BLITZRANK: Principled Zero-shot Ranking Agents with Tournament Graphs
Abstract: LLMs have emerged as powerful zero-shot rerankers for retrieval-augmented generation, offering strong generalization without task-specific training. However, existing LLM reranking methods either rely on heuristics that fail to fully exploit the information revealed by each ranking decision or are inefficient when they do. We introduce a tournament graph framework that provides a principled foundation for $k$-wise reranking. Our key observation is that each $k$-document comparison reveals a complete tournament of $\binom{k}{2}$ pairwise preferences. These tournaments are aggregated into a global preference graph, whose transitive closure yields many additional orderings without further model invocations. We formalize when a candidate's rank is certifiably determined and design a query schedule that greedily maximizes information gain towards identifying the top-$m$ items. Our framework also gracefully handles non-transitive preferences - cycles induced by LLM judgments - by collapsing them into equivalence classes that yield principled tiered rankings. Empirically, across 14 benchmarks and 5 LLMs, our method achieves Pareto dominance over existing methods: matching or exceeding accuracy while requiring 25-40% fewer tokens than comparable approaches, and 7$\times$ fewer than pairwise methods at near-identical quality.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to rank things (like search results) using LLMs without special training. It shows how to get the most out of each comparison the model makes by treating small group comparisons like mini “tournaments,” then combining what we learn into a bigger picture. The method is called BlitzRank.
What questions were the researchers trying to answer?
- How can we pick the best items (like the top 10 search results) by asking an LLM to compare small groups, while using as few model calls (and tokens) as possible?
- How can we use all the information revealed by each group comparison, not just the winner?
- What should we do when the model’s judgments aren’t perfectly consistent (for example, it says A beats B, B beats C, but C beats A)?
- Can this approach be both accurate and efficient across many datasets and different LLMs?
How did they approach the problem?
The main idea: using tournaments
Imagine ranking many items (documents) with a helpful judge (the LLM). Instead of comparing just two at a time, we compare a small group of size k (like 5 or 10). In that group, the judge can tell us a full ordering—who is first, second, third, etc. That reveals all the pairwise matchups inside the group (for k items, that’s k·(k−1)/2 little “who beats who” results). This is like running a mini tournament among those k items.
Making the most of each comparison
When we collect these mini tournaments and add them to a growing “preference graph” (a map of who beats whom), we can use simple logic to learn even more:
- If A beats B and B beats C, it’s very likely A beats C. This “chain of wins” means each new piece of information can unlock more orderings without asking the model again. The paper calls this transitive reasoning, and it helps finish ranking some items early because we’ve already determined their relationships to everyone else.
Handling conflicts or cycles
Sometimes the judge’s answers form a loop: A beats B, B beats C, and C beats A. That’s not a failure—it usually means these items are very similar, making them hard to tell apart. The paper groups items in such loops into “tiers” (think of them as ties). You get a ranked list of tiers—like Tier 1 (best), Tier 2, Tier 3—with ties inside each tier. This is fair: if the judge can’t consistently separate those items, we shouldn’t pretend we can.
The BlitzRank algorithm (in simple steps)
- Keep a growing graph of who beats whom based on the judge’s answers.
- Use transitive logic (chains of wins) to infer extra results for free.
- Decide which items are already “final” (their place is certain) and stop once the top m are finalized.
- Choose the next group to compare by picking items that are least resolved (most uncertain), one from each uncertain tier. This greedy strategy ensures every round adds new information.
