- The paper presents a hierarchical framework that leverages global image retrieval and temporal matching for accurate 6D pose estimation across ambiguous environments.
- It integrates an environment-aware, self-supervised residual CNN to enhance degraded images, significantly improving keypoint detection and correspondence matching.
- Empirical results on underwater, Mars-analogue, and indoor benchmarks demonstrate substantial gains in localization accuracy compared to traditional methods.
6D Camera Relocalization in Visually Ambiguous Extreme Environments: A Technical Essay
This paper addresses 6-DoF camera relocalization under visually ambiguous extreme environments, including underwater and extraterrestrial scenes, which are characterized by low image quality, repetitive/ambiguous structures, and frequently degenerate appearance. Conventional methods—either direct regression models or feature/correspondence-based pipelines—demonstrate high accuracy in structured indoor scenes and common urban exteriors (e.g., Cambridge Landmarks, 7-Scenes), but their efficacy degrades sharply on ambiguous and degenerated data due to the inability to detect discriminative features or to retrieve covisible images reliably.


Figure 2: Typical scenes from Cambridge landmarks (left), contrasted with ambiguous and degraded samples from Aqualoc (underwater) and Mars-Analogue (extraterrestrial) environments (right).
The central challenge is twofold: (1) contamination from semantic ambiguity—overwhelming textureless or repetitive patterns; (2) severe image degradation (low illumination, blur, adverse medium effects), which fundamentally impairs feature extraction and robust image matching. The paper formalizes the need for an environment-robust, confidence-maximizing regressor of 6D pose, avoiding the multi-hypotheses and Bayesian strategies of recent work.
Hierarchical Temporal Localization Framework
The proposed method implements a hierarchical, correspondence-driven localization system, employing SuperPoint and SuperGlue for keypoint extraction and matching. The foundation is an offline Structure-from-Motion (SfM) reconstruction using training images to create a 3D database of points and image descriptors. At test time, localization proceeds in two main stages:
- Global Matching: Retrieval-based association of the query with database images using global descriptors, followed by keypoint-level 2D-3D correspondence extraction—suitable for scenes where discriminative matches can still occur.
- Temporal Matching: To overcome failed retrieval under ambiguity, temporal information is leveraged. Anchored frames (initially localized queries with sufficient correspondences) propagate correspondences recursively to their spatially-adjacent sequence frames, enabling robust pose bootstrapping even in repetitive or featureless regions. This yields a significant increase in successfully relocalized frames and supports iterative optimization.
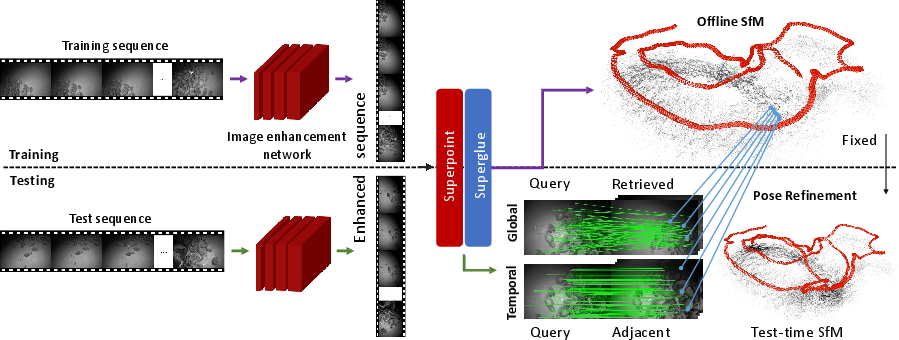
Figure 4: System overview—CNN-based environment-aware enhancement as a front-end, followed by hierarchical localization with both global and temporal matching stages and final pose/SfM refinement.
A final incremental SfM refinement updates the entire 3D structure as new frames are localized, integrating pose and structure estimation. This addresses drift and further disambiguates challenging sequences.
Environment-Aware Image Enhancement via Self-Supervised Residual CNN
Image degradation imposes a critical bottleneck for all downstream correspondence matching. The paper proposes a novel, lightweight, environment-aware image enhancement module, pre-pending the localization pipeline. This module is a CNN trained end-to-end in a self-supervised manner, optimizing a loss composed of:
- Keypoint Matching Assignment Loss: Encourages the enhanced output image to exhibit features better suited for reliable local feature detection and matching (measured via SuperPoint/SuperGlue).
