Rethinking Code Complexity Through the Lens of Large Language Models
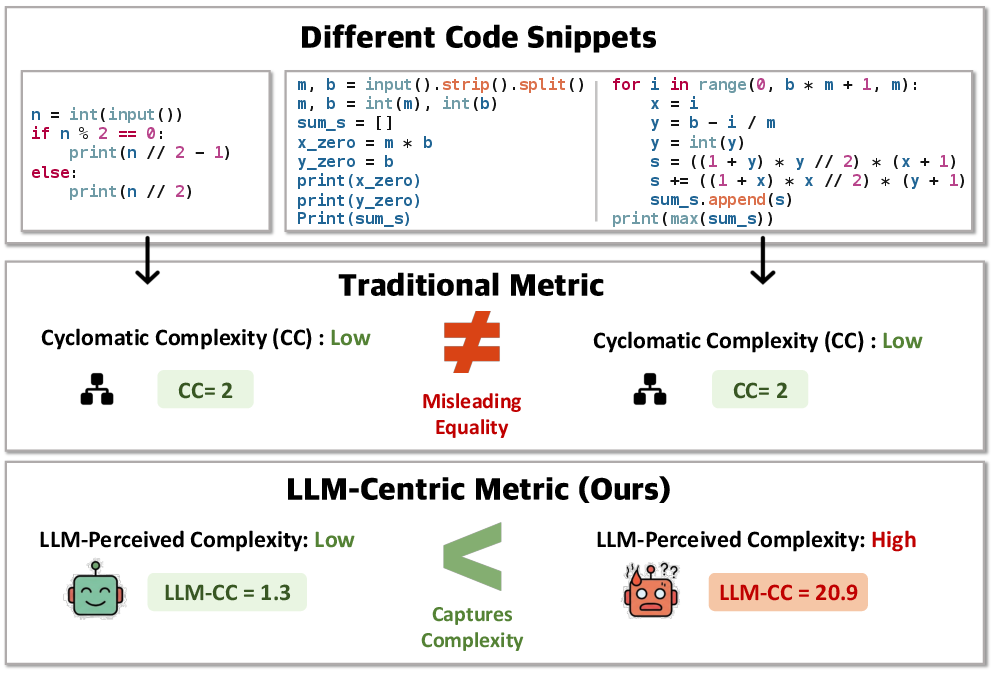
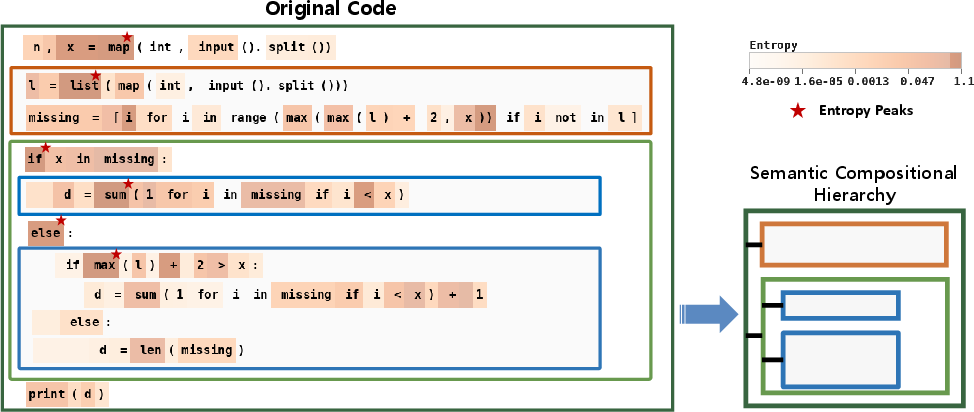
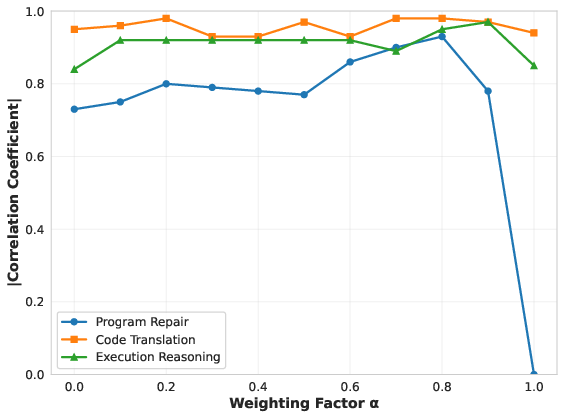
Abstract: Code complexity metrics such as cyclomatic complexity have long been used to assess software quality and maintainability. With the rapid advancement of LLMs on code understanding and generation tasks, an important yet underexplored question arises: do these traditional complexity metrics meaningfully characterize the difficulty LLMs experience when processing code? In this work, we empirically demonstrate that, after controlling for code length, classical metrics exhibit no consistent correlation with LLM performance, revealing a fundamental mismatch with model-perceived difficulty. To address this gap, we propose LM-CC, a novel code complexity metric designed from the perspective of LLMs. The core premise of LM-CC is that LLM-perceived difficulty is driven by the nonlinearity of program semantics. Accordingly, we decompose programs into semantic units based on entropy, organize these units into a compositional hierarchy, and quantify complexity as a principled aggregation of compositional level and branching-induced divergence, capturing cumulative model uncertainty during code processing. Our extensive experiments show that LM-CC not only correlates more strongly with LLM performance than traditional metrics but also that lowering it directly enhances task performance.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
The following list outlines applications that can be deployed now, leveraging the paper’s LM-CC metric, entropy-guided semantic decomposition, and demonstrated causal improvements from reducing LM-CC.