A simple example: the 25 horses puzzle
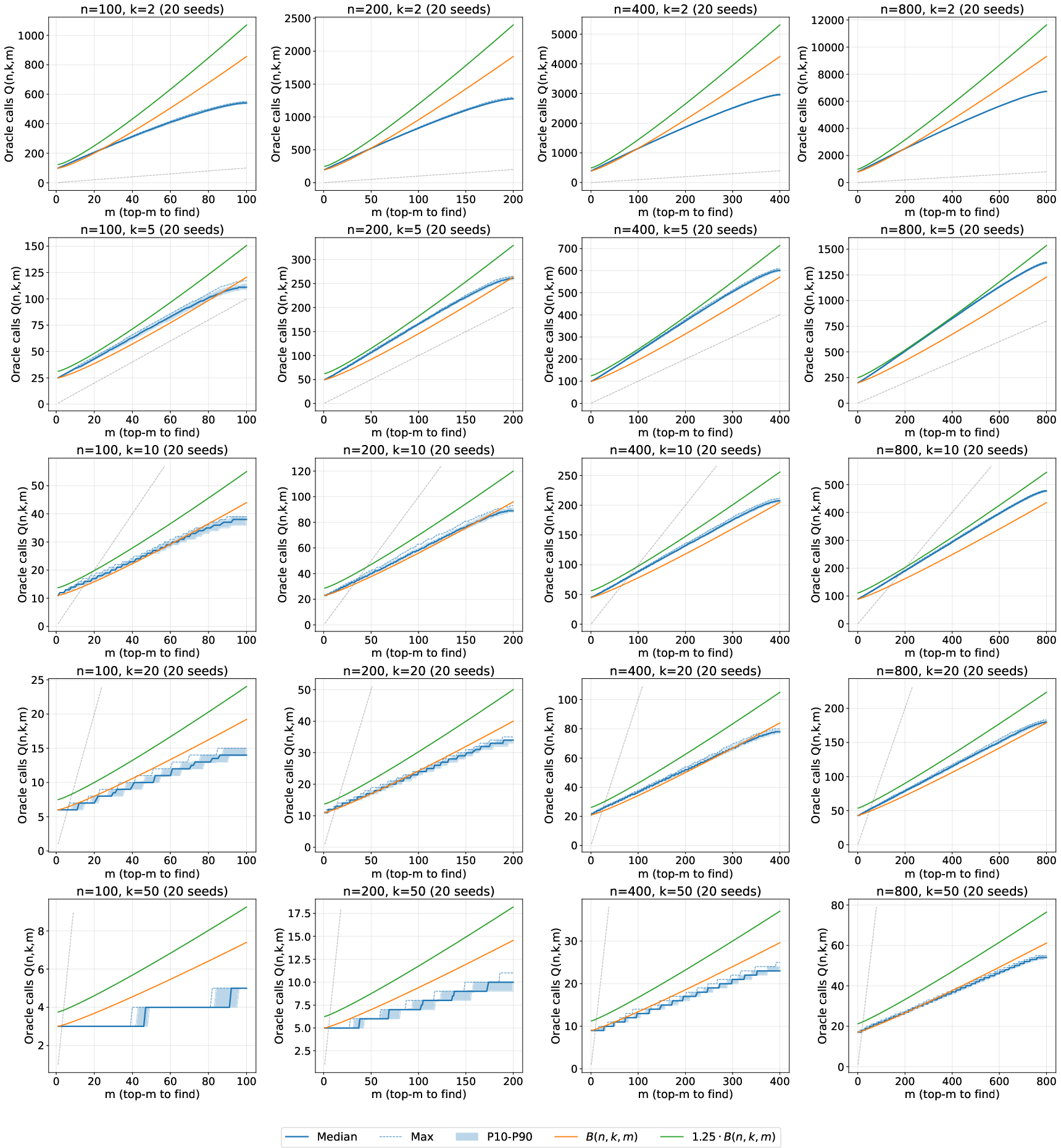
Classic puzzle: you have 25 horses, can race 5 at a time, and want the top 3 fastest. The smart way isn’t just picking winners—it’s using the full order from each race and the chain of wins between races. The paper shows BlitzRank reaches the known optimal solution: only 7 races are needed.
What did they find?