- Smoothness Constraint: Mitigates overfitting to trivial pixel-level changes.
The enhancement model predicts a residual to the input, recovering a more viable latent image for feature extraction with no dependence on synthetic pairs, enabling transferability to real ambiguous environments.

Figure 6: The environment-aware image enhancement module learns to maximize discriminative keypoint matches through self-supervised residual prediction.
Ablation experiments show that this enhancement delivers substantial gains over mere fine-tuning of local feature networks (SuperPoint, SuperGlue), underscoring the crucial role of pre-processing as a domain adaptation mechanism.
Experimental Results: Extreme Environments
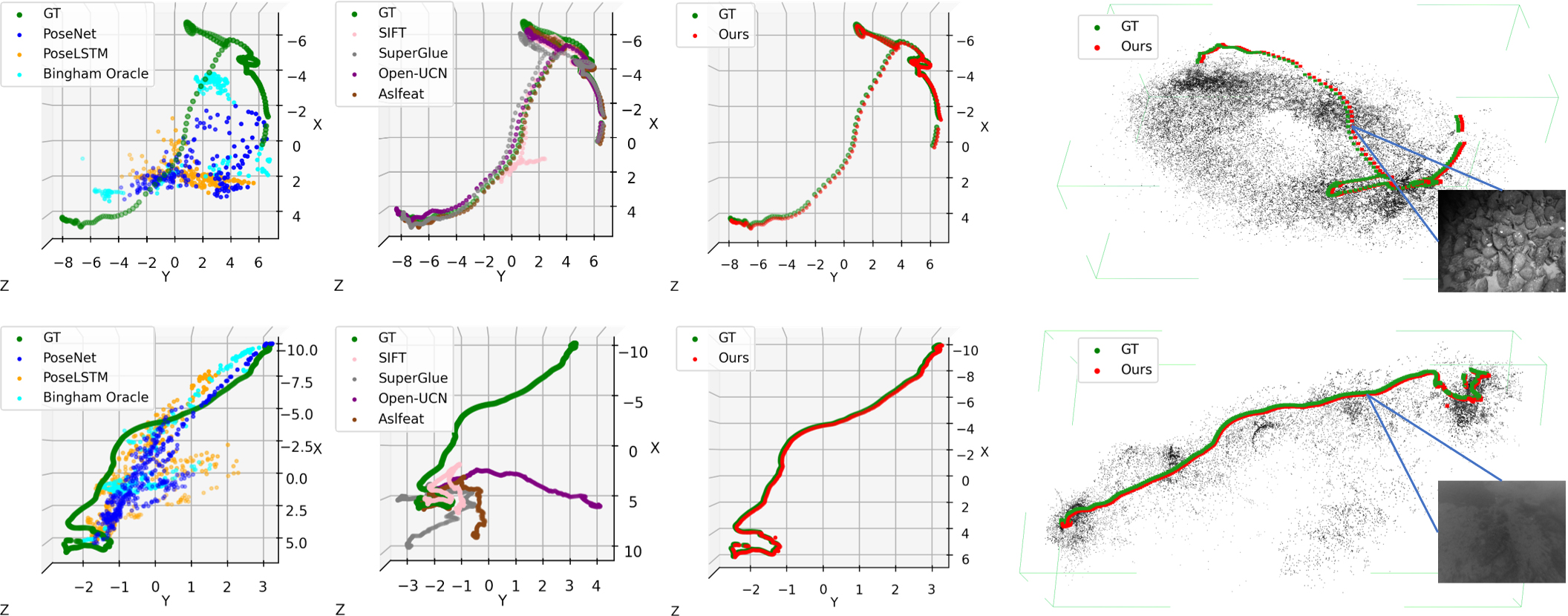
Extensive empirical analysis is carried out on the Aqualoc (underwater), Mars-Analogue (desert), and 7-Scenes (indoor) datasets. The system is benchmarked against direct regression methods (PoseNet, PoseLSTM, Bingham, etc.), spatial correspondence pipelines (DSAC++, ESAC, HF-Net, PixLoc), and both classical and learned feature descriptors (SIFT, SURF, Open-UCN, ASLFeat, SuperGlue).
