S-MUSt3R: Sliding Multi-view 3D Reconstruction
Abstract: The recent paradigm shift in 3D vision led to the rise of foundation models with remarkable capabilities in 3D perception from uncalibrated images. However, extending these models to large-scale RGB stream 3D reconstruction remains challenging due to memory limitations. This work proposes S-MUSt3R, a simple and efficient pipeline that extends the limits of foundation models for monocular 3D reconstruction. Our approach addresses the scalability bottleneck of foundation models through a simple strategy of sequence segmentation followed by segment alignment and lightweight loop closure optimization. Without model retraining, we benefit from remarkable 3D reconstruction capacities of MUSt3R model and achieve trajectory and reconstruction performance comparable to traditional methods with more complex architecture. We evaluate S-MUSt3R on TUM, 7-Scenes and proprietary robot navigation datasets and show that S-MUSt3R runs successfully on long RGB sequences and produces accurate and consistent 3D reconstruction. Our results highlight the potential of leveraging the MUSt3R model for scalable monocular 3D scene in real-world settings, with an important advantage of making predictions directly in the metric space.









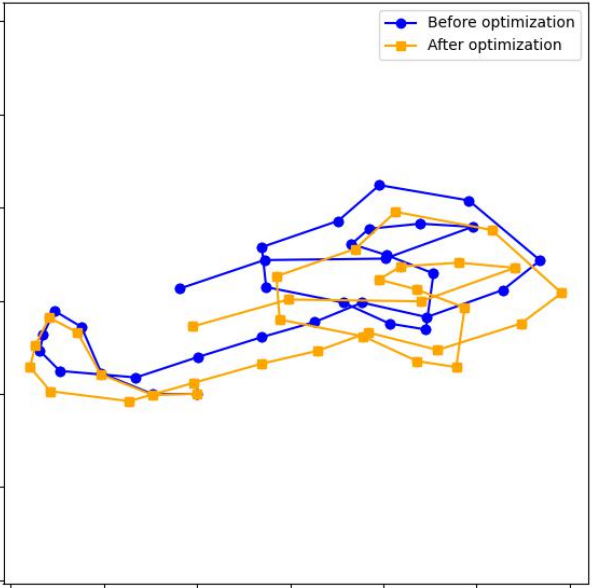
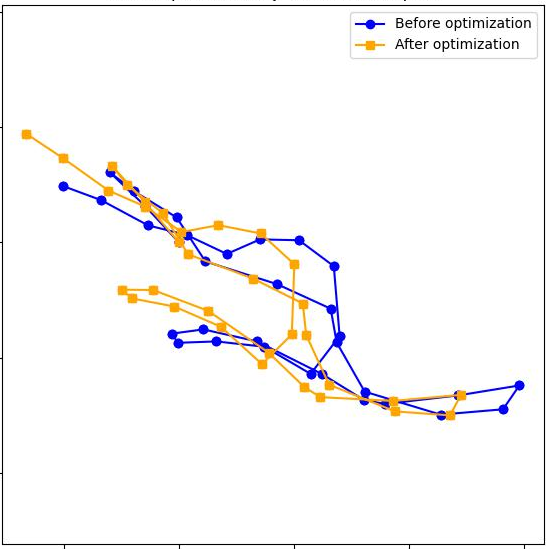
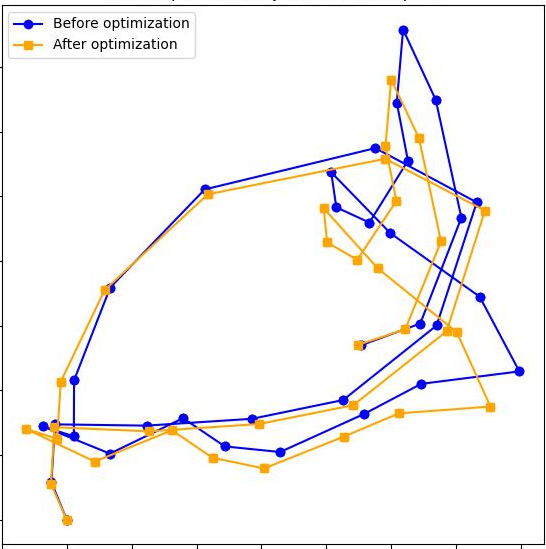
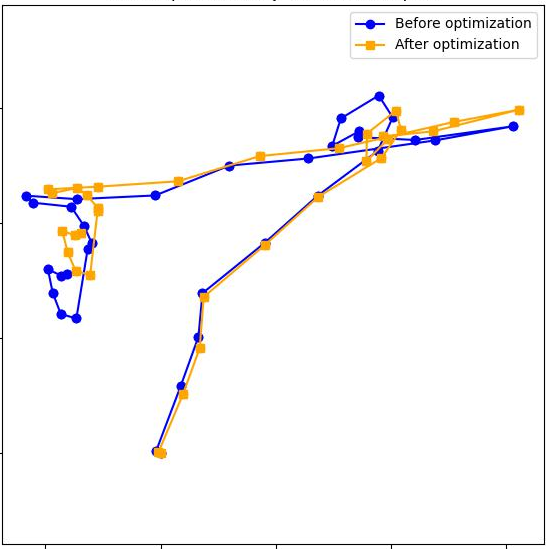


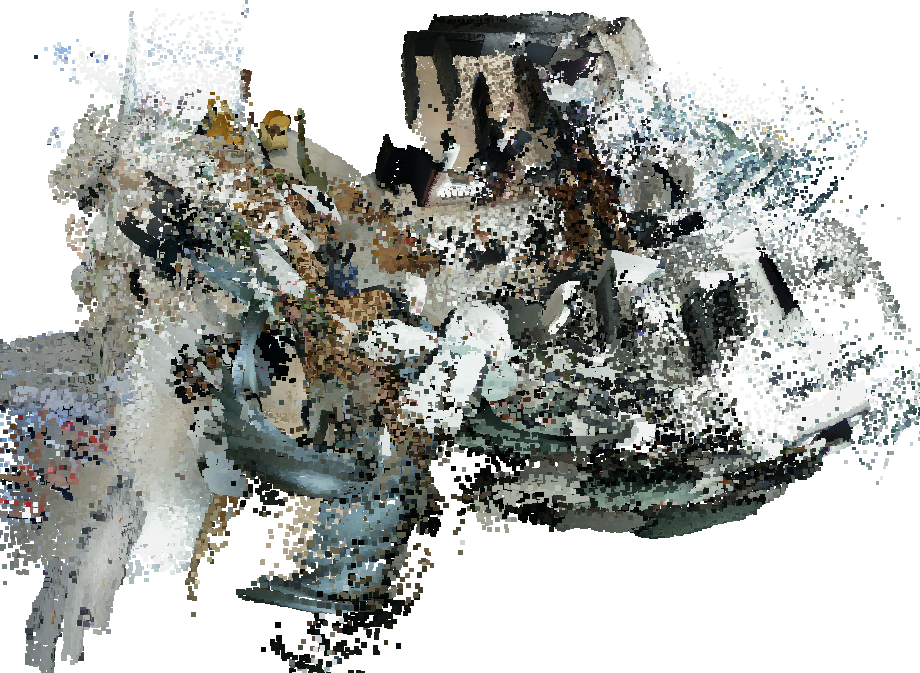
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “S-MUSt3R: Sliding Multi-view 3D Reconstruction”
What is this paper about?
This paper is about teaching a computer to build a 3D map of the world using only a regular video (just RGB images from one camera). The authors show a simple way to make a powerful AI model (called MUSt3R) handle long videos that normally don’t fit in a computer’s memory. Their method, S-MUSt3R, breaks a long video into smaller parts, rebuilds each part in 3D, and then carefully stitches those parts together into one accurate, life‑sized 3D scene.