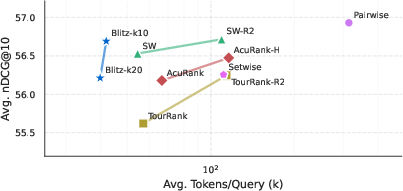
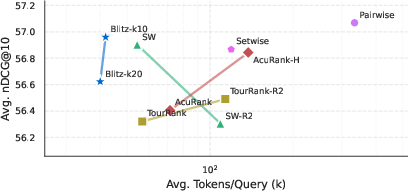
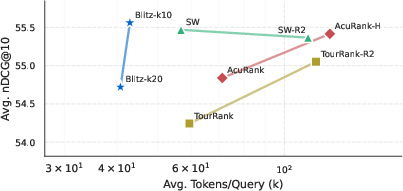
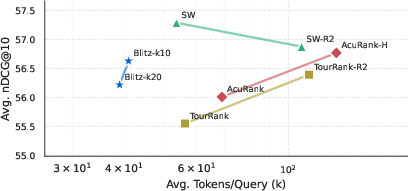
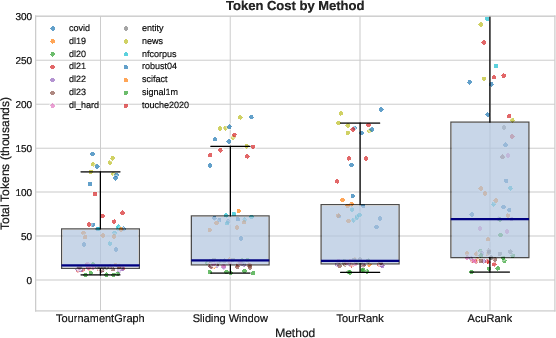
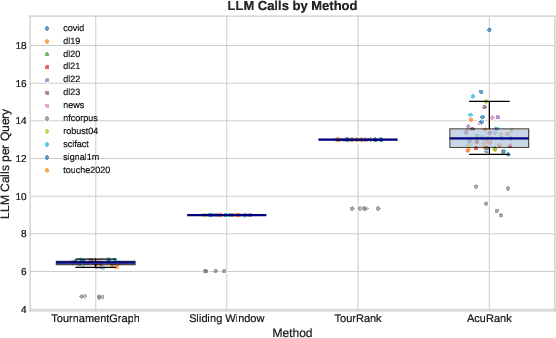
- Efficiency: BlitzRank uses 25–40% fewer tokens than strong listwise baselines (like sliding windows) and about 7× fewer tokens than pairwise comparison methods, while reaching very similar accuracy.
- Accuracy: Across 14 datasets and 5 different LLMs, BlitzRank matches or beats other methods in ranking quality (nDCG@10), even though it uses fewer model calls.
- Generalization: The efficiency and accuracy hold across multiple popular LLMs (GPT-4.1, Gemini-3-Flash, DeepSeek, Qwen, GLM), showing the method isn’t tied to one model.
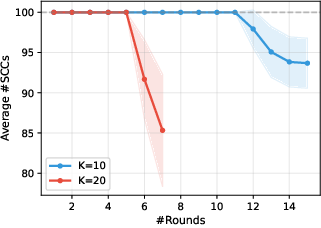
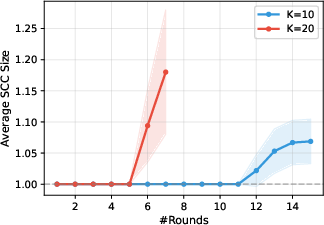
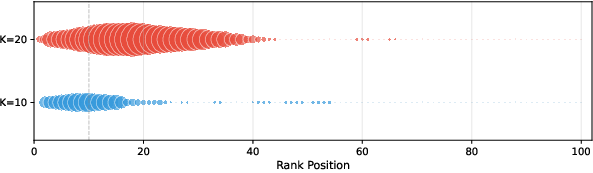
- Window size matters: Comparing 10 items at a time often works better than comparing 20. Larger windows make the model more likely to produce cycles (ties), especially among mid-ranked items, probably because it’s harder to track many items at once. Smaller windows reduce these ties and improve accuracy.
- Predictable cost: BlitzRank converges in a steady number of rounds (for k=10, about 13–14 rounds; for k=20, about 6–7), making it easier to estimate cost ahead of time.
- Cycles aren’t noise: Items that form cycles (ties) tend to be genuinely similar (for example, they have similar BM25 scores), confirming that cycles reflect real ambiguity rather than random mistakes.
Why does this matter?
- Faster, cheaper ranking: Because BlitzRank squeezes extra information out of each comparison, it reduces token usage and cost without hurting quality.
- Better retrieval systems: Search, question-answering, and retrieval-augmented generation (RAG) systems can rerank results more efficiently and fairly, which is important at scale.
- Practical design for comparisons: The method applies beyond LLMs—like crowdsourced judgments or sports tournaments—anywhere group comparisons are possible and expensive.
- Honest handling of ties: Grouping hard-to-separate items into tiers produces a fair, principled ranking when perfect ordering isn’t possible.
Key takeaways
- Compare small groups, not just pairs; record all the matchups from each group.
- Use chain-of-wins reasoning to infer many extra results for free.
- Treat cycles as tie tiers, not errors.
- Pick the next items to compare from the most uncertain tiers to maximize progress.
- This approach saves tokens, keeps accuracy high, and works across different datasets and LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved in the paper. Each item is phrased to be actionable for future research.