On the most challenging underwater and Mars-Analogue datasets, standard methods—including recent multi-modal and Bayesian relocalization strategies—exhibit extreme failure rates or gross pose errors, particularly where global retrieval is infeasible and visual odometry cannot be reliably chained. State-of-the-art direct regressors and even COLMAP are unable to generalize across all ambiguous settings; in Aqualoc, COLMAP fails on 4 out of 10 sequences.
Quantitatively, the proposed method achieves:
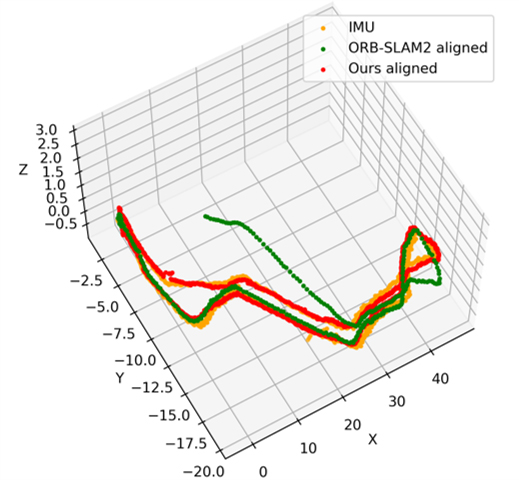
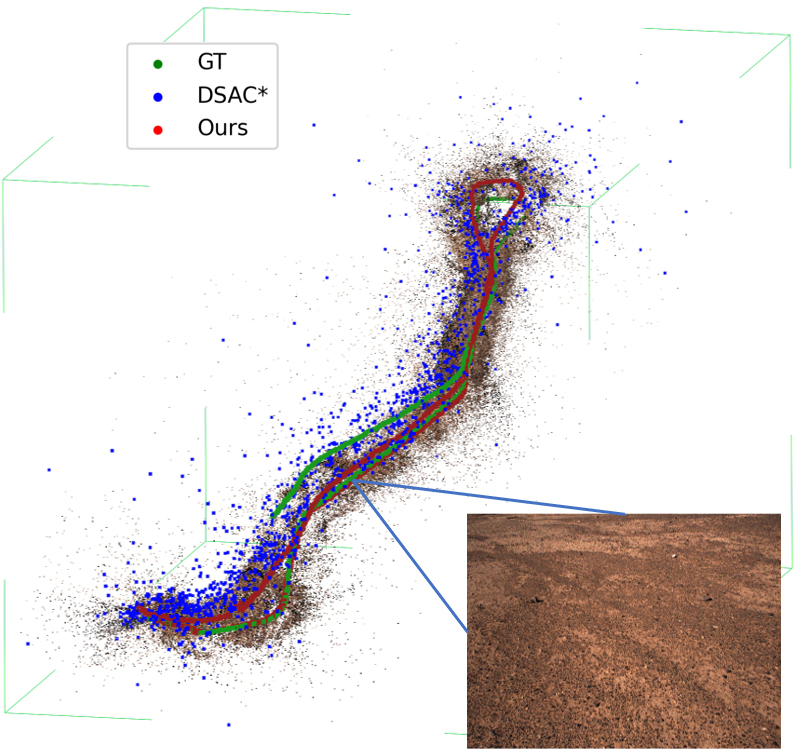
Figure 3: On Mars-Analogue data, the reconstructed 3D trajectory by the proposed pipeline is sharply aligned with ground truth, whereas ORB-SLAM2 and other approaches exhibit significant errors or drift.
The enhancement module delivers visible improvements in image quality and keypoint coverage, directly translating to increased correspondence counts in the downstream SfM and localization accuracy, as visualized.