What questions were the researchers trying to answer?
In simple terms, they asked:
- How can we turn a long, uncalibrated video (no special camera settings needed) into a consistent 3D map using just one camera?
- Can we do this using a simple process, without lots of extra complicated systems?
- Can we match the accuracy of the best existing methods—and even run well in real places where robots move around?
How does their method work?
Think of making a giant poster from a roll of stickers:
- If you try to place the whole roll at once, it’s messy and too big.
- Instead, you place small overlapping strips, make sure each strip lines up with the next, and adjust the whole poster so the picture looks perfect.
S‑MUSt3R follows that same idea.
The problem with long videos
Modern 3D “foundation models” (large AI models trained on tons of image data) can convert images to 3D very well, but they use a lot of memory. After a few hundred frames, even big GPUs can run out. So a long video is too big to process in one go.
Step 1: Split the video into overlapping segments
- The video is cut into chunks (for example, 60 frames each), and neighboring chunks overlap (so the end of one shares frames with the start of the next).
- Overlaps are like having common edges between puzzle pieces; they help align pieces later.
Step 2: Reconstruct each piece with MUSt3R
- MUSt3R takes each chunk and predicts:
- A “pointmap” (for each pixel, where it sits in 3D space),
- A depth map (how far things are),
- A confidence map (how sure it is about each pixel),
- Camera poses (where the camera was for each frame).
- MUSt3R has a special advantage: it produces metric 3D—meaning distances are in real units (like meters), not just relative scale. That’s very helpful for robots.
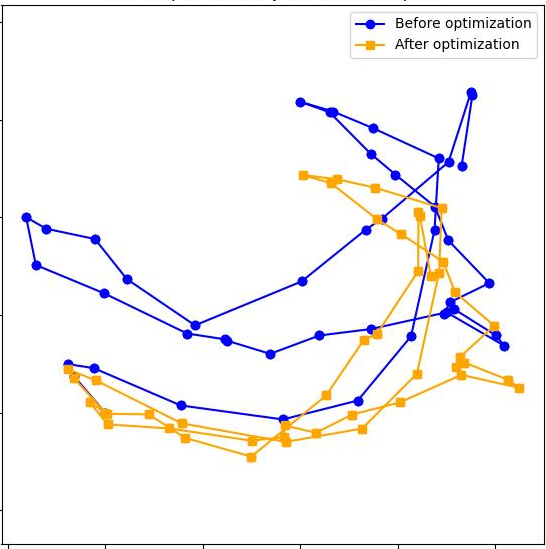
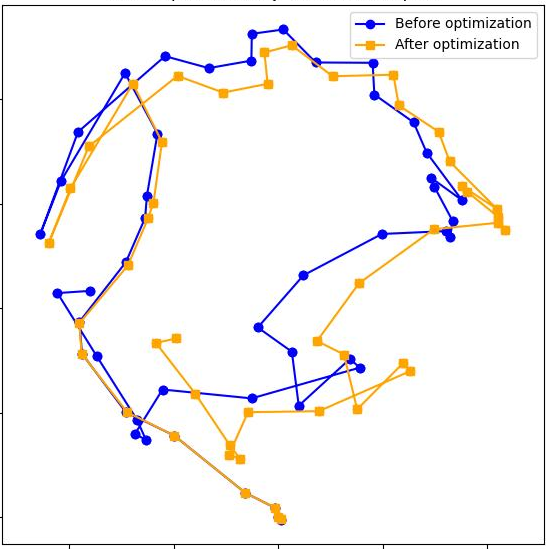
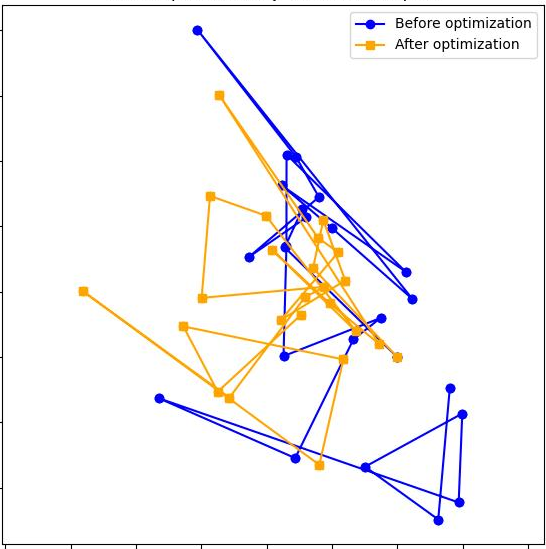
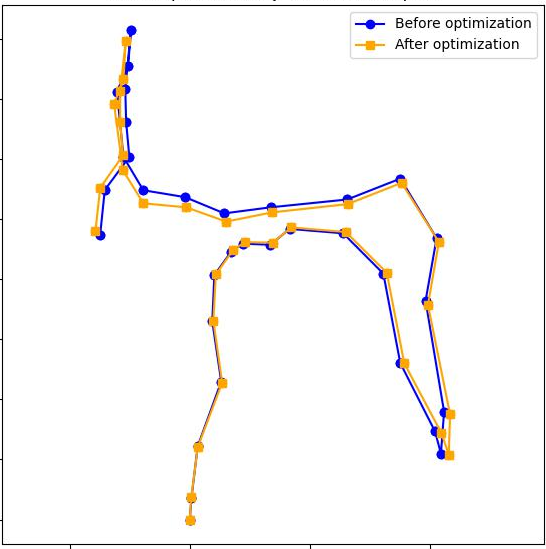
Step 3: Stitch the pieces together
- The overlapping frames give the model “matching points” between neighboring chunks.
