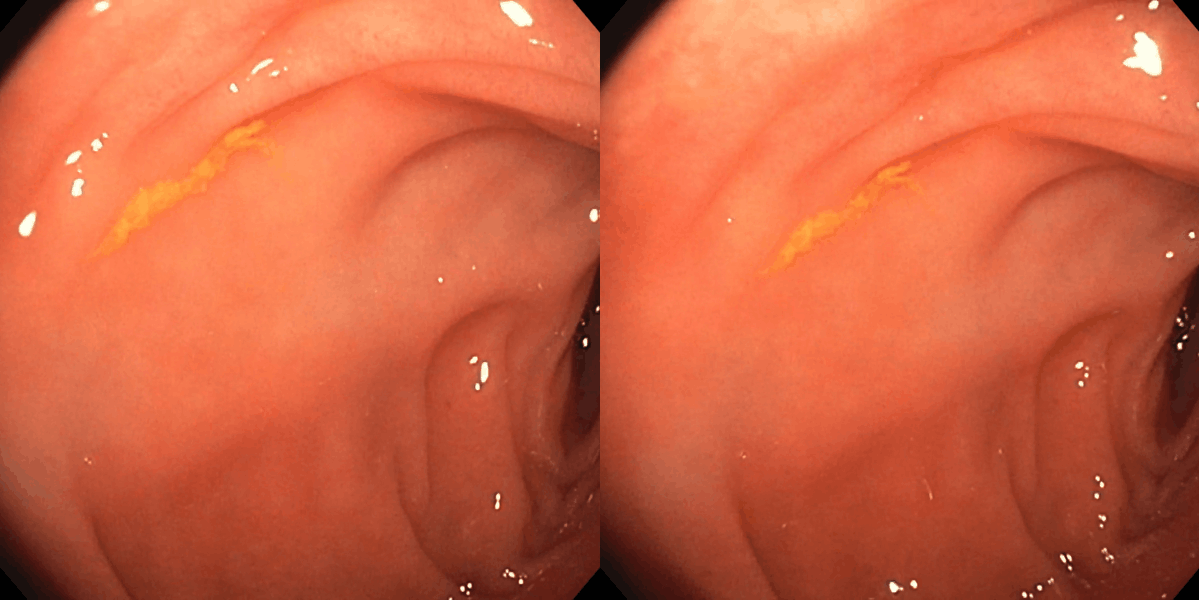


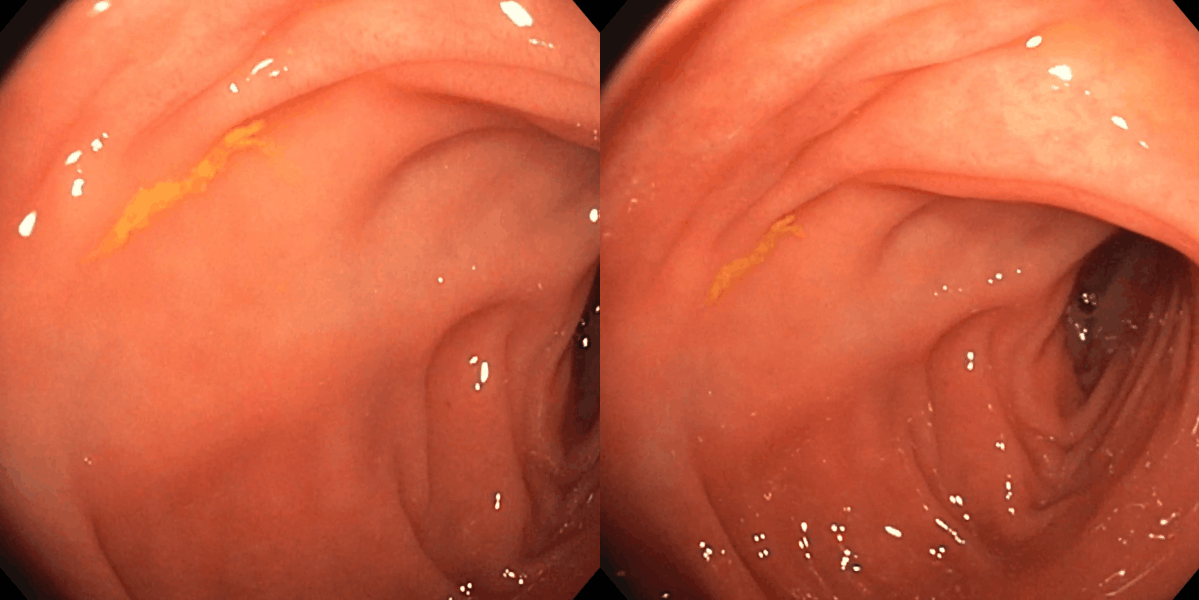


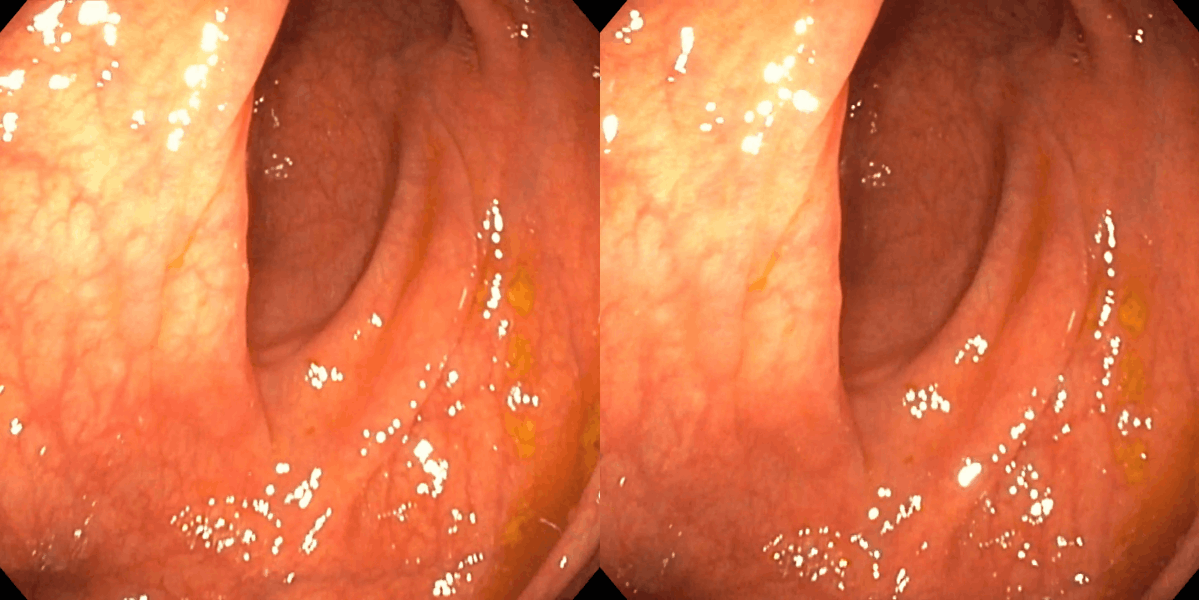



