Learning to Reason in 13 Parameters
Abstract: Recent research has shown that LLMs can learn to \textit{reason}, often via reinforcement learning. Some work even trains low-rank parameterizations for reasoning, but conventional LoRA cannot scale below the model dimension. We question whether even rank=1 LoRA is necessary for learning to reason and propose TinyLoRA, a method for scaling low-rank adapters to sizes as small as one parameter. Within our new parameterization, we are able to train the 8B parameter size of Qwen2.5 to 91\% accuracy on GSM8K with only 13 trained parameters in bf16 (26 total bytes). We find this trend holds in general: we are able to recover 90\% of performance improvements while training $1000x$ fewer parameters across a suite of more difficult learning-to-reason benchmarks such as AIME, AMC, and MATH500. Notably, we are only able to achieve such strong performance with RL: models trained using SFT require $100-1000x$ larger updates to reach the same performance.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in plain language)
This paper asks a surprising question: can we teach a big AI model to “think through” math problems by tweaking only a handful of its settings—like turning just a few tiny knobs—instead of changing millions or billions of settings?
The authors introduce a tiny add‑on called TinyLoRA that can change how a LLM reasons while training as few as 1–13 parameters (settings). With only 13 trained parameters—about 26 bytes, smaller than a short text message—they push a 7–8 billion parameter model to around 91% accuracy on a popular math benchmark (GSM8K). They also show this works on harder tests and that it works best when the model learns by getting “rewards” (reinforcement learning), not by copying answers (supervised finetuning).
What questions were they trying to answer?
- How small can model updates be while still improving “reasoning” (especially in math)?
- Is reinforcement learning (getting reward signals) better than supervised finetuning (learning from example answers) when the update is tiny?
- Can a new method, TinyLoRA, shrink the usual “adapter” updates from millions of parameters down to just a few—or even one—without losing much performance?
How they did it (with simple analogies)
Think of a huge robot with billions of dials (parameters). Changing all of them is heavy and slow. So people use “adapters” (small add‑ons) that adjust only a few important dials to teach new skills.
- LoRA: A common adapter that adds a small, targeted change to certain parts of the model. It’s much smaller than full retraining, but still often needs millions of parameters.
- TinyLoRA: The authors’ new adapter that’s much, much tinier. Imagine one shared “slider” that subtly nudges many parts of the robot at once in carefully chosen directions.
How does TinyLoRA stay so small?
- It finds the most important directions in each model layer beforehand (you can think of these as the main “axes” along which a layer most strongly reacts).
- It then uses a tiny trainable vector (just a few numbers) to mix these directions in a consistent way across many layers—like one slider controlling many similar parts.
- By sharing this tiny vector across modules and layers, the total number of new trainable settings can drop to just a handful.
How does the learning work?
- Reinforcement Learning (RL): Like practicing a game—try an answer, get a reward if it’s right, and adjust the tiny knobs to get more rewards next time. The paper mainly uses a method called GRPO (a policy‑gradient style RL). The reward is simple: 1 if the final answer is correct, 0 if not.
- Supervised Finetuning (SFT): Like copying a teacher’s full solution line‑by‑line. This can require the model to memorize lots of extra details, which is hard to cram into a tiny set of knobs.
Benchmarks and models:
- They test on math reasoning datasets: GSM8K (grade‑school word problems), plus harder sets like MATH500, AIME, and AMC.
- They use large instruction‑tuned models (e.g., Qwen2.5‑7B/8B), and compare TinyLoRA with standard LoRA and a smaller variant called LoRA‑XS.
