- The paper presents a new RL post-training algorithm, MT-GRPO, that dynamically reweights tasks to maximize worst-case performance in LLM reasoning.
- It integrates improvement-aware updates with ratio-preserving sampling to balance gradient contributions, yielding worst-task accuracy gains of 6–16% over baselines.
- Empirical evaluations show MT-GRPO accelerates learning with up to 50% fewer training steps needed to achieve target worst-task accuracy in multi-task settings.
Multi-Task GRPO: Robust RL Post-Training for LLM Reasoning
Motivation and Problem Analysis
Scaling LLMs toward general-purpose reasoning necessitates robust performance across diverse tasks and benchmarks. Standard RL-based post-training, especially with GRPO, typically optimizes for single-task or mean reward objectives, which permits severe imbalances: easy tasks dominate gradient flow, while harder, underrepresented tasks stagnate, compounded by uneven zero-gradient rates (i.e., prompts yielding no informative gradient signal under GRPO). This deficiency precludes reliable deployment, as models achieving high average scores may fail critically on individual tasks.
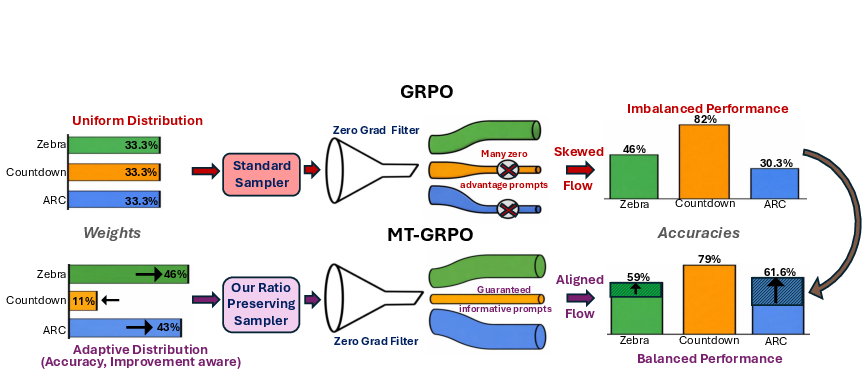
Figure 1: GRPO’s uniform sampling leads to domination of easy tasks (Countdown), while ARC and Zebra lag due to high zero-gradient rates; MT-GRPO prioritizes weak tasks and ratio-preserving sampling to align gradient contributions, improving task balance.
Methodology: MT-GRPO Framework
The paper introduces Multi-Task GRPO (MT-GRPO), a post-training algorithm for LLMs that directly incorporates task-wise robustness into the RL training objective. MT-GRPO consists of two principal innovations:
- Improvement-Aware Task Reweighting: MT-GRPO dynamically adapts task weights using both absolute task-level reward and improvement signal (per-step reward change), explicitly targeting maximization of worst-task performance. This avoids pathological collapse onto the current worst task, typical in strict minimax regimes (ε=0), by coupling reward and improvement in a tunable convex combination.
- Ratio-Preserving Sampler: MT-GRPO enforces the correspondence between adapted task weights and actual gradient signal via batch composition. After filtering zero-gradient prompts, the RP sampler generates batch proportions tightly matching the learned weights, using oversampling and acceptance-aware resampling based on per-task zero-gradient rates. This resolves the discrepancy where high-filtering tasks (e.g., ARC) are underrepresented in parameter updates.
The optimization objective is formulated as a Lagrangian relaxation of a constrained mean-maximization problem: maximize average reward with bounded disparity across tasks. The induced regularizer penalizes deviation from uniform weighting (ℓ1 distance), enabling trade-offs between mean and worst-case accuracy via a tunable parameter λ.
Experimental Evaluation
Controlled Three-Task Setting
MT-GRPO was evaluated on post-training Qwen-2.5-3B (base) across Countdown (math planning), Zebra (logic grid), and ARC (inductive reasoning). All baselines (GRPO, SEC-GRPO, DAPO, SEC-DAPO) were compared under identical RL pipelines.
MT-GRPO yielded absolute gains of 6%+ in worst-task accuracy over strong baselines (DAPO), without sacrificing average accuracy. Additionally, MT-GRPO required 50% fewer training steps to reach 50% worst-task accuracy, demonstrating accelerated learning on weak tasks.