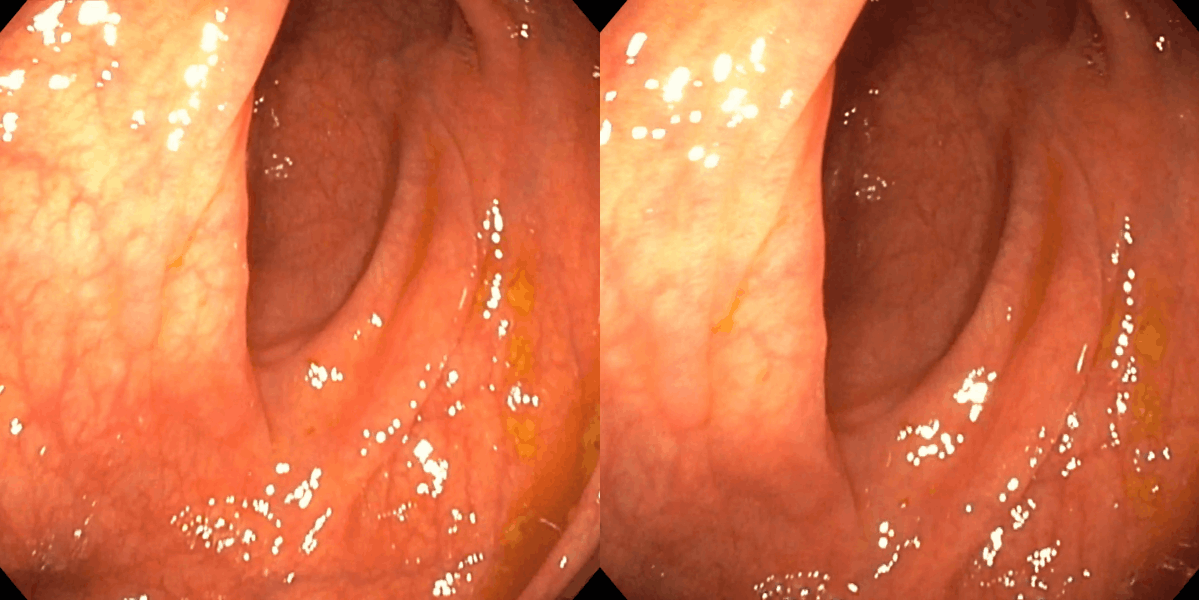
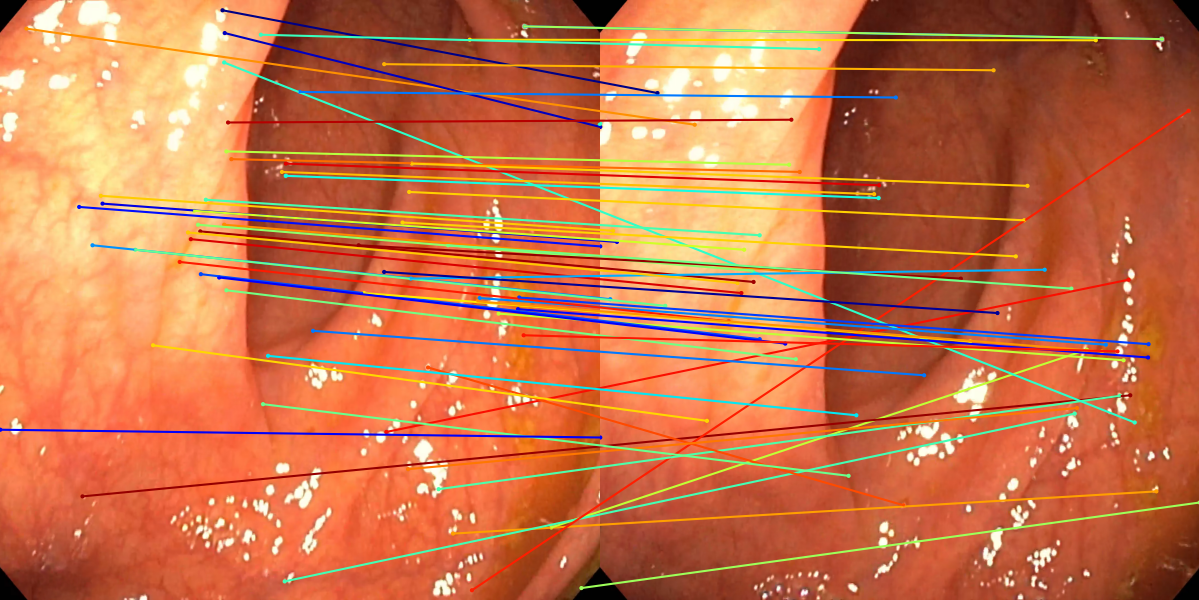