What they found and why it matters
Main results (in simple terms):
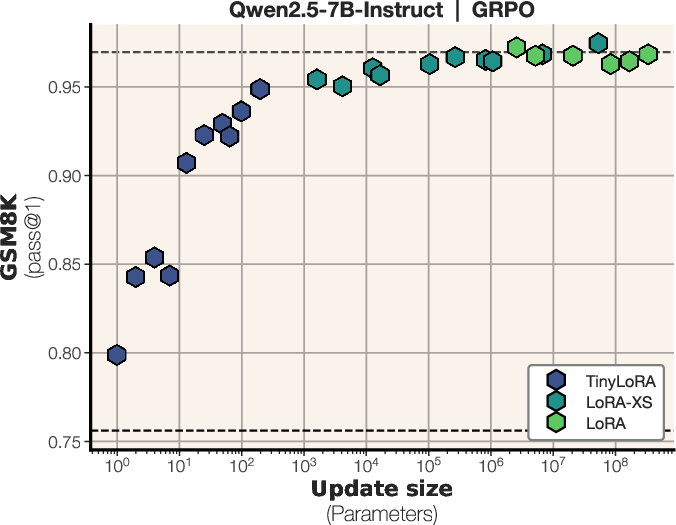
- Tiny updates can work shockingly well with RL:
- On GSM8K, training only 13 parameters (≈26 bytes) got about 91% accuracy—close to full finetuning.
- With under 100 trained parameters, RL reached about 90%+, while SFT with the same tiny size barely improved.
- This trend holds on tougher tests:
- On a suite of harder math benchmarks (like AIME, AMC, MATH500), training as few as ~196 parameters kept roughly 87–90% of the performance gains you’d get from much larger updates.
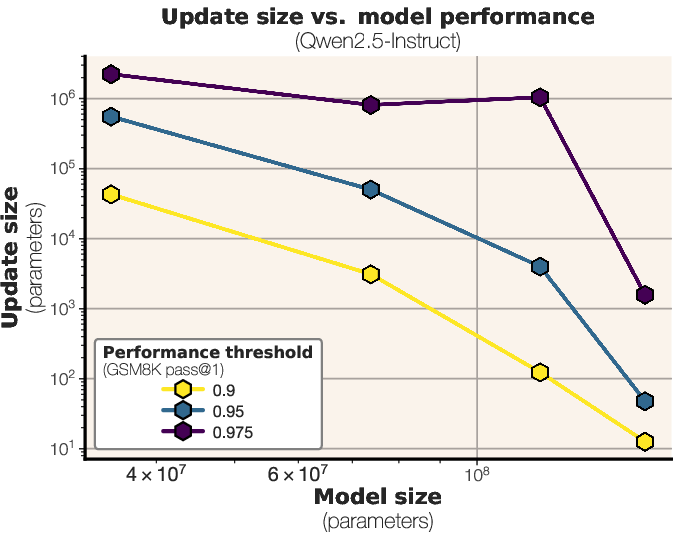
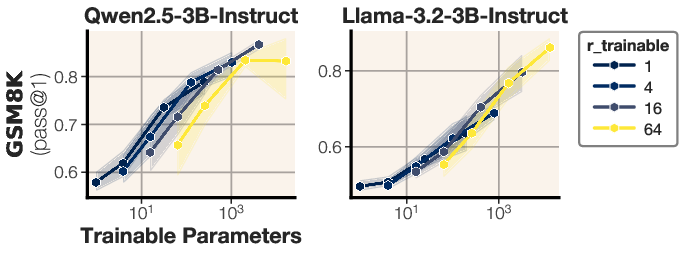
- Bigger base models need even smaller updates:
- As the base model gets larger, you can “steer” it effectively with fewer parameters. In other words, the bigger the model, the easier it is to nudge it toward good reasoning with tiny tweaks.
- RL beats SFT in the tiny‑update regime:
- RL gives a clean “signal” (right/wrong reward), so the model only stores what helps it win.