- Formal query complexity for general
m: The paper proves a tight bound for top-1 selection but leaves top-mquery complexity as a conjecture. A rigorous upper bound (and matching lower bounds) for arbitrarym, possibly under adversarial or stochastic tournaments, remains open. - Optimality of the greedy schedule: The SCC-based, in-reach–ordered query schedule is shown to guarantee progress, but its optimality (or approximation factor) against an oracle-optimal scheduler for minimizing queries is unknown.
- Adaptive window sizing
k: While the framework supports variablek, the paper does not propose or analyze policies that adaptkper round to document lengths, token budgets, or learned uncertainty—nor provide theoretical guarantees for such adaptive policies. - Early stopping without full finalization: Termination requires each top-
mcandidate to be fully finalized (K(v) = n - 1). It is unclear whether weaker certification criteria (e.g., only relative to the frontier/boundary tiers) can safely enable earlier stopping with guarantees. - Robustness to noisy oracles: The approach treats cycles as meaningful tiers rather than noise, but it lacks a model of stochastic or adversarial oracle errors and does not analyze error amplification via transitive closure. No mechanisms are provided for repeated comparisons, consensus aggregation, or confidence-weighted edges.
- Edge verification and error correction: The algorithm assumes correctness of edges returned by the oracle. Strategies for detecting and correcting erroneous edges (e.g., re-querying disputed pairs, majority voting across seeds, or robust inference under bounded noise) are not explored.
- Confidence-aware tournaments: LLM outputs may contain implicit or explicit confidence signals. Extending the framework to weighted tournaments (with edge confidences), and analyzing how weights affect finalization and query complexity, is unexplored.
- Cycle resolution policies: Beyond tiering via SCCs, the paper does not consider targeted queries to break cycles (inside SCCs) when a total order is required, nor does it analyze the minimal queries needed to refine large SCCs near the top-
mboundary. - Tie-breaking within SCC tiers: When the boundary tier contains more items than the remaining quota, ties are “broken arbitrarily” (or via initial retrieval order). The impact of different tie-breaking policies on nDCG@10, fairness, and stability is unstudied.
- Sensitivity of SCC formation to prompt design: The paper attributes larger SCCs (especially at
k = 20) partly to “lost in the middle,” but does not evaluate prompt variations (positioning, chunking, salience cues) to mitigate cyclic judgments or quantify their effect on SCC size and accuracy. - Distinguishing ambiguity from noise: BM25 score variance is used as a proxy to suggest SCCs capture genuine similarity, but there is no ground-truth validation (e.g., human judgments) disentangling ambiguity from model inconsistency or prompt artifacts.
- Computational overhead of graph operations: The cost and scalability of computing reachability (
L(v),W(v)), SCCs, and condensation each round on largen(e.g., top-500 or top-1k candidates) are not characterized, especially for streaming or incremental updates. - Parallelization limits and synchronization: While the paper notes natural parallelization across SCCs, it does not quantify speedups, address synchronization overhead when merging results, or analyze consistency when parallel batches induce overlapping transitive inferences.
- Applicability beyond LLM reranking: The framework claims generality (crowd judgments, human evaluation, tournament design), yet experiments and failure modes outside document reranking (e.g., human raters with systematic biases or sparse feedback) are not provided.
- Baseline comparability and tuning: Uniform prompt format is used across methods, but baselines optimized for different prompts/windowing may be disadvantaged. Sensitivity analyses over baseline hyperparameters, prompt variants, and per-dataset tuning are missing.
- Cost accounting beyond input tokens: Efficiency is measured with input tokens only; output tokens, latency, monetary cost, and throughput (especially under parallelization) are not reported, which may alter the practical Pareto frontier.
- End-to-end RAG impact: The study focuses on ranking metrics (nDCG@10). Effects on downstream answer quality, factuality, or hallucination rates in RAG systems are not assessed, nor are task-level metrics (e.g., EM/F1 in QA).
- Generalization across retrieval pipelines: All evaluations use BM25 top-100. The framework’s behavior with stronger/neural retrieval, different pool sizes (e.g., 200–1000), or domain-specific retrievers is not examined.
- Large-
nbehavior and memory constraints: Although query complexity is discussed up ton ≤ 800synthetically, practical behavior on much larger candidate pools and the memory/token trade-offs of scalingnare not characterized. - Effects of
mand boundary placement: The paper fixesm = 10. The algorithm’s sensitivity to differentm(small vs. largem), the frequency and severity of boundary-tier ties, and the resulting impact on metrics remain unexplored. - Alternative termination criteria for tiers: In non-transitive settings, certifying that “any subset” from a boundary SCC is valid may be insufficient for applications requiring stable or interpretable selections. Formal criteria for acceptable tier-level outputs are not defined.