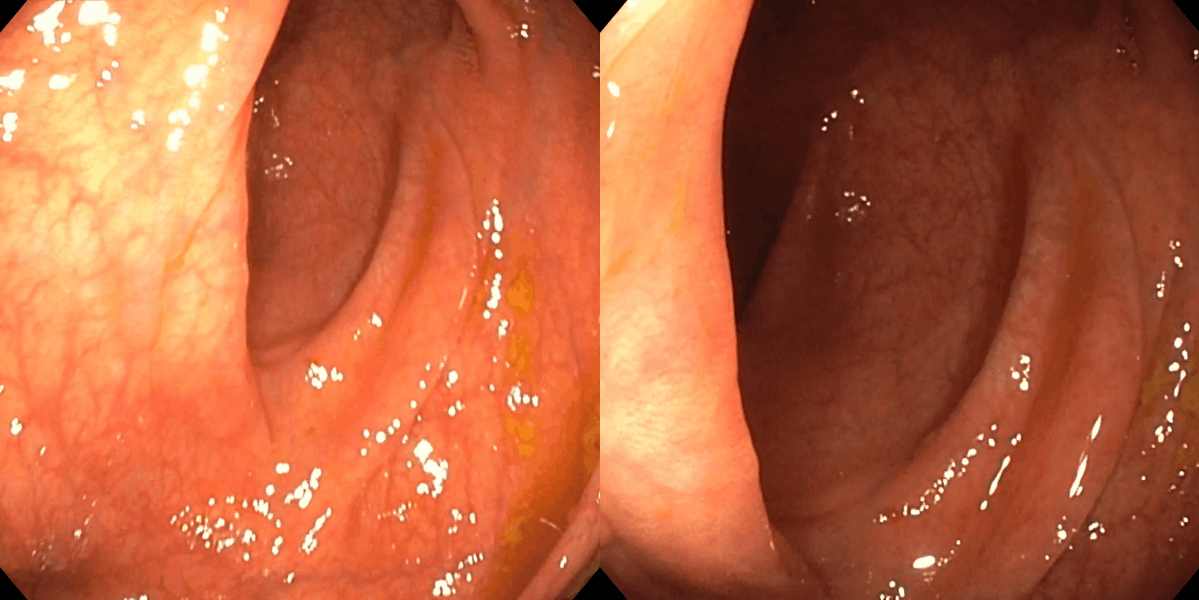
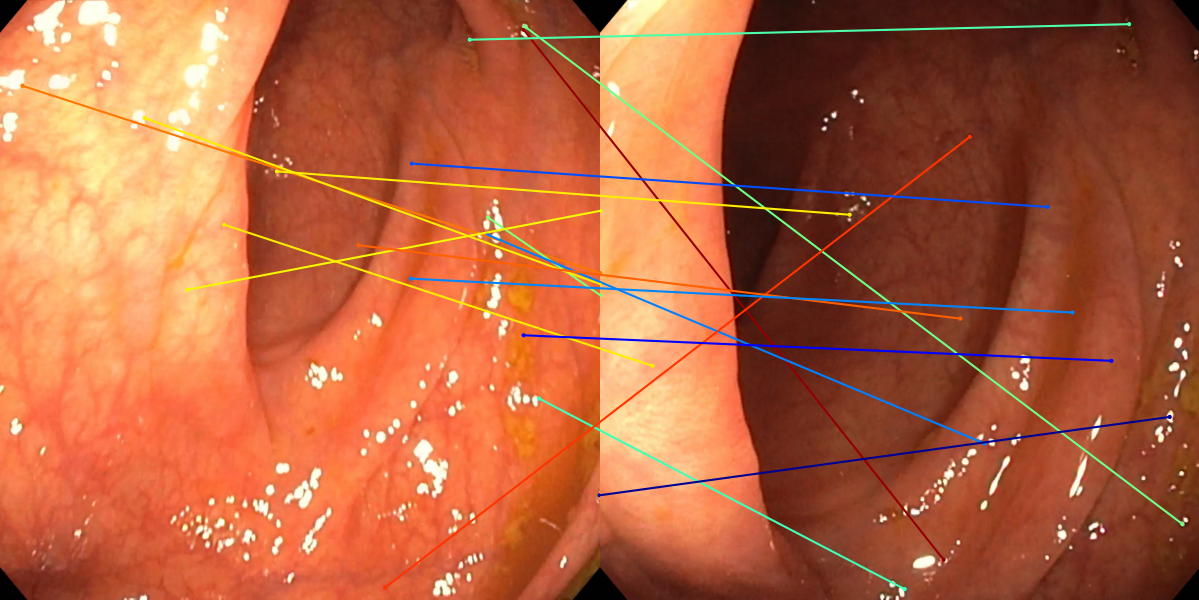


Figure 3: Matching results between frame pairs at increasing intervals, with SuperPoint-E yielding denser and more persistent correspondences.