- Using those matches, the method computes how to best move, rotate, and scale one chunk so it lines up with the next (like aligning two transparent photos).
- The paper tries a few types of “moves”:
- SIM(3): rotate + move + uniform scale (like zooming in/out).
- Affine(3) and SL(4): more flexible “stretchy” moves that can fix distortions, but are slower and less stable.
- They find SIM(3) is the best balance of speed and accuracy.
Making the alignment more reliable
- The method uses MUSt3R’s confidence scores to down-weight doubtful points.
- It also checks if the depth for the same pixel is consistent across overlapping chunks; if not, that pixel is trusted less. Analogy: if two friends disagree about how far away an object is, you rely less on that object when lining up the pictures.
“Loop closure”: correcting drift over long runs
- As you move through a long scene, small errors stack up (called drift), like drawing a map while walking and gradually getting a bit off track.
- When the camera comes back to a place it has seen before (a “loop”), the method notices this by comparing image features.
- It then creates an extra mini‑segment around the loop and uses it as a bridge to tighten up the alignment, like realizing “we’ve been here before” and erasing/re-drawing parts of your hand-drawn map so everything fits.
Final cleanup: global optimization
- All segments and their connections form a “pose graph” (think a network where each node is a chunk, and edges are how they align).
- A simple optimizer adjusts the whole network a little bit so all overlaps agree as much as possible—like gently stretching a rubber map so roads line up everywhere.
What did they find, and why does it matter?
The authors tested S‑MUSt3R on well-known 3D datasets (TUM RGB‑D, 7‑Scenes) and on real robot navigation videos.
Key takeaways:
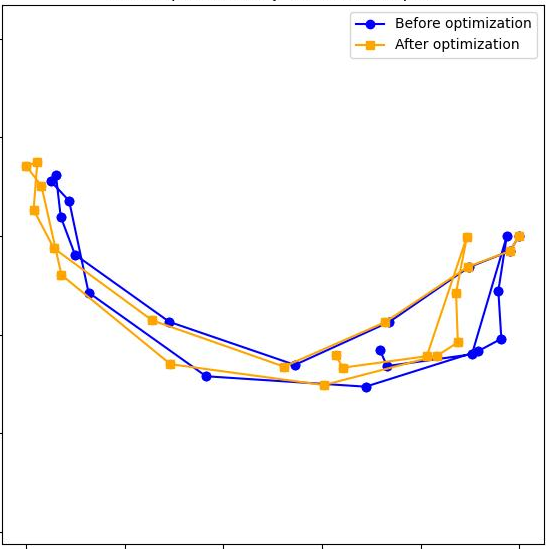
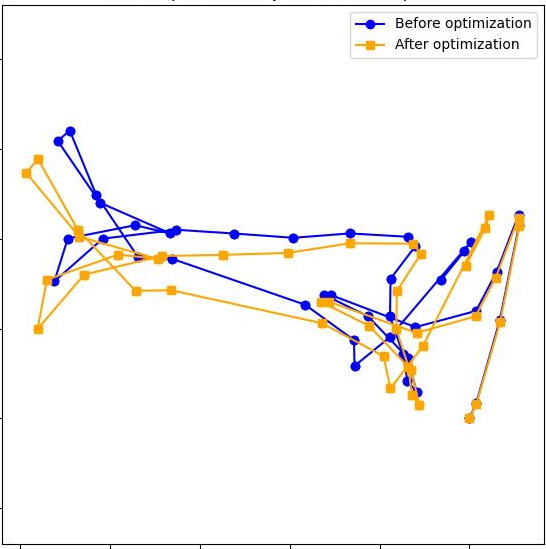
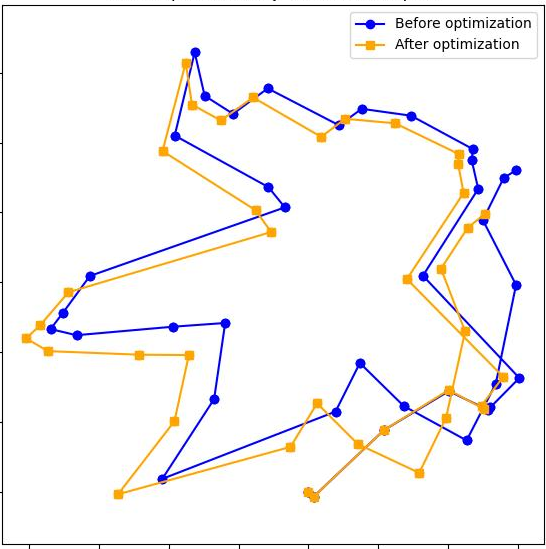
- It works on long RGB sequences and stays accurate.