- Lower bounds and instance optimality: Information-theoretic lower bounds for
k-wise top-mselection (with or without non-transitivity) and conditions under which BlitzRank is instance-optimal are not established. - Distributional assumptions and adversarial tournaments: The framework does not analyze worst-case adversarial tournaments (e.g., dense cycles targeting the top-
mboundary) or characterize expected performance under realistic distributions of pairwise preferences. - Use of partial tournaments within windows: If the oracle returns ties or incomplete orderings within
k(common with LLMs), mapping to a full tournament may be invalid. Handling partial orders or explicit ties inSis not addressed. - Active item selection within large SCCs: The “one representative per SCC” rule may be suboptimal for large SCCs near the frontier. Item selection policies that target informative members (e.g., high-degree nodes or uncertain edges) are not developed or analyzed.
- Cross-oracle inconsistency: Differences in SCC patterns across LLMs are reported qualitatively, but a systematic analysis of how oracle capability and calibration affect cycle prevalence and finalization speed is missing.
- Statistical significance and robustness: Reported accuracy differences are small in some cases; statistical tests, confidence intervals, and robustness analyses (e.g., across random seeds, query shuffles, and prompt variants) are not provided.
- Safety and fairness considerations: Tiered outputs and tie-breaking may introduce biases (e.g., favoring initial retrieval order). The paper does not discuss fairness criteria, bias detection, or mitigation strategies in the ranking outputs.
Glossary
- Bayesian inference: A probabilistic method for updating beliefs (distributions) based on observed evidence. "REALM takes a probabilistic approach, modeling relevance as Gaussian distributions updated via Bayesian inference."
- BM25: A probabilistic information-retrieval ranking function that scores documents based on term frequency and document length normalization. "For each dataset, BM25~\citep{robertson2009probabilistic} retrieves the top-100 candidates per query."
- Condensation (of a graph): The graph obtained by collapsing each strongly connected component into a single supernode, preserving edges between components. "The condensation $\condense{G}$ collapses each SCC to a supernode, with edges inherited from cross-component edges in ."
- Coefficient of variation: A normalized measure of dispersion given by the ratio of the standard deviation to the mean, often expressed as a percentage. "Convergence is predictable (coefficient of variation 2\% in query count)"
- Directed acyclic graph (DAG): A directed graph with no cycles. "A fundamental fact: $\condense{G}$ is always a DAG"
- Forced-tie property: A theoretical condition ensuring progress by revealing new edges when SCCs have equal in-reach. "The key insight is the forced-tie property (Lemma~\ref{lem:tied-unknown-edge-general}):"
- Gaussian distributions: Normal distributions used to model continuous variables; here, document relevance. "AcuRank~\citep{yoon2025acurank} maintains Gaussian distributions over document relevance and performs Bayesian updates via TrueSkill"
- Greedy algorithm: An algorithmic strategy that makes locally optimal choices to ensure progress. "We present BlitzRank, a greedy algorithm that schedules queries among minimally-resolved SCCs to guarantee progress"
- In-reach: The set (or count) of nodes that can reach a given node via directed paths in the revealed graph. "ordered by ascending in-reach in $\condense{G}$"
- Kemeny-optimal aggregation: A rank aggregation method that finds the ranking minimizing total pairwise disagreements. "shuffling and Kemeny-optimal aggregation mitigate positional biases"
- k-wise comparison oracle: An oracle that, given a subset of up to k items, returns all pairwise preferences among them. "We access through a -wise comparison oracle ."
- Loss count: The number of items that beat a given item in the underlying tournament. "We write for the number of items that beat -- its loss count."
- nDCG@10: Normalized Discounted Cumulative Gain at rank 10; a metric for ranking quality that emphasizes higher-ranked relevant documents. "We measure ranking quality via nDCG@10"
- Non-transitive preferences: Preference judgments that contain cycles, violating transitivity. "non-transitive preferences -- cycles induced by LLM judgments --"
- Pareto dominance: A condition where a method is at least as good on all metrics and strictly better on at least one. "Empirically, across 14 benchmarks and 5 LLMs, our method achieves Pareto dominance over existing methods"
- Pareto frontiers: Curves representing the trade-off between competing objectives where no objective can be improved without worsening another. "Pareto frontiers showing the accuracy-efficiency trade-off across LLM oracles."