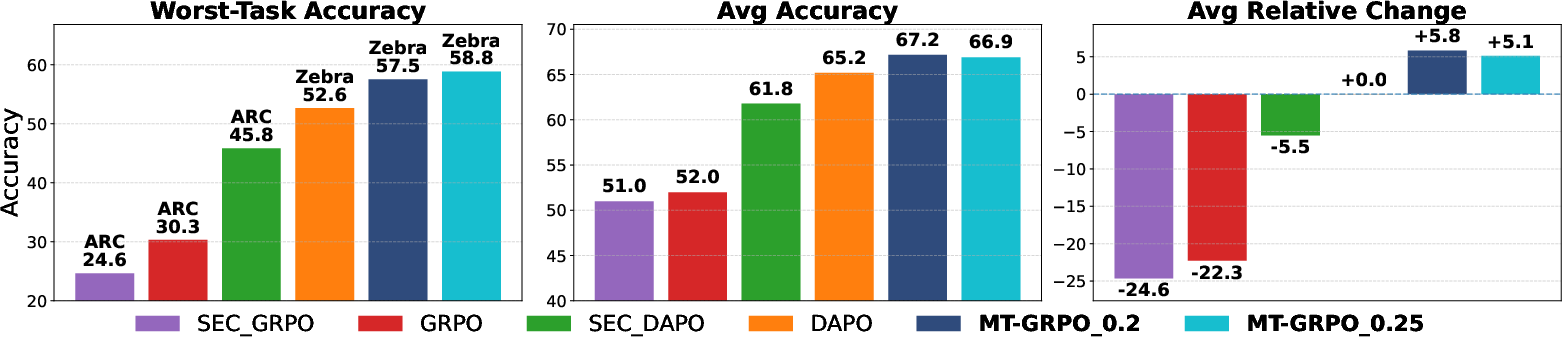
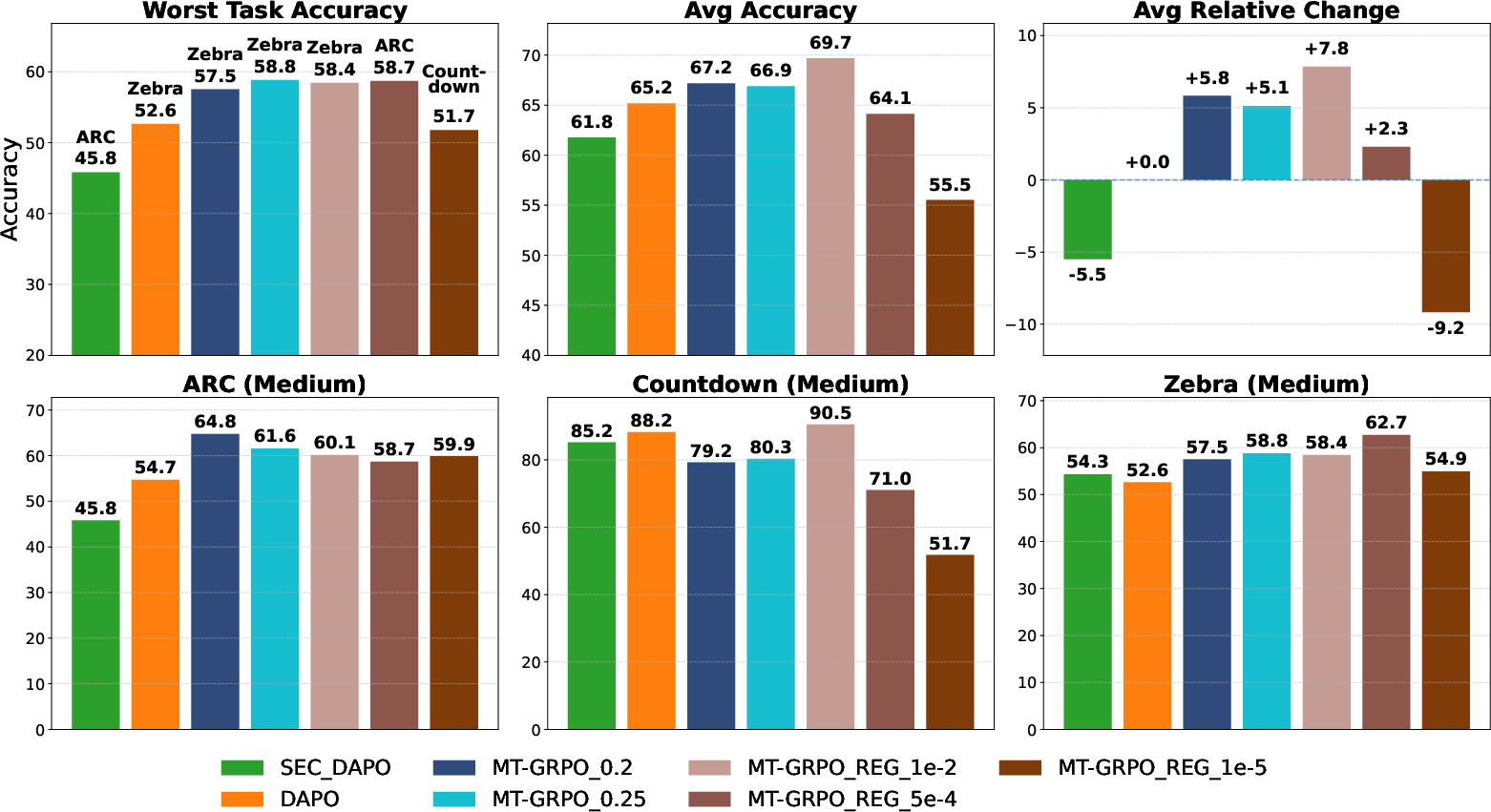
Figure 2: MT-GRPO outperforms all baselines in worst-task accuracy (by ≥6%), maintains average accuracy, and achieves higher per-task relative change.