- It’s as good as, or better than, several strong systems that use more complex backends.
- It beats a competing “stitching” approach (VGGT‑Long) by a large margin in many cases.
- It doesn’t need camera calibration and still produces metric (real‑world) distances—very useful for robots doing tasks like path planning or collision avoidance.
- A light, segment-level loop closure and optimization is enough; no heavy, complicated machinery is required.
- Using SIM(3) for alignment gives the best mix of stability and speed.
- Longer segments (when memory allows) usually improve accuracy because you need to stitch fewer pieces.
Why it matters:
- This approach shows you can scale powerful 3D AI models to long videos without retraining them or adding bulky systems.
- Robots, AR/VR devices, and other tools that need 3D understanding can benefit from a simpler, more memory‑friendly pipeline that still gives real‑world measurements.
What are the limitations?
- The final quality still depends on how good the local reconstructions are. If MUSt3R makes mistakes in a chunk, stitching can’t fix everything.
- Loop detection needs a similarity threshold (a hyperparameter). If it’s not tuned well, loops can be missed or false loops may slip in. More adaptive or probabilistic methods could make this even more robust.
What’s the big picture?
S‑MUSt3R is like reading a long book by chapters: process each chapter well, then make sure the chapters connect smoothly, and finally skim the whole story to resolve inconsistencies. With this simple “split–rebuild–stitch–tidy” strategy, the paper shows that long, uncalibrated, single‑camera videos can be turned into accurate, metric 3D maps. This is a practical step toward reliable, real‑world 3D perception for robots and other smart devices.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated to guide actionable future research:
- Lack of formal analysis and empirical stress tests on MUSt3R’s “metric” scale: why and when does metric scale hold without intrinsics? How stable is scale across cameras with different FOVs, focal lengths, or zoom/auto-focus changes? Measure inter-segment scale drift before/after alignment and across devices.
- No runtime and memory profiling: quantify GPU memory savings from segmentation, per-stage timing (segment reconstruction, alignments, loop detection, pose-graph optimization), and throughput (fps). Report scaling behavior for very long sequences (tens/hundreds of thousands of frames).
- Segmenting strategy is heuristic and static: only
lis ablated,p(overlap) is fixed tol/2. No adaptive segmentation based on scene overlap, parallax, motion type, or memory budget. Explore auto-tuning ofl/pand dynamic window sizes. - Confidence reweighting by depth disagreement is ad hoc and under-specified: the weighting formula is not fully detailed (normalization, bounds, hyperparameters), and numerical stability/calibration are untested. No ablation on reweighting vs. confidence-only vs. depth-only. Consider learned or probabilistic reweighting schemes.
- Reliance on MUSt3R encoder pooled features for loop detection is unvalidated: no precision/recall or ROC analysis of place recognition under large viewpoint/illumination changes. Compare against established global descriptors (e.g., NetVLAD, AP-GeM) with geometric verification and study false-positive loop closures.
- Pose-graph optimization only adjusts segment-to-segment transforms; within-segment cameras/pointmaps are never refined. This cannot correct drifts or biases inside segments. Evaluate adding lightweight cross-segment joint refinement (e.g., local BA on overlapping frames) and its impact on accuracy and compute.
- Robustness in challenging conditions is not systematically evaluated: dynamic scenes, rolling shutter, motion blur, severe low-texture (beyond anecdotal corridor case), large parallax, repeated patterns, or drastic lighting changes. Design targeted benchmarks and stress tests.
- Treatment of intrinsics and lens distortion is unclear: “uncalibrated” is assumed, but performance under unknown distortion, time-varying intrinsics (zoom), or strong radial distortion is not measured. Incorporate distortion-aware modeling or data-driven correction.
- SIM(3) alignment may undermine metric consistency: while chosen for speed/robustness, uniform scale per alignment can change absolute scale across segments. Quantify inter-segment scale variance and propose constraints/priors to preserve global metric consistency.
- Limited exploration of more expressive transform groups: Affine(3) and SL(4) are briefly tested, but no regularization, priors, or hybrid strategies (e.g., per-edge model selection, robust switching) are explored to stabilize SL(4) or selectively increase expressiveness when needed.
- Data association across segments is short-range and 3D-point-only: no global track management or long-range feature/track fusion. Explore track-based alignment spanning multiple segments to improve robustness in low-parallax or repeated/planar regions.
- No quantitative evaluation of reconstruction quality beyond odometry (ATE/AAE): depth/geometry metrics (e.g., depth RMSE, completeness, Chamfer/L1, surface normals) against ground truth 3D are missing. Add geometry-focused benchmarks and metrics.