- RankGPT prompt format: A specific instruction format used to prompt LLMs for ranking tasks. "All methods use the same underlying LLM with the RankGPT prompt format~\citep{sun2023chatgpt}, differing only in their ranking strategy."
- Retrieval-augmented generation: A paradigm where generation models use retrieved documents to inform responses. "LLMs have emerged as powerful zero-shot rerankers for retrieval-augmented generation"
- Sliding-window paradigm: A listwise reranking strategy that processes overlapping windows of documents. "concurrently established the sliding-window paradigm, processing windows of 20 documents with stride 10"
- Strongly connected component (SCC): A maximal set of nodes where each node is reachable from every other via directed paths. "Our framework captures this via strongly connected components (SCCs): items in cycles form equivalence classes"
- Tiered ranking: A ranking that orders equivalence classes (tiers) when a total order among items is inconsistent. "collapsing them into equivalence classes that yield principled tiered rankings."
- Top-m selection: The task of identifying the m highest-ranked items from a set. "This paper develops a principled framework for this class of problems: top- selection from items via -wise comparison queries."
- Tournament (graph): A directed graph with exactly one directed edge between each pair of distinct vertices. "In graph theory, a tournament is a directed graph with exactly one edge between every pair of vertices"
- Transitive closure: The augmentation of a graph with all edges implied by reachability along existing paths. "These tournaments are aggregated into a global preference graph, whose transitive closure yields many additional orderings without further model invocations."
- Transitive tournament: A tournament whose edges admit a consistent total order (i.e., are acyclic after condensation). "A key theoretical insight is that the condensation of any tournament is itself a transitive tournament"
- TrueSkill: A Bayesian rating system for ranking and matchmaking that updates player (or document) skill estimates. "performs Bayesian updates via TrueSkill"
- Zero-shot reranking: Using an LLM to reorder documents without task-specific training. "LLMs have emerged as powerful zero-shot rerankers for retrieval-augmented generation"
Practical Applications
Immediate Applications
The following applications can be deployed with existing LLMs, retrieval systems, and the provided BlitzRank code, offering immediate efficiency gains and more principled rankings.
- Enterprise and developer RAG reranking (software, knowledge management)
- Use BlitzRank as a drop-in reranker for retrieve-then-rerank pipelines (e.g., BM25 + LLM) to select top-m passages for generation with 25–40% fewer tokens than common listwise methods and 7× fewer than pairwise.
- Tools/workflows: integrate BlitzRank into vector DB stacks and LLM inference layers; default to k=10, terminate when m items are finalized; run parallel batches across SCCs to lower latency.
- Assumptions/dependencies: LLM oracles must return full orderings across k items; context-length constraints and “lost-in-the-middle” effects favor moderate k (e.g., 10); initial retrieval quality impacts final ranking.
- Customer support and internal search triage (software, operations)
- Prioritize top-m relevant articles/tickets from large candidate sets using BlitzRank’s transitive closure and finalization criteria to avoid unnecessary LLM calls.
- Tools/workflows: build a triage service that exposes tiered rankings for ambiguous results; surface SCC tiers as “equivalent relevance” groups for agents.
- Assumptions/dependencies: ability to prompt LLM for k-wise ranking; operational acceptance of tiered ties for near-equivalent items.
- Human-in-the-loop model evaluation (academia, ML ops)
- Replace pairwise or sliding-window evaluations with k-wise panels that record full intra-set preferences; use BlitzRank to determine top-m systems/outputs with fewer comparisons.
- Tools/workflows: evaluator dashboards that compute in-reach L(v), known relationships K(v), and terminate when finalists are certified; SCC heatmaps as an ambiguity signal.
- Assumptions/dependencies: crowdworker or expert prompts must elicit full ordering among k items; inter-rater reliability may affect cycles, but SCCs gracefully capture disagreement.
- Crowdsourced preference judgments and UX testing (industry research, product)
- Run k-wise tasks that elicit complete orderings (not just winners), then aggregate via tournament graphs to select top designs/features more efficiently.
- Tools/workflows: redesign evaluation tasks to collect full k-item orderings; adopt tiered rankings for “too-close-to-call” items.
- Assumptions/dependencies: crowd platforms must support listwise judgments; incentives and instructions must mitigate positional bias.