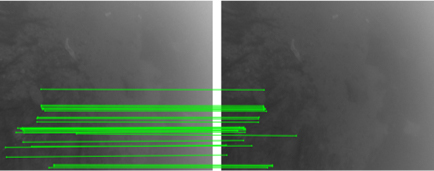
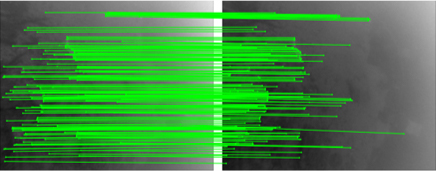
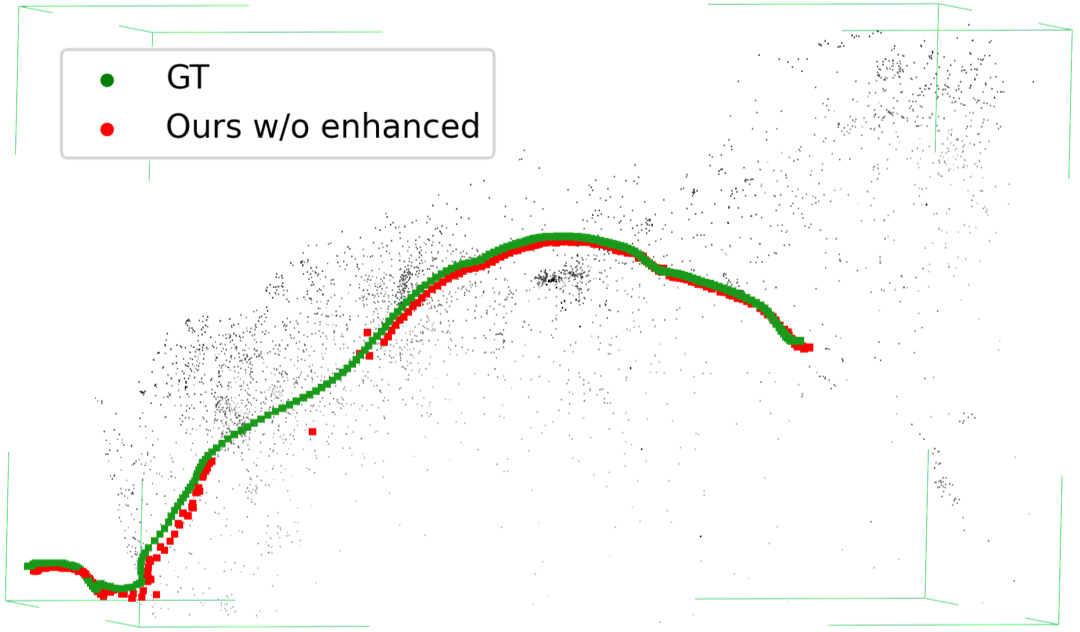
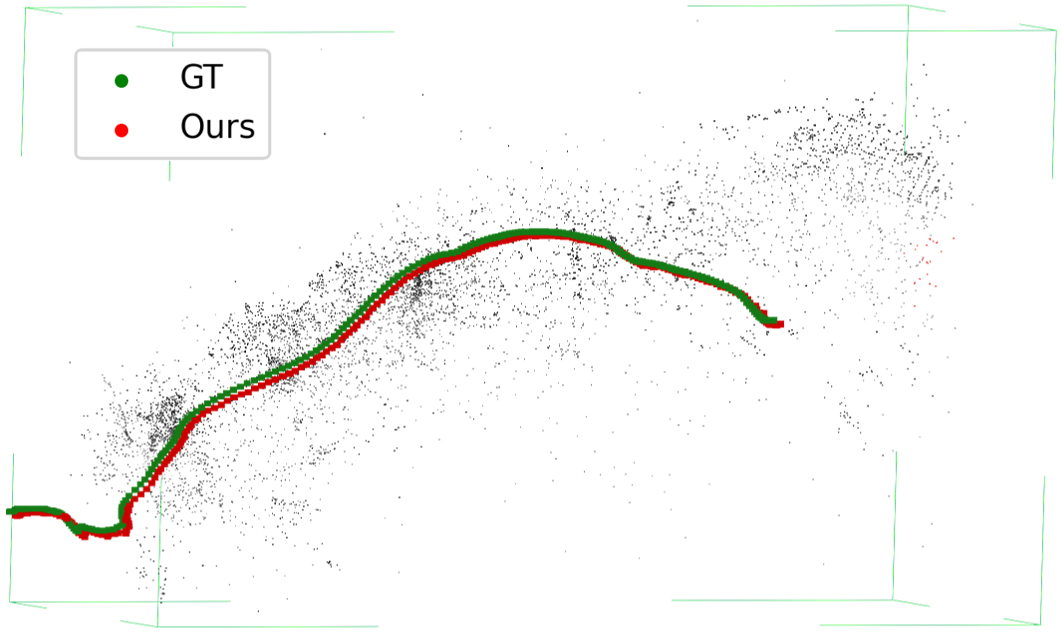
Figure 5: Sequential effect of enhancement—clearer images (top), high-quality keypoint matches (middle), denser and more accurate trajectories (bottom).