- Reproducibility gap with proprietary robot dataset: dataset and protocols are not released; evaluation is not independently verifiable. Provide data or standardized benchmarks with similar characteristics.
- Loop-closure hyperparameters (
sigma_sim,k_min) and acceptance tests are not ablated: study sensitivity, develop self-tuning thresholds, or probabilistic loop acceptance to reduce hand-tuning and improve reliability. - No outdoor or large-scale (city/block-level) evaluation: assess performance under longer loops, sparse features, and significant scale/appearance changes; study scalability of the pose graph as the number of segments grows.
- Failure detection and recovery mechanisms are absent: how are misalignments or incorrect loop closures detected/mitigated? Investigate robust backends (e.g., switchable constraints, graduated non-convexity, TEASER-like certifiable solvers) and rollback strategies.
- Confidence is used in pairwise alignment but not propagated to the pose-graph: edge weights in the global optimization do not reflect uncertainty estimates. Incorporate uncertainty-aware weighting of constraints in LM.
- Integration with optional weak cues is unexplored: when IMU/wheel odometry is available, can it be used in a calibration-free way to stabilize drift while preserving the minimalist design?
- IRLS alignment sensitivity is uncharacterized: initialization, Huber parameter, and outlier breakdown point are not discussed. Compare against RANSAC-based estimators and analyze degeneracy in planar/low-parallax overlaps.
- Parameter selection is manual (e.g.,
sigma_sim, overlapp, Huber δ, KD-tree neighbors): develop automated selection or learned policies driven by online validation signals (e.g., residuals, consistency checks). - Long-sequence memory management is unspecified: storage/eviction policies for features, pointmaps, and descriptors are not described; streaming and embedded constraints are unaddressed.
- Code/data release plans are not stated, limiting reproducibility and uptake.
- Rolling-shutter effects and temporal distortions are not modeled or evaluated; include camera-specific temporal distortions in testing and alignment (e.g., RS-aware pose refinement).
- Construction of loop segment
S_L(window size around matched images, number of added frames, selection policy) is unspecified and not ablated; study its impact on accuracy and compute. - Scalability of the segment-level pose graph is not analyzed: how do node/edge counts and solver convergence behave with many loops and overlapping constraints? Provide complexity and convergence studies.
- Domain shift and training bias: MUSt3R’s generalization across sensor types, resolutions, and novel environments is not assessed; evaluate on deliberately out-of-distribution cameras/scenes and quantify degradation.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage S/logging MUSt3R’s sliding, segment-stitching pipeline on top of MUSt3R’s metric monocular 3D predictions without camera calibration.
- Robotics (indoor mobile robots) — monocular 3D mapping and localization for navigation
- Sectors: robotics, logistics, healthcare, security
- Use cases: autonomous service robots in offices/hospitals/retail, warehouse AGVs, patrol robots in GPS-denied spaces; metric map building for traversability, collision avoidance, and path planning; recovery in challenging corridors/feature-sparse areas (as demonstrated)
- Potential tools/workflows/products:
- ROS2 node integrating S-MUSt3R outputs (poses, pointmaps, depths) into Nav2/SLAMToolbox pipelines
- Occupancy grid generation from pointmaps; pose-graph correction as a standalone microservice
- Mapping “as-a-service” backend: upload monocular video; receive metric point cloud/poses
- Dependencies/assumptions: GPU for MUSt3R inference; sufficient parallax and texture; loop-closure threshold tuning (σ_sim); segment length/overlap chosen per platform; dynamic scenes may degrade performance
- AR/VR and 3D content creation — metric indoor reconstructions from phone/body-cam video
- Sectors: software, media, real estate, e-commerce
- Use cases: fast room scans with true scale for staging, gaming occlusion, virtual try-on of furniture, virtual tours, retail planograms
- Potential tools/workflows/products:
- Mobile capture app + cloud processor; export PLY/OBJ/glTF; Unity/Unreal plugin for scene import
- Mesh reconstruction from MUSt3R’s pointmaps; scale-aware measuring tools for creators
- Dependencies/assumptions: stable video capture; adequate lighting and texture; compute on server-side or high-end edge device; privacy safeguards
- Construction, Facility Management, and Digital Twins — low-cost, calibration-free indoor digitization
- Sectors: construction, AEC (architecture/engineering/construction), facilities
- Use cases: as-built documentation, asset inventory, maintenance routing, progress monitoring; alignment to BIM/CAD, space utilization analytics
- Potential tools/workflows/products:
- S-MUSt3R pipeline integrated with Autodesk/Bentley connectors; Omniverse/IFC export
- Post-processing: pointmap-to-mesh/floorplan extraction; pose graph output for change detection
- Dependencies/assumptions: minimal dynamic clutter for consistent loop closure; QA checks in repetitive or low-texture corridors; compute resources sized to site scope
- Public safety and emergency response — rapid indoor situational maps from monocular body-cam
- Sectors: public safety, government
- Use cases: fast metric mapping for team coordination in complex buildings, route planning in GPS-denied interiors
- Potential tools/workflows/products:
- Command-center service that ingests responders’ video streams and returns stitched metric maps/trajectories
- Integration with incident management dashboards; export to GIS viewers
- Dependencies/assumptions: adequate illumination/visibility; near-real-time compute availability; policies for on-device/off-cloud processing and privacy
- Retail operations and inventory robotics — store layout mapping and navigation
- Sectors: retail, robotics
- Use cases: autonomous inventory scans, shelf auditing, restocking routes, overnight mapping
- Potential tools/workflows/products:
- Store-mapping toolchain using S-MUSt3R; path optimization with metric constraints
- Integration with planogram compliance systems
- Dependencies/assumptions: repetitive textures may challenge loop closure; mixed dynamic scenes; GPU-equipped robots or central processing nodes
- Healthcare logistics and service robots — route mapping in hospitals without calibrated cameras
- Sectors: healthcare, robotics