- Editorial and content curation (media, marketing)
- Rank pitches or campaign variants with k-wise comparisons; leverage SCC tiers to identify clusters of similar-quality content for follow-up testing.
- Tools/workflows: curation boards showing tiers and transitive inferences; print-ready top-m selection once K(v)=n−1 for finalists.
- Assumptions/dependencies: stakeholders accept tiered outputs; enough distinctiveness in content to reduce cycles.
- Bug triage and backlog prioritization (software engineering)
- Compare groups of issues with k-wise rankings; use transitive closure to certify top-m items to prioritize within sprint capacity.
- Tools/workflows: CI bot that runs BlitzRank on issue candidates; exposes “finalized” tags when K(v)=n−1; SCC tiers for equally critical items.
- Assumptions/dependencies: engineering teams must provide oracles (LLMs or humans) that can assess relative impact and risk across items.
- A/B testing and offline recommender evaluation (data science)
- Evaluate model variants with k-wise comparisons per query cohort; BlitzRank reduces evaluation rounds and flags ambiguous cohorts via SCC statistics.
- Tools/workflows: cohort-level tournament graphs; ambiguity dashboards using SCC size/location; predictable token budgets due to stable round counts.
- Assumptions/dependencies: evaluation oracle must generalize across variants; tie tiers need a business rule for breaking ties or follow-up tests.
- Tournament scheduling for hackathons/e-sports (events)
- Replace naive brackets with k-wise “mini-round-robins” to identify top-m finalists quickly; certify rankings with transitive closure.
- Tools/workflows: scheduling app that chooses representatives from minimally-resolved SCCs (greedy schedule); supports parallel matches.
- Assumptions/dependencies: format must allow k-player matches; fairness constraints and spectator preferences may limit designs.
- Procurement and grant review triage (public sector, philanthropy)
- Use panels to perform k-wise comparisons of proposals; adopt tiered rankings to reflect genuine ambiguity and avoid forced arbitrary ordering.
- Tools/workflows: review portals that condense SCCs into tiers and finalize top-m when relationships are known; logs of transitive inferences for auditability.
- Assumptions/dependencies: governance acceptance of tiered outcomes; clear tie-breaking policies at funding boundaries.
- Cost forecasting and governance for LLM usage (ML ops, finance)
- Predict token spend from BlitzRank’s tight convergence distribution; enforce budget-aware stopping when finalists are finalized.
- Tools/workflows: token budgeting calculator using observed rounds (e.g., 13–15 for k=10); alerting when cycles increase costs.
- Assumptions/dependencies: stable oracle behavior across tasks; cost models aligned to actual LLM billing.
- Ambiguity-aware reranking analytics (software, IR)
- Monitor SCC emergence to trigger auxiliary retrieval (e.g., diversify sources when mid-rank cycles appear); identify “hard” queries where additional context may help.
- Tools/workflows: SCC analyzers that compare within-tier BM25 variance to neighbors; automatic retrieval refinement for ambiguous tiers.
- Assumptions/dependencies: access to retrieval scores; acceptable latency for auxiliary rounds.
- Academic benchmarking and methodology (IR, NLP)
- Evaluate listwise vs. pairwise baselines with BlitzRank to quantify token savings and accuracy; use tiered metrics when cycles are prevalent.
- Tools/workflows: open-source BlitzRank integration for IR benchmarks; reports on Pareto frontiers across oracles and datasets.
- Assumptions/dependencies: reproducible prompts and oracle configurations; acceptance of tiered evaluation protocols.
Long-Term Applications
The following applications require further validation, integration, scaling, or domain-specific development before widespread deployment.
- Clinical triage and decision support (healthcare)
- Rank diagnostic hypotheses or treatment plans via k-wise expert+AI panels, retiring low-probability options quickly; use SCC tiers to reflect medical uncertainty.
- Tools/products: clinical CDS modules with tournament graphs; policy for tie tiers at decision boundaries; explainability via transitive evidence paths.
- Assumptions/dependencies: rigorous clinical validation, safety, and regulatory approval; robust oracles beyond general-purpose LLMs; bias and fairness audits.
- Robotics and autonomous systems planning (robotics)
- Evaluate k simulated trajectories/skills at once, aggregating tournaments to select top-m plans with fewer simulations; use tiers to manage near-equivalent plans.
- Tools/products: planner orchestration with BlitzRank scheduling; parallelization across SCCs to reduce wall-clock time.