Track lengths (average number of images per reconstructed point) are extended, further highlighting the enhanced temporal consistency of features, which is critical for downstream pose and map accuracy.




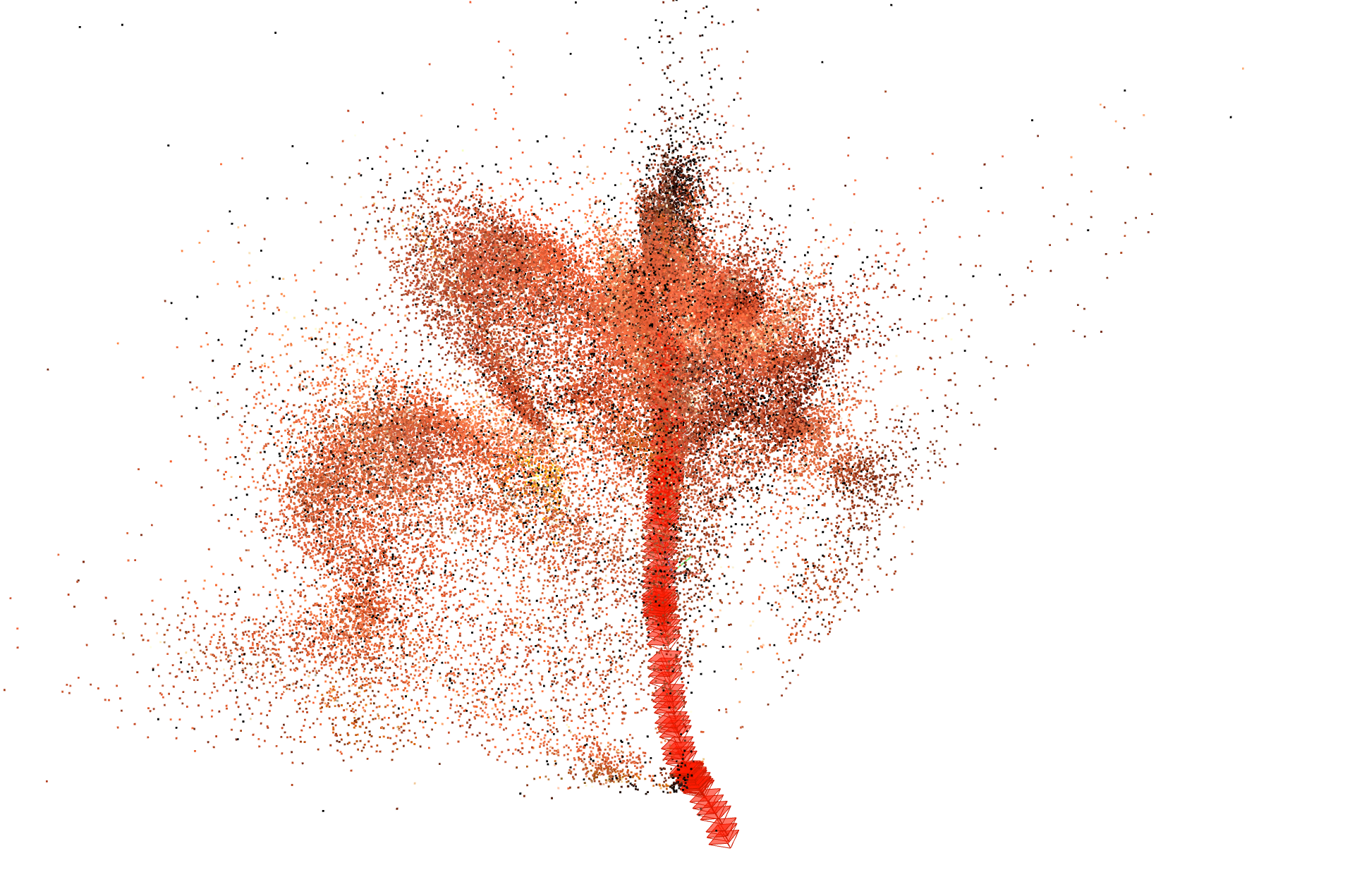




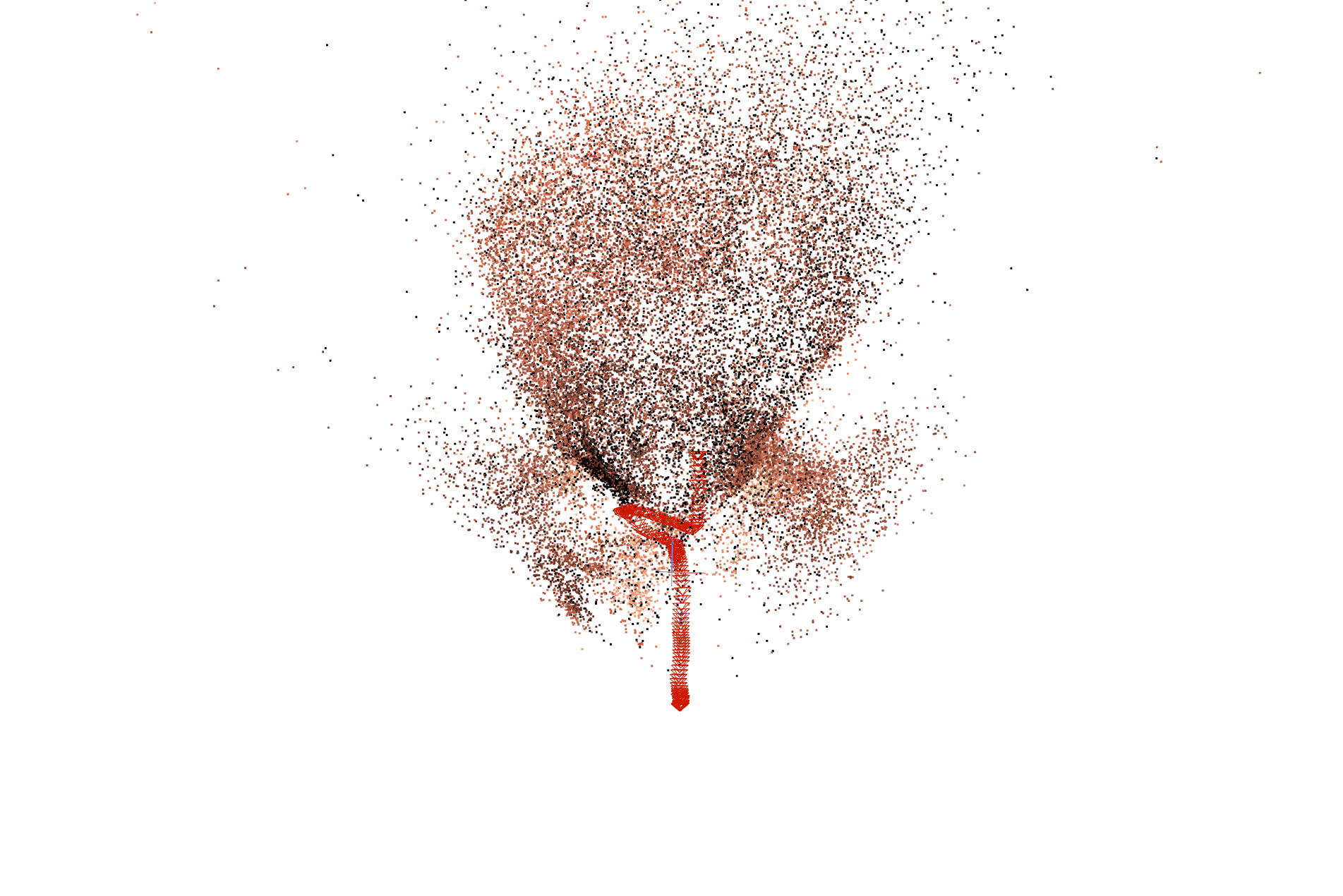




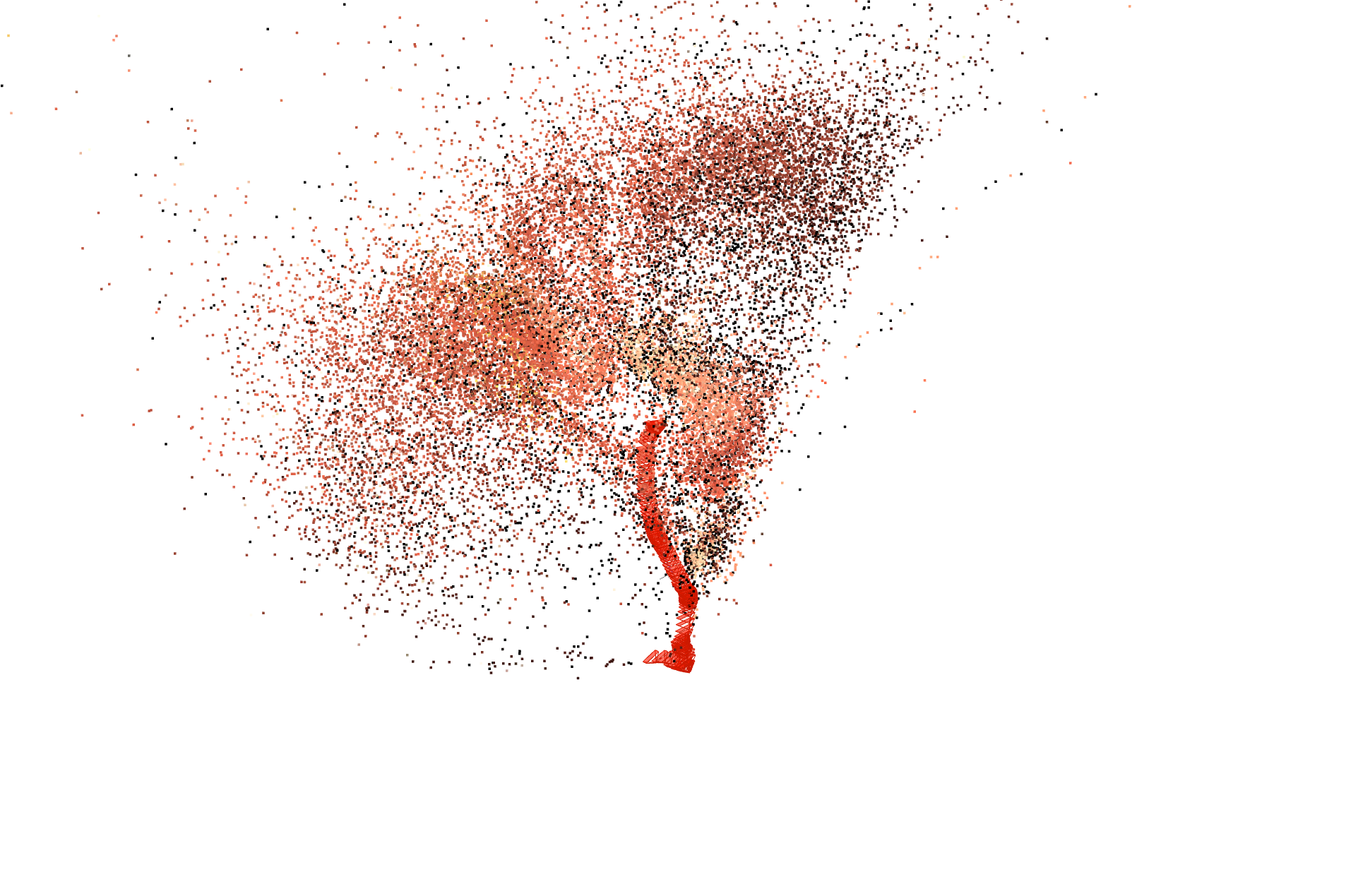
Figure 4: Comparisons of reconstructed point clouds and camera trajectories; SuperPoint-E reconstructions are markedly denser with more stable camera paths.
Coverage Across Long Sequences
On full-length colonoscopy videos, SuperPoint-E enables reconstruction of up to 33.2% of all frames compared to 15.1% for SIFT+GM, nearly doubling effective coverage. The method produces significantly larger contiguous submaps and a higher average per-model image count.










Figure 5: Visualization of reconstruction coverage over full sequences; SuperPoint-E yields notably greater and more continuous frame inclusion.