- Use cases: specimen/medication delivery carts, cleaning robots; maintaining metric maps across wards
- Potential tools/workflows/products:
- Hospital digital twin update service from patrol videos; ROS2 integration with hospital robot fleets
- Dependencies/assumptions: privacy/PHI compliance; staff/patient motion can introduce reconstruction noise; robust loop-closure settings
- Insurance and real estate documentation — metric capture for claims and listings
- Sectors: insurance, real estate, finance
- Use cases: claims inspection with metric measurements; virtual walkthroughs; property condition baselines
- Potential tools/workflows/products:
- Web portal to upload phone/gimbal videos; auto-generated, scale-accurate models and measurements
- Dependencies/assumptions: coverage completeness of capture; consistent motion; data governance
- Academic research and teaching — an accessible, calibration-free baseline for long monocular sequences
- Sectors: academia, education
- Use cases: 3D vision coursework labs; SLAM benchmark baselines; ablation studies on segment length/transform groups; robotics capstones
- Potential tools/workflows/products:
- Course kits and Jupyter notebooks; ROS bag utilities; reproducible leaderboards (TUM/7-Scenes)
- Dependencies/assumptions: access to the MUSt3R pre-trained weights; GPU availability
- Security and inspection — interior patrol mapping with monocular cameras
- Sectors: security, industrial inspection
- Use cases: route verification, anomaly localization; map maintenance in large campuses
- Potential tools/workflows/products:
- Patrol robot SDK with S-MUSt3R; inspection reports tied to metric 3D coordinates
- Dependencies/assumptions: low-light conditions may impair results; hyperparameter tuning for large loops
- Software componentization — “engine” for monocular 3D in existing stacks
- Sectors: software, robotics middleware
- Use cases: swap-in foundation-model-based mapping for legacy SfM/SLAM; pipeline simplification
- Potential tools/workflows/products:
- gRPC/REST microservice exposing segment processing, alignment, loop closure; containerized deployment on-prem/cloud
- Dependencies/assumptions: licensing for MUSt3R weights; GPU scheduling; monitoring for drift/loop quality
Long-Term Applications
These applications are feasible with further research, optimization, or ecosystem development (e.g., real-time constraints, robustness in difficult scenes, large-scale deployments).
- Real-time, on-device monocular SLAM on edge platforms and mobile phones
- Sectors: robotics, consumer devices, AR
- Use cases: live navigation for small robots/drones; on-phone AR scanning with metric scale
- What’s needed: model compression/quantization, FlashAttention-like memory optimizations, pipeline-level scheduling; robust auto-tuning of loop-closure hyperparameters; thermal/power budgets
- Outdoor and large-scale mapping with monocular video only
- Sectors: mapping, smart cities, logistics
- Use cases: campus-scale maps; low-cost fleet mapping in GPS-degraded areas (e.g., parking garages, tunnels)
- What’s needed: robustness to lighting/weather, larger loops and long-term drift handling, scene-scale variation; better dynamic object handling and texture-poor facades
- Multi-robot collaborative mapping and cross-session loop closure
- Sectors: robotics, infrastructure management
- Use cases: fleets building unified metric maps; incremental updates of digital twins
- What’s needed: distributed pose-graph optimization across segment graphs; consistent metric alignment across robots; scalable, robust place recognition beyond single-stream KD-trees
- Dynamic-scene understanding: separating moving objects from static structure
- Sectors: robotics, AR, surveillance
- Use cases: navigation in crowded spaces; persistent maps with transient object filtering
- What’s needed: integration with motion segmentation, learned dynamic priors; uncertainty-aware alignment; robust confidence strategies beyond depth-consistency
- Photorealistic digital twins by fusing with NeRFs/Gaussian Splatting
- Sectors: AEC, media, simulation
- Use cases: metric, photorealistic twins for simulation/training; high-fidelity visualization
- What’s needed: consistent camera/scene priors for neural rendering; pipelines to turn S-MUSt3R poses/pointmaps into efficient NeRF/GS initializations; compute scaling
- Persistent AR cloud anchors and shared indoor maps
- Sectors: AR cloud, enterprise IT
- Use cases: multi-user, cross-session AR experiences with metric alignment in large buildings
- What’s needed: robust place recognition at building scale; map versioning and merging; privacy-preserving sharing protocols
- Safety-certified navigation in regulated domains (hospitals, factories)
- Sectors: healthcare, manufacturing
- Use cases: robots relying on monocular-only sensing for certified pathways
- What’s needed: formal verification of mapping accuracy bounds; redundancy/fallback sensing; standardized test suites and acceptance criteria
- Industrial inspection in complex plants (energy, oil & gas)
- Sectors: energy, industrial
- Use cases: mapping pipe galleries, substations, refineries with monocular payloads
- What’s needed: resilience to repeated patterns/low-texture metallic surfaces; improved loop closure in large, self-similar environments; hazard-safe hardware integration
- Policy and standards for low-cost, calibration-free 3D capture
- Sectors: government, standards bodies
- Use cases: guidelines for public building digitization; procurement frameworks for monocular-only mapping; privacy standards for indoor scans
- What’s needed: public datasets beyond labs; repeatable benchmarks for scale accuracy and drift; privacy-by-design capture practices
- Finance and insurance automation — risk and appraisal pipelines
- Sectors: finance, insurance
- Use cases: automated valuation/risk scoring from metric interior scans
- What’s needed: standardized measurement extraction from pointmaps; explainability/traceability; integration with underwriting systems and regulatory compliance
- Assistive technologies and accessibility planning
- Sectors: assistive tech, smart home
- Use cases: generating metric floorplans for mobility-aid planning and home modifications
- What’s needed: robust processing in cluttered homes; simple capture UX; integration with assistive planning tools and safety constraints
Cross-cutting Assumptions and Dependencies
- Compute: MUSt3R-based inference currently benefits from GPU acceleration; segmenting alleviates memory limits but does not eliminate the need for capable hardware.