Robustness on Standard and Data-Scarce Settings
On the standard 7-Scenes indoor benchmark, the system approaches the performance of state-of-the-art correspondence-based methods, despite using only 20% (and even 5%) of the training data. This validates the system’s data efficiency in less ambiguous settings and the general applicability of the pipeline.


Figure 7: On the 7-Scenes Chess sequence, the pipeline achieves strong accuracy with only 5% of the training data.
Ablation and Limitations
Ablations reveal that both the temporal enhancement scheme and the pose refinement module are required for optimal results. Fine-tuning feature networks alone yields inferior accuracy compared with explicit image enhancement. Feature selection experiments indicate SuperPoint+SuperGlue outperform other descriptors post-enhancement.
However, reconstruction-dependent limitations persist: inaccuracies in SfM or calibration can propagate to pose estimation. In highly cluttered scenes with noisy 3D point clouds or insufficient geometric structure, small residual pose losses remain unavoidable.
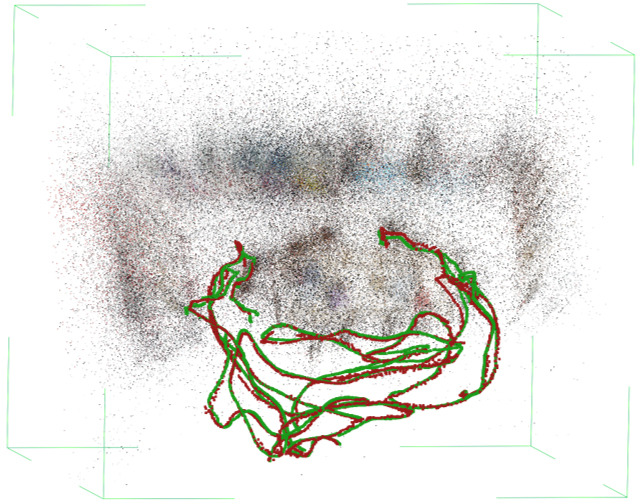

Figure 8: Example of imperfect reconstruction in fine-grained (Kitchen) scenes—noise in SfM and camera intrinsics results in minor localization errors.
Implications and Prospects
The main theoretical contribution lies in demonstrating the efficacy of harnessing temporal redundancy and correspondence bootstrapping under ambiguity, which is overlooked in existing pipelines. Practically, the enhancement+temporal pipeline provides robust relocalization in domains—deep-sea, extraterrestrial, other adverse environments—where alternative sensor modalities cannot be relied upon, creating an avenue for real-world robot deployment.
Future work should focus on parallelized keypoint matching for real-time application, and integration of robust, domain-agnostic SfM modules with active self-calibration. The paradigm set by this work will be crucial for advancing vision-based navigation for autonomous exploration and mapping in unconstrained, visually challenging environments.
Conclusion
This paper systematically characterizes the failure modes of contemporary visual relocalization models in ambiguous extreme environments and presents a robust, empirical solution based on temporal correspondence expansion and self-supervised image enhancement. Extensive experiments validate significant outperformance versus baselines in the most challenging visual domains while preserving or surpassing state-of-the-art generalization. The methodology is directly applicable to sub-sea robotics, planetary rovers, and any context with degenerate or ambiguous visual input, setting a new benchmark for extreme-environment localization (2207.06333).