- CI/CD LM-CC Analyzer for Codebases
- Sectors: software development, DevOps, QA
- Use case: Automatically compute LM-CC per commit; flag “LLM-hard” code regions; gate AI-assisted tasks (repair, translation) based on LM-CC thresholds.
- Tools/workflows: GitHub Action/Bitbucket Pipeline; SonarQube plugin; CLI that computes token entropy (e.g., via CodeLlama-7b) and LM-CC with configurable .
- Assumptions/dependencies: Access to a code LLM for entropy; compute budget in CI; code privacy constraints; LM-CC generalizes across languages/frameworks used.
- Prompt Orchestration and Tool Routing
- Sectors: AI coding assistants, productivity tooling
- Use case: Use LM-CC as a signal to switch strategies (e.g., chain-of-thought, structured prompts) or trigger external tools (tests, static analysis, execution).
- Tools/workflows: “LM-CC Router” that selects reasoning templates and toolchains; VS Code extension; API hooks in Copilot-like systems.
- Assumptions/dependencies: Reliable LM-CC inference at snippet-level; consistent gains across models; latency acceptable for interactive use.
- Model-Aware Code Refactoring
- Sectors: software, open-source maintainers
- Use case: Semantics-preserving rewrites to reduce LM-CC (without lowering cyclomatic complexity) to improve LLM success in repair, translation, and reasoning.
- Tools/workflows: “Refactor-bot” that proposes rewrites validated by tests; pre-merge checks ensuring LM-CC decreases and behavior is unchanged.
- Assumptions/dependencies: Strong test coverage; acceptance of style changes; rewrite strategies maintain human readability and performance.
- Benchmark Stratification and Fair Evaluation
- Sectors: academia, benchmarking consortia, platform evaluation
- Use case: Re-bin datasets by LM-CC to compare models fairly and uncover structural failure modes beyond length and cyclomatic complexity.
- Tools/workflows: Benchmark dashboards; LM-CC-binned leaderboards; reporting standards for difficulty calibration.
- Assumptions/dependencies: Standardized LM-CC computation across tasks; agreed thresholds/bins; reproducibility requirements.
- Training Data Curation and Curriculum
- Sectors: AI model training (industry/academia), edtech (programming)
- Use case: Weight/sequence training samples by LM-CC for curriculum learning; build robust generalization to non-linear semantics.
- Tools/workflows: Data pipeline tagging LM-CC; schedulers that interleave low→high LM-CC; ablation to tune per task.
- Assumptions/dependencies: Access to large datasets; compute budget for entropy calculations; observed correlations hold under the training setup.
- Failure Diagnosis and Entropy Hotspot Visualization
- Sectors: DevOps, QA, IDE tooling
- Use case: Visualize token entropy and semantic hierarchy to explain LLM errors; prioritize fixes for deep/branching structures.
- Tools/workflows: IDE plugin (VS Code/JetBrains) showing LM-CC heatmaps; dashboards correlating pass@1 drops with LM-CC spikes.
- Assumptions/dependencies: Integration with LLMs to compute entropy; acceptable overhead; developer adoption.
- Security-Conscious Assistant Policies
- Sectors: cybersecurity, compliance-heavy domains (finance, healthcare)
- Use case: High LM-CC segments trigger stricter policies (manual review, safer transformations, limited autonomous changes).
- Tools/workflows: Policy engines in AI-assisted pipelines; LM-CC thresholds mapping to escalation paths.
- Assumptions/dependencies: LM-CC correlates with error risk on sensitive code; policy frameworks accept model-centric signals.
- API/SDK Documentation Optimization
- Sectors: developer relations, platform teams
- Use case: Curate example code with low LM-CC to improve AI assistant reliability and developer onboarding.