- Scene properties: sufficient parallax, textured surfaces, and stable illumination improve results; highly dynamic scenes, extreme low light, and large, featureless spaces remain challenging.
- Hyperparameters: loop closure relies on thresholds (e.g., σ_sim); auto-tuning/self-calibration would increase reliability in the field.
- Data/model availability: MUSt3R pre-trained weights and licensing; generalization beyond benchmark domains may require validation.
- Output post-processing: pointmaps typically require meshing/floorplan extraction and semantic labeling for downstream products.
- Privacy/compliance: indoor capture can include sensitive content; deployments need appropriate policies and on-device processing options.
These applications leverage S-MUSt3R’s core innovations—segment-wise processing, confidence modulated by depth agreement, lightweight loop closure, and pose-graph optimization—combined with MUSt3R’s metric predictions from uncalibrated RGB. Together, they enable practical, scalable monocular 3D reconstruction workflows today and point to robust, real-time, and large-scale systems with additional R&D.
Glossary
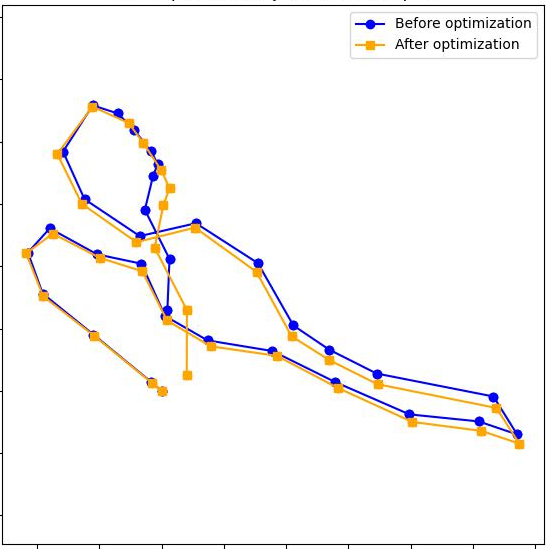
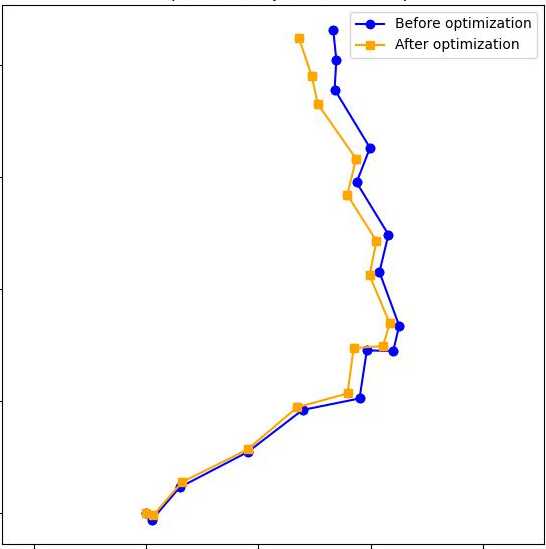
- Absolute pose error (APE): A metric quantifying the difference between estimated and ground-truth camera poses. "we report root mean square error~(RMSE) of the absolute pose error~(APE) using EVO metric~\cite{Grupp17evo}."
- Absolute trajectory error (ATE): A metric measuring the deviation of an estimated trajectory from ground truth over time. "Root mean square error~(RMSE) of absolute trajectory error (ATE) on 7-Scenes~\cite{Shotton13cvpr} (unit: m)."
- Affine(3): The 3D affine transformation group allowing rotations, translations, non-uniform scaling, and shearing. "Recent works propose to replace SIM(3) group with Affine(3)~\cite{yu2025relativeposeestimationaffine} or SL(4) groups~\cite{maggio2025vggtslamdensergbslam} to cope with such distortions."
- All-to-all attention: A Transformer attention pattern where every token attends to every other token, improving global context modeling. "Fast3R~\cite{faster} replaced pairwise attention with all-to-all attention"
- Backpropagation: The gradient-based training procedure that propagates errors through all model components. "Trained on massive datasets with backpropagation of errors through the entire pipeline integrating 3D scene representation, camera pose and intrinsic parameter estimation,"
- Bundle adjustment: A nonlinear optimization refining camera parameters and 3D points jointly across multiple views. "Using multi-view geometry~\cite{Koenderink91} and bundle adjustment~\cite{Pan24eccv-GLOMAP,Schonberger16cvpr-SfMRevisited},"
- Confidence-aware loss: A training objective that weights errors by predicted confidence to emphasize reliable estimates. "MUSt3R trains the model using a confidence-aware loss and predicts a confidence score for each pixel in the images."
- Cosine similarity threshold: A cutoff on descriptor similarity used to decide loop-closure candidates. "The cosine similarity threshold is ."
- Differentiable SfM: Structure-from-Motion formulated with differentiable components for end-to-end training. "often via differentiable SfM trained end-to-end."
- EVO metric: A toolkit/metric used to compute trajectory evaluation measures such as APE/ATE. "we report root mean square error~(RMSE) of the absolute pose error~(APE) using EVO metric~\cite{Grupp17evo}."