Task-weight dynamics, illustrated below, show MT-GRPO adaptively reallocates weights toward Zebra and ARC as Countdown performance saturates, while baselines persistently oversample Countdown.
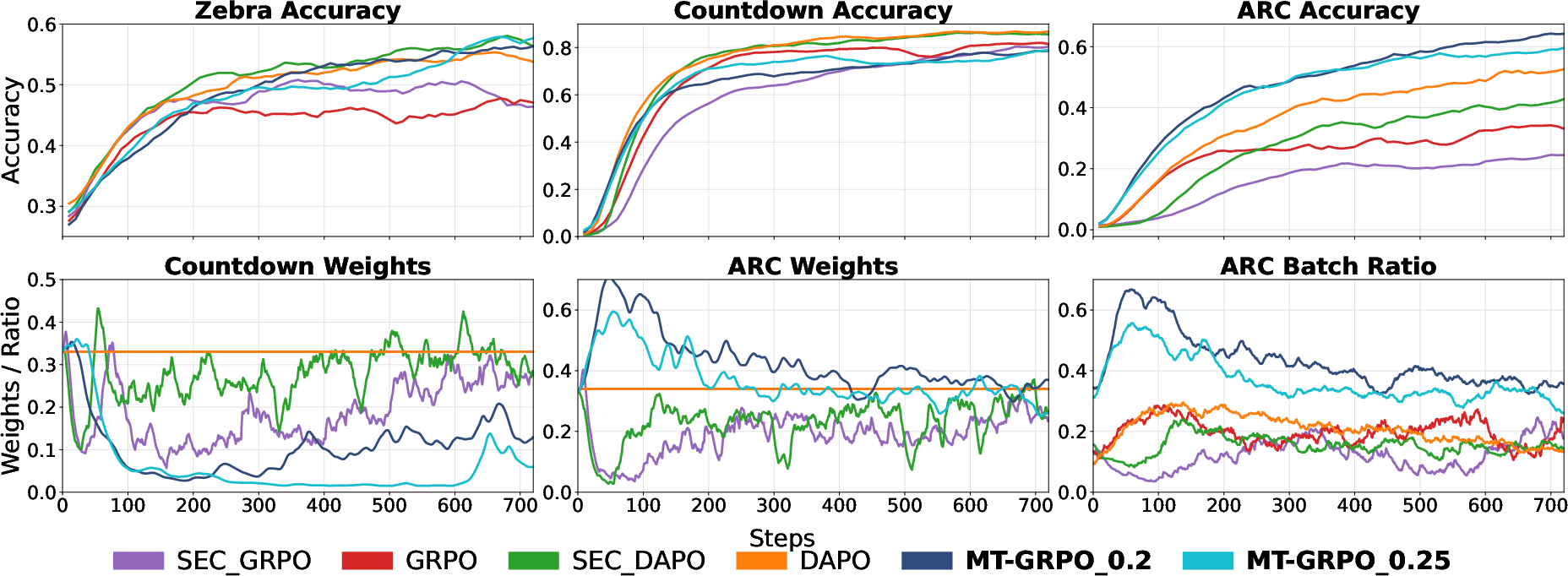
Figure 3: MT-GRPO rebalances weights toward underperforming tasks, yielding balanced improvements; RP sampler ensures batch proportions align with weights, boosting ARC.
Scaling to Nine Tasks
In a larger, more heterogeneous nine-task setting (easy, medium, and hard variants of Countdown, Zebra, ARC), MT-GRPO’s adaptive reweighting persisted in balancing robustness and mean accuracy. Increasing λ improved worst-task accuracy (by up to 16% over GRPO, 6% over DAPO), at the cost of average accuracy, demonstrating controllable trade-offs. Smaller λ values achieved higher relative change, especially on harder tasks.