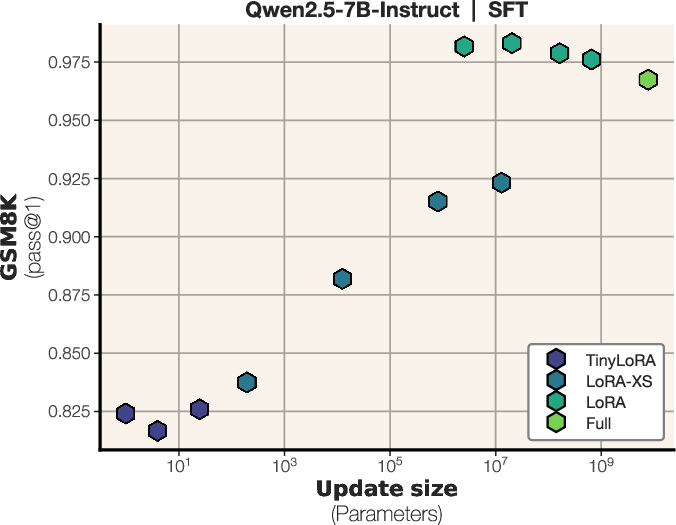
- SFT tries to mimic full solutions, mixing important and unimportant details, which takes more capacity—so it needs 100–1000× larger updates to match RL performance at this scale.
Why this is important:
- Speed and memory: Training and serving adapters that are just a few bytes or kilobytes is far cheaper and faster.
- Personalization at scale: You can store and swap many tiny adapters on one machine, letting many users have custom skills without needing separate big models.
- Fewer side effects: Small updates tend to change less of the model, which can reduce forgetting or breaking other abilities.
What this could mean going forward
- Big models may be “pre‑loaded” with lots of know‑how. Tiny updates might just teach them how to “show their work” better—like encouraging longer, more careful solutions—rather than teaching brand‑new knowledge.
- If this scales, organizations could cheaply tailor large models to many tasks with almost no extra storage.
- Caveats:
- These results are focused on math reasoning. It’s not yet clear if the same tiny‑update success holds for other areas (science writing, coding beyond math, creative tasks).
- Some model families reacted better than others (e.g., Qwen2.5 often improved more than LLaMA at very small sizes), so results may depend on the base model and its training.
In short: The paper shows that with a clever tiny adapter (TinyLoRA) and the right kind of learning (reinforcement learning with rewards), LLMs can learn to reason better by changing only a handful of parameters—sometimes as few as one—saving time, memory, and cost while keeping most of the performance gains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address.
- Formal characterization of the “information-dense” RL updates hypothesis: rigorously quantify and compare the information content absorbed by SFT vs RL (e.g., mutual information between parameter updates and rewards, intrinsic dimensionality of the learned update subspace, or MDL-based measures), rather than relying on qualitative arguments.
- End-to-end storage accounting for TinyLoRA adapters: the reported “26 bytes” counts only trainable parameters; clarify and measure total storage needed at inference, including per-module truncated SVD caches (U, Σ, V), the random projection tensor P (or its seed), metadata for weight tying, and any runtime buffers; provide a standardized “adapter byte-budget” that covers all components.
- Serving-time compute and latency: quantify the inference overhead of reconstructing updates from U, Σ, V and P compared to standard LoRA (kernel support exists) and full fine-tuning; report throughput, latency, and memory impact in multi-tenant scenarios where hundreds of TinyLoRAs are hosted concurrently.
- Implementation-induced bias: the vLLM rank≥4 constraint was sidestepped by merging weights and correcting with truncated importance sampling; perform a controlled comparison against a native low-rank kernel implementation to test for bias, variance, and stability differences in training and evaluation.
- Generalization beyond math: test TinyLoRA on diverse reasoning domains (coding, science QA, planning, instruction following, multilingual benchmarks) to assess whether extreme parameter efficiency is unique to math/verifiable reward settings.
- RL algorithm dependence: evaluate TinyLoRA under multiple RL post-training paradigms (e.g., PPO variants, on-policy distillation, DPO/RPO, reward models vs purely verifiable rewards, varying KL controls) to isolate which elements are critical in the tiny-update regime.