- Feed-forward foundation models: Large pretrained models that infer outputs in a single forward pass without iterative optimization. "feed-forward foundation models based on the Transformer architecture~\cite{vaswani2017attention}."
- Flash-Attention: A memory-efficient attention algorithm for Transformers enabling faster/larger-sequence processing. "While techniques like Flash-Attention~\cite{dao2023flashattention2} improve efficiency, GPU memory consumption remains high,"
- Gauss-Newton: A second-order optimization method commonly used for nonlinear least-squares problems. "By blending Gauss-Newton with gradient descent, the LM algorithm redistributes error over all nodes so that all constraints are satisfied as much as possible."
- Homography: A projective transformation relating two views of a planar scene or general perspective mappings. "aligning segments with transforms from SL(4) group requires estimating a relative homography matrix between the segments;"
- Huber loss: A robust loss function that is quadratic for small errors and linear for large ones to reduce outlier influence. "where is the Huber loss function which down-weights the influence of outliers."
- h-solver: A solver used to estimate homographies between segments in the SL(4) setting. "we use h-solver from VGGT-SLAM~\cite{maggio2025vggtslamdensergbslam}."
- Iteratively Reweighted Least Squares (IRLS): An optimization technique that solves robust regression by reweighting residuals iteratively. "we deploy, in the case of SIM(3) and Affine(3) transforms, the Iteratively Reweighted Least Squares (IRLS) optimization \cite{vggt-long}."
- KDTree: A spatial indexing data structure for fast nearest neighbor search in descriptor space. "We create and maintain KDTree() structure of image descriptors;"
- Levenberg–Marquardt (LM) algorithm: A damped least-squares optimizer combining Gauss-Newton and gradient descent. "This non-linear least-squares problem is efficiently solved using the Levenberg-Marquardt (LM) algorithm."
- Lie group: A continuous group of transformations used to model geometric mappings (e.g., SIM(3)). "It is common to estimate transforms using SIM(3) Lie group~\cite{vggt-long,eth3d_slam,Teed21nips-DROID-SLAM}"
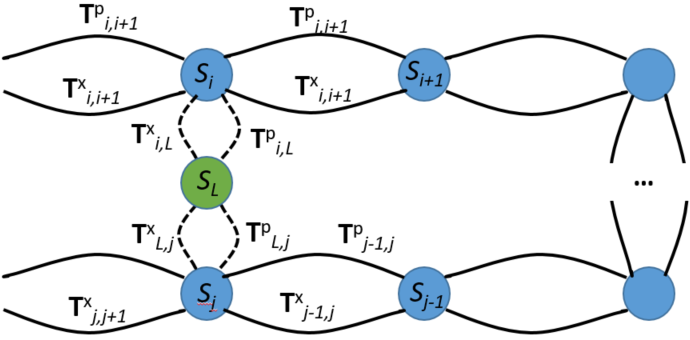
- Loop closure: The detection and incorporation of revisited locations to reduce accumulated drift in a trajectory. "then aligns the segments and corrects the accumulated drift with lightweight loop closure and optimization."
- Metric space: A space where distances have physical units, enabling scale-aware predictions. "with an important advantage of making predictions directly in the metric space."
- Monocular: Refers to using a single camera or image stream, without stereo or depth sensors. "monocular RGB alone remains an open challenge,"
- Multi-view geometry: The mathematical framework for relating multiple camera views to reconstruct 3D. "Using multi-view geometry~\cite{Koenderink91} and bundle adjustment~\cite{Pan24eccv-GLOMAP,Schonberger16cvpr-SfMRevisited},"
- Patch features: Local image descriptors extracted over patches, used for matching or loop detection. "MUSt3R's encoder which generates patch features for any image in the sequence."
- Pointmap: A dense per-pixel mapping of image pixels to 3D points in a scene coordinate frame. "They predict pointmaps, depths and camera poses in a single forward pass"
- Pose graph: A graph whose nodes represent poses (or segments) and edges impose relative transformation constraints. "building a pose graph where segments are nodes and the edges are constrained by alignments"
- Pose graph optimization: Global optimization over a pose graph to enforce consistency among relative constraints. "combines MASt3R with a complex backend of pose graph optimization and bundle adjustment."
- Projective warping: A transformation allowing perspective distortions beyond affine changes. "Then, SL(4) group includes translations, scaling and projective warping."
- RMSE: Root Mean Square Error; a statistic measuring the magnitude of errors. "We report root mean square error~(RMSE) of the absolute pose error~(APE) using EVO metric~\cite{Grupp17evo}."
- Running memory: A memory mechanism that maintains and updates scene information incrementally across frames. "it leverages a running memory and updates 3D scene of current observations on-the-fly."
- Shearing: A linear transformation that skews the shape along one axis. "Affine(3) group includes in addition non-uniform scaling and shearing."
- SIM(3): The 3D similarity transformation group including rotation, translation, and uniform scaling. "Conventional SIM(3) group includes rotations, translations and uniform scaling."
- SL(4): A higher-order transformation group enabling more general projective mappings. "Then, SL(4) group includes translations, scaling and projective warping."
- Transformer architecture: A neural network architecture based on attention mechanisms, widely used in vision and language. "feed-forward foundation models based on the Transformer architecture~\cite{vaswani2017attention}."
- Uncalibrated images: Images captured without known camera intrinsics, requiring methods to infer calibration or operate without it. "3D perception from uncalibrated images."
- ViT-L / ViT-B: Vision Transformer model variants (Large/Base) used as encoder/decoder backbones. "with ViT-L encoder and ViT-B decoder available at {\tt https://github.com/naver/must3r}."
Collections
Sign up for free to add this paper to one or more collections.