Ablations and Practical Findings
- Ratio-Preserving Sampler: Removing RP sampler led to compensation—MT-GRPO upweighted ARC to counter its underrepresentation—but effective batch proportions remained skewed, impeding robust learning. Acceptance-aware sampling reduced resampling overhead and ensured efficiency.
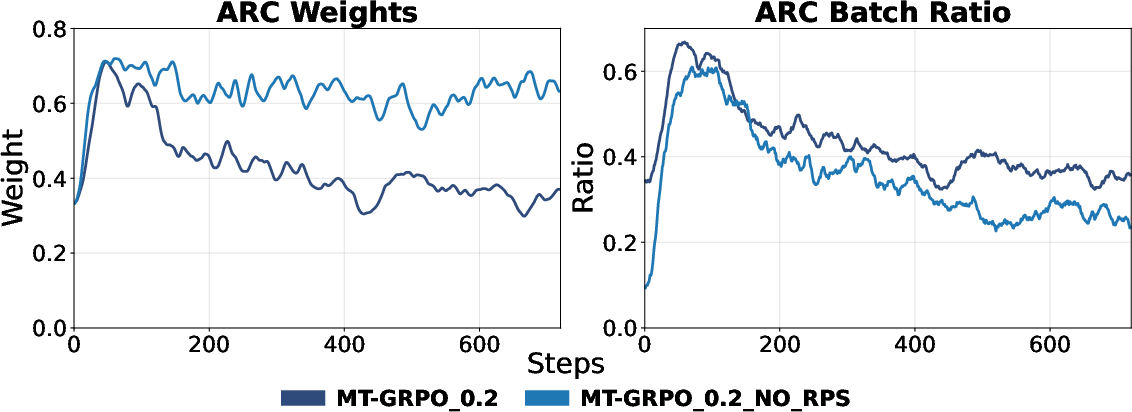
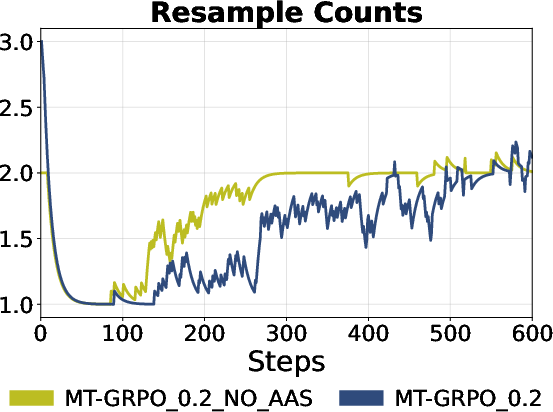
Figure 4: Left: Without RP sampler, MT-GRPO cannot fully represent ARC in batch, even after weight adjustment. Right: Acceptance Aware Sampling reduces required resampling rounds.
Theoretical and Practical Implications
By optimizing for task-wise robustness—max-min or controlled mean/worst-case trade-offs—the MT-GRPO framework directly addresses negative transfer, gradient conflict, and the limitations of average-based objectives in multi-task LLM RL post-training. The explicit incorporation of task improvement signals (cf. [liu2023famo]) and ratio-preserving sampling mechanisms are necessary extensions to existing robust optimization approaches, which do not account for RL-specific nonstationarity and zero-gradient prevalence.
Practically, MT-GRPO equips LLMs for broader deployment as general reasoners, mitigating reliability issues critical in safety-sensitive, multi-domain, or sequential reasoning applications. The results generalize across task diversity and dataset difficulty scales.
Speculation on Future Directions
The methodology enables detailed curriculum management, utility-based trade-offs (mean-vs-worst), and can be extended to more granular task taxonomy or domain-correlated groupings. Integration with other robust RL paradigms (distributionally robust optimization, Nash-based RLHF) and hierarchical curriculum schedules is plausible. Further, ratio-preserving sampling could inform mixture selection and data reweighting in supervised or semi-supervised multi-task fine-tuning, beyond RL.
Conclusion
MT-GRPO establishes a robust framework for reliable multi-task RL post-training in LLMs, coupling adaptive improvement-aware task weighting with ratio-preserving sampling to maximize worst-task competence and accelerate balanced learning. The empirical gains in worst-task accuracy and training efficiency validate the theoretical formulation, marking MT-GRPO as a practical solution for deploying general-purpose LLMs in heterogeneous reasoning environments (2602.05547).