- Reward design and robustness: move beyond exact-match rewards to partial credit, verifier quality/robustness, length penalties, and hallucination penalties; analyze how reward shaping impacts learning with tens of parameters.
- Stability and variance in tiny regimes: report training stability, failure modes, and confidence intervals across seeds; conduct sensitivity analysis for learning rates, temperatures, batch sizes, generations-per-prompt, and exploration strategies at ≤100 parameters.
- Scaling law validation: the trend “larger backbones need smaller updates” was shown for Qwen2.5/LLama3; validate across more families (e.g., Mistral, Gemma, Phi), sizes (from sub-1B to >70B), and architectures (MoE) to assess universality; propose a predictive scaling law with error bars.
- Module-level attribution: systematically identify which modules (Q/K/V/O, MLP up/down/gate) contribute most under extreme tying; explain why “tiling” outperforms structured sharing; test hybrid sharing strategies and per-layer/per-block tying to optimize tiny adapters.
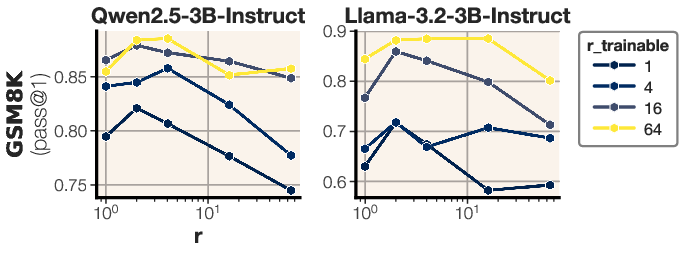
- Choice of frozen rank r and projection P: go beyond random fixed P—compare learned projections, per-module P, orthogonal or structured P, and different r values; study optimization landscapes and conditioning to explain why higher frozen ranks degraded performance in ablations.
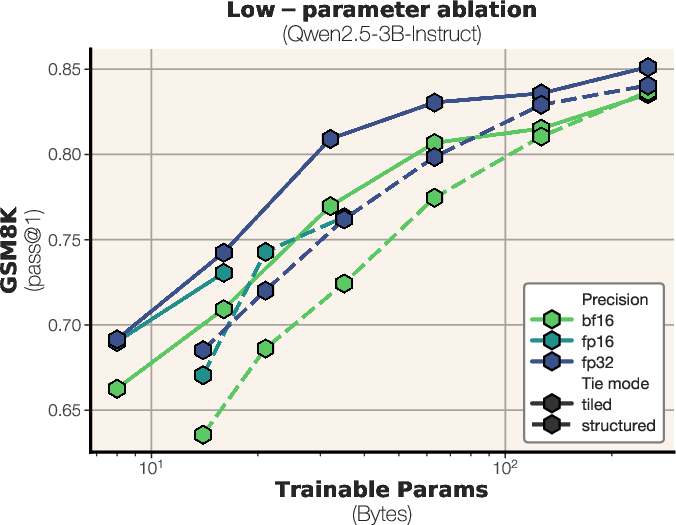
- Precision and quantization: investigate why fp32 outperforms bf16/fp16 “bit-for-bit”; explore 8-bit/4-bit adapters, quantization-aware training, stochastic rounding, and error-compensated communication in the byte-constrained regime.
- Data leakage and memorization: quantify potential pretraining exposure (especially for Qwen) and its influence on tiny-update success; perform strict deduplication and OOD tests to separate genuine reasoning improvements from memorization; evaluate with contamination-aware splits.
- Forgetting and multi-task retention: measure performance on unrelated capabilities post-RL TinyLoRA (e.g., general chat, factual QA) versus SFT, including long-term retention and catastrophic forgetting assessments.
- Chain-of-thought mechanics: directly test whether tiny updates primarily modulate response length/format vs deeper reasoning steps; instrument CoT step counts, intermediate correctness, and causal interventions to establish mechanisms of improvement.