Domain Generalization
Transfer experiments to gastroscopy and bronchoscopy datasets show minimal performance degradation—even though SuperPoint-E is trained exclusively on colonoscopy data—demonstrating powerful domain adaptation properties. For instance, reconstructed 3D points in gastroscopy sequences increase by 5x over SIFT, with a drop in specular-associated keypoints to 4.5%.





Figure 6: Example reconstructions from bronchoscopy and gastroscopy data, evidencing successful domain generalization in complex anatomical environments.
Ablation and Efficiency
Comprehensive ablation over the source of supervision (SIFT only vs SIFT+SuperPoint), batch size N, and detector thresholds confirms that using multi-source supervision and moderate batch sizes optimizes descriptor quality. Furthermore, SuperPoint-E descriptors possess high enough discriminability to reduce dependence on costly guided matching, enabling practical downstream integration.
Implications and Future Directions
SuperPoint-E marks a significant step towards practical, dense 3D reconstruction in challenging endoscopic environments, providing features tailored to the domain's low-texture, non-Lambertian, and rapidly varying illumination characteristics. From a theoretical standpoint, the work underscores the value of higher-order temporal consistency for self-supervised representation learning in dynamic, real-world domains.
Practically, SuperPoint-E expands the viability of mapping and navigation for robotic and computer-assisted interventions, supporting mixed-reality overlays and automated spatial coverage assessments during routine procedures. The domain agnosticism observed in cross-modality experiments suggests that similar tracking-based adaptation mechanisms could be applied in other minimally-invasive visual domains with analogous constraints.
There is promising scope for further research in integrating SuperPoint-E with differentiable SLAM systems, multi-modal data (depth, polarization), or downstream surgical planning pipelines. The reduction of dependence on costly global geometrical verification (guided matching) also opens pathways for real-time deployment in resource-constrained settings.
Conclusion
SuperPoint-E introduces robust domain-adaptive local feature detection and description for endoscopic videos via a principled Tracking Adaptation training paradigm. Across diverse metrics and experimental setups, it consistently surpasses both classical and modern deep-learning baselines in enabling dense, stable, and discriminative 3D reconstructions. Its flexible supervision approach and practical performance characteristics suggest strong utility for both academic research and clinical applications in endoscopic vision.