- Assumptions/dependencies: high-fidelity oracles (physics sims, learned evaluators) capable of k-wise ordering; real-time constraints.
- Agentic AI orchestration and tool selection (software, AI platforms)
- Agents use k-wise comparisons to pick tools, prompts, or subplans; tournament graphs reduce indecision loops and cost while surfacing ambiguous branches.
- Tools/products: “BlitzRank Agent” plugins for frameworks; adaptive k selection based on context and task difficulty.
- Assumptions/dependencies: reliable agent feedback loops; guardrails for non-transitive preferences; integration with memory and retrieval modules.
- Policy and governance of selection processes (public sector, education)
- Formalize tiered ranking in admissions, hiring, and funding decisions; treat cycles as meaningful ambiguity rather than noise, with transparent tie-resolution policies.
- Tools/products: decision support systems that record reachability and finalization; audits of transitive inferences for procedural fairness.
- Assumptions/dependencies: stakeholder buy-in; legal acceptance of tiered outputs; clear, equitable tie-breaking rules.
- Investment and risk triage (finance)
- Rank opportunities/risks with k-wise analyst panels; SCC tiers capture genuinely similar risk profiles, directing deeper due diligence where needed.
- Tools/products: portfolio triage dashboards with tournament analytics; automated follow-up sampling for mid-tier ties.
- Assumptions/dependencies: calibrated domain oracles; compliance and auditability; mitigation of herd effects in cyclic judgments.
- Energy and infrastructure planning (energy, civil)
- Select top-m project proposals or demand-response bids via k-wise expert evaluations; leverage transitive closure to reduce review cycles.
- Tools/products: planning portals with SCC tiering and finalization; structured justifications tied to inferred orderings.
- Assumptions/dependencies: domain-specific evaluators; policy compliance; multi-criteria integration.
- Multi-modal ranking (images, audio, video)
- Extend k-wise tournaments to VLMs/AV models for ranking visual or audio candidates (e.g., frames, clips) with reduced inference cost and principled tiering.
- Tools/products: multi-modal BlitzRank library; cross-modal SCC analytics for ambiguous content.
- Assumptions/dependencies: robust multi-modal oracles; context-length and attention constraints in long video/image sets.
- Dataset curation and evaluator training (ML research)
- Use SCC analysis to identify highly ambiguous samples, akin to ELSPR, filtering or annotating them for training evaluator models and robust rankers.
- Tools/products: “BlitzCuration” pipelines that tag and route ambiguous items; curriculum design based on SCC difficulty.
- Assumptions/dependencies: scalable annotation workflows; agreement on ambiguity handling; downstream model sensitivity to curated tiers.
- Adaptive scheduling and learned k (algorithmic development)
- Learn policies that select k and representatives dynamically to balance accuracy and cost; pursue formal query complexity bounds for m>1 and larger n.
- Tools/products: AutoBlitz schedulers; theoretical modules that certify progress and bound cost.
- Assumptions/dependencies: offline training data; generalized guarantees across tasks; careful tuning to avoid “lost-in-the-middle” degradation.
- Tournament design in professional sports and competitions (sports management)
- Redesign formats with k-wise round-robins to reduce matches while reliably identifying top-m standings; publish tiered tables when non-transitivity arises.
- Tools/products: scheduling planners using BlitzRank for match selection; fairness simulators to evaluate format changes.
- Assumptions/dependencies: rules, broadcasting constraints, and audience acceptance; handling of draws and logistics.
Cross-cutting assumptions and dependencies
- Oracle quality and consistency: The framework assumes access to an oracle (LLM, expert panel, simulator) that can return a complete ordering among k items; non-transitivity is expected and handled via SCC tiers.
- k selection and context limits: Larger k increases cycles due to attention limits; empirical results favor k≈10 for LLM oracles in long-context settings.
- Initial retrieval and candidate diversity: Better initial retrieval reduces cycles and speeds finalization; homogeneous candidates increase SCC size.
- Cost and latency constraints: Predictable round counts enable budgeting; parallelization across SCCs reduces latency but depends on batchable oracles.
- Governance, fairness, and auditability: Tiered rankings must be accepted by stakeholders; decision boundaries in top-m selection require clear tie-handling policies.
- Scaling and domain adaptation: High-stakes applications require domain-specific evaluators, validation, and compliance before deployment.
Collections
Sign up for free to add this paper to one or more collections.