- Comparative baselines: include empirical comparisons against other PEFT methods designed for tiny budgets (e.g., VeRA, VB-LoRA, UniLoRA, NoRA, AdaLoRA, ShareLoRA) under identical RL and SFT settings, especially below 10K parameters.
- Cost-effectiveness: report wall-clock, GPU-hours, and token-generation costs for RL vs SFT at matched accuracy gains; provide compute/accuracy Pareto curves to substantiate “RL is more efficient” claims in practice.
- Byte-budget communication: study lossy/lossless compression, delta coding, and seed-only transmission strategies for federated/distributed training of TinyLoRA; quantify accuracy degradation under realistic communication constraints.
- Reproducibility and release: provide full code, configs, seeds, and evaluation scripts (including vLLM/VERL modifications) to replicate the low-rank kernel workaround; publish per-dataset ablation tables and CI-based reproducibility checks.
- Safety, alignment, and calibration: evaluate side effects of RL with verifiable rewards on toxicity, sycophancy, calibration, and robustness to adversarial prompts; assess whether tiny updates exacerbate or mitigate safety risks.
- Transfer and composition: test if a 13-parameter GSM8K adapter transfers to other math datasets and whether multiple tiny adapters can be composed (e.g., task-specific stacking) without interference; analyze adapter interference and routing strategies.
Practical Applications
Practical Applications Derived from the Paper
Below we group actionable, real-world applications that emerge from the paper’s findings and methods—especially TinyLoRA, extreme parameter-efficient RL-based post-training, and adapter sharing—into immediate and long-term opportunities.
Immediate Applications
- Personalization at scale via multi-tenant adapter serving (software/enterprise)
- Deploy thousands of TinyLoRA adapters per model instance to tailor reasoning style and workflows per customer, team, or task with negligible memory overhead.
- Potential tools: Adapter orchestration service; per-tenant “Reasoning Profiles.”
- Assumptions/dependencies: Access to a strong base model (≥7B); verifiable reward signals; inference stack supporting adapter swapping (e.g., vLLM/Punica-like serving).
- Cost-efficient RL post-training for math and code reasoning (software/education)
- Use GRPO with verifiable rewards (exact-match for math, unit-test pass rates for code) to boost performance using 10–10,000 trainable parameters instead of millions/billions.
- Potential tools: “AutoRL Reasoning Booster” that runs small RL jobs to produce micro-adapters for math/coding tasks.
- Assumptions/dependencies: High-quality, programmatic reward functions; sufficient base model competency; RL pipeline (e.g., VERL).
- On-device or low-bandwidth adaptation with micro-updates (mobile/IoT/privacy)
- Ship or learn TinyLoRA adapters locally (tens to hundreds of bytes) to customize reasoning without moving large weights; ideal for privacy-preserving, bandwidth-constrained settings.
- Potential tools: Edge RL kit for mobile; adapter packaging and secure delivery.
- Assumptions/dependencies: Quantized base models that fit on-device; task rewards measurable locally; safe update policies.
- Federated RL with tiny parameter exchanges (software/healthcare/finance)
- Clients compute RL updates from local data and send only micro-adapters upstream, drastically reducing communication costs and privacy risk.
- Potential tools: Federated RL aggregator for TinyLoRA; secure adapter signing/verification.
- Assumptions/dependencies: Programmatically verifiable rewards; secure aggregation; compliance considerations for regulated data.
- Safety/compliance “micro-patches” (policy/enterprise governance)
- Encode safety rules, regulatory constraints, or formatting requirements as reward functions; deploy TinyLoRA adapters that enforce policy without retraining the base model.
- Potential tools: Compliance Patch Studio; Policy-to-Reward compiler.
- Assumptions/dependencies: Clear, machine-verifiable compliance criteria; robust evaluation to avoid reward hacking; governance for patch lifecycle.
- Reduced-forgetting task overlays (software/MLOps)
- Maintain multiple low-rank reasoning adapters to avoid overwriting base capabilities; switch per task domain (e.g., math vs. code vs. chat).