- Tools/workflows: Documentation lint checking LM-CC; auto-suggest simplified examples; A/B tests for assistant success rates.
- Assumptions/dependencies: LM-CC computed on examples; trade-offs with illustrative complexity; multilingual coverage.
Long-Term Applications
The following applications are promising but require further research, scaling, standardization, or integration beyond current capabilities.
- LM-CC–Aware Training Objectives and Architectures
- Sectors: AI R&D, foundation model labs
- Use case: Integrate LM-CC-weighted sampling or structural penalties into loss functions; design architectures that mitigate hierarchical/branching uncertainty.
- Tools/workflows: Curriculum schedulers; entropy-sensitive attention mechanisms; hierarchical tokenization strategies.
- Assumptions/dependencies: Empirical gains at scale; stable LM-CC estimates during training; careful tuning to avoid biasing models toward simpler code.
- LLM-Friendly Compilers/Formatters
- Sectors: compilers, build systems, dev tooling
- Use case: Compiler/formatter passes that reduce LM-CC while preserving semantics and performance (e.g., flattening deep nesting, refactoring branching).
- Tools/workflows: “LLM-friendly” optimization flags; automatic code layout strategies guided by LM-CC.
- Assumptions/dependencies: Verified semantics and performance parity; acceptance of style changes; cross-language generalization.
- Hybrid Agents for High-Assurance Software
- Sectors: healthcare (medical devices), robotics (safety-critical), energy (control software), finance (trading systems)
- Use case: Runtime agents that use LM-CC to decide when to invoke formal verification, symbolic execution, or human-in-the-loop review.
- Tools/workflows: Orchestrators combining LLMs with static/dynamic analyzers; LM-CC thresholds tuned to risk profiles.
- Assumptions/dependencies: Strong toolchain interoperability; regulatory acceptance of model-aware risk gating; robust coverage.
- Enterprise Change Management and Risk Scoring
- Sectors: large-scale software engineering, IT governance
- Use case: Incorporate LM-CC into change risk scoring for AI-driven code mods across monorepos; inform approval workflows and rollout plans.
- Tools/workflows: Risk dashboards; integration with ticketing systems; LM-CC trend monitoring.
- Assumptions/dependencies: Organizational buy-in; clear ROI; stable LM-CC across heterogeneous stacks.
- Standardization and Policy Adoption
- Sectors: standards bodies, procurement, compliance
- Use case: Define LM-CC reporting in software quality standards and vendor SLAs for AI code automation.
- Tools/workflows: Reference implementations; conformance tests; public benchmarks with LM-CC annotations.
- Assumptions/dependencies: Community consensus; transparent, audited LM-CC implementations; legal/privacy considerations.
- Cost and Latency Prediction for AI Code Ops
- Sectors: platform engineering, FinOps, MLOps
- Use case: Use LM-CC to forecast inference cost and latency for code tasks; plan budgets and scheduling for AI-assisted workflows.
- Tools/workflows: Predictive models mapping LM-CC to resource usage; pipeline schedulers.
- Assumptions/dependencies: Stable relationship between LM-CC and runtime cost across models; instrumentation for accurate measurement.
- Automated Large-Scale Refactoring Pipelines
- Sectors: SaaS at scale, legacy modernization
- Use case: Distributed pipelines that iteratively lower LM-CC across repositories (guided by tests and performance checks).
- Tools/workflows: Refactoring agents; test generation to validate semantics; phased rollout strategies.
- Assumptions/dependencies: Extensive test suites; refactor acceptance; balancing human readability and LLM ease.
- Complexity-Aware Curriculum in Education
- Sectors: education (CS programs, MOOCs)
- Use case: Courseware that aligns assignments and auto-grading with LM-CC to calibrate difficulty for AI-supported learning environments.
- Tools/workflows: LM-CC tagging of problems; adaptive pathways based on student + assistant performance.
- Assumptions/dependencies: Ethical use of AI in assessment; avoiding over-optimization to model-centric difficulty at the expense of human learning goals.
Cross-Cutting Assumptions and Dependencies
- LM-CC robustness: Assumes LM-CC’s strong partial correlations generalize across languages, tasks, and models; the paper shows DeepSeek/CodeLlama-based evidence, but broader validation is needed.
- Entropy source: Requires access to an LLM to compute token-level entropy; model choice, threshold, and weighting impact results.
- Compute and privacy: Entropy/LM-CC computation introduces latency/cost and may require on-premise deployment for sensitive code.
- Test coverage: Semantics-preserving rewrites depend on comprehensive tests; weak coverage increases risk of behavioral drift.
- Human factors: Refactoring to reduce LM-CC must balance readability, maintainability, performance, and team conventions.
Collections
Sign up for free to add this paper to one or more collections.