- Potential tools: AdapterOps for task routing and A/B testing; adapter versioning/rollbacks.
- Assumptions/dependencies: Routing/gating logic; monitoring for drift and interference.
- Education: adaptive math tutors (education)
- Personalize problem difficulty and reasoning style for a student by training micro-adapters from verifiable outcomes (correct steps, boxed answers).
- Potential tools: Per-student Reasoning Profile adapters; analytics dashboards showing learning gains.
- Assumptions/dependencies: Accurate math verifiers; base model math capability; pedagogical oversight.
- Developer productivity: test-driven code assistants (software)
- Use unit-test pass/fail as a reward to tune micro-adapters that improve structured reasoning, debugging, and step-by-step planning in code generation.
- Potential tools: CI-integrated RL booster generating adapters per repo/service.
- Assumptions/dependencies: Reliable test suites; safeguards against overfitting to tests; base model coding proficiency.
- Research acceleration in PEFT and RL for LLMs (academia)
- Reproduce and extend RL-vs-SFT comparisons, intrinsic dimensionality studies, and ablations with TinyLoRA; rapidly prototype adapters using merged-weight inference and truncated importance sampling as in the paper.
- Potential tools: Open TinyLoRA library; standardized reward/eval packs (GSM8K, MATH, coding tests).
- Assumptions/dependencies: Access to compute; large base models; stable RL tooling.
Long-Term Applications
- Cross-domain verifiable reasoning beyond math (healthcare, law, science, finance)
- Create robust, programmatic reward functions (checkers) for clinical guideline adherence, contract consistency, scientific derivations, and financial calculations; train micro-adapters to elevate reasoning while retaining base knowledge.
- Potential tools: Domain-specific verifier libraries; evidence-tracing outputs; audit trails for patches.
- Assumptions/dependencies: High-quality, trusted verifiers; rigorous validation and regulatory approval in sensitive domains.
- Trillion-scale model governance with micro-controls (enterprise/ML governance)
- Steer massive foundation models using handful-of-parameter patches for tasks, regions, or compliance regimes; audit/rollback adapters as policy instruments.
- Potential tools: Global Patch Manager; adapter signing and provenance; risk dashboards.
- Assumptions/dependencies: Ultra-large base models; strong MLOps and auditability; policy change management.
- Adapter marketplaces and standards (software/platforms)
- Distribute certified micro-adapters for tasks (e.g., “AMC Math Patch,” “Python Debugging Patch”) with metadata (domain, reward design, eval scores).
- Potential tools: Adapter registry/storefront; compatibility and safety standards; licensure and IP frameworks.
- Assumptions/dependencies: Interoperability standards; vetting pipelines; legal frameworks for patch IP and responsibility.
- Edge autonomy in robotics and industrial systems (robotics/energy/manufacturing)
- Language-guided planning and verification (task completion, safety checks) trained as TinyLoRA updates on-device; adapt quickly to new tasks with minimal comms.
- Potential tools: Onboard verifiers (sensor-based checkers); micro-adapter deployment pipelines; local reinforcement signals.
- Assumptions/dependencies: Reliable success signals; adequate compute on edge; safety certification.
- Healthcare decision support with localized adapters (healthcare)
- Hospitals maintain site-specific adapters encoding local formularies, protocols, and documentation norms; adapters enforce guideline-adherent reasoning.
- Potential tools: Clinical Reasoning Patch Hub; governance workflows; continuous monitoring.
- Assumptions/dependencies: Clinical validation; robust medico-legal compliance; integration with EHR systems.
- Multi-organization federated RL consortia (policy/academia/industry)
- Collaboratively improve reasoning using federated micro-updates across institutions (schools, hospitals, labs), sharing only bytes-level patches and unified reward specs.
- Potential tools: Secure federated broker; reward alignment councils; shared benchmarks.
- Assumptions/dependencies: Secure aggregation; harmonized reward definitions; governance agreements.
- Ultra-scale personalization: millions of adapters per cluster (software/cloud)
- Host and hot-swap massive numbers of micro-adapters for specific users, tasks, or contexts; dynamic routing based on signals (query type, compliance needs).
- Potential tools: High-density adapter KV stores; low-latency router; cache-aware serving.
- Assumptions/dependencies: Efficient adapter memory formats; routing heuristics; SLA guarantees.
- Continuous, self-improving assistants on-device (daily life/mobile)
- Use user feedback and verifiable outcomes (calendar constraints satisfied, budget kept, tasks completed) as rewards for incremental TinyLoRA updates, preserving privacy.
- Potential tools: Local reward mappers; safety filters; rollbacks and “restore baseline” controls.
- Assumptions/dependencies: Reliable mapping from feedback to rewards; protections against drift and unsafe adaptations.
- Theory-driven training protocols and information-efficiency (academia)
- Formalize and exploit RL’s signal-to-noise separation properties to design new objectives and architectures optimized for tiny update regimes; extend MDL analyses for LLM RL.
- Potential tools: Benchmark suites that measure performance vs. update size; analyzer tools for update sparsity/density.
- Assumptions/dependencies: Sustained research funding; access to diverse domains and verifiers.
- Low-bandwidth humanitarian and educational deployments (policy/NGOs)
- Distribute strong base models once and periodically push micro-adapters for curricula, languages, or local constraints without heavy network requirements.
- Potential tools: Offline adapter bundles; community-led reward design (curriculum checkers).
- Assumptions/dependencies: Base model availability in target regions; local validation; cultural/linguistic tailoring.
Glossary
- AdaLoRA: A LoRA variant that adaptively allocates low-rank budget across layers to improve parameter efficiency. "AdaLoRA"
- adapter: A small trainable module added to a frozen model to adapt it to a task with few additional parameters. "the size of an adapter allows"
- backbone model: The underlying pretrained network that adapters or fine-tuning modify. "backbone model size."
- bf16: The bfloat16 numerical format (16-bit float with wider exponent) commonly used for efficient training. "in bf16 (26 total bytes)."
- bit-constrained regime: A setting where the total update size in bytes (not just parameter count) is constrained. "Scaling in the bit-constrained regime"
- boxed chat template: A specific prompt/response formatting style used during training/evaluation. "use the `boxed' chat template."
- exact-match reward: A binary reward signal that gives credit only when the model’s answer exactly matches the reference. "All our RL experiments use exact-match reward."
- float16: A 16-bit floating-point numerical format used to reduce memory and bandwidth. "float16 precision"
- fp32: A 32-bit floating-point numerical format; higher precision but larger size. "fp32 is most performant bit-for-bit."
- frozen SVD rank r: The number of singular components kept fixed in TinyLoRA’s truncated SVD decomposition. "sweeping over the frozen SVD rank "
- gate projection: The MLP linear projection that controls gating in transformer blocks. "gate projections in the MLP."
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm used for post-training LLMs. "in particular Group Relative Policy Optimization (GRPO)"
- instruction-tuned: Refers to models further trained on instruction–response data to improve following user prompts. "instruction-tuned LLMs"
- intrinsic dimension: The effective low-dimensional manifold on which high-dimensional model solutions tend to lie. "manifold of a low intrinsic dimension"
- KL coefficient: The scalar weight applied to the KL penalty in RL objectives to control policy deviation. "KL coefficient $0.001$"
- KL divergence: A measure of divergence between two probability distributions, used to monitor train–inference mismatch. "the KL divergence between the log probabilities"
- KL penalty: A regularization term penalizing deviation from a reference policy during RL post-training. "we do not use any KL penalty"
- LoRA: Low-Rank Adaptation; adds low-rank updates to frozen weights for parameter-efficient fine-tuning. "Low-Rank Adaptation (LoRA)"
- LoRA Drop: A method that drops or prunes parts of LoRA parameters for efficiency/robustness. "LoRA Drop"
- LoRA-XS: A LoRA variant that uses truncated SVD bases and learns a tiny recombination matrix to minimize parameters. "LoRA-XS"
- Minimum description length: An information-theoretic measure of how concisely data can be encoded under a model. "minimum description length of under the model"
- NoRA: Nested Low-Rank Adaptation; a structured way of composing low-rank adapters. "NoRA"
- numerical mismatch: The discrepancy that arises when training and inference use different numerical paths or merges. "This creates a natural numerical mismatch between training and inference"
- off-policy learning: Learning from data generated by a policy different from the one being optimized. "a version of off-policy learning"
- Pareto frontier: The trade-off curve showing optimal performance for each update-size budget. "the pareto frontier between update size and performance"
- policy gradient: A class of RL methods that estimate gradients of expected returns w.r.t. policy parameters. "policy gradient:"
- projection dimension (u): The size of the trainable vector in TinyLoRA that is projected to form per-module updates. "trainable projection dimension "
- query/key/value projections: The linear projections used inside self-attention to form Q, K, and V vectors. "the query, key, value, and output projections in self-attention"
- rank (LoRA rank): The dimensionality of the low-rank adapter; lower rank means fewer parameters. "running LoRA at its smallest setting (rank 1)"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL where rewards are based on verifiable outcomes (e.g., correct answers). "reinforcement learning with verifiable rewards (RLVR)"
- self-attention: The mechanism allowing tokens to attend to other tokens in the same sequence. "in self-attention"
- ShareLoRA: A method that shares LoRA parameters across modules or layers to reduce total parameters. "ShareLoRA"
- SFT (Supervised finetuning): Fine-tuning via next-token prediction on labeled demonstrations. "SFT works best with larger update sizes of at least $1M$ parameters."
- structured parameter sharing: Sharing parameters among modules of the same type in a structured way. "structured, where nearby modules of the same type share parameters"
- TinyLoRA: The paper’s method that scales LoRA-style adapters down to as few as one trainable parameter. "We propose TinyLoRA, a method for scaling low-rank adapters to sizes as small as one parameter."
- Truncated importance sampling: An off-policy correction technique that caps importance weights to reduce variance. "truncated importance sampling"
- Truncated SVD: A low-rank approximation of a matrix using its top singular components. "truncated SVD of "
- UniLoRA: A LoRA-style method emphasizing minimal parameterization (e.g., one vector). "UniLoRA"
- VeRA: Vector-based Random Matrix Adaptation; a parameter-efficient adaptation approach. "VeRA"
- VERL: An open-source framework for RLHF-style post-training of LLMs. "within the open-source VERL framework"
- vLLM: A high-throughput inference engine for LLMs. "using vLLM for inference."
- WeightLoRA: A variant that performs LoRA-style updates directly in weight space. "WeightLoRA"
- weight merging: Combining adapter updates into the base weights for efficient inference. "merging the LoRA weights at each training step"
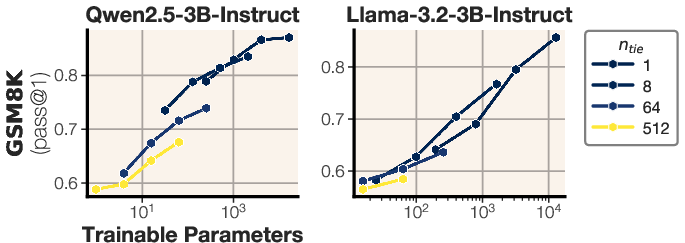
- weight tying: Sharing the same trainable parameters across multiple modules to cut parameter count. "With weight tying across modules"
- tiled parameter sharing: Sharing parameters across modules at similar depths irrespective of type. "tiled, where nearby modules of similar depth share parameters"
Collections
Sign up for free to add this paper to